1C and ETL
ETL and 1C. Data retrieval
First look
If you, as an ETL specialist, are faced with the need to obtain data from 1C, then this is the first thing you can see when trying to figure out the structure of the database (this is from the MSSQL case, the picture is similar for other DBMS):
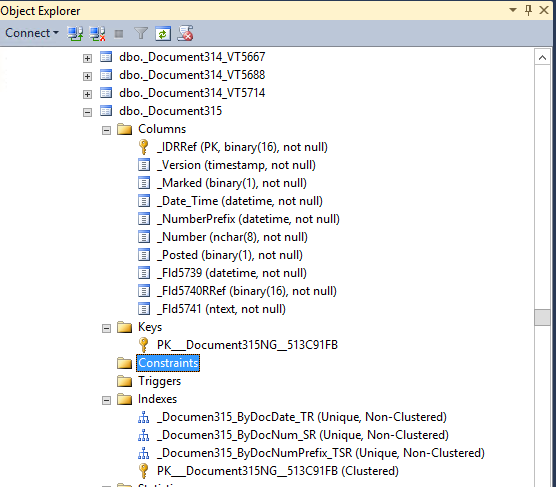
Business meaning in the names of tables and fields is missing, there are no foreign keys.
')
A couple of affectionate about 1C itself. Real DBMS tables in it are hidden behind objects that the developer sees, who often do not know about the real structure of the database. Yes ... And all the code is in Russian. In addition, there are enumerations, the string representations of which using SQL are almost impossible to obtain. More on this here .
There are cases when there is no database (and 1C in the file version), but this, of course, orients you towards integration without using the means of the DBMS.
However, do not despair, because everything is not as bad as it seems.
Attentive look
To capture data from 1C, you have 2 ways:
The implementation of the "high-level" interface
You can use file uploads, web / json services and other 1C capabilities that will be compatible with your ETL.
+
- You do not have to climb in 1C. Everything that 1C should do on the side of 1C
- You do not violate the licensing policy of 1C
-
- There is another source for errors in the form of additional uploads, downloads,
schedules, robotization - This will work significantly slower due to the peculiarities of 1C interfaces.
- With any changes in the captured data, you will have to make changes to the upload (but this can be bypassed by the tuning system)
- This will cause more errors in data integrity than working directly with the DBMS.
Implementation on the DBMS
+
- Faster
- Allows you to guarantee the completeness of data in the repository with the right approach
-
- Violates the license agreement with 1C
So, after weighing the pros and cons, you decide to build integration through a DBMS, or at least
think about how you will do this further.
Data mapping
In order to link business data, as they are understood on the 1C side with real database tables, you need to do some magic in 1C itself, namely, to get a description of 1C metadata in a usable form (in connection of business objects and tables).
Again, there are at least 3 approaches:
- Using the com-connection, web / json service to get the correspondence table from 1
- Do the same on the 1C side by forming a metadata table
- Parse a binary file that is stored in the same database
The third way seems to me somewhat risky due to the fact that 1C has a habit of making changes to its insides without warning. And, at the same time, quite complicated.
The choice between 1 and 2 is not so obvious, but for my taste it is much more convenient to use a pre-formed table, and more reliable in daily use, and there is no need to use something other than pure SQL.
It is more convenient to keep and maintain the relevance of the table using 1C, updating after each configuration update. At the same time, ETL can use View, which will show the data already in a more digestible form.
Preparing a metadata table
Create an object in 1C that contains configuration metadata (unfortunately, the script does not do this, but you can give the 1C instruction to a nickname)
Register of Information. Structure Configurations
Fields:
NameTableStorage
NameTable
Synonym Tables
Purpose
FieldName
SynonymPole
All lines 150 characters
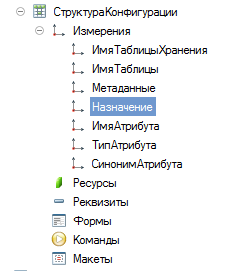
It turns out to be denormalized, but quite comfortable and simple.
