DataGrip 2017.2: Supports Redshift and Azure, several databases in PostgreSQL, transaction control and more
Hello! We continue a series of posts about new versions of IDE from JetBrains. Talk about what's new in DataGrip 2017.2 .
- Amazon Redshift and Microsoft Azure support
- Multiple databases for a single PostgreSQL source
- Transaction Control
- Evaluation of expressions
- Divide DDL and Data tabs for tables
- Integration with recovery tools for PostgreSQL and MySQL
- Improvements related to the launch of queries
- Improvements related to writing code
and other…

Cloud technology is gaining momentum, and we are trying to keep up. Users asked to support some of them in our tracker, especially Redshift .
')
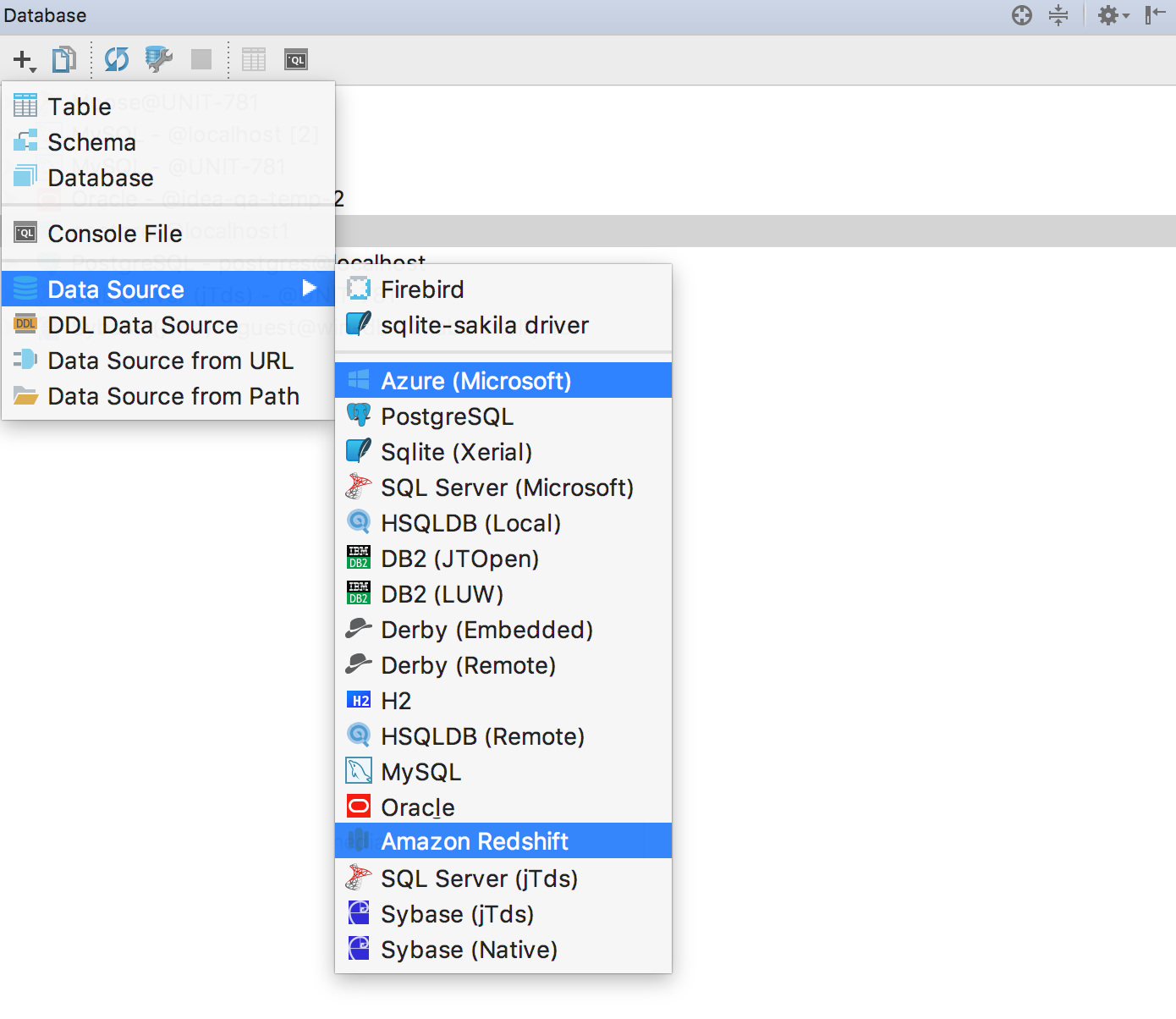
Microsoft Azure is similar to SQL Server : we added a driver, an interface for creating a data source, and improved getting information about objects. This process is called "introspection."
Introspection in Amazon Redshift has become incremental: after the operation, DataGrip looks for information only about the changed objects.
Supported specific parts of the grammar that are not in PostgreSQL . For example, UNLOAD is highlighted correctly, and the query in the argument string is processed like normal SQL — autocompletion and navigation work.
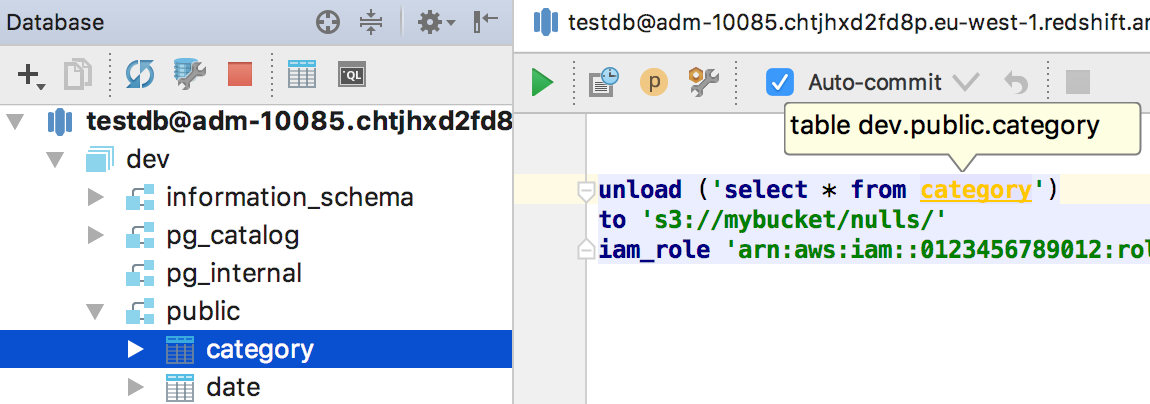
Another example: support functions that are not in PostgreSQL .

If in the code for Redshift something is highlighted in red, and you know that it is correct, this is a bug. Please write about this in our tracker .
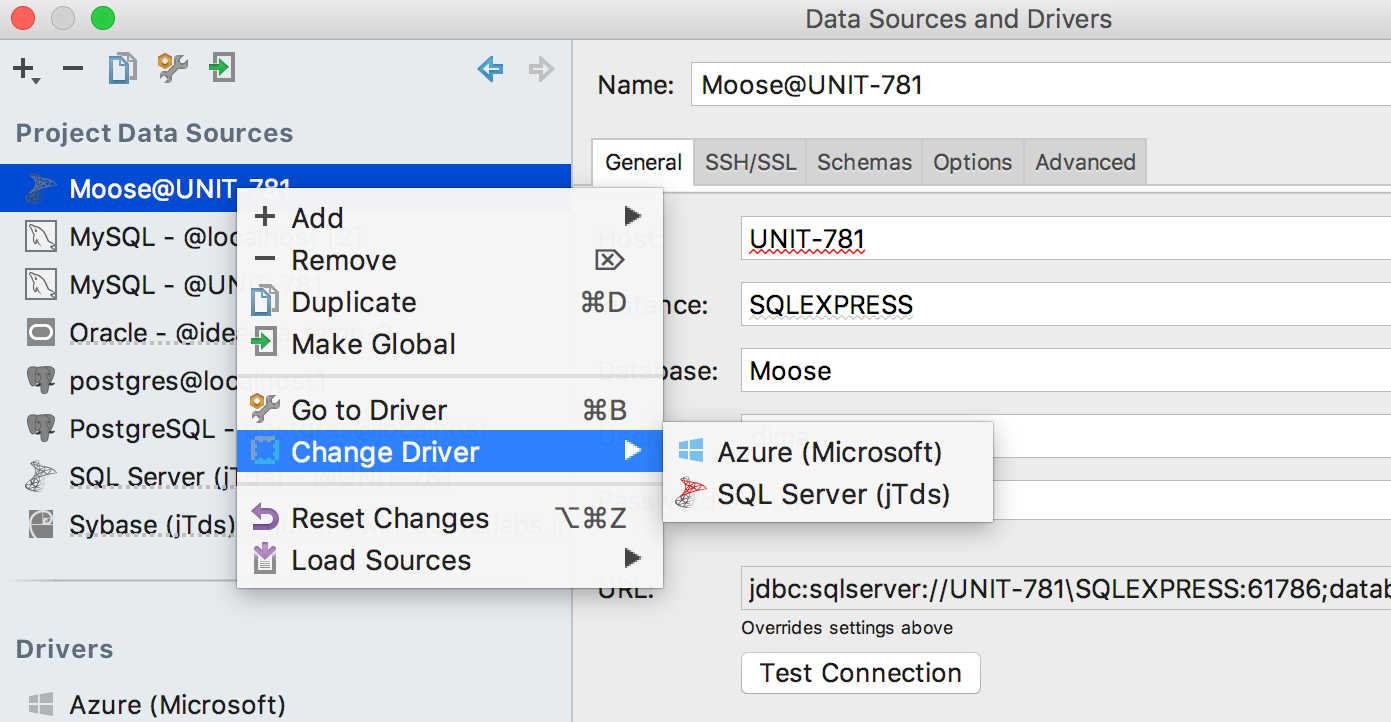
If you connect to Azure and Redshift through the drivers for SQL Server and PostgreSQL , please switch to the correct driver from the context menu.
We have been waiting for this thing for a long time , and we thank those who waited :)
To do this, we rewrote a significant part of the kernel and are still working on it. So your opinion on using multiple databases in PostgreSQL is especially important to us.

Data sources with multiple databases now work in Amazon Redshift , in Microsoft Azure, and in other databases that you connect to via JDBC, if the driver itself supports it.
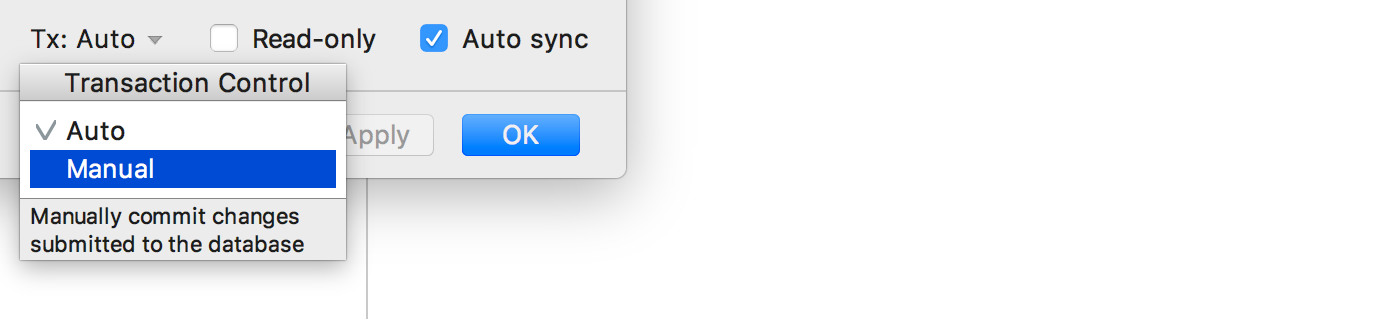
Transaction Control has replaced the Auto-commit option .
