Thematic modeling with BigARTM
Introduction
Drew attention to the translation of the publication titled "Thematic modeling of repositories on GitHub" [1]. The publication has a lot of theoretical data and very well describes topics, concepts, the use of natural languages and many other applications of the BigARTM model.
However, a regular user without knowledge in the field of thematic modeling for practical use is sufficiently knowledge of the interface and a clear sequence of actions when preparing text source data. This publication is dedicated to developing software for preparing text data and choosing the development environment.
Installing BigARTM on Windows and preparing source data
The installation of BigARTM is well described in the video of the presentation [2], so I will not dwell on it, I’ll note that the programs listed in the documentation are designed for a specific version and may not work on the downloaded version. The article uses version_v 0.8.1.
The BigARTM program works only on Python 2.7. Therefore, to create a single software package, all auxiliary programs and examples are written in Python 2.7, which led to some complication of the code.
')
Text data for thematic modeling should be processed in accordance with the following steps [4].
- Lemmatization or stemming;
- Delete stop words and words that are too rare;
- Selection of terms and phrases.
Consider how you can implement these requirements in Python.
What is better to apply: lemmatization or stemming?
The answer to this question will be obtained from the following listing, in which the first paragraph of the text from the article [5] is used as an example. Hereinafter, parts of the listing and the result of their work will be presented as they are displayed in the jupyter notebook environment format.
Lemma listing with lemmatize
# In[1]: #!/usr/bin/env python # coding: utf-8 # In[2]: text=u' \ \ \ ' # In[3]: import time start = time.time() import pymystem3 mystem = pymystem3 . Mystem ( ) z=text.split() lem="" for i in range(0,len(z)): lem =lem + " "+ mystem. lemmatize (z[i])[0] stop = time.time() print u", lemmatize- %f %i "%(stop - start,len(z)) Result robots listing on lemmatization.
for practice, very often there is a problem for solving which method of optimization is used in ordinary life with multiple choices, for example, a gift for the new year, we intuitively solve the problem of minimal expenditure while setting quality of purchase
Time taken lemmatize - 56.763000 to process 33 words
Listing stemming with stemmer NLTK
#In [4]: start = time.time() import nltk from nltk.stem import SnowballStemmer stemmer = SnowballStemmer('russian') stem=[stemmer.stem(w) for w in text.split()] stem= ' '.join(stem) stop = time.time() print u", stemmer NLTK- %f %i "%(stop - start,len(z)) Result robots listing:
There are often problems in practice, for which the optimization method in ordinary life is solved with a multitude of choices, for example, for the new year, we intuitively solve the problems of minimal costs while setting the quality of purchases
Time spent stemmer NLTK- 0.627000 for processing 33 words
Listing stemming with Stemmer module
#In [5]: start = time.time() from Stemmer import Stemmer stemmer = Stemmer('russian') text = ' '.join( stemmer.stemWords( text.split() ) ) stop = time.time() print u", Stemmer- %f %i "%(stop - start,len(z)) Result robots listing:
There are often problems in practice, for which the optimization method in ordinary life is solved with a multitude of choices, for example, for the new year, we intuitively solve the problems of minimal costs while setting the quality of purchases
Time spent by Stemmer- 0.093000 on processing 33 words
Conclusion
When time for data preparation for thematic modeling is not critical, lemmatization should be applied using the pymystem3 and mystem modules, otherwise stemming should be applied using the Stemmer module.
Where can I get a list of stop words for their subsequent removal?
Stop words by definition are words that do not carry a semantic load. The list of such words should be made taking into account the specifics of the text, but there should be a basis. The base can be obtained with the brown case.
Listing of getting stop-words
#In [6]: import nltk from nltk.corpus import brown stop_words= nltk.corpus.stopwords.words('russian') stop_word=" " for i in stop_words: stop_word= stop_word+" "+i print stop_word Result robots listing:
and it’s not about me since I’m since it’s all so it’s but you’ll have it, I’ve never had it from me now because of it, if suddenly or not it was him before you again so you after all there then nothing she can they are there where you need it for we you what they were so that without it, if something like that too, then who will be this one for this one almost my order for her now to be where everyone can ever be at last two on the other, even after over the more the one through these of us about all of them to akaya isn’t much three this mine however well it’s my own before this sometimes a little bit better that it’sn’t always like them all between
You can also get a list of stop words in the network service [6] for a given text.
