Generative models from OpenAI

This article is devoted to the description of four projects , united by a common theme of improvement and application of generative models. In particular, it will focus on teaching methods without a teacher and GAN.
In addition to the description of our work, in this article we would like to tell you more about the generative models: their properties, meaning and possible development prospects.
One of the main activities of OpenAI specialists is the development of algorithms and methods that give computers the ability to understand our world.
')
We rarely think about how much we know about the world in which we live. We know that it consists of three-dimensional environments, from objects that move, collide and interact, from people who walk, talk and think, from animals that graze, fly, run or bark, from monitors displaying information encoded with using a specific language. We know what the weather is now, who won the basketball game, and what happened in 1970.
This is a huge amount of information, to which, in general, it is easy to find a way in the physical world of atoms or in the digital world of bits. It only remains to develop models and algorithms that can analyze and understand this myriad of data.
One of the most promising ways to achieve this goal is the development of generative models. The process of learning a generative model looks like this: a large enough array of data is collected from any area (for example, millions of images, sentences or sounds, etc.), and then the model is trained to generate such data on its own. At the core of this approach is the intuitively found idea that can be expressed by Richard Feynman's famous quote:
"What I can not recreate, I do not understand."
Richard Feynman
The point is that the neural networks used as generative models have a much smaller number of parameters compared to the amount of data on which they are trained. Therefore, to summarize the data, the models are forced to identify and effectively internalize their essence.
Already, generative models find many applications , and in the future they can be used for automated study of categories, parameters and other immediate properties of a particular data set in all their diversity.
Image creation
Consider a specific example. Suppose we have a large collection of images: for example, 1.2 million images in the ImageNet data set . It should, however, be borne in mind that in the future this may be an extensive collection of images or video clips obtained from the Internet or from search robots. If we change the size of each image so that its width and height are 256 (the nominal size), our data set will be one large block of pixels with a size of 1.200.000x256x256x3 (approximately 200 GB). Below are some sample images from this dataset:

These images are examples of what our visual world looks like, and we call them "samples from true data distribution." Now we need to create a generative model that could be trained to generate such images from scratch. In particular, the generative model in this case can be one large neural network that displays the images that we call “samples from the model”.
DCGAN
One of these latest models is the DCGAN network, developed by scientists led by A. Redford (the model is shown in the figure below). This network accepts as input 100 random numbers obtained from a uniform distribution (we call them code or hidden variables , in the diagram they are marked in red) and displays an image (in this case, 64x64x3 images on the right, marked in green). Step-by-step code changes entail corresponding changes in the generated images . This means that the model has studied enough the properties of images to describe how the world looks, and not just to remember some examples.
The network (marked in yellow) consists of standard components of a convolutional neural network , such as layers of deconvolution (the result of the deployment of convolutional layers), fully connected layers, and so on:

DCGAN is initialized with random weights, so a random code connected to the network generates a completely random image. However, it is obvious that there are millions of parameters in the network that we can change, and our goal is to learn how to set these parameters so that the patterns created by the network from random codes look like the data used for its training. In other words, we want the distribution of the model to correspond to the true distribution of data in the image space.
Teaching Generative Model
Suppose we used the just-initialized network to generate 200 images, starting each time with a new random code. The question is how to adjust the network settings to encourage it to create some more plausible samples in the future? And this is not about a simple controlled setting. For these 200 generated images, we have no explicit desired requirements, other than to look like real ones. One of the successful approaches to solving this problem is to follow the algorithm of the Generative adversarial network (GAN). To do this, enter the second discriminator network (as a rule, it is a standard convolutional neural network), which will try to determine whether the input image is real or generated.
For example, you can enter 200 generated and 200 real images into the discriminator network and train it, like the standard classifier, to distinguish two types of images by source. The trick is to apply the back-propagation error method to both networks, the discriminator and the generator, and thus learn how to change the parameters of the generator so that it can complicate the discriminator to recognize its 200 samples. Thus, these two networks come into conflict: the discriminator tries to distinguish real images from fake images, and the generator tries to create images that the discriminator will take as real ones. As a result, the network generator will learn to display images that are indistinguishable for the discriminator from the real ones.
There are several other approaches to comparing these distributions, which we briefly describe below. But before that, we would like to visually present the essence of the learning process on the example of the following animation, which demonstrates samples from the generative model.
In both cases, the network generator starts with noisy and chaotic samples, but over time it concentrates and receives more realistic image statistics:

VAE learns to generate images (logarithmic time)

GAN learns to generate images (linear time)
Amazing spectacle: neural networks are studying what the visual world looks like! Such models usually have only about one hundred million parameters, so the network trained on ImageNet must compress (with losses) 200 GB of pixel data to 100 MB of weights. To this end, the model seeks to identify the most characteristic features of the data: for example, it can find out that the pixels that are nearby can be of the same color, or that the world consists of horizontal or vertical rows of pixels or multi-colored spots. Over time, the model can detect many more complex patterns: certain types of backgrounds, objects, textures found in certain predictable combinations, or gradually transforming into video, etc.
More general wording
In the mathematical sense, it can be a set of examples as samples from true data distribution. In the example below, the blue area shows a part of the image space, which with a high probability (when a certain threshold is exceeded) contains real images, and black dots indicate the points of our data (each of them is one image in our data set). Now, our model already describes the distribution ^ p (x) (green), which is determined implicitly by importing points from the normal (Gaussian) distribution with zero mean value (red) and their mapping in a neural (deterministic) network, i.e. in our generative model (yellow).
Our network is a function with parameters and changing these parameters will change and adjust the generated distribution of images. Our next goal is to find the parameters. that create a distribution that closely matches the true distribution of data (for example, characterized by a small data loss ( Kullback – Leibler divergence )). Thus, one can imagine that the green distribution starts with random values, and then in the process of learning it changes the parameters iteratively and seeks to stretch and shrink it in order to achieve a more accurate match to the blue distribution.
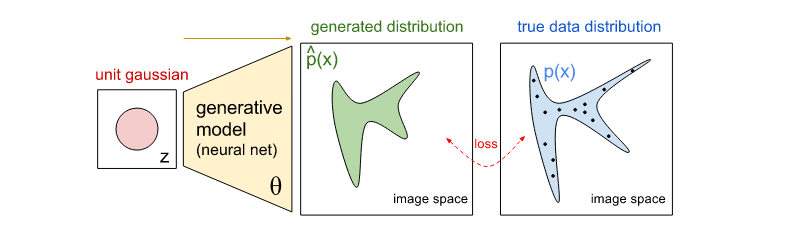
Three approaches to learning generative models
Most generative models are based on the basic principle described above, but they have many particular differences. Next, we will show these differences in three well-known examples of teaching methods for generative models.
In the Generative-Competitive Networks (GAN) , already mentioned above, the learning process is a game between two separate networks: a generator network (see above) and a discriminator network that seeks to determine whether objects are examples from the true distribution of p (x) or model distributions ^ p (x). Each time the discriminator notices the difference between the two distributions, the generator slightly adjusts its parameters to make the difference less noticeable. As a result (theoretically), the generator will learn how to accurately reproduce the true distribution of data, and the discriminator, while checking random samples from the two distributions, will not be able to distinguish them.
Variational autocoders (VAE) allow us to formalize this problem within the framework of probabilistic graphical models , where we maximize the lower bound of the log-likelihood of data.
At the same time, autoregressive models, such as PixelRNN , teach the network to model the conditional distribution of each individual pixel, taking into account the previous pixels (in the direction to the left and up). This process is similar to the inclusion of image pixels in the multi-layer recurrent network char-rnn , but recurrent neural networks (RNN) work with the image not in one direction, but in two - horizontally and vertically.
All these approaches have their pros and cons. In particular, variational autocoders allow not only to carry out training, but also to effectively perform Bayesian output in complex probabilistic graphical models with hidden variables ( DRAW or Attend Infer Repeat can be considered as examples of relatively complex from recently developed models). However, the samples generated by these models are often slightly blurred. The clearest images at the moment can be obtained using the GANs, but they are more difficult to optimize because of the unstable learning dynamics. PixelRNNs are distinguished by a fairly simple and stable learning process ( softmax loss ) and make it possible to achieve the highest logarithmic likelihood today (that is, the likelihood of the data generated). But these systems are relatively inefficient in the sampling process and have difficulty providing codes in low resolution for images. Each of these models represents a promising area of research, and we would like to see how far these studies will go in the future.
OpenAI Development
Generative models are of particular interest to the OpenAI research team. More recently, we have developed four projects designed to contribute to the development of this area of knowledge. The results of each project are accompanied by source code and a detailed technical report.
GAN enhancement ( code ). As mentioned above, GAN is a very promising family of generative models, since GAN, unlike other methods, is capable of generating very clean and clear images and mastering codes containing valuable information about the textures of these images. However, the main principle of GAN is a game that is played by two networks, and this is an important (and difficult) condition for their balance. For example, both networks may have difficulty choosing between two solutions, and the network generator may stop performing its tasks. In this paper, Tim Salimans, Ian Goodfellow, Wojciech Zaremba and their colleagues presented a number of new methods for improving the effectiveness of GAN learning. These methods allow us to scale the GAN and get successful samples of size 128x128 from ImageNet:

Real Images (ImageNet)

Generated images
Our samples from the CIFAR-10 dataset are also very sharp. Amazon Mechanical Turk operators distinguish our samples from real ones with an error rate of 21.3% (for a random guessing, the probability of error is 50%):

Real Images (CIFAR-10)

Generated images
We not only generate beautiful images, but also implement a new approach to semi- controlled GAN training , according to which the discriminator produces additional output by identifying patterns marked at the entrance. This approach allows us to obtain the highest level image results from the MNIST , SVHN and CIFAR-10 data sets using settings with a very small number of labeled examples . For example, for MNIST images, we achieve an accuracy of 99.14% using a total of 10 labeled examples for each class for a fully connected neural network. This result is very close to the best-known results of applying fully controlled training methods for networks in which all 60,000 tagged examples are used. This is a very promising achievement, given that the preparation of labeled examples in a practical way can be quite expensive.
The generative and adversary network is a relatively new model (it is only two years old), and we hope that now such networks will develop faster and increase their stability in learning.
VAE enhancement ( code ). In this development, Derk Kingma and Tim Salimans present a flexible and scalable, by computing, method for increasing the accuracy of variational inference. Until now, most autoencoders have been trained using approximate a posteriori probabilities , in which each hidden variable is independent. In recent extensions , attempts have been made to solve this problem by defining each hidden variable by other variables that precede it in the chain. However, this method seems to be computationally inefficient due to the introduced sequential dependencies. The main scientific contribution of this work is called the reverse autoregressive flow (eng. Inverse Autoregressive Flow, abbreviated IAF). This is a new approach, which, unlike the previous development, allows us to parallelize the computation of extensive approximate a posteriori probabilities and make them almost arbitrarily flexible.
The second table below contains examples of images from a 32x32 model. In the first table for comparison, earlier samples from the DRAW model are shown (samples from vanilla versions of VAE looked even worse and more diffuse). The fact that the DRAW model was published only a year ago can be considered another confirmation of the rapid development of research in the field of learning generative models.

