Artisto: experience of launching neural networks in production

Edward Tiantov ( Mail.ru Group )
My name is Eduard Tiantov, I am engaged in machine learning in the company Mail.ru Group. I will tell you about the application of video styling using Artisto neural networks , about the technology that underlies this application.
Let me give you a couple of facts about our application:
')
- 1st mobile video styling app in the world;
- Unique video stabilization technology;
- Application with technology developed for 1 month .
Firstly, this is the very first video styling application in the world. Before that, there were only startups like deepart.io - the company still exists and offers, for example, to convert 10 seconds. video for 100 euros. And we offer all users to do it absolutely free of charge online, unlike deepart.io, which do it offline.
Secondly, we have a unique video stabilization technology. We have been working on this for a very long time, because if we take technology for a photo and try to apply it for video, various problems arise that greatly degrade the quality of the video. I will talk about this in detail.
And third, we are just one month from the moment we sat down to develop the technology to the moment when the application came out in the stores. It took only one month, which is quite fast.

Raise your hands, which of you are aware of convolutional neural networks? Quite a lot of people, but still half, so I’ll dwell on this in sufficient detail so that everyone can understand what is happening.
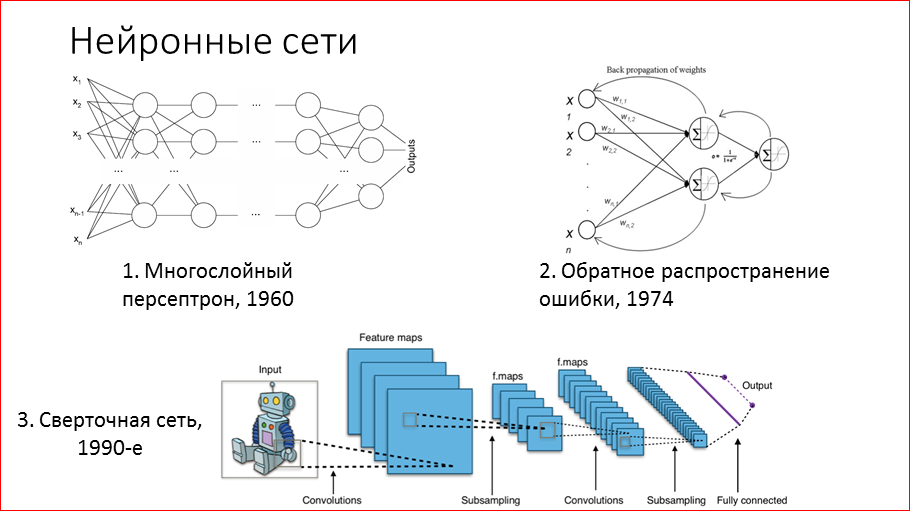
A bit of history. Scientists have been trying to understand how our brain works for quite a long time, and in the 60s they offered a mathematical model called “multilayer perceptron”, where neurons are combined into layers and all neurons are connected with adjacent layers by “each with each” connection. Technically, learning such a network means defining these weights, and such a network can reproduce any dependencies between data.
In the 74th year, we learned how to train them more or less effectively by the method of back propagation of error. This method is used to this day, naturally, with some improvements. Its essence lies in the fact that we take at the output what our network gives, compare it with what should be, with the true value on the sample, and based on this difference, errors, we change the weights in the last layer. And then we repeat this procedure layer by layer, as if spreading the error from the end of the network to the beginning. So these networks are trained.
In the 90s, Yang Li Kun (he is now the head of the Facebook FAIR research laboratory) was actively working on creating convolutional networks. In 1998, he released a paper where he explained in detail how such networks could be used to recognize handwritten numbers on checks, and some banks in the USA applied this technology in practice. But then this technology of convolutional networks did not receive much popularization due to the fact that it was necessary for a long time and it was difficult to train them, and a lot of calculations were needed. The breakthrough happened much later, and I will tell about it.
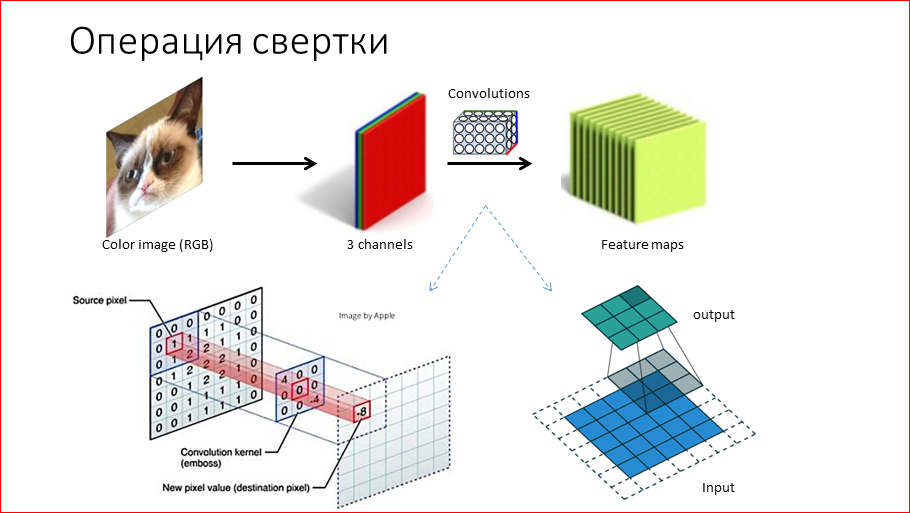
Let's discuss in detail what a convolution network is. It got its name from the convolution operation, oddly enough. Its meaning is as follows - we take an RGB image (or you can gray scale), these are 3 channels, 3 matrices. We run these matrices through convolution. The convolution, as shown below on the slide, is a 3 x 3 matrix in this case, which we move in the image and elementwise multiply the weights on this convolution by the corresponding numbers and add, we get the corresponding positions, certain numbers. It turns out that we converted the input matrix to the output one. This output matrix is called feature maps. And, if you say that the convolution graphically encodes, it encodes some signs on the image. These can be, for example, sloping lines. Then in the feature map we will have information on where, in which places this oblique line is on the image. Naturally, in the convolutional neural networks of these convolutions are very, very many, thousands, and they encode various signs. What is most remarkable about this is that we absolutely do not need to ask them, i.e. they learn themselves in the process of learning.

