WI-FI in the subway: Catch me if you can. Challenges of configuring dynamic networks

When Wi-Fi only appeared on the first lines of the metro, we realized that we were becoming the hero of Bill Murray from “Groundhog Day”. With the only difference that he woke up every time on February 2, and for weeks we tried to catch trains of at least one branch and pour the same configuration on them. Setting it up manually was a bad idea - the trains went to the depot and stood there for several days.
Doctor, is it treated?
We realized that without an automatic tool, the entire company would do nothing more than catch problem trains and fill configurations. Most of our equipment is from Cisco, and first we wanted to find an existing vendor solution. We tried to configure the Cisco Prime system, but later abandoned it for several reasons:
')
1) expensive licenses for such a quantity of equipment as ours - more than 10 thousand units;
2) RADWIN equipment installed on trains was not supported;
3) standard problems associated with the specifics of our network.
We tried other options, but in August 2014, one Government Resolution was issued, and then it was just necessary to change the approach. It was necessary to completely change the configuration of the train controllers to start the system of mandatory identification.
Then we already had a software development department. Why not implement the necessary functionality by yourself? We need a service that tries to connect to the equipment around the clock until it “floods” the configuration script with it. Neither version nor reference configuration. Only the execution of a specific small script.
Enter into the protocol: telnet / ssh and nuances in command perception
It turned out that I did not pass the CCNA courses in vain. Thanks to them, I knew how to configure Cisco equipment. In addition, I had experience in developing individual services that “communicated” with other applications through the console.
The matter of technology
The equipment of trains is controlled via the console using standard telnet and SSH protocols. Some of the equipment supports monitoring and management via SNMP. Separate pieces of equipment are poorly accessible from the fixed network due to the nature of the network layer, so they can only be reached through the head equipment using CDP
There was no time to search for the ideal solution, and we stopped at the simplest: to automate what the operator manually enters through the console.
This is a general scheme:
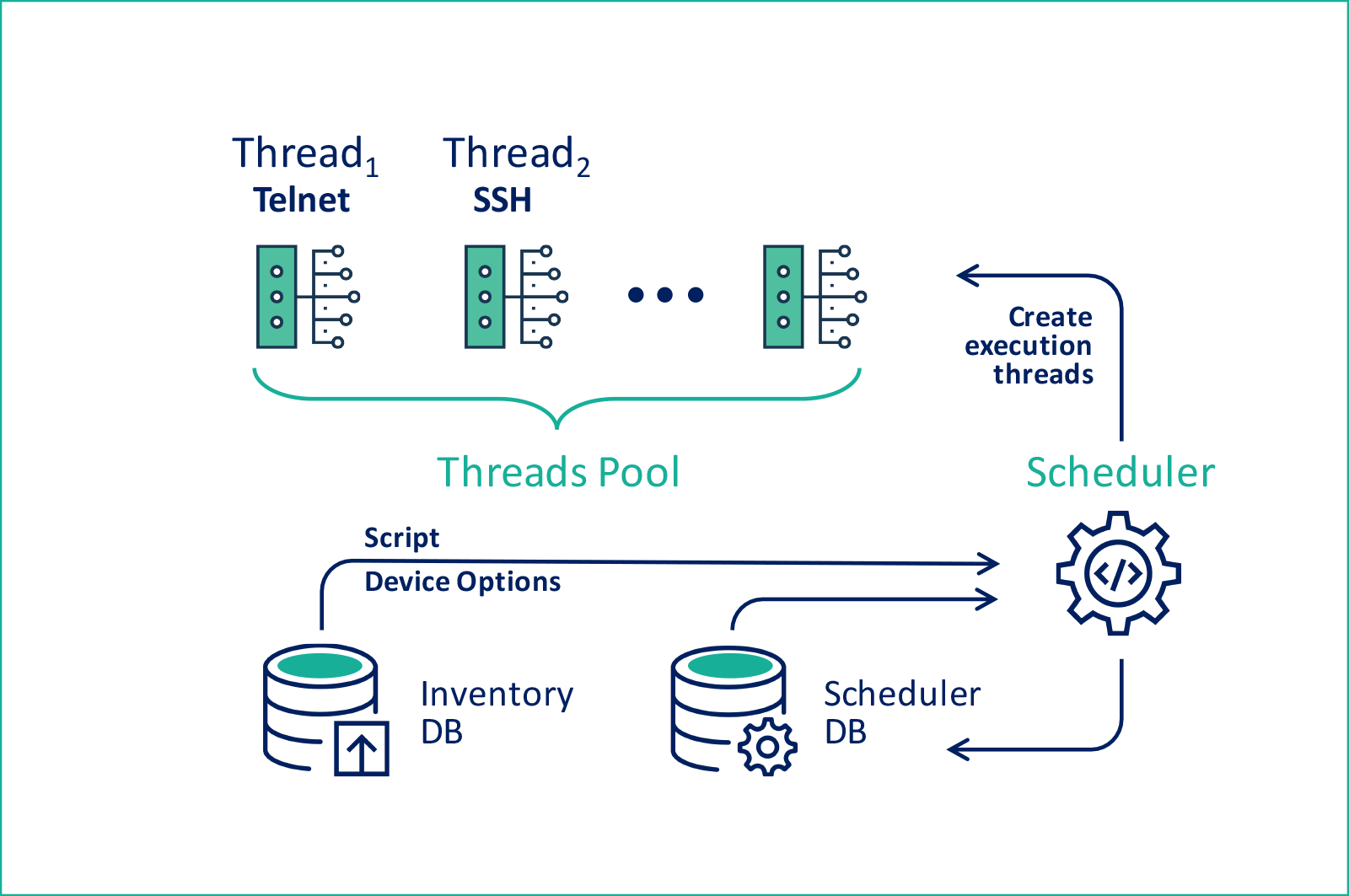
It would seem that the solution is simple, there should be no problems, but no. His work was influenced by the specificity of individual types of equipment.
The matter of technology
For versatility, the telnet / SSH protocol was chosen, but it is impossible to understand exactly when the device has finished “writing” the answer and will wait for input from the user. To solve this problem, we have created our own dictionary of “stop-symbols”. Each command that went to the console had several attributes: echo, response timeout, and a sign that the response was complete. They determined the behavior of the service after sending the command. A sign of completion was a special character following the device name in the console: “>” or “#”