Determine the level of transaction control for each data source. In manual mode, you need to commit transactions by performing a COMMIT . In automatic mode ( Auto ) - no.
The transaction control level can also be defined for each console separately, along with the Isolation level , if the database supports it.
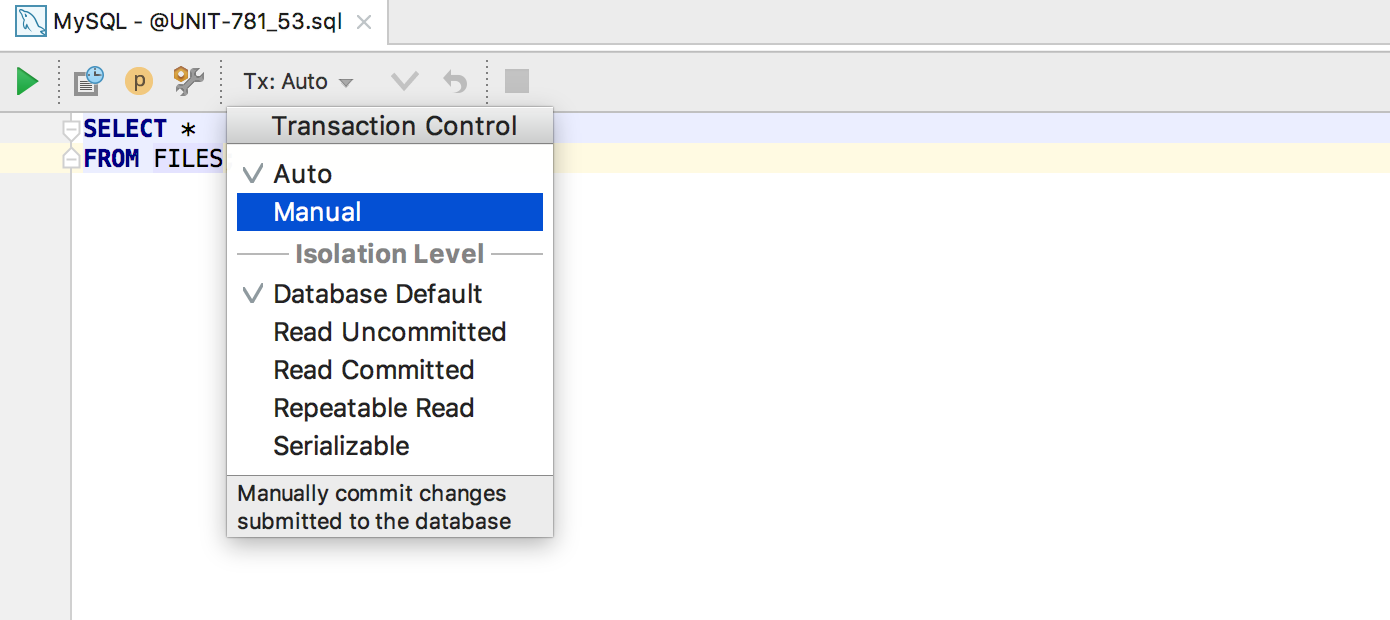
In the data editor, in manual mode, two buttons were added: Commit and Rollback . These actions are available in the context menu.
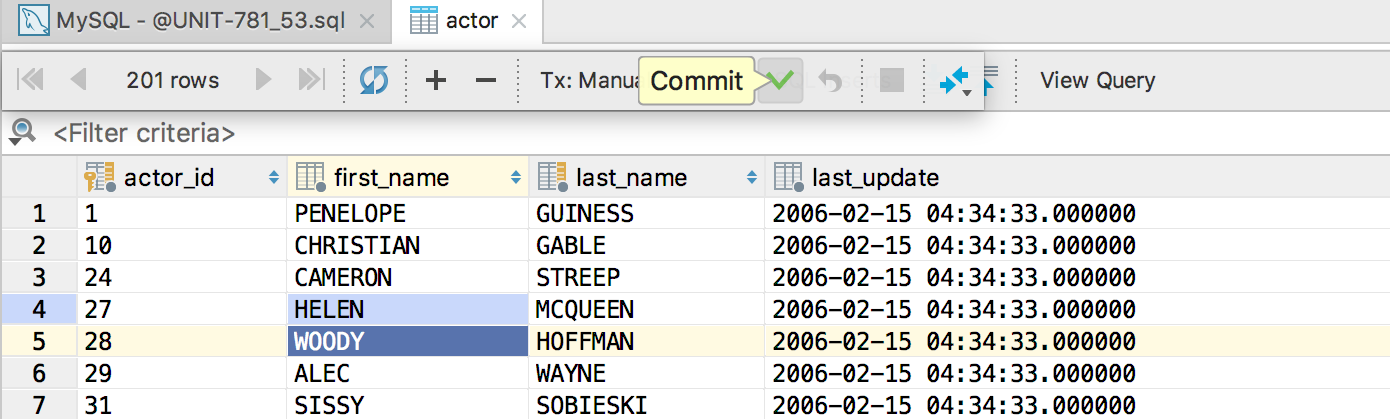
It works like this:
The Submit button or Ctrl / Cmd + Enter sends data to the database: your local changes are rolled in, which until then were highlighted and stored within the DataGrip session. But this transaction will not be fixed if you have manual mode.
Revert Selected from the context menu or Ctrl / Cmd + Alt + Z on selected lines rolls back local changes in these lines. Previously, this was caused by Ctrl + Z , but usually this key combination means to cancel, not roll back.
The Commit or Shift + Ctrl + Alt + Enter button commits the transaction. If you have local changes that are not sent to the database (remember: highlighted), they will automatically go to the database before they are recorded.
Rollback button rolls back an uncommitted transaction.
This will help to quickly see the data without writing a separate query.
As in our other IDEs, use the key combination Ctrl + Alt + F8 to quickly calculate the value of an expression. An expression in this case means the value of a database object, for example, for a table, it is the data itself.
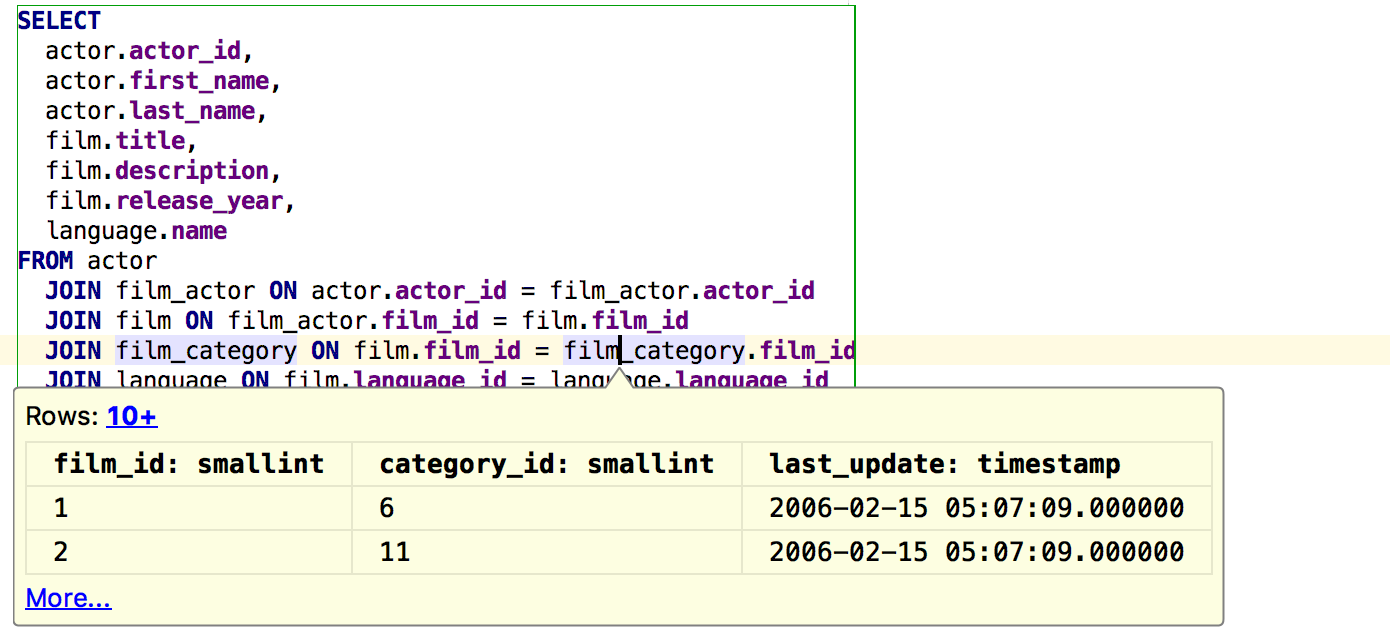
For a column from a query, these are the column values in the expected result.
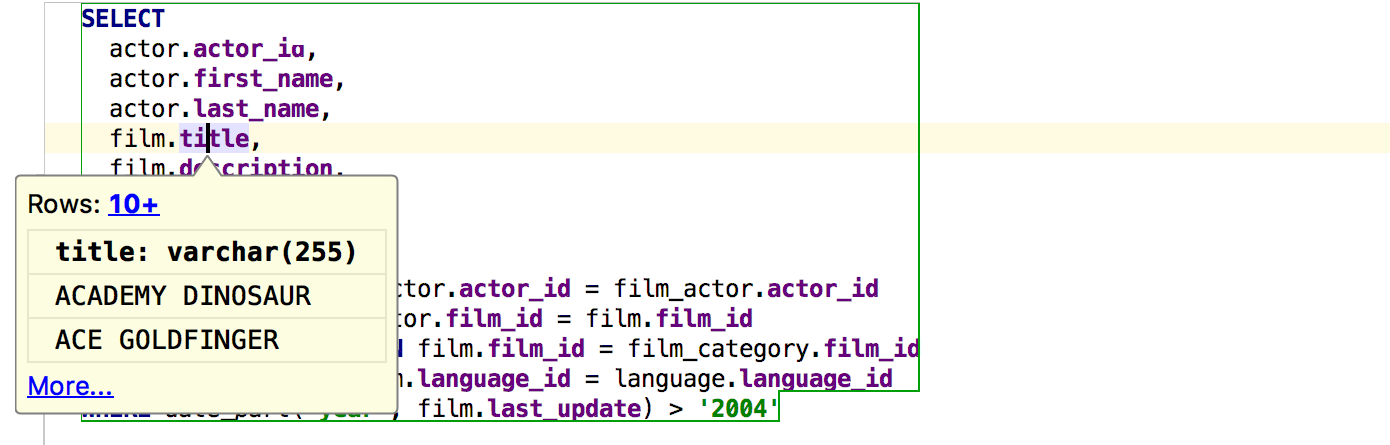
If you perform the same action on a keyword in a query (or subquery), its result will appear in a popup window. Alt + Click works for this .