The second important block is pooling or subsampling. It is recognized to reduce the dimension of the input matrix, the input layer. As shown in the figure, we take a 4 x 4 matrix and take 4 maximum elements each, i.e. we obtain a matrix of 2 x 2. So we essentially reduce, namely 4 times, all subsequent calculations. This also, as a bonus, gives us some resistance to the movement of turns of objects in the picture, because in convolutional neural networks there are many pooling operations. As a result, by the end of the network, the spatial coordinates are slightly lost, and some independence from the position is obtained.
If we see what a convolutional network learns, it will turn out quite interesting. This network studied on the faces:
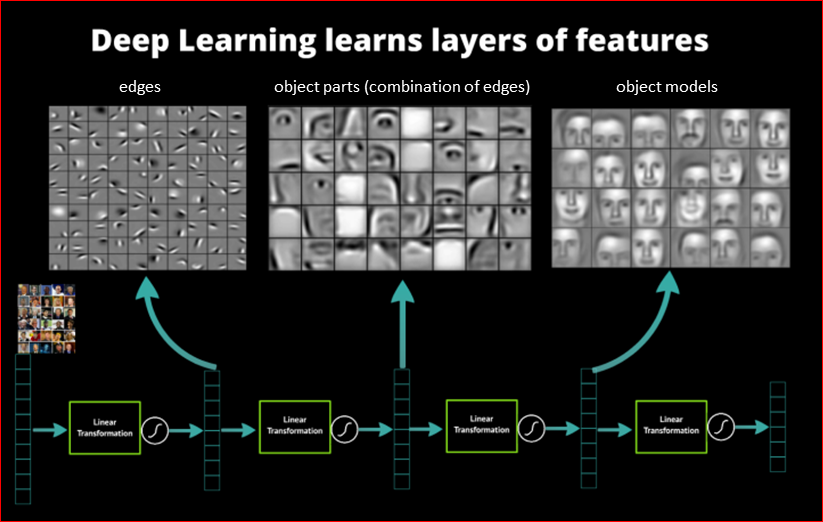
And we can see that on the first convolutional layer the neural network learns the simplest primitives - various gradients, lines, often colors, i.e. base primitives. We know for sure at the moment that our visual cortex of the brain - visual cortex - works in the same way, respectively, the network emulates our brain.
Further. It turns out that as we move through the network, the signs that the network allocates become more complicated and more complicated. Based on the first layer, the second layer already recognizes some parts of the face - eyes, ears, etc. And already the last layer builds whole models of faces. We get the hierarchy of features - the closer to the end of the network, the more complex the objects we can detect on the basis of simpler at first.

