Python Click Generator for Data Engineer
The process of developing an educational program is very similar to the process of developing a new product. And there, and there you try first to understand, and is there a demand for what you are going to produce? Is there really a problem you want to solve?
This time it was pretty easy for us. Several graduates of our Big Data Specialist program for probably a year asked for:
Then the employers began to “fly in” requests, which can be collectively described as:
From this moment it became clear that there is demand, and the problem exists. We must rush into the development of the program!
An interesting point in the development of an educational program is that you do not validate it with a direct potential client. Well, imagine, we approach a person who would like to learn from us, and ask: “Is this what you need?” And he has no idea at all, because he doesn’t understand it yet.
Therefore, the program should be validated, firstly, for those who understand this - real data engineers; secondly, employers - after all, they are the final consumers of our product.
')
After talking with six engineers, some of whom are involved in hiring employees in a team, it became very quickly clear what the main essence of such a person’s work is, and what tasks such a person should be able to solve.
The essence of the work of the engineer’s date is to be able to create pipelines from data, monitor them and troubleshoot, as well as solve one-time ad-hoc tasks on uploading and transforming data.
Specifying, it turned out that he should be able to:
In each of these points you can write a number of different tools. There is even a beautiful visualization on this topic. It was impossible and necessary to cover all of them in the program, so we decided that it was enough for a person to get experience in creating one batch and one real-time pipeline. The rest, if necessary, he will independently master in the future.
But it is important that he learn how to do the “from and to” pipeline so that there is not a single white spot in the process. And then there was a problem for us, as the organizers.
We stopped at the fact that our participants will analyze the clickstream. And we have to figure out how we will generate it directly to them on the sites. The prerequisites for such a decision are as follows:
Great, it remains to think of how. Part of the date engineers suggested that you can look towards the tools for testing the site - for example, Selenium . The part even made a clarification that it is better to use PhantomJS inside it, since it is “headless”, which means it will be faster.
We took their advice and wrote their own user emulator for our member sites. The very not-so-what-code below (important: we will give the same site to everyone, so we can use specific search parameters in the code, knowing the structure of this site):
What have we done? We generate users of different types. Here are two (in fact, more of them): a music lover and a person who wants to understand the grammar. Type selection is randomly selected.
Inside the type, we also implemented an element of randomness: a user of the same type will not follow the same links that we would directly use, and the link will be selected randomly from a subset of the “correct” links + there is also an element of randomness when the user gets to “ wrong links. This was done because in the future, participants will analyze this data and try to somehow segment these users.
In addition, to make it look straightforward like real user behavior, we implemented random timeout on the page. And this gun shoots until we stop it.
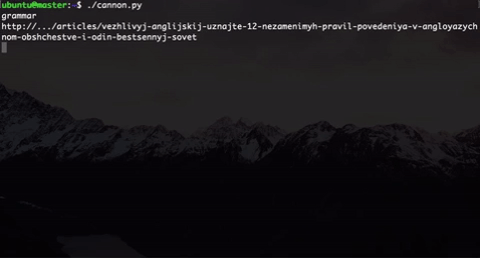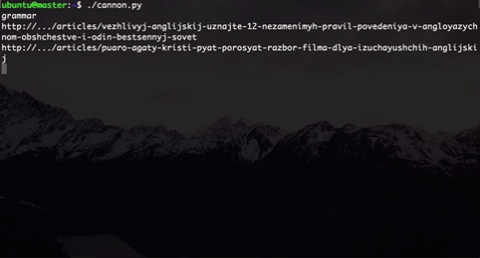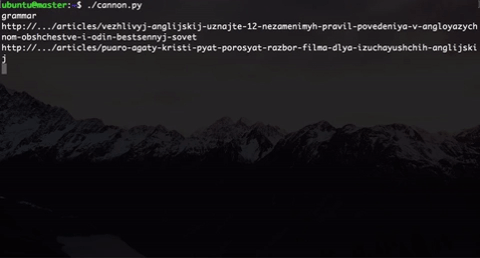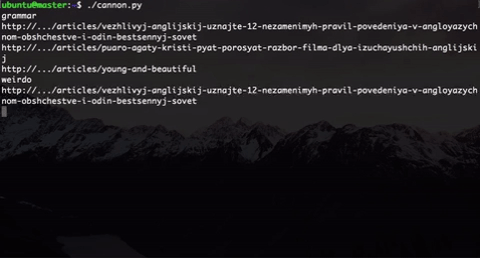
The only thing that a group of 20-30 people with such a gun can not be quickly processed, so we decided to run this script through gnu parallel . This line allows you to run our script in parallel on all available kernels:
So the project begins, on which he will work for 6 weeks on the Data Engineer program .
Prehistory
This time it was pretty easy for us. Several graduates of our Big Data Specialist program for probably a year asked for:
Make for us another program where we could learn to work with Kafka, Elasticsearch, and various Hadoop ecosystem tools to collect data pipelines.
Then the employers began to “fly in” requests, which can be collectively described as:
Data Engineers are very hot jobs!
In reality, we have not been able to close them for half a year.