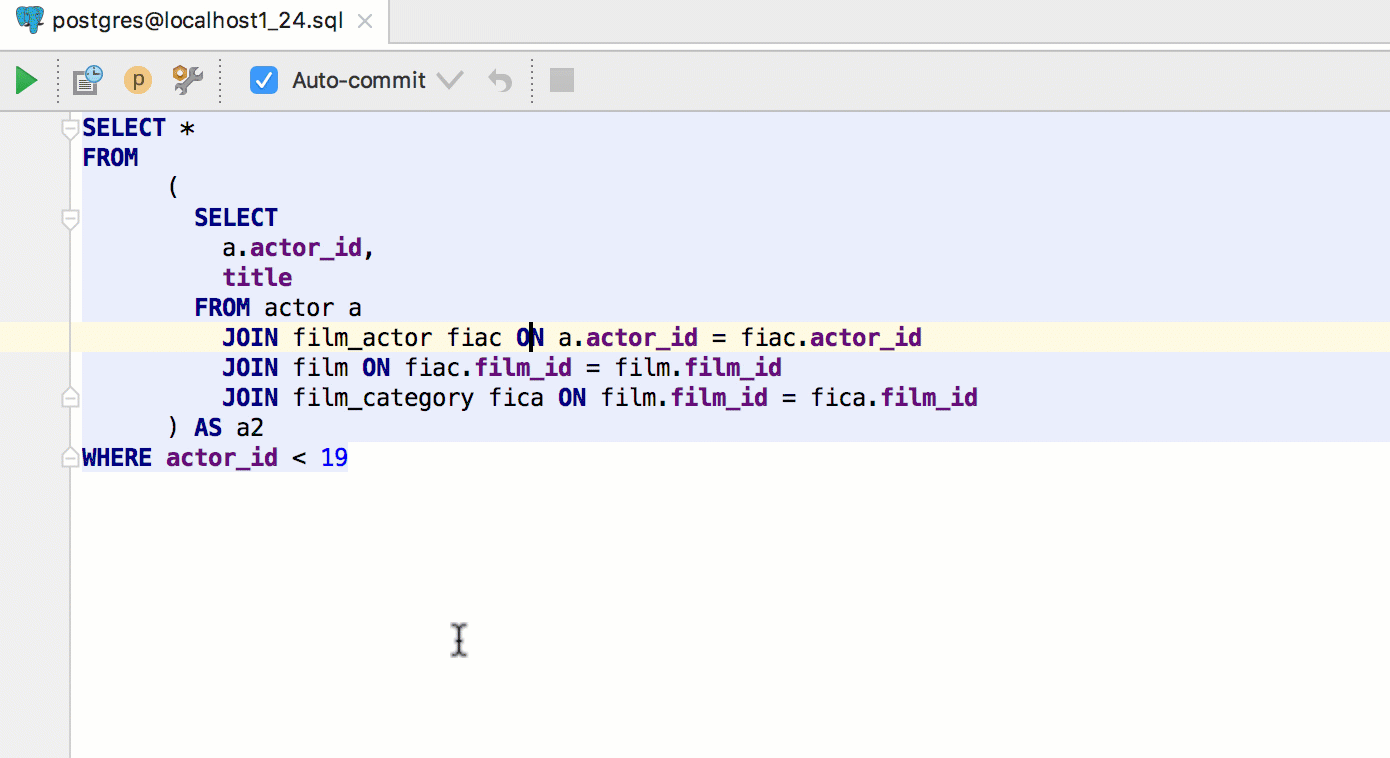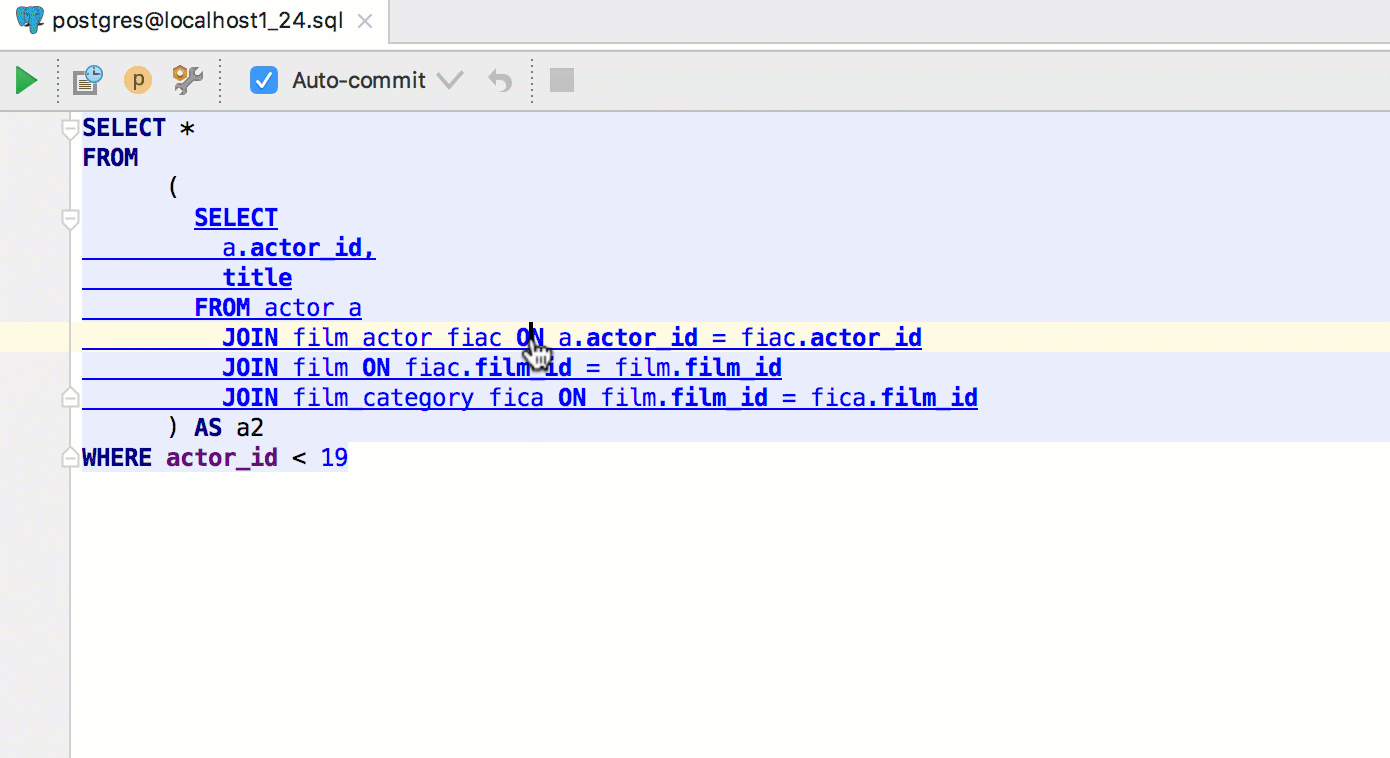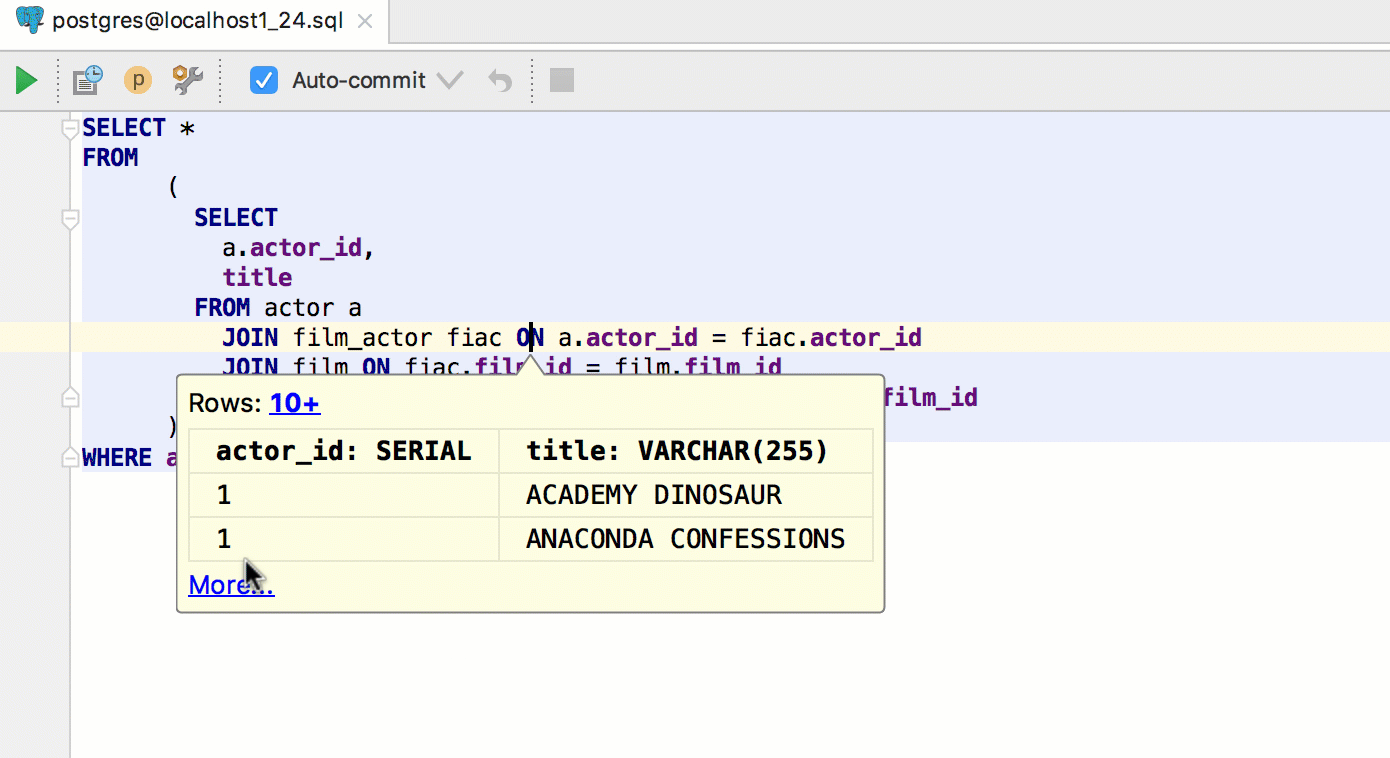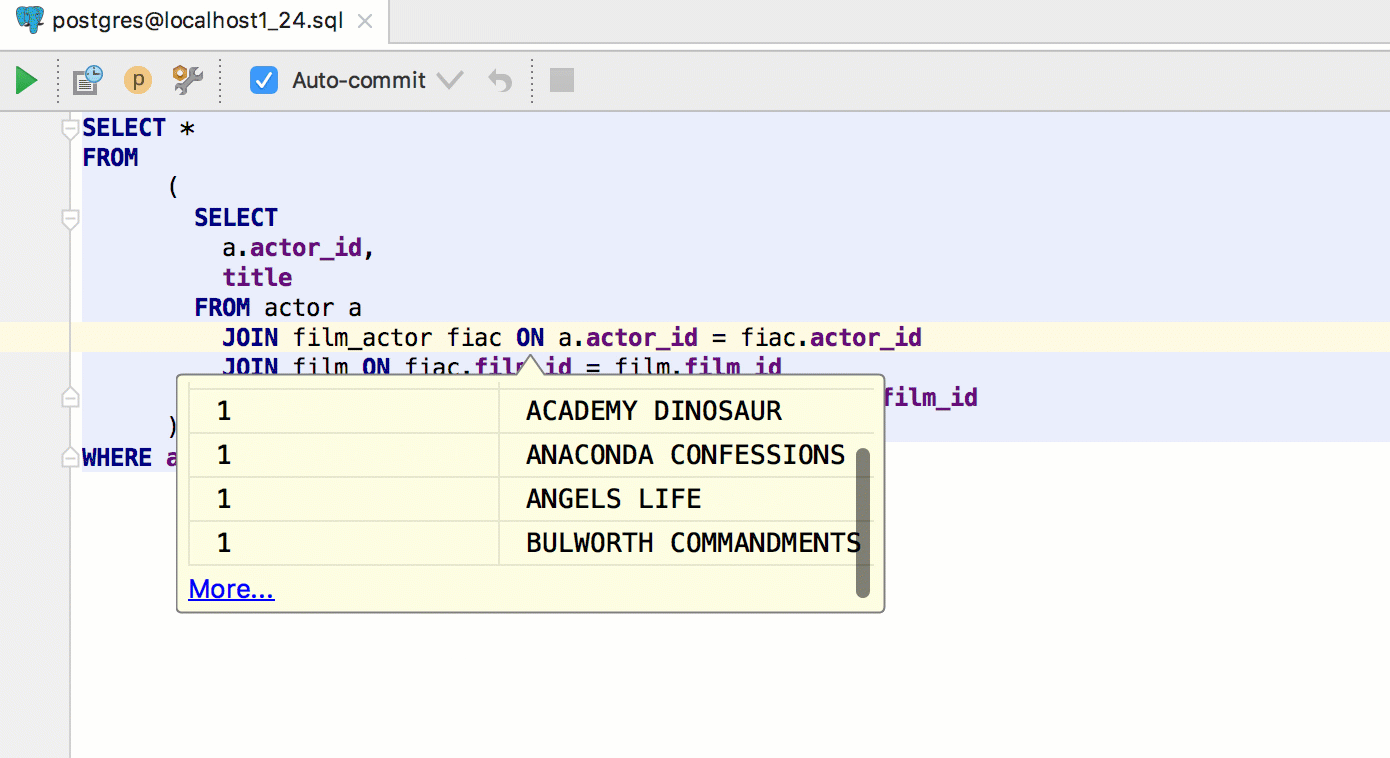
Alt + F8 calls a separate window for evaluating expressions. As in the “fast” version, for the table you will see the data.