Conclusion
It is rational to first use the basis of stop words, for example, from the brown case, and after analyzing the processing results, modify or supplement the list of stop words.
How to distinguish terms from the text and ngram?
In the publication [7] for thematic modeling using the program BigARTM recommend “After lemmatization, n-grams can be collected from the collection. Bigrams can be added to the main dictionary by dividing words with a special character that is not in your data:
- Russian_post;
- Ukrainian_rod;
- send_cause
- Russian_bolnitsa.
Here is a listing for selecting from the text bigrams, trigrams, fourgrams, fivegrams.
The listing is adapted to Python 2.7.10 and is configured to highlight bigrams, trigrams, fourgrams, fivegrams from text. The "_" is used as a special character.
Listing of getting bigrams, trigrams, fourgrams, fivegrams
#In [6]: #!/usr/bin/env python # -*- coding: utf-8 -* from __future__ import unicode_literals import nltk from nltk import word_tokenize from nltk.util import ngrams from collections import Counter text = " \ \ " #In [7]: token = nltk.word_tokenize(text) bigrams = ngrams(token,2) trigrams = ngrams(token,3) fourgrams = ngrams(token,4) fivegrams = ngrams(token,5) #In [8]: for k1, k2 in Counter(bigrams): print (k1+"_"+k2) #In [9]: for k1, k2,k3 in Counter(trigrams): print (k1+"_"+k2+"_"+k3) #In [10]: for k1, k2,k3,k4 in Counter(fourgrams): print (k1+"_"+k2+"_"+k3+"_"+k4) #In [11]: for k1, k2,k3,k4,k5 in Counter(fivegrams): print (k1+"_"+k2+"_"+k3+"_"+k4+"_"+k5) Result robots listing. To shorten, I quote only one value from each ngram.
bigrams - new_year
trigrams - given_quality_purchases
fourgrams - which_is used_of_optimization
fivegrams- costs_in_already_qualified_qualities_
Conclusion
This program can be used to highlight consistently repeated in the text NGram considering each one word.
What should a program for the preparation of textual data for thematic modeling contain?
More often copies of documents are placed one by one in a separate text file. At the same time, the initial data for thematic modeling is the so-called “bag of words”, in which words related to a particular document begin with a new line after the tag - | text.
It should be noted that even with the complete fulfillment of the above requirements, there is a high probability that the most frequently used words do not reflect the content of the document.
Such words can be removed from a copy of the original document. It is necessary to control the distribution of words in the documents.
To speed up the simulation, after each word the colon indicates the frequency of its use in this document.
The initial data for testing the program were 10 articles from Wikipedia. The titles of the articles are as follows.
- Geography
- Maths
- Biology
- Astronomy
- Physics
- Chemistry
- Botany
- Story
- Physiology
- Computer science
Listing of getting ready for modeling text
#In [12]: #!/usr/bin/env python # -*- coding: utf-8 -*- import matplotlib.pyplot as plt import codecs import os import nltk import numpy as np from nltk.corpus import brown stop_words= nltk.corpus.stopwords.words('russian') import pymystem3 mystem = pymystem3.Mystem() path='Texts_habrahabr' f=open('habrahabr.txt','a') x=[];y=[]; s=[] for i in range(1,len(os.listdir(path))+1): # i filename=path+'/'+str(i)+".txt" text=" " with codecs.open(filename, encoding = 'UTF-8') as file_object:# i- for line in file_object: if len(line)!=0: text=text+" "+line word=nltk.word_tokenize(text)# i- word_ws=[w.lower() for w in word if w.isalpha() ]# word_w=[w for w in word_ws if w not in stop_words ]# lem = mystem . lemmatize ((" ").join(word_w))# i - lema=[w for w in lem if w.isalpha() and len(w)>1] freq=nltk.FreqDist(lema)# i - z=[]# z=[(key+":"+str(val)) for key,val in freq.items() if val>1] # : f.write("|text" +" "+(" ").join(z).encode('utf-8')+'\n')# |text c=[];d=[] for key,val in freq.items():# i - if val>1: c.append(val); d.append(key) a=[];b=[] for k in np.arange(0,len(c),1):# i - ind=c.index(max(c)); a.append(c[ind]) b.append(d[ind]); del c[ind]; del d[ind] x.append(i)# y.append(len(a))# a=a[0:10];b=b[0:10]# TOP-10 a b i - y_pos = np.arange(1,len(a)+1,1)# TOP-10 performance =a plt.barh(y_pos, a) plt.yticks(y_pos, b) plt.xlabel(u' ') plt.title(u' № %i'%i, size=12) plt.grid(True) plt.show() plt.title(u' ', size=12) plt.xlabel(u' ', size=12) plt.ylabel(u' ', size=12) plt.bar(x,y, 1) plt.grid(True) plt.show() f.close() The result is a listing of generating robots of auxiliary diagrams. To shorten, I quote only one diagram for TOP-10 words from one document and one diagram for the distribution of words over documents.