We fly to the base!
At the heart of any configuration management system should be a database of relevant equipment. Since we did not use standard inventory solutions, we decided to form a data structure based on the metro structure that we understand:
1) the equipment is in cars with its type and number;
2) trains are often reassembled from different cars, so the meta-essence of the train is relevant only if it is on the line, and, therefore, in touch;
3) trains run along the lines - there are 13 in Moscow;
4) equipment can be of different types and has different settings.
In addition, we came up with "virtual" trains, and tied to them stationary equipment: base stations in the tunnel, equipment of station nodes and network cores.

All according to plan
We decided to implement the configuration system through the scheduler. In a separate table sets the scripts that you want to apply. They are stored entirely as is, with all the special characters and attributes. To simplify the selection, we tied the scripts to the type of equipment and added a sign of inheritance.
However, when setting up the entire train, a relationship appears between different types of equipment: so as not to lose the availability of controllers when changing the addressing, first it was necessary to set up the train routers and only then controllers. In the scripts, we added a sign of activity and the criterion “to apply only if the equipment is connected” . It was also decided at the service logic level to update the equipment availability parameter when connecting to a given IP address.
Next, we entered a table of tasks that referred to the scripts and also had an activity sign and a parameter field. The key one is the text of the SQL query for selecting the device identifiers to which the configuration should be sent. The use of just such a scheme made it possible, by any indication, to select devices from the database for configuration by the selected script.
Finally, we created tables of events and currently executed tasks . Events referred to tasks and also had inheritance attributes. It was possible to specify what the next event should be executed in case of success or in case of an error, as well as the field of the last event triggering and the specified frequency. Some events had to be triggered in time, and others only as a result, so we introduced extended typing, aligning this field with a sign of inactivity. In the table of current tasks, bundles of equipment identifiers, events and tasks, as well as the last execution time and status attributes were recorded.

Hook for trains
After the data structure was designed, and the overall implementation model became clear, I wrote a program to perform the tasks. It was a two-threaded solution: one thread checked active events in the database and created or changed the corresponding entries in the table of active tasks. The second consistently went through all the active tasks and tried to fulfill them. So the first version of the system appeared.
The matter of technology
I wrote the entire service in Embarcadero RAD Studio version 2010 using Overbyte ICS and Devart Unidac and SecureBridge components. Originally it was a system service under MS Windows, its configuration was stored in a separate file in XML format .