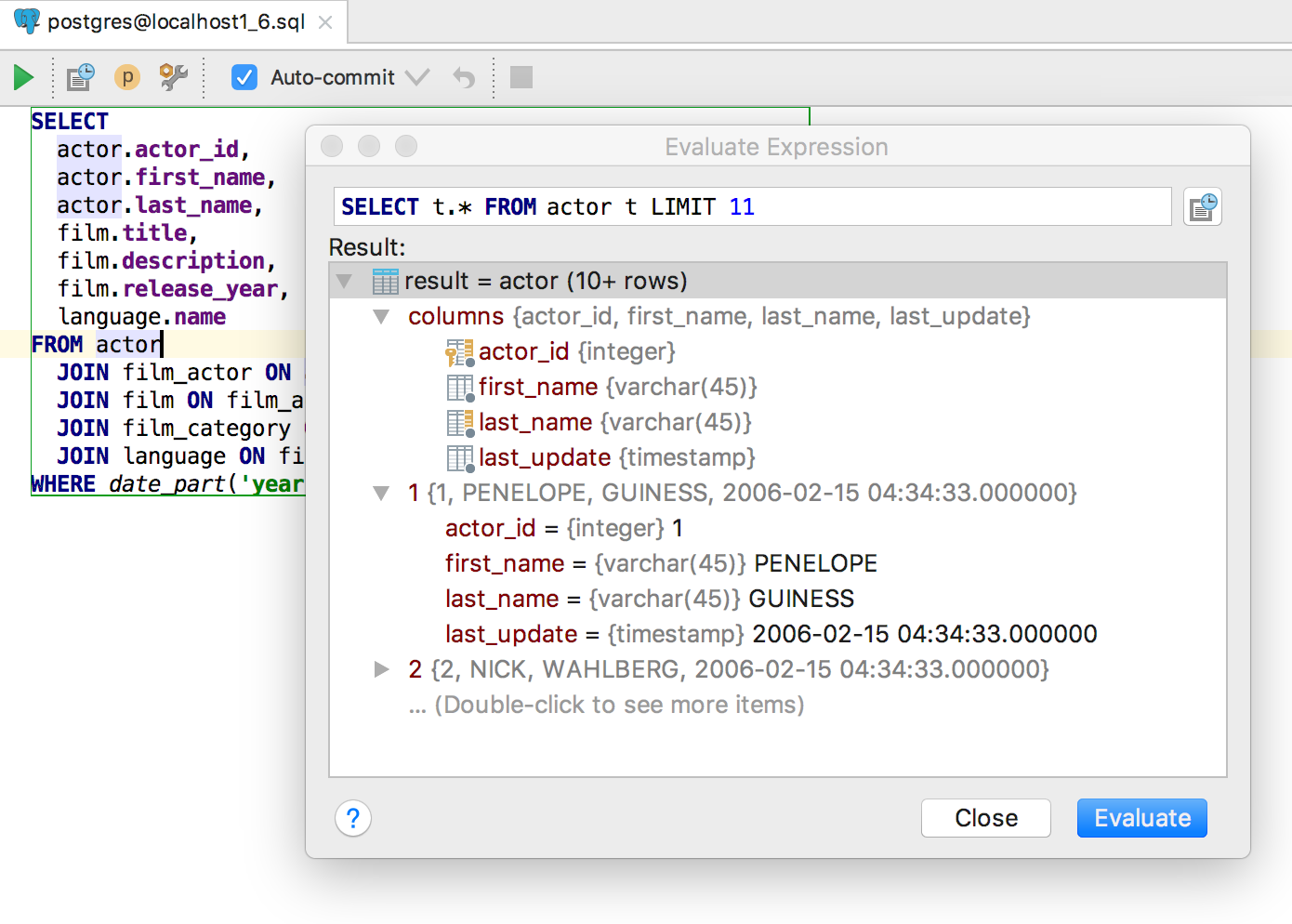
Here you can evaluate expressions in the classic sense of this.
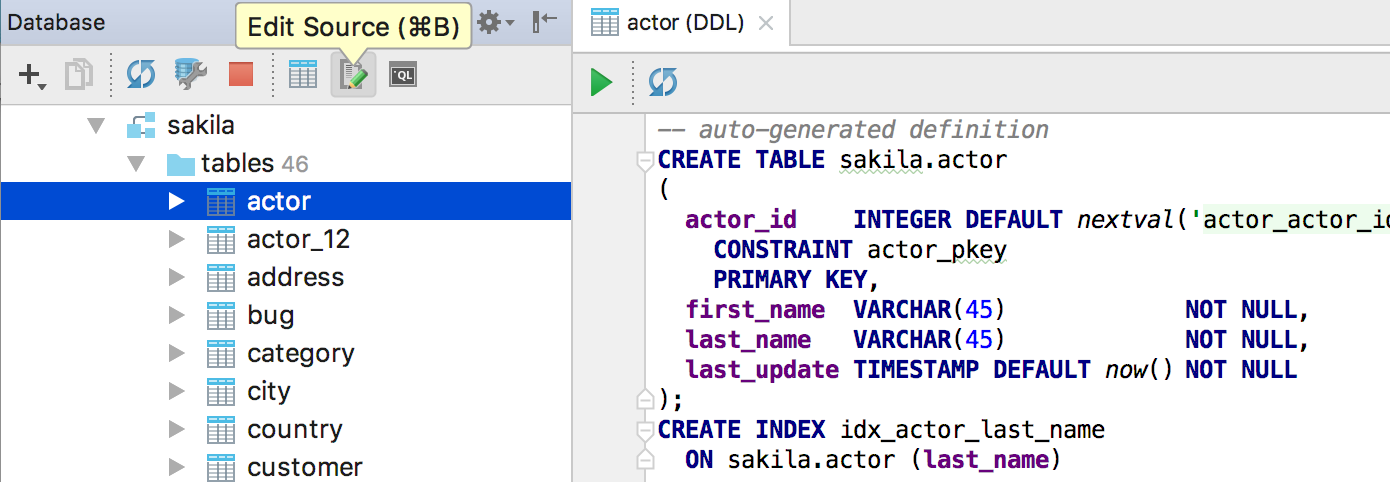
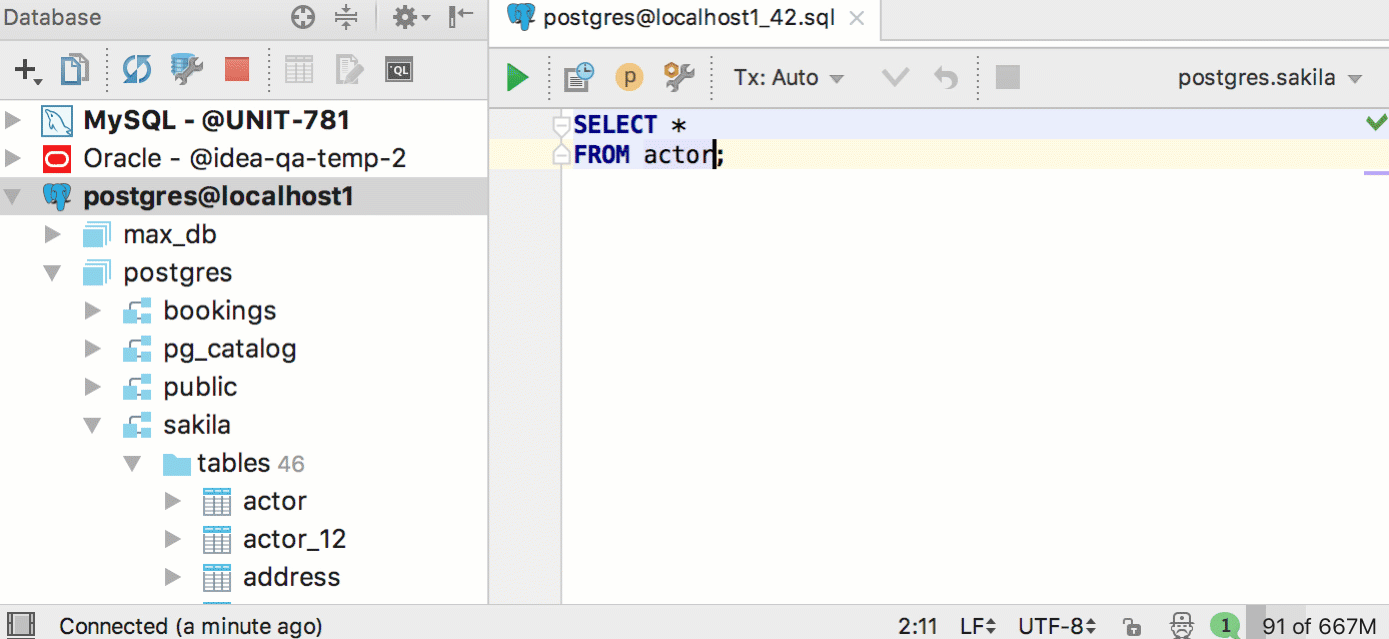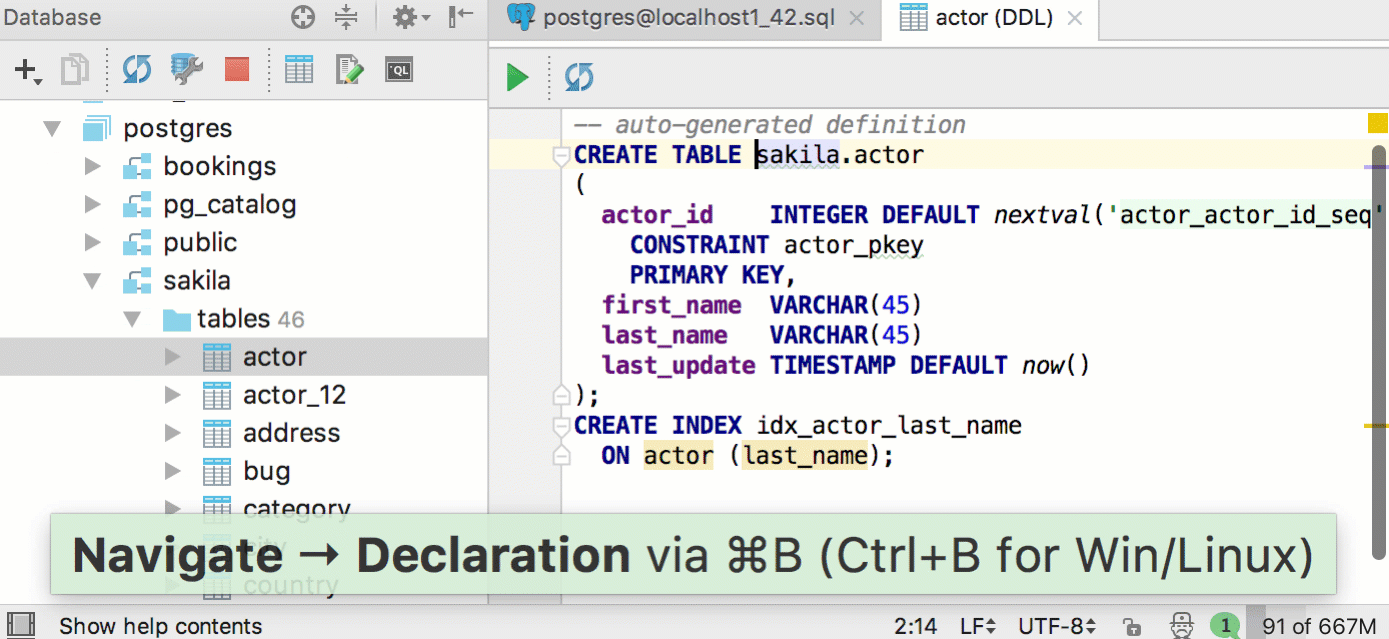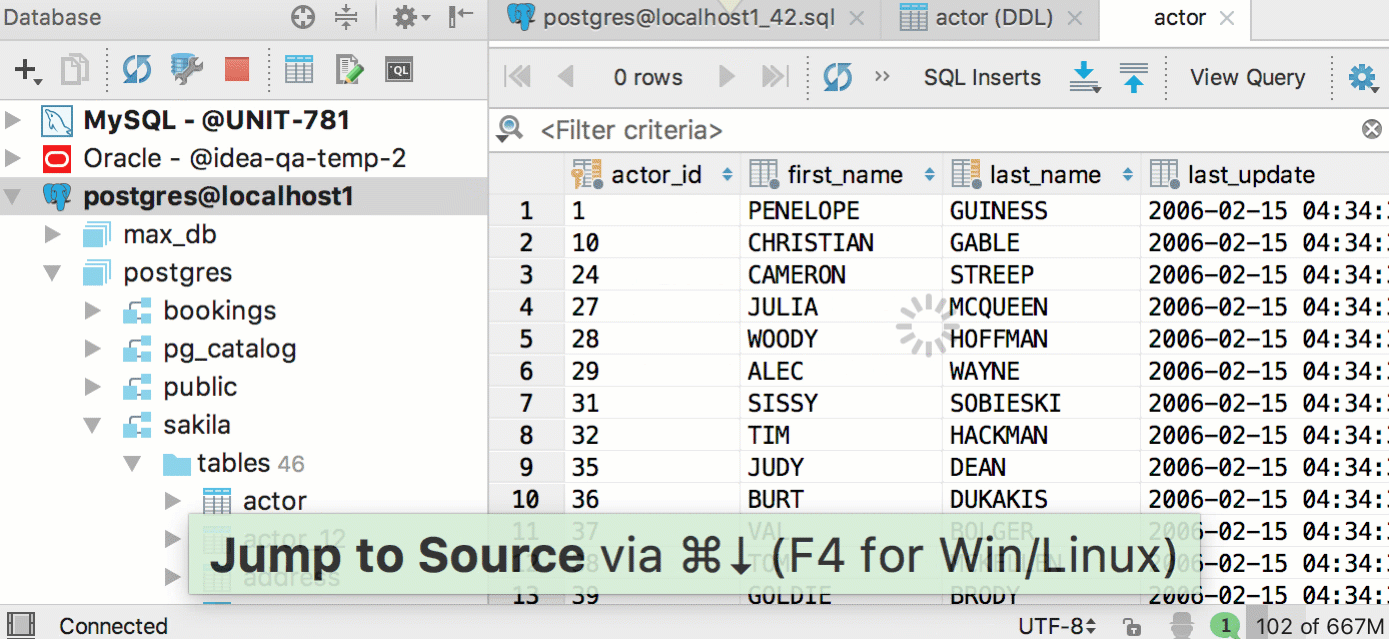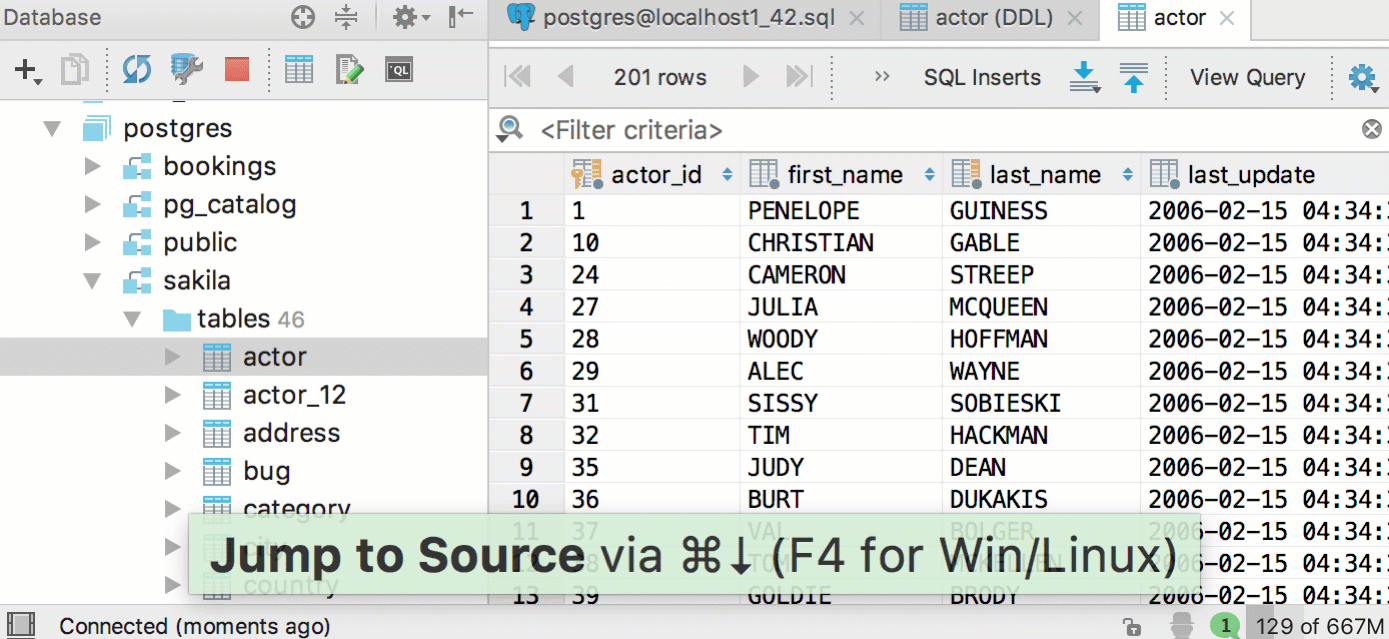
We have separated the table data from the source code - there are no more tabs DDL and Data .
Now, double-click on the table to open the data. To view the DDL, click Edit Source on the toolbar or Ctrl / Cmd + B on the table.
You will see the same DDL editor if you press Ctrl / Cmd + B on the table name in the SQL script. Ctrl / Cmd + click does the same. In previous versions, this