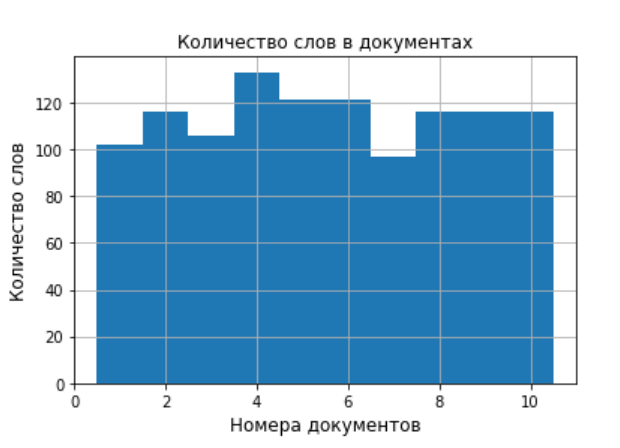
As a result of the program, we received ten diagrams which selected 10 words by frequency of use. In addition, the program builds a diagram of the distribution of the number of words over documents. This is convenient for preliminary analysis of the source data. With a large number of documents, frequency diagrams can be saved in a separate folder.
The result of the robots of the listing on the generation of the “bag of words”. To reduce the results, I cite the data from the created text file habrahabr.txt only according to the first document.
| text of the earth: 3 range: 2 country: 4 perekipely: 2 people: 2 tradition: 2 structure: 2 appearance: 2 some: 2 name: 2 first: 4 create: 2 find: 2 Greek: 3 to have: 4 form: 2 ii: 2 inhabited: 4 contain: 3 river: 4 east: 2 sea: 6 place: 2 eratosthenes: 3 information: 2 view: 3 herodot: 3 sense: 4 cartography: 2 famous: 2 whole: 2 imagine: 2 quite a few: 2 science: 4 modern: 2 achievement: 2 period: 2 ball: 3 definition: 2 assumption: 2 to lay: 2 presentation: 7 to compose: 3 to depict: 2 straitometer: 3 term: 2 round: 7 to use: 2 coast: 2 south : 2 coordinate: 2 land: 16 to dedicate: 2 reach: 2 map: 7 discipline: 2 meridian: 2 disk: 2 Aristotle: 4 due: 2 description: 6 separate: 2 geographical: 12 it: 2 surround: 3 anaximander: 2 name: 8 that: 2 author: 2 composition: 3 ancient: 8 late: 4 experience: 2 ptolemy: 2 geography: 10 time: 3 work: 2 also: 6 detour: 3 your: 2 approach: 2 circle: 2 wash: 3 inland: 2 Greeks: 2 china: 2 century: 6 her: 2 ocean : 3 north: 2 side: 2 era: 3 inner: 2 flat: 2 red: 2 arrianin: 2 which: 8 other: 2 to use: 3 this: 5 base: 3 live: 2
A single textual modality indicated at the beginning of each document as | text was used. After each word, the number of its use in the text is entered through the colon. The latter speeds up both the process of creating a batch and filling out the dictionary.
How can I simplify the work with BigARTM to create and analyze a topic?
To do this, you first need to prepare text documents and analyze them using prepositional software solutions, and secondly, use the development environment jupyter notebook.
The notebooks directory contains all the necessary folders and files for the program.
Parts of the program code are debugged in separate files and after debugging are collected in a common file.
The proposed preparation of text documents allows for thematic modeling on a simplified version of BigARTM without regularizers and filters.
Listing to create batch
#In [1]: #!/usr/bin/env python # -*- coding: utf-8 -* import artm # batch batch_vectorizer = artm.BatchVectorizer(data_path='habrahabr.txt',# " " data_format='vowpal_wabbit',# target_folder='habrahabr', # batch batch_size=10)# batch From the file habrahabr.txt, the program in the habrahab folder creates one batch from ten documents, the number of which is given in the variable batch_size = 10. If the data does not change and the frequency matrix has already been created, then the above part of the program can be skipped.