The main disadvantage of the configuration was the speed of work: most of the equipment was not in touch. In addition, due to the peculiarities of the management subnet structure, communication with the equipment took a few seconds. We set the connection timeout from 30 seconds to 2 minutes, and during a day we managed to catch a maximum of 20 trains.
Obviously, the key to improving performance is multithreading. Omit all the difficulties that I encountered in developing a multi-threaded solution (those who tried to do something similar under Windows, know this firsthand). We achieved the desired result, and on a virtual machine with 6 cores, the service could simultaneously process more than 500 pieces of equipment.
The next optimization step was to single out the “easy” task of checking the availability of equipment. I wrote a separate request for all types of “train” equipment and set the frequency every 30 minutes. During this time, either one train leaves the line, or a new one arrives. By including the corresponding criterion in other tasks, I achieved that only units of equipment that were in touch during the last half hour were polled. And in this mode, we lasted long enough until we were faced with the nuances already at the level of operation.
The matter of technology
More than once I tried to recompile a service for a Linux-like OS. True, I did not solve this task, because there was no real need for it. A bare “virtual machine” based on Windows Server 2012 only with this service and a stand-alone “virtual machine” with a database based on MariaDB under CentOS 6 worked so well that there was no point in wasting time on such an improvement.
Exploitation, heartless you ... flour
For several years of the existence of the network, we have created and applied more than 160 scripts: many of them had complex dependencies and the need for consistent application on the same equipment. Basically, we configured Access-Lists and changed the QoS rules, but there were also critical changes related to authorization and DHCP.
As a result, due to the flaws in the configuration system, the trains traveled with equipment that was configured completely differently. Users could easily get into the train, where Wi-Fi did not work only because the devices were incorrectly configured. In most cases, the situation was promptly corrected, but a flurry of requests to the support service for the identified problem left an indelible mark.
Other problems were related to the replacement of physically faulty equipment. The operation changed the equipment to a new one with settings “by default”, which might already be incompatible with the current system of service provision. The autoconfigurator did not correct such errors, since believed that the equipment is configured correctly. Over time, this became a significant problem: users could go on trains without Wi-Fi only for this reason. The decision was the transfer of many scripts and rules into operation, but the human factor has not been canceled, and even though mistakes have appeared less frequently, they were revealed as painfully and for a long time.
SI system: general configuration requirements, hardware version marker