action selected an object in the database tree. In 2017.2, to do this, press Alt + F1 and select Database view . Write to us if it became inconvenient: after all, for such an action there used to be one click, and now two.
But the data editor for the table has become easier to open - just press F4 in the code or in the tree.
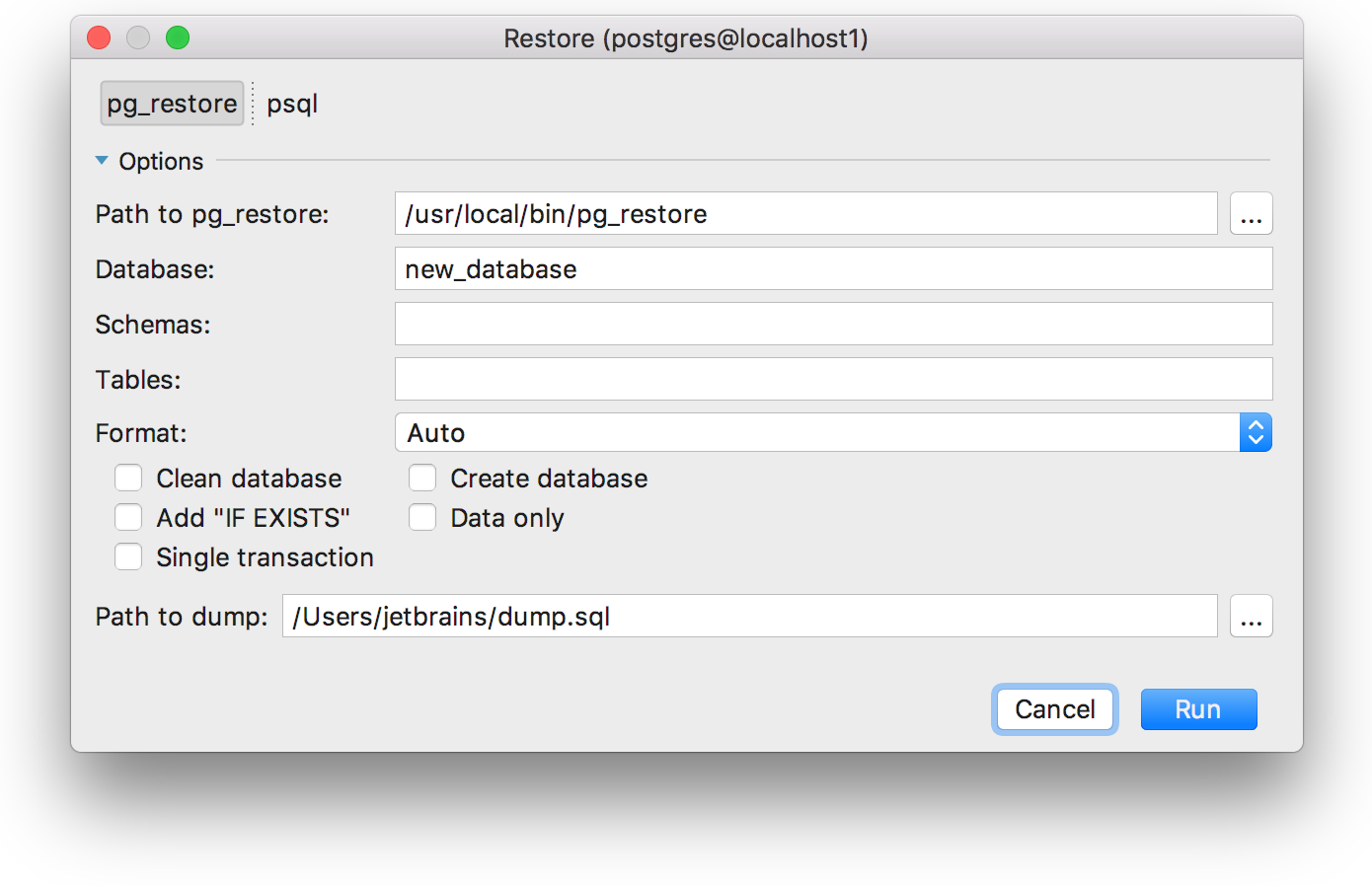
In 2016.3 we integrated mysqldump and pg_dump into DataGrip. It was logical to integrate and restore tools for these bases, even asked about it on Habré last time. They appeared in the context menu. If only one tool is available in this context, for example, the menu item is called ' Restore with pg_restore '.