Listing to populate the dictionary and create a model
#In [2]: batch_vectorizer = artm.BatchVectorizer(data_path='habrahabr',data_format='batches') dictionary = artm.Dictionary(data_path='habrahabr')# model = artm.ARTM(num_topics=10, num_document_passes=10,#10 dictionary=dictionary, scores=[artm.TopTokensScore(name='top_tokens_score')]) model.fit_offline(batch_vectorizer=batch_vectorizer, num_collection_passes=10)#10 top_tokens = model.score_tracker['top_tokens_score'] The program BigARTM after downloading data to the dictionary generates 10 topics (by the number of documents), the number of which is given in the variable num_topics = 10. The number of passes through the document and the collection are specified in the variables num_document_passes = 10, num_collection_passes = 10.
Listing to create and analyze topics
#In [3]: for topic_name in model.topic_names: print (topic_name) for (token, weight) in zip(top_tokens.last_tokens[topic_name], top_tokens.last_weights[topic_name]): print token, '-', round(weight,3) Result robots program BigARTM:
topic_0
plant - 0.088
botany - 0.032
century - 0.022
peace - 0.022
Linney - 0.022
year - 0.019
which is 0.019
development - 0.019
Aristotle - 0.019
nature - 0.019
topic_1
astronomy - 0.064
heavenly - 0.051
body - 0.046
task - 0.022
movement - 0.018
to study - 0.016
method - 0.015
star - 0.015
system - 0.015
which is 0.014
topic_2
land - 0.049
geographical - 0.037
geography - 0.031
ancient - 0.025
which is 0.025
name - 0.025
performance - 0.022
round - 0.022
card - 0.022
also - 0.019
topic_3
physics - 0.037
physical - 0.036
phenomenon - 0.027
theory - 0.022
which is 0.022
law - 0.022
total - 0.019
new - 0.017
base - 0.017
science - 0.017
topic_4
to study - 0.071
total - 0.068
section - 0.065
theoretical - 0.062
substance - 0.047
visible - 0.047
physical - 0.044
movement - 0.035
hypothesis - 0.034
pattern - 0.031
topic_5
physiology - 0.069
thyroid - 0.037
people - 0.034
organism - 0.032
Lats - 0.03
artery - 0.025
iron - 0.023
cell - 0.021
study - 0.021
livelihoods - 0.018
topic_6
mathematics - 0.038
cell - 0.022
science - 0.021
organism - 0.02
total - 0.02
which is 0.018
mathematical - 0.017
live - 0.017
object - 0.016
gene - 0.015
topic_7
history - 0.079
historical - 0.041
word - 0.033
event - 0.03
science - 0.023
which is 0.023
source - 0.018
historiography - 0.018
research - 0.015
philosophy - 0.015
topic_8
term - 0.055
informatics - 0.05
scientific - 0.031
language - 0.029
year - 0.029
science - 0.024
Information - 0.022
computational - 0.017
name - 0.017
science - 0.014
topic_9
century - 0.022
which is 0.022
science - 0.019
chemical - 0.019
substance - 0.019
chemistry - 0.019
also - 0.017
development - 0.017
time - 0.017
item - 0.017
The results obtained generally correspond to the topics and the simulation result can be considered satisfactory. If necessary, regularizers and filters can be added to the program.
Conclusions on the results of work
We considered all stages of the preparation of text documents for thematic modeling. For specific examples, a simple comparative analysis of modules for lemmatization and stemming was carried out. We considered the possibility of using NLTK to get a list of stop words and search for phrases for the Russian language. We consider the listings written in Python 2.7.10 and adapted for the Russian language, which allows them to be integrated into a single progam complex. An example of thematic modeling in the jupyter-notebook environment, which provides additional opportunities for working with BigARTM, is analyzed.
Used links
1. Thematic modeling of repositories on GitHub .
2. Lecture 49 - Install BigARTM in Windows
3. bigartm / bigartm
4. Basics of word processing.
5. Solving linear programming problems using Python.
6. We are testing a new verification algorithm. Questions and suggestions.
7. Using the library for thematic modeling BigARTM.
2. Lecture 49 - Install BigARTM in Windows
3. bigartm / bigartm
4. Basics of word processing.
5. Solving linear programming problems using Python.
6. We are testing a new verification algorithm. Questions and suggestions.
7. Using the library for thematic modeling BigARTM.
Source: https://habr.com/ru/post/334668/
All Articles