Code 1C to fill the structure:
= (,); = ..(); . = .(); . = .; . = .; . = .(.); . = .; . = .; . = .(.); ; ; .(); Again, everything is quite simple and obvious, despite the Russian language. You need to run this code every time you update the configuration. This can be done by hand in processing or with the help of a routine task.
The table can be viewed both in client mode and from SQL, knowing their names.
SELECT * FROM _InfoReg27083 ORDER BY _Fld27085 (_InfoReg27083 - the name that 1C gave the register table with the structure, _Fld27085 - the name of the field with the name of the storage table)
You can make the View more convenient.
If there is no possibility to make changes to the configuration, you can make a table by connecting via com, or adding unloading into the table of the database that is involved in ETL in processing.
And here about what types of tables are, and why they are needed (need access to ITS 1C) .
The next step is to create a data map and description of the transformation.
| Field | Field1c | Transformation | ... |
|---|---|---|---|
| _Fld15704 | Document. Realization of Goods Services. Weight | Check> = 0, round (10,2), ... | ... |
Here we have a mapping table that can be used in further work.
Capture data changes
Now in terms of a strategy for capturing data changes. Here again there are several options. It is easier to take the tables entirely, which of course can cost the server significant additional costs.
However, there are other ways:
- Use object versions
- Use exchange plan
Use object versions
For objects of "reference" type 1C supports version. The version number of the object is written to the _version binary field, which is updated neatly with each record update. In MSSQL, for example, this is a timestamp type field. Versions are supported for objects of the following types: “Document”, “Reference book”, “Business process”, “Task”, “Chart of accounts”, “Plan of types of characteristics”, “Constants”. It is quite simple to use the version, having saved the value of the latest version for the object in the staging area, and on the next update, select objects larger than the version field. Together with the “main” object, you need to remember to pick up its tabular parts (see Purpose - “Tabular Part”) in the structure (field type _DocumentXXX_IDRRef or _ReferenceXXX_IDRRef - link to the main table).
Use exchange plan
For non-reference types, this approach is not suitable, but you can use the “exchange plan” object. In the structure table, their purpose = 'Registration of Changes'. A separate exchange plan table is created for each configuration object.
At the database level, this is a table, such a structure:
_NodeTRef, - the type identifier of the “node” of the exchange plan. It is not very interesting to us.
_NodeRRef, - exchange plan node identifier
_MessageNo, - message number
Next come the key fields of the “main” table. They differ depending on the type of table with which the exchange plan table is associated:
_IDRRef - in this case, the ID of the directory or document
maybe so here:
_RecorderTRef
_RecorderRRef
This will be a table of changes in the accumulation register, information register, subordinate to the registrar, or the accounting register. There can also be a key of the information register table if it is not subordinate to the registrar.
In order for such a table of change registration to exist, you need to include in the 1C configurator the object we need in the exchange plan. In addition, you need to be created node exchange plan, identifier (_IDRRef) which we will need to use.
The exchange plan table can be found in the structure (see above). Since in terms of the exchange, changes are recorded for all nodes, and not just for the storage, we need to limit the selection to the _NodeRRef we need . The exchange plan can also be used for reference objects, but in my opinion it is a meaningless waste of resources.
How to collect data through the exchange plan:
To begin with, we write an update to the exchange plan, where we put an arbitrary _MessageNO (always better 1).
for example
UPDATE _DocumentChangeRec18901 set _MessageNO = 1 WHERE _NodeRRef = @_NodeRRefNext, select data from the data table, linking it with the key to the exchange plan table
SELECT [fieldslist] FROM _Document18891 inner join _DocumentChangeRec18901 ON _Document18891._IDRRef = _DocumentChangeRec18901._IDRRef and _MessageNO = 1 AND _NodeRRef = @_NodeRRefAnd confirm the selection of changes by deleting the change table entries.
DELETE FROM _DocumentChangeRec18901 WHERE _MessageNO = 1 AND _NodeRRef = @_NodeRRefTotal: We learned to read on the side of ETL 1C metadata, learned to perform data capture. The remaining steps of the ETL process are well known. For example, you can read here .
Source: https://habr.com/ru/post/334798/
All Articles