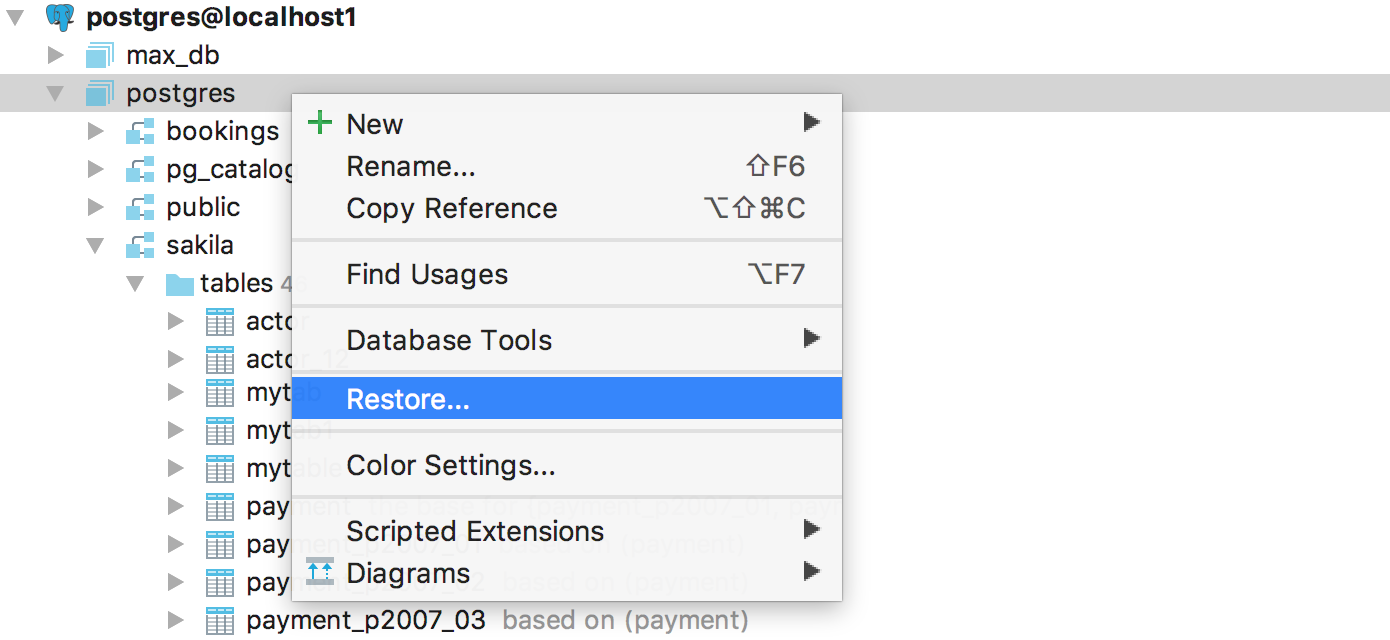
If the base is PostgreSQL , then you can use pg_dump or psql : select at the top of the dialog.
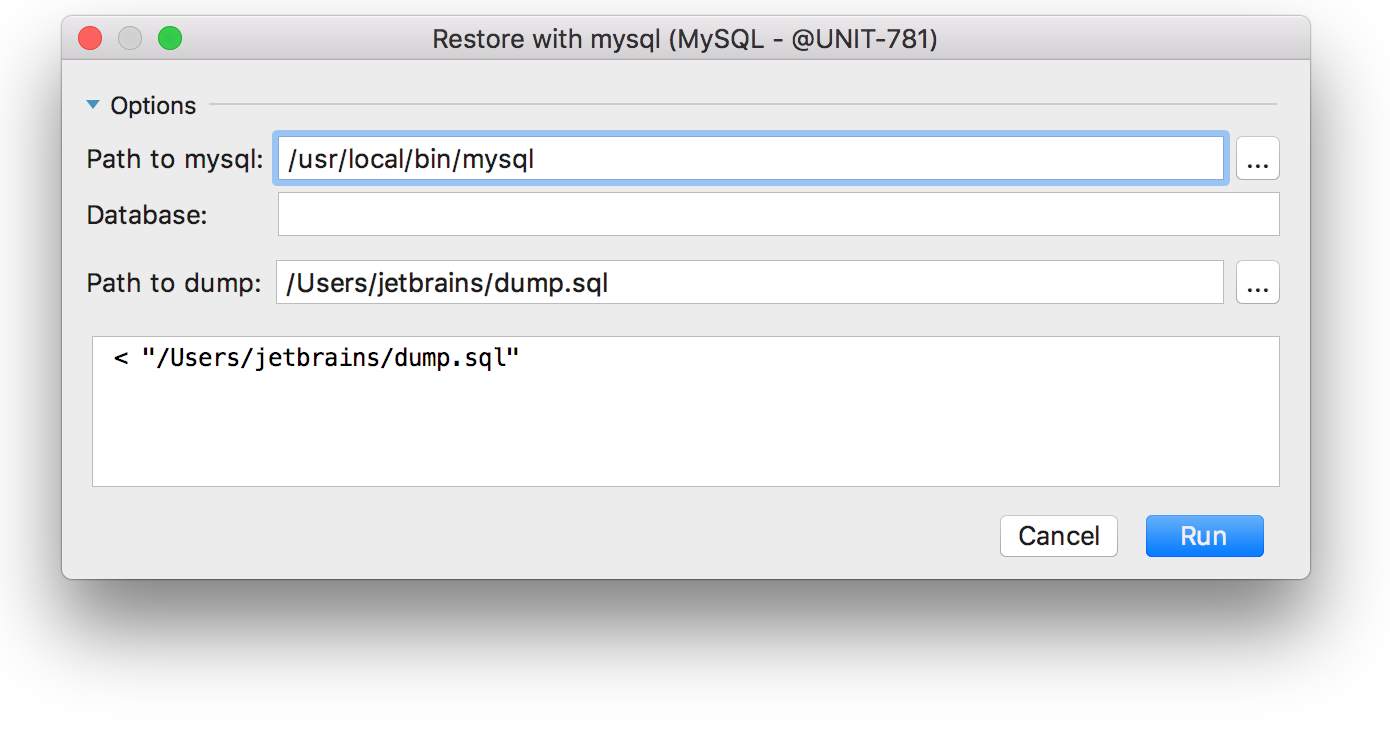
And this is how the window looks for MySQL :
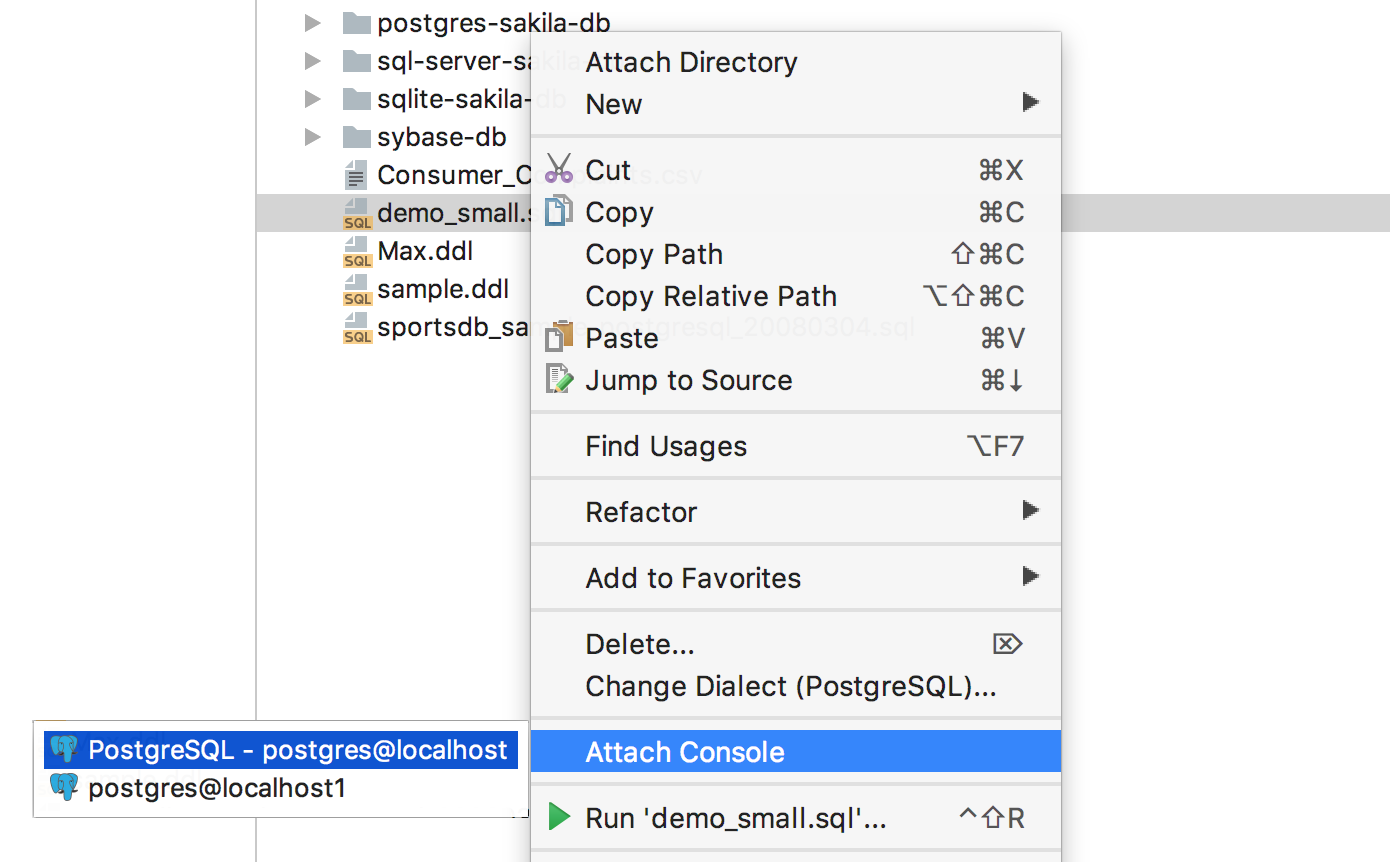
Added a new action - Attach console . It is called, as always, from the search for actions using Ctrl + Shift + A or the context menu of the file. The goal is to run the file in the context of a specific console that you attach to it.
This way, you can run the script on multiple data sources sequentially.