It's great that you paid attention to this specialty. Now the market has a very large bias towards Data Scientists, and more than half of the project work is engineering.
From this moment it became clear that there is demand, and the problem exists. We must rush into the development of the program!
An interesting point in the development of an educational program is that you do not validate it with a direct potential client. Well, imagine, we approach a person who would like to learn from us, and ask: “Is this what you need?” And he has no idea at all, because he doesn’t understand it yet.
Therefore, the program should be validated, firstly, for those who understand this - real data engineers; secondly, employers - after all, they are the final consumers of our product.
')
After talking with six engineers, some of whom are involved in hiring employees in a team, it became very quickly clear what the main essence of such a person’s work is, and what tasks such a person should be able to solve.
Program
The essence of the work of the engineer’s date is to be able to create pipelines from data, monitor them and troubleshoot, as well as solve one-time ad-hoc tasks on uploading and transforming data.
Specifying, it turned out that he should be able to:
- Collect raw data
- Work with queues and configure them
- Run Jobs with data processing (including ML) on a schedule
- Configure BI
- Work with relational databases
- Work with noSQL
- Work with tools for real-time processing
- Use command-line tools
- Work competently with the environment
In each of these points you can write a number of different tools. There is even a beautiful visualization on this topic. It was impossible and necessary to cover all of them in the program, so we decided that it was enough for a person to get experience in creating one batch and one real-time pipeline. The rest, if necessary, he will independently master in the future.
But it is important that he learn how to do the “from and to” pipeline so that there is not a single white spot in the process. And then there was a problem for us, as the organizers.
Click Generator
We stopped at the fact that our participants will analyze the clickstream. And we have to figure out how we will generate it directly to them on the sites. The prerequisites for such a decision are as follows:
- Since one of the pipelines must be real-time, static ready datasets are not suitable for us, we need to somehow generate data also in real-time,
- Since we decided that participants should build a “from and to” pipeline, this means that they should collect data directly from the site, as they would in real life.
Great, it remains to think of how. Part of the date engineers suggested that you can look towards the tools for testing the site - for example, Selenium . The part even made a clarification that it is better to use PhantomJS inside it, since it is “headless”, which means it will be faster.
We took their advice and wrote their own user emulator for our member sites. The very not-so-what-code below (important: we will give the same site to everyone, so we can use specific search parameters in the code, knowing the structure of this site):
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from numpy.random import choice import time import numpy as np dcap = dict(DesiredCapabilities.PHANTOMJS) dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 YaBrowser/17.6.1.745 Yowser/2.5 Safari/537.36") driver = webdriver.PhantomJS(desired_capabilities=dcap) driver.set_window_size(1024, 768) hosts = ["35.190.***.***"] keywords = {"music": "", "grammar": ""} conformity = 0.9 condition = 1 def user_journey(host, journey_length, keywords, user_type, conformity): driver.get("http://" + host) el = driver.find_element_by_link_text("") # journey el.click() print driver.current_url for i in xrange(journey_length): try: links = [] the_links = [] p = 0 P = [] links = driver.find_elements_by_class_name("b-ff-articles-shortlist__a") # url if len(links) == 0: links = driver.find_elements_by_class_name("b-ff-mobile-shortlist__a") # , if len(links) == 0: links = driver.find_elements_by_class_name("b-ff-articles-tags__a") # , links[0].click driver.current_url the_links = driver.find_elements_by_partial_link_text(keywords.get(user_type)) # url, the_link = choice(the_links, 1)[0] # url links.append(the_link) # p = (1-conformity)/float(len(links)-1) # url, , conformity P = [p]*len(links) # P[-1] = conformity # 'the link' conformity l = choice(links, 1, p=P) # time.sleep(np.random.poisson(5)) # l[0].click() print driver.current_url except: driver.close # , - while condition == 1: for host in hosts: journey_length = np.random.poisson(5) user_type = choice(keywords.keys(), 1)[0] print user_type user_journey(host, journey_length, keywords, user_type, conformity) What have we done? We generate users of different types. Here are two (in fact, more of them): a music lover and a person who wants to understand the grammar. Type selection is randomly selected.
Inside the type, we also implemented an element of randomness: a user of the same type will not follow the same links that we would directly use, and the link will be selected randomly from a subset of the “correct” links + there is also an element of randomness when the user gets to “ wrong links. This was done because in the future, participants will analyze this data and try to somehow segment these users.
In addition, to make it look straightforward like real user behavior, we implemented random timeout on the page. And this gun shoots until we stop it.
The only thing that a group of 20-30 people with such a gun can not be quickly processed, so we decided to run this script through gnu parallel . This line allows you to run our script in parallel on all available kernels:
$ parallel -j0 python ::: cannon.py Total
- Each participant raises the site we have issued using nginx.
- Sends us the ip-address of your server.
- Implements on all pages of your site javascript to collect clicks.
- Collects data arriving from our gun on his website.
- Sends to Kafka.
- Well, then on the pipeline ...
So the project begins, on which he will work for 6 weeks on the Data Engineer program .
Source: https://habr.com/ru/post/334756/
All Articles