Then we came up with a “reference script,” which brings the hardware configuration to the state we need. And for complete happiness, it was necessary to come up with a method that preserves the configuration label directly on the equipment. For controllers, we began to use empty ACLs. For example, for the version of January 1, 2015, we created an ACL with the name “v2015010101” - this parameter is easy to read, and the implemented storage of script application logs right in the database allowed us to build queries based on information collected from the equipment by service scripts. The final configuration scheme is as follows:
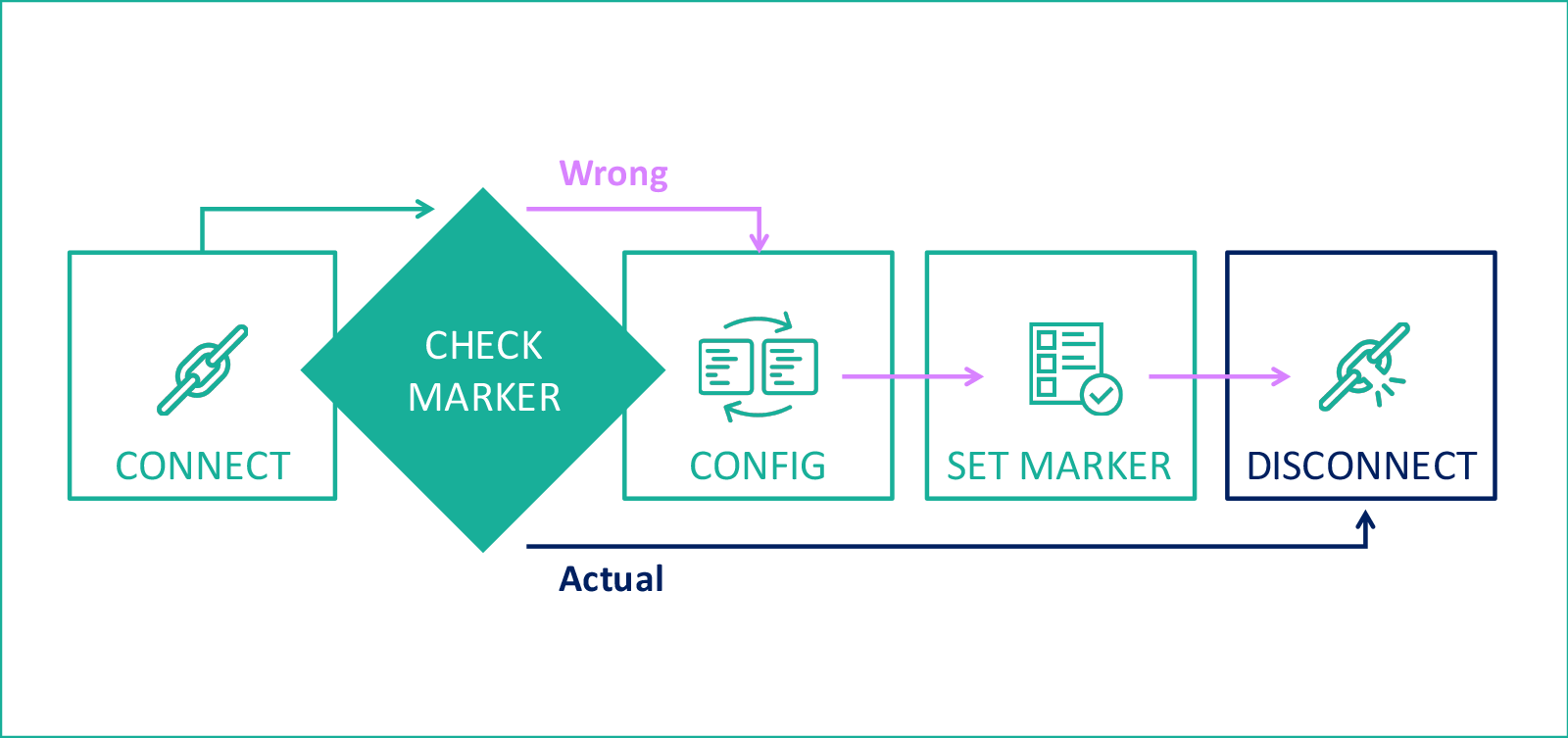
The matter of technology
For routers, we began to use an empty directory on the flash as a marker. In general, the overall structure of the script looks like this:
sh flash:
... check the result for the presence of a marker of the current configuration, if there is no marker, go ahead ...
delete / recursive / force flash: v2016071001
delete / recursive / force flash: v2016101001
... all the old markers are deleted ...
delete / recursive / force flash: v2016111101
conf t
... followed by the main configuration code ...
end
wr
... closes the script, the command to save the new marker ...
mk v2017080101
sh flash:
... check the result for the presence of a marker of the current configuration, if there is no marker, go ahead ...
delete / recursive / force flash: v2016071001
delete / recursive / force flash: v2016101001
... all the old markers are deleted ...
delete / recursive / force flash: v2016111101
conf t
... followed by the main configuration code ...
end
wr
... closes the script, the command to save the new marker ...
mk v2017080101
The introduction of the “reference script” coincided with the formation of the services available before authorization, so the configurations could change several times a week. The developed system could change the configuration of all available equipment in trains in a couple of minutes. At this point, Wi-Fi users completely disappeared for a few minutes, including the SSID of the Wi-Fi network ceased to “shine”.
The bursts also affected the infrastructure: all users who were connected at that moment spontaneously reconnected to the network after the setup was completed. This could lead to a fall in services that are sensitive to the intensity of the increase in load.
As a result, we changed the scheme again. Now the reference script starts every day early in the morning with the opening of the metro and “catches” equipment on trains that just go on the line and turn out to be online. The number of available attempts is configured so that by the time the metro closes, the script stops working. Thus, trains are checked and tuned as they reach the line without significant impact on network users. This solution made it possible to abandon the secondary survey of the availability of equipment and reduced the resource consumption of the auto-configurator by about 5 times.
Better than a swiss knife
In almost three years of use, the service was upgraded four times, the last one when porting to the St. Petersburg metro network. The longest up-time without rebooting was more than six months, and the reboot was associated with the need to update the service itself. With the help of the service, we also configured and updated firmware controllers, routers and radio equipment, as well as configured wagon switches, reloaded tunnel equipment firmware, and even tried to automatically reload interfaces on the equipment of station nodes in case of degradation. The developed system turned out to be so successful that so far no substantial needs have arisen for any new solution.
And we have open vacancies.
Watch them here
Source: https://habr.com/ru/post/334734/
All Articles