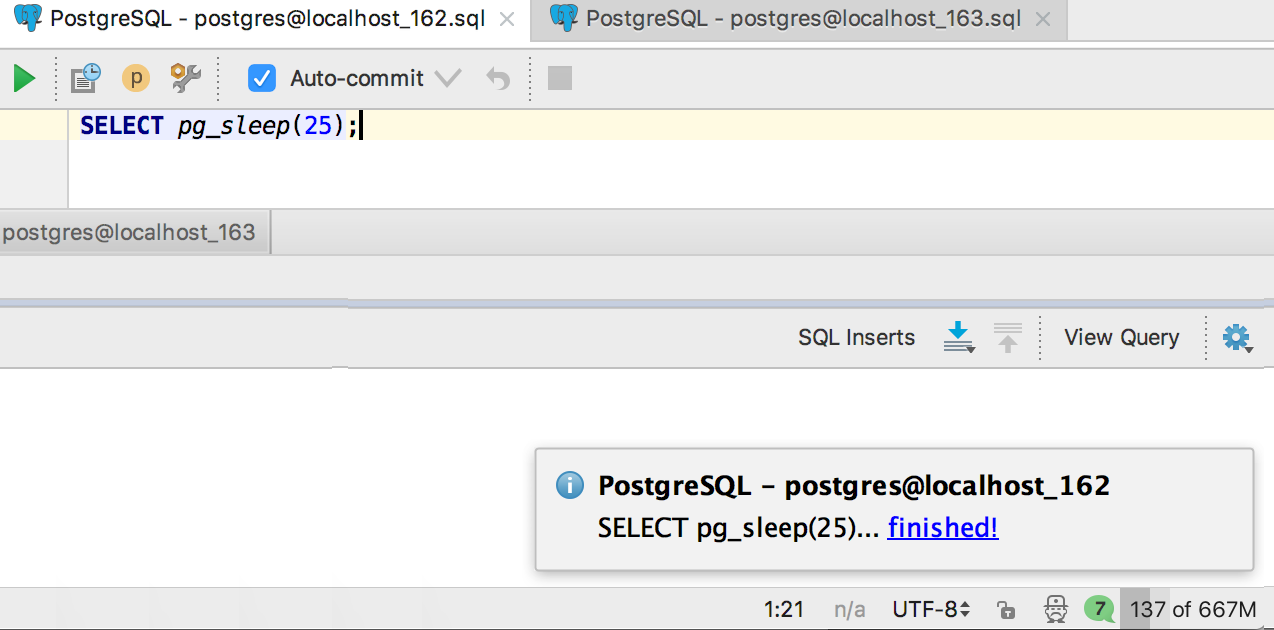
This requested : notification of the completion of long requests. Now a request that has a runtime of more than 20 seconds will throw such a notification inside the DataGrip. Notification can be turned off: the name of the notification “Database queries that took much time”.
One more thing that was asked : now, if you switch consoles, the result obtained from it is switched.

And vice versa: when switching tabs with results, consoles are switched.

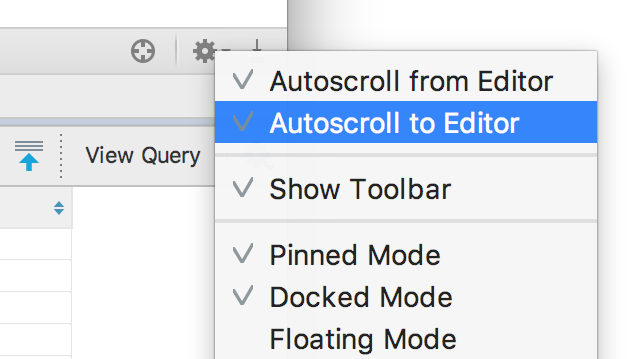
This behavior is now the default - to turn it off, look for the “ Autoscroll ..” options in the settings menu by the gear icon.
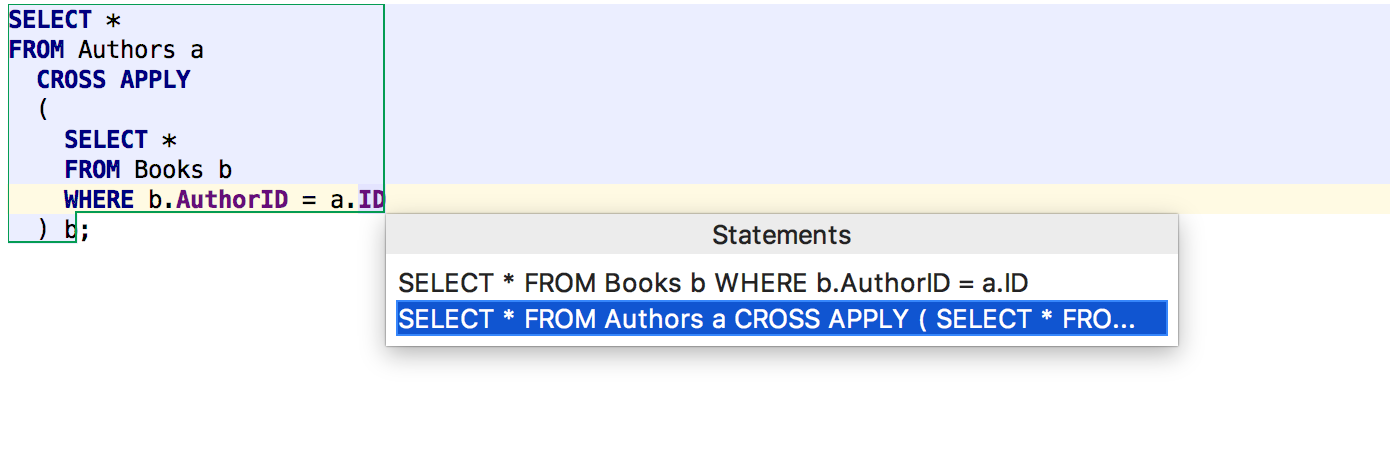
Another small improvement is that when you run a query with a subquery, the default selection window is an external query, not an internal one, as before. Internal queries often cannot be executed.
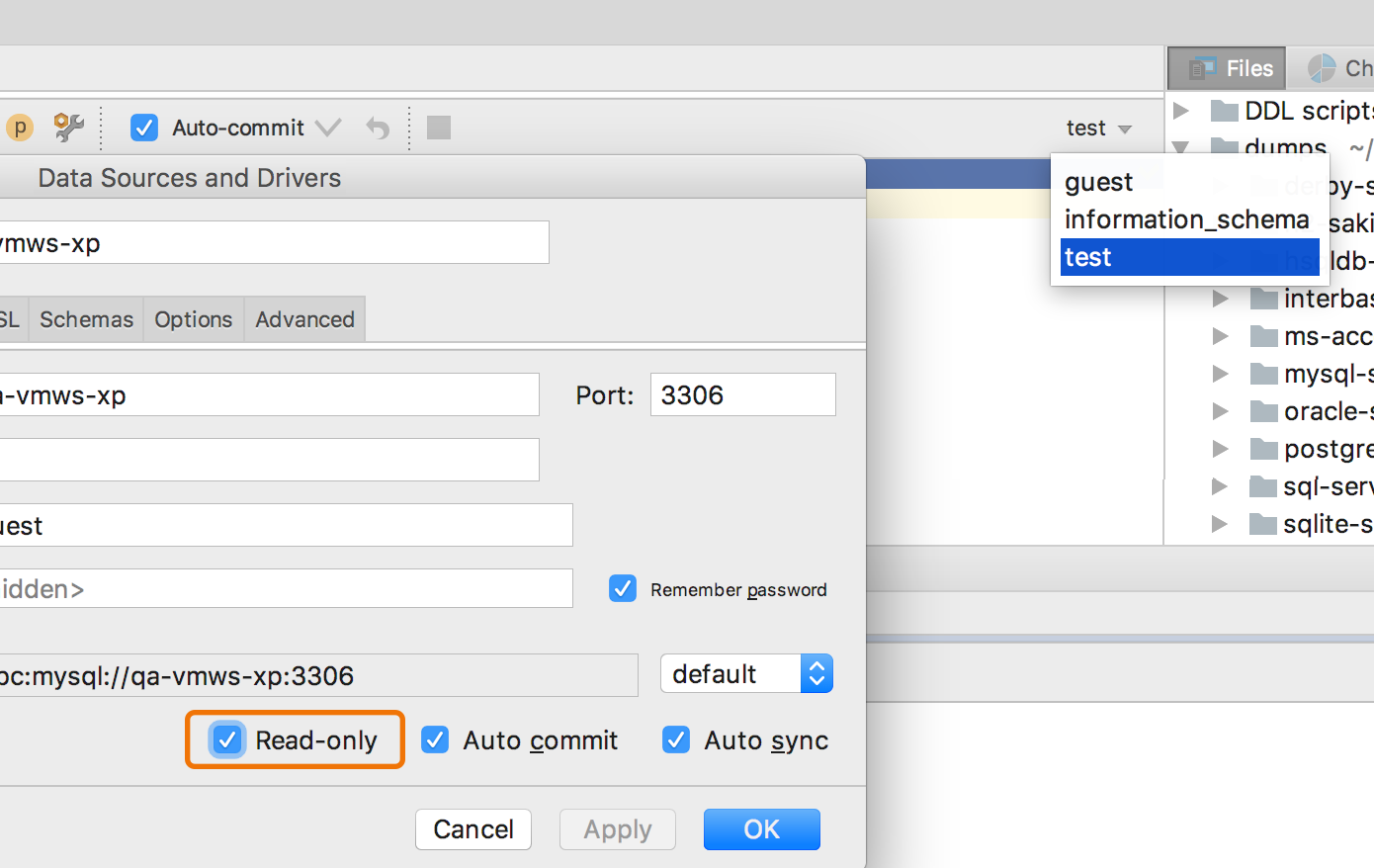
Fixed switch schemes for read-only connections in MySQL .
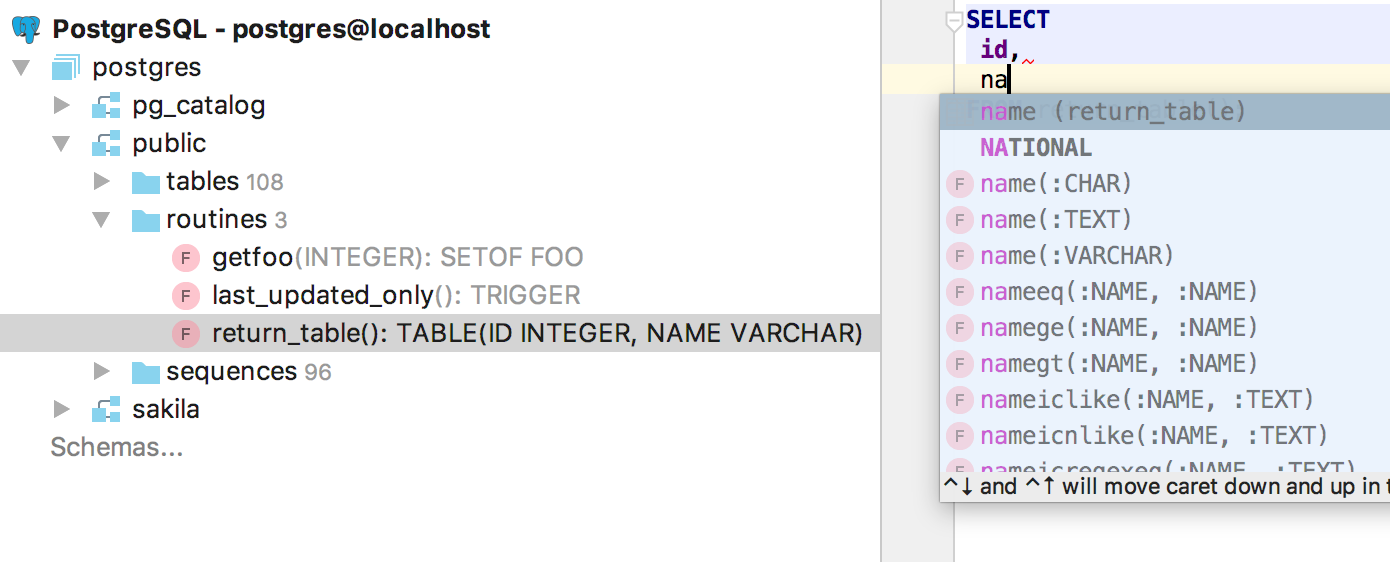
Autocompletion now works for functions returning tables.