The main progress in computer vision occurred within the framework of the ImageNet Challenge. ImageNet is such a base of photos, marked up by hands, there are about 10 million of them. It was specially created for researchers from all over the world to compete and progress in this computer vision.
There is a popular challenge - since 2010, competitions are held annually, there are many different categories and the most popular is the classification into 1000 image classes. Among the classes are many animals, different breeds of dogs, etc. In 2012, for the first time in this competition, the convolutional network won, its author Krizhevsky (Krizhevsky A.) was able to put all the calculations on the GPU, there are quite a lot of them and because of this, he was able to train a 5-layer network. At that time, it was a significant breakthrough, both for convolutional networks and computer vision, because it significantly reduced the error.
The error there is measured by top 5, i.e. the network gives 5 possible categories, which is depicted in the picture, and if at least one matches, it is considered a success. What is very interesting - scientists have measured how many people are mistaken in this challenge. They planted people, gave them the same markup data, and it turned out that the error was about 5%. And modern convolutional networks have an error of about 3.5%. This does not quite mean that neural networks work better than our brains, because they were sharpened specifically for these thousands of classes, and people do not always distinguish the breeds of dogs, and if you plant a person and teach these classes, then naturally it will be better but, nevertheless, the algorithm is very, very close.

Consider the popular architecture. In this case, it is VGG. This is one of the winners of 2014. It is very popular, and popular because the followers trained it posted on the network, and everyone could use it. It looks, it seems, difficult, but in fact it is just a block, each block is convolutional. These are several layers of convolutions and then a pooling operation, i.e. image reduction. And this is how it repeats 5 times, 5 pooling happens. At the end, our convolutions already see an image of 14 x 14, and the number of filters near the end increases. Those. if we first have 32 filters that recognize primitives, then at the end of the network we already have 512 filters that recognize some complex objects, maybe chairs, tables, animals, etc. Further in this network are fully connected blocks that perform purely classification into these 1000 classes based on these features.
This pre-trained network is used in many tasks, because these features that the network highlights can be used in many tasks in computer vision, including for styling photos.
Let's go to this topic. How to transfer the style to the photo?

First, what do we want to be extremely clear? We want to take a photo, in this case it’s a city, and take some style, for example, Van Gogh’s “De sterrennacht” and try to redraw the original content image in this style. And get a piece of art, as they say. It seems incredible, but in the modern world it is possible. Those. we no longer need any artist for this, we can do it.

A little bit of history. In September 2015, Leon Gatis published an article in which he told how to do this, came up with. Its only drawback was that this algorithm was quite slow, and because of this wide practical application for the end user at that time did not receive.
In March 2016, two articles were published with the idea of how to speed up all this processing, and the first of them was our compatriot from Skoltech - Dmitry Ulyanov suggested how this can be done first.
And then after a couple of months Prisma comes out, gets a resounding success, and after a month and a half Vinci is launched from Vkontakte for photo styling, and from us - Artisto for styling video exclusively at that time.
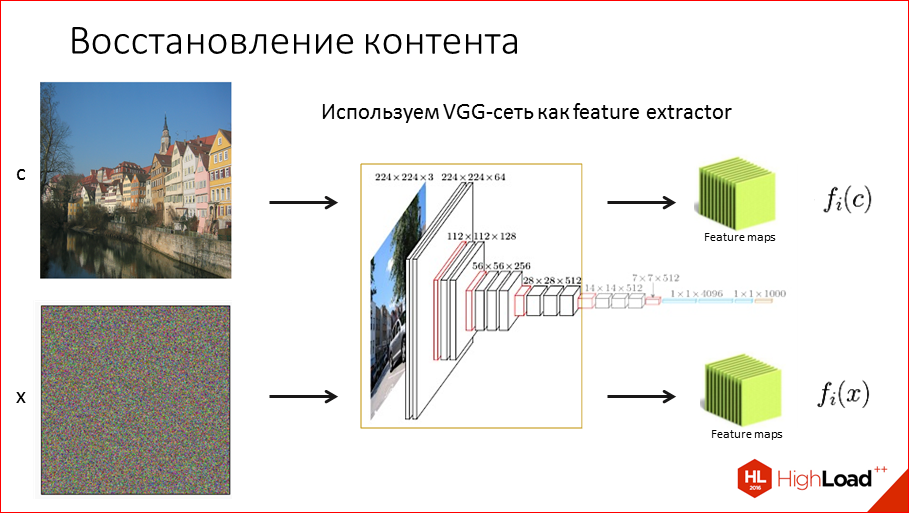
How can all this be done? Let's start with the first article Artistic Style. How do we recover content? Those. we need to mix the content picture and the style one in some way. First we need to try to restore the content. What are we going to do for this? We will take our VGG network, which I mentioned earlier, and use it as a feature extractor, i.e. We will consider it as a way to extract features from the image. We run the picture through this network and get at the output hierarchical information in these feature maps, which tells us that it is located on this image. Accordingly, we can get rid of any other image, for example, noise, get some numbers, these feature maps, and we can already compare them to each other, i.e. Now we can compare pictures numerically.
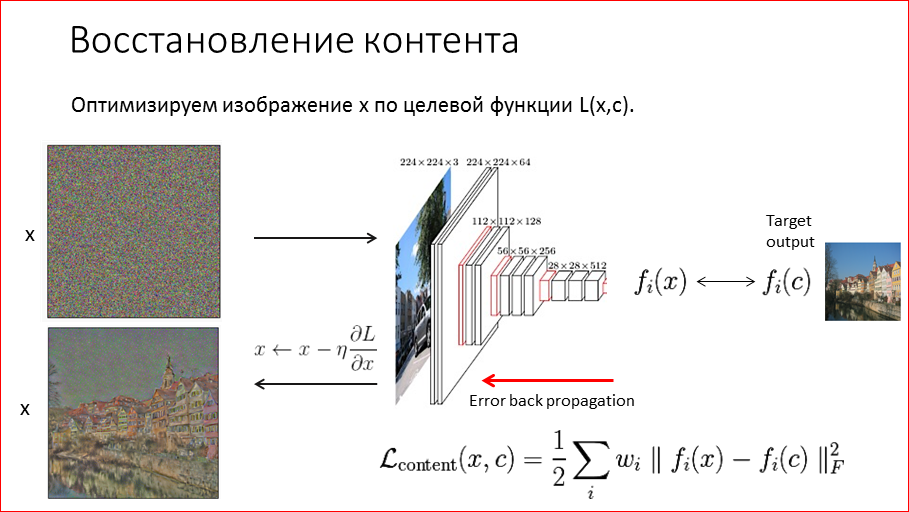
What algorithm proposed Gatis. He proposed such an optimization algorithm - we start with noise, this is our canvas, to which we try to draw a picture that will be similar to the content one. We run it through the network, get the signs and compare how similar they are to the content features of our target image. We measure the error. Naturally, at first it is huge, because nothing worked there on the noise, there are no objects. And this error by the reverse propagation of the error — back propagation is driven by the algorithm over the network. But we do not change the network ourselves, i.e. it is fixed, and the error comes to us in the beginning, in the image. And we replace on the basis of the error at the output the image itself, i.e. redraw. So we repeat n iterations.

And if you look after 1000 iterations, how the restoration takes place, then we see that quite well we were able to restore the original content image using this algorithm. We see, of course, that the colors are lost.
If you look at the last pictures, these are just the last layers, layer 4.2 was taken here, this is one of the last layers. If you look closer, bring the picture closer, you can see that in addition to colors, some spatial coordinates are lost, i.e. floated image borders.

This happened for obvious reasons, because we have pooling in our network, we compress and compress the image, and in the end we know that, for example, the house is located there, but we only approximately understand where it is located in the picture. If you try to restore these layers, it will turn out so inaccurate.
If, on the contrary, to take advantage of the early layers, then there is already almost no information is lost, and everything is restored very well. Here you can figure out that in order to mix the style with the content, we better use the latest layers, which are not so precisely restored, because we don’t need to accurately restore the picture, we need to redraw it in the style.
Moving on to the most interesting, how can you still transfer the style? And what is style in general?
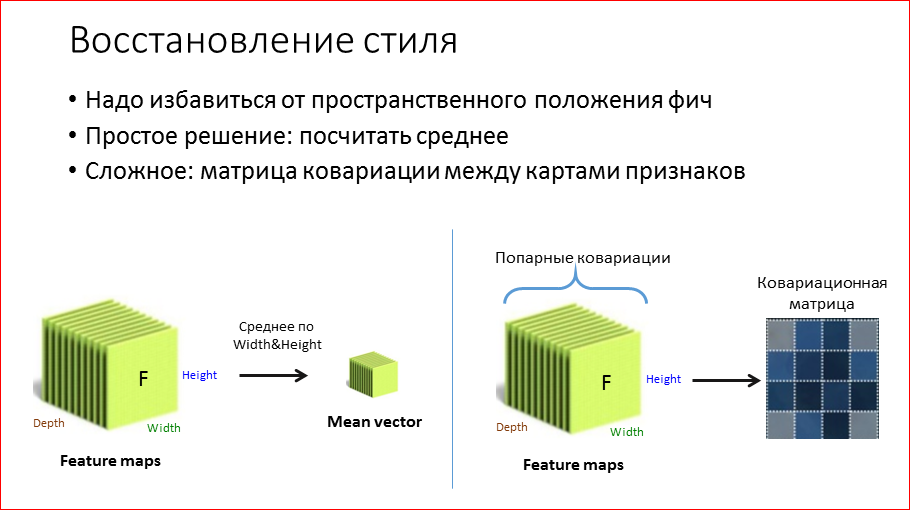
It seems that style is such strokes, colors. That is what I want to transfer. If we take the exact same algorithm and try to restore the style, then we have objects that were in the style image, will be in the same places. Accordingly, the first thing we need to do and, in fact, the only thing is to get rid of spatial coordinates. Naturally, if we get rid of the coordinates, then we can somehow convey the style.
By the way, we posted in open access the video of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, learn, share and subscribe to the YouTube channel .
There are two options for how to do this. More precisely, there are several, I will tell simple, to understand, and difficult.
You can simply take the feature map. We fixed some layer on which we want to restore the style, let's say, some earlier from the 2nd block. We take and average the spatial coordinates. Those. Got such a vector mean. How can this be understood? Those. it will really restore the style, we will see it now. Why will it recover? You can, for example, assume that some of the convolutions, for example, encodes the sign of the presence of a star in the image. We have n stars on “De sterrennacht”, say, 10. If we have only 2 stars in the optimization process, and there are 10 stars there, then comparing these means will help us understand that we need to draw another star, to make the sky more stellar .
A more complicated way is to take and multiply all these feature maps between each other in pairs and get so-called. covariance matrix. This is such a generalization of the variance for the multidimensional case, i.e. in the first case, we had an average, and this, we can assume that the variance. And since Since the dispersion contains information about the relationships between the filters, then experimentally it works better.

And our algorithm does not change much, i.e. we also fix some layer from which we want to restore the style, or layers. We run our style image through the network. We get some kind of feature map, from it we get a covariance matrix and do the same with our canvas, with noise and compare not the feature map, but these matrices. And in the same way we drive the error back. And it turns out well.

What do we see here? This is Van Gogh-style noise. Colors, strokes - everything passed.
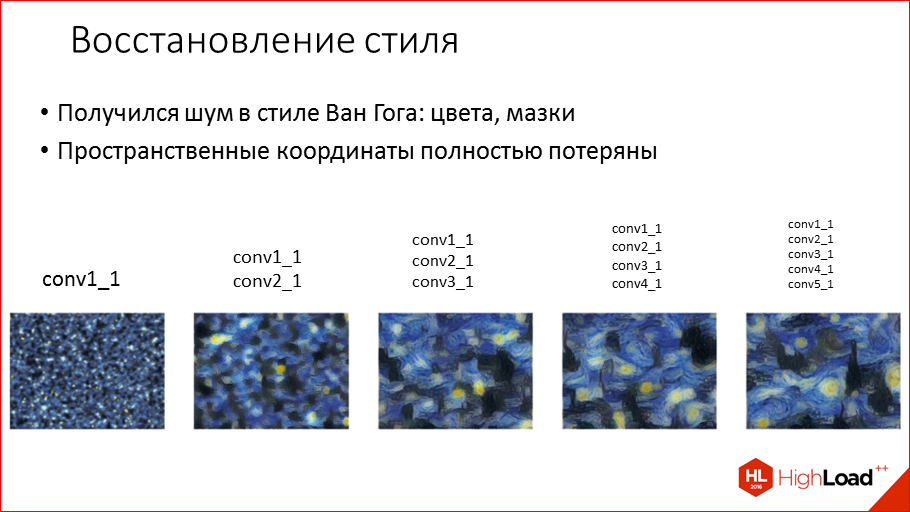
If we play with different layers, we will see that for example, on the 1st layer there is still not enough information about the style, there are only colors: yellow, blue, black. And the further we add layers, for example, if we add the 2nd and 3rd, then there, in principle, the style is very well conveyed. If we add from the last layers that recognize objects, then we will start to get out all kinds of towers, images, but they completely lose their coordinates, of course. But, nevertheless, it is obvious that it is preferable to take from the first layers, which convey precisely the style itself.
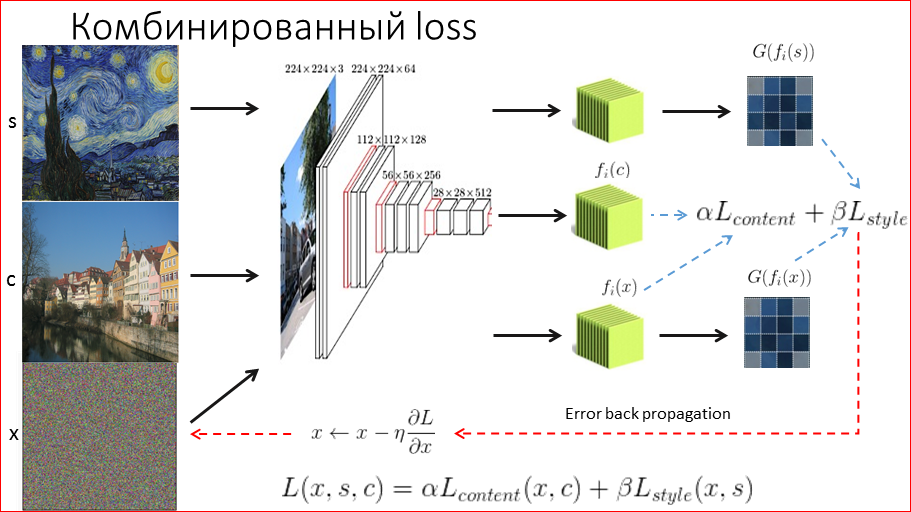
Now that we have 2 technologies for restoring style and content, we’d like to mix them up somehow to better mix these 2 images. How do we do it? Again, we fix the style, we get a covariance matrix from it, remember, right? We take the content image, we retrieve from it feature map, we fix.
And now our noise is chased away, we get both. And in a certain proportion we compare. Those. we compared 2 covariance matrices, 2 feature map, we got some kind of error, we weigh it with some weights, for example, we say that the style is 10 times more important than the content, and we hope that the objects will remain on their places, but will be redrawn in the style we need.

And, about a miracle, it really happens, this picture from the article excited the entire public in deep learning. It was a breakthrough. And it allows you to stylize any image without an artist.

So, if to summarize, then this algorithm allows us to mix any 2 pictures, no matter what. At least 2 photos. It does not require any training, only optimization here, so you can experiment quickly enough, select the necessary parameters and, in general, get some kind of result very quickly. The code on all popular libraries for deep learning is, you can choose any one that is most appropriate. But the biggest fat minus is that all this is very long time calculated for online, i.e. if it is 5 minutes on the CPU, if it is modern on the GPU, then it is about 10-15 seconds. Another photo you can try to shove somehow online, for video - no.
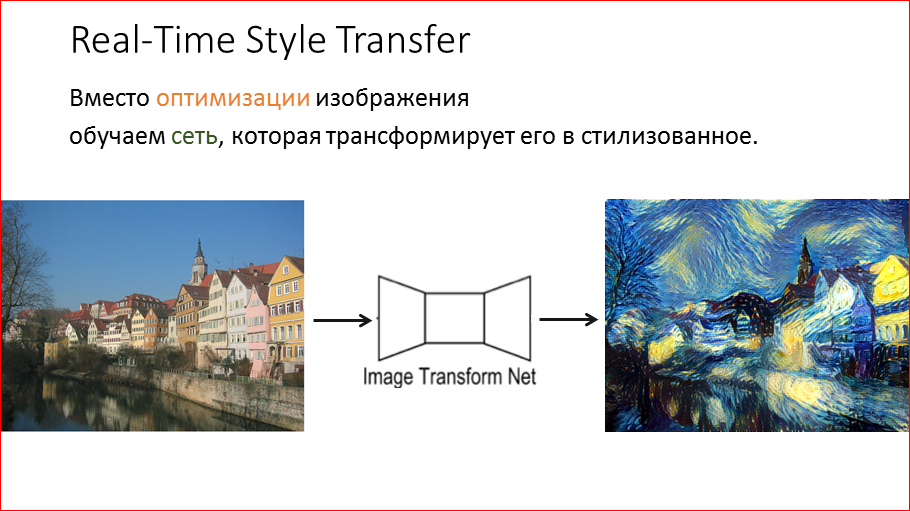
And Dmitry Ulyanov a little later suggests how this can all be greatly accelerated. The idea is simple and elegant - just take and teach the network to stylize any image. Do not engage in any optimization, but simply filed any picture, the network somehow digests it and produces a stylized image.
It sounds easy. How do we do this?
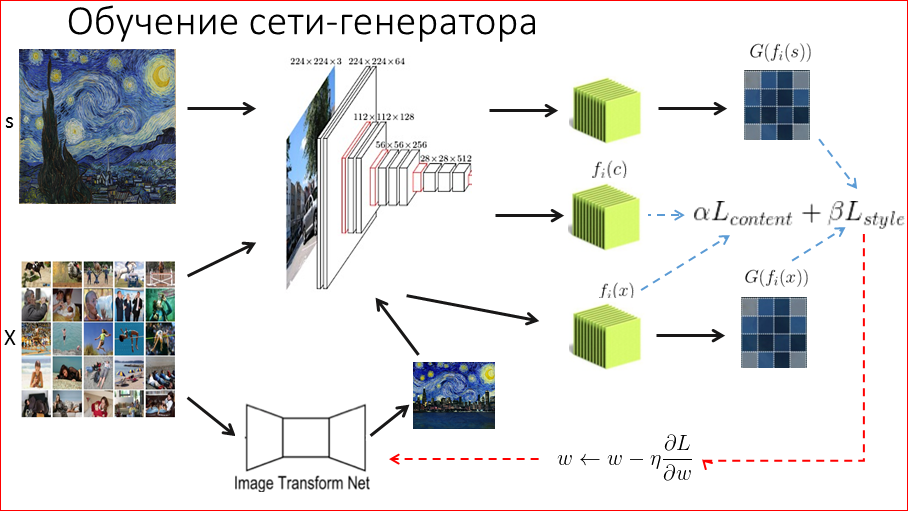
Again, we fix the style image, the covariance matrix of it, the content image and its attributes, and now we have a difference here. We need to stylize any image. Accordingly, we take some dataset, we will train the network. We take a dataset of some kind of photo. It is desirable for our application to take photos that users will actually upload, and not some abstract ones. For example, photos of people - users love to take pictures of people, themselves, there they must necessarily be, in order to be able to draw a network on them specifically. After that, we take some image from this dataset, run it through our new network-generator, or transformational network, which we must style down the image. Initially, when we initialize it, it gives out some noise, but over time it will be trained and produce some kind of stylized image. Since we need to train the network, we need to understand how well it stylizes. We do it the same way - we run this stylized image through the network, get the data we need and compare it with the content and style we want. Again, some proportions. And we run this error back and no longer optimize the image, but we train the network itself. And so we go on this dataset, and after tens of thousands of iterations the network learns to stylize the image.

This is an example from Ulyanov’s