Generated from DRAW model

Generated from IAE VAF-trained
InfoGAN ( code ). Peter Chen and his colleagues presented InfoGAN, a GAN extension that studies disentangled and interpreted representations for images. A regular GAN network does the task of reproducing the distribution of data in a model, but the structure and organization of code space is not defined. There are many possible solutions for matching (mapping) a normal Gaussian distribution with images, and the one that you end up with can be complicated and too confusing. InfoGAN provides the code space with an additional structure, adding new goals that involve maximizing the mutual exchange of information between small subsets of view variables and the observer.
This approach gives remarkable results. For example, in the images of the three-dimensional faces shown below, we change one continuous parameter of the code, leaving the rest unchanged. Of the five examples given (for each line), it can be seen that the resulting parameters in the code take into account interpretable dimensions, and that the model may already be aware of the existence of different shooting angles, facial expressions, etc., although no one has reported the existence of The importance of these differences:
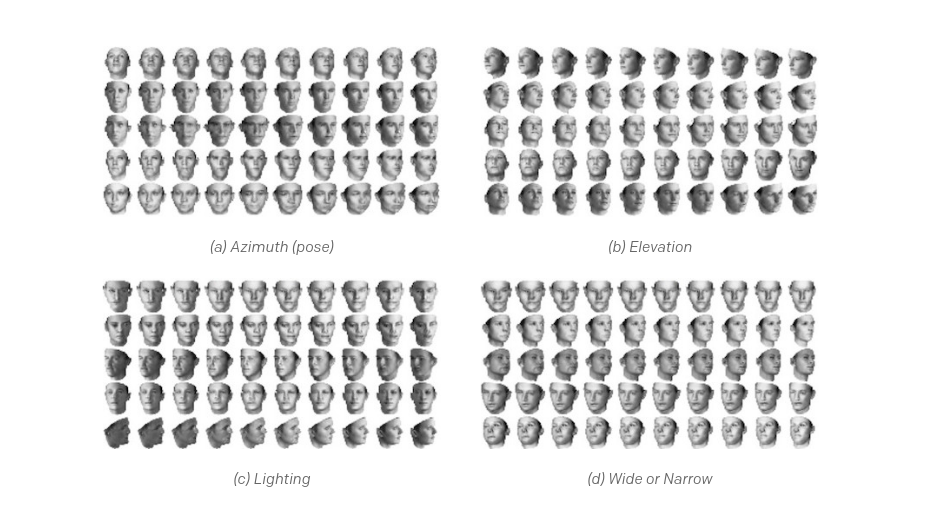
It should also be noted that it was possible to obtain clear, separated representations of images even earlier (for example, in the DC-IGN model by T. Kulkarni et al.). But these approaches are based on additional observation, while our approach is implemented as completely uncontrollable.
Two other new projects are devoted to another area of close attention of the OpenAI research team - reinforcement learning (eng. Reinforcement learning) and united by a common interest in generative models.
The research process, based on curiosity, in the methods of deep learning with reinforcement through Bayesian neural networks ( code ). A successful research process in multidimensional and continuous spaces today remains one of the unsolved problems in training with reinforcement. Without effective research methods, agents of our networks fuss around for nothing until they accidentally encounter situations leading to reward. For many simple “toy” tasks, this is enough. But if we want to apply these algorithms to complex settings in real multidimensional spaces, as is customary in robotics, this is not enough. In this article, Rein Huthouft and his colleagues offer VIME, a practical approach to research using uncertainty in generative models. VIME allows an agent to motivate himself independently and actively seek out amazing options for state-of-action. We demonstrate how VIME can improve a whole range of policy search methods and obtain significant results in solving more realistic tasks with less frequent rewards (for example, in scenarios in which an agent should study basic movement methods without getting any indications).

Learning strategies with VIME
Learning strategies through a “naive” research process
Finally, we would like to present an additional fifth project: Generative Adversarial Imitation Learning ( code) , in which Jonathan Ho and his colleagues present a new approach to simulation training . Jonathan Ho accepted the offer to work in the OpenAI team as a summer internship. He did most of this work while studying at Stanford University, but we present the results of his research here as a close subject and a very creative use of GAN in reinforcement learning. A standard reinforcement training scheme usually requires the development of a reward function that describes the desired agent behavior. However, in practice, this can be quite an expensive process and there will be a lot of trial and error on the way to the correct result. At the same time, during simulation training, an agent learns by demonstrating examples (for example, through a teleoperation in robotics), which eliminates the need to develop a reward function.


The most popular methods of simulation training include a two-step process, the first step of which will be the study of the function of remuneration, and the second - the actual training with reinforcement in the form of this reward. Such a process can take a lot of time and, due to its indirect nature, it is difficult to guarantee that the strategy adopted as a result will bring the desired results. The study in question proved that strategies can be directly extracted from the data by combining with the GAN. Thus, the new method can be used to study strategies for demonstrating the work of experts (without remuneration) in such “hard” OpenAI Gym environments as “ Ant ” and “https://gym.openai.com/envs/Humanoid-v1”.
What's next
Generative models are a rapidly growing field of study. , , , , , . : Photoshop ++, (, « »). : «» , , , , training of the neural network in cases where the use of labeled data (labeled data) is expensive.
However, the more important potential of this work lies in the fact that in the process of teaching generative models we endow the computer with an understanding of our world and what it consists of.
Source: https://habr.com/ru/post/334568/
All Articles