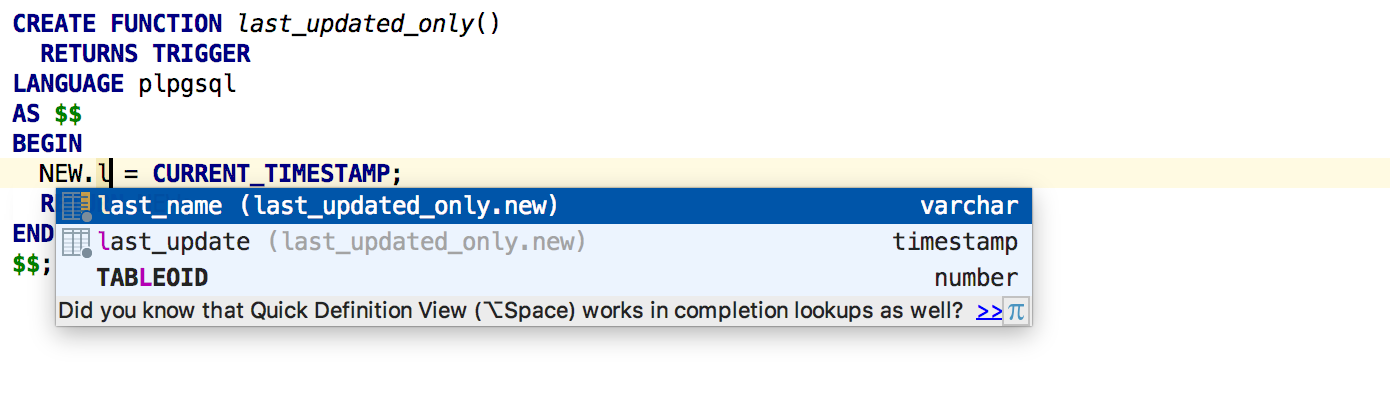
Links NEW and OLD are correctly processed for triggers in PostgreSQL.
Added support for MERGE offers.

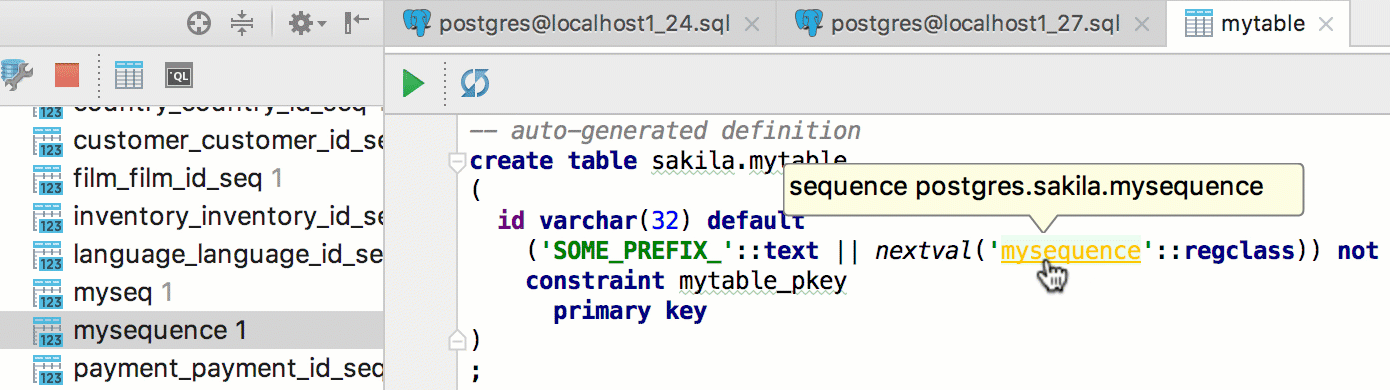
Supported sequences in scripts.
- Database objects can be added to bookmarks ( Bookmarks ).
- File indexing can be stopped and continued at any time.
- Search results in Find in Path with the same lines are combined into one result.
- Support for ALTER FOREIGN TABLE in PostgreSQL .
- Support for the ' json_table ' function in Oracle .
- All attributes are displayed in the generated DDL for Redshift .
- DBE-4600 , the renamed schema is now immediately displayed in the script and in the tree.
- DBE-1288 , renaming sequences in PostgreSQL does not break the query.
- DBE-4507 , you can now create a composite primary key.
- DBE-4637 , requests with GROUP BY no longer report an error that does not exist.
- Scrolling in the data editor has become faster.
And as always: download here , report bugs here , and we also respond on the forum , on Twitter and here in the comments.
Thank!
JetBrains.
- Amazon Redshift and Microsoft Azure support
- Multiple databases for a single PostgreSQL source
- Transaction Control
- Evaluation of expressions
- Divide DDL and Data tabs for tables
- Integration with recovery tools for PostgreSQL and MySQL
- Improvements related to the launch of queries
- Improvements related to writing code
and other…
Amazon Redshift and Microsoft Azure support
Cloud technology is gaining momentum, and we are trying to keep up. Users asked to support some of them in our tracker, especially Redshift .
')
Microsoft Azure is similar to SQL Server : we added a driver, an interface for creating a data source, and improved getting information about objects. This process is called "introspection."
Introspection in Amazon Redshift has become incremental: after the operation, DataGrip looks for information only about the changed objects.
Supported specific parts of the grammar that are not in PostgreSQL . For example, UNLOAD is highlighted correctly, and the query in the argument string is processed like normal SQL — autocompletion and navigation work.
Another example: support functions that are not in PostgreSQL .
If in the code for Redshift something is highlighted in red, and you know that it is correct, this is a bug. Please write about this in our tracker .
If you connect to Azure and Redshift through the drivers for SQL Server and PostgreSQL , please switch to the correct driver from the context menu.
Multiple databases for one PostgreSQL source
We have been waiting for this thing for a long time , and we thank those who waited :)
To do this, we rewrote a significant part of the kernel and are still working on it. So your opinion on using multiple databases in PostgreSQL is especially important to us.
Data sources with multiple databases now work in Amazon Redshift , in Microsoft Azure, and in other databases that you connect to via JDBC, if the driver itself supports it.
Traction control
Transaction Control has replaced the Auto-commit option .
Determine the level of transaction control for each data source. In manual mode, you need to commit transactions by performing a COMMIT . In automatic mode ( Auto ) - no.
The transaction control level can also be defined for each console separately, along with the Isolation level , if the database supports it.
In the data editor, in manual mode, two buttons were added: Commit and Rollback . These actions are available in the context menu.
It works like this:
Automatic and manual mode.
The Submit button or Ctrl / Cmd + Enter sends data to the database: your local changes are rolled in, which until then were highlighted and stored within the DataGrip session. But this transaction will not be fixed if you have manual mode.
Revert Selected from the context menu or Ctrl / Cmd + Alt + Z on selected lines rolls back local changes in these lines. Previously, this was caused by Ctrl + Z , but usually this key combination means to cancel, not roll back.
Only in manual mode
The Commit or Shift + Ctrl + Alt + Enter button commits the transaction. If you have local changes that are not sent to the database (remember: highlighted), they will automatically go to the database before they are recorded.
Rollback button rolls back an uncommitted transaction.
Expression evaluation
This will help to quickly see the data without writing a separate query.
As in our other IDEs, use the key combination Ctrl + Alt + F8 to quickly calculate the value of an expression. An expression in this case means the value of a database object, for example, for a table, it is the data itself.
For a column from a query, these are the column values in the expected result.
If you perform the same action on a keyword in a query (or subquery), its result will appear in a popup window. Alt + Click works for this .
Alt + F8 calls a separate window for evaluating expressions. As in the “fast” version, for the table you will see the data.
Here you can evaluate expressions in the classic sense of this.
DDL tables
We have separated the table data from the source code - there are no more tabs DDL and Data .
Now, double-click on the table to open the data. To view the DDL, click Edit Source on the toolbar or Ctrl / Cmd + B on the table.
You will see the same DDL editor if you press Ctrl / Cmd + B on the table name in the SQL script. Ctrl / Cmd + click does the same. In previous versions, this action selected an object in the database tree. In 2017.2, to do this, press Alt + F1 and select Database view . Write to us if it became inconvenient: after all, for such an action there used to be one click, and now two.
But the data editor for the table has become easier to open - just press F4 in the code or in the tree.
Integration with recovery tools for PostgreSQL and MySQL
In 2016.3 we integrated mysqldump and pg_dump into DataGrip. It was logical to integrate and restore tools for these bases, even asked about it on Habré last time. They appeared in the context menu. If only one tool is available in this context, for example, the menu item is called ' Restore with pg_restore '.
If the base is PostgreSQL , then you can use pg_dump or psql : select at the top of the dialog.
And this is how the window looks for MySQL :
Run queries
Added a new action - Attach console . It is called, as always, from the search for actions using Ctrl + Shift + A or the context menu of the file. The goal is to run the file in the context of a specific console that you attach to it.
This way, you can run the script on multiple data sources sequentially.
This requested : notification of the completion of long requests. Now a request that has a runtime of more than 20 seconds will throw such a notification inside the DataGrip. Notification can be turned off: the name of the notification “Database queries that took much time”.
One more thing that was asked : now, if you switch consoles, the result obtained from it is switched.
And vice versa: when switching tabs with results, consoles are switched.
This behavior is now the default - to turn it off, look for the “ Autoscroll ..” options in the settings menu by the gear icon.
Another small improvement is that when you run a query with a subquery, the default selection window is an external query, not an internal one, as before. Internal queries often cannot be executed.
Fixed switch schemes for read-only connections in MySQL .
Code writing
Autocompletion now works for functions returning tables.
Links NEW and OLD are correctly processed for triggers in PostgreSQL.
Added support for MERGE offers.
Supported sequences in scripts.
Rest
Added:
- Database objects can be added to bookmarks ( Bookmarks ).
- File indexing can be stopped and continued at any time.
- Search results in Find in Path with the same lines are combined into one result.
- Support for ALTER FOREIGN TABLE in PostgreSQL .
- Support for the ' json_table ' function in Oracle .
- All attributes are displayed in the generated DDL for Redshift .
Corrected:
- DBE-4600 , the renamed schema is now immediately displayed in the script and in the tree.
- DBE-1288 , renaming sequences in PostgreSQL does not break the query.
- DBE-4507 , you can now create a composite primary key.
- DBE-4637 , requests with GROUP BY no longer report an error that does not exist.
- Scrolling in the data editor has become faster.
And as always: download here , report bugs here , and we also respond on the forum , on Twitter and here in the comments.
Thank!
JetBrains.
Source: https://habr.com/ru/post/334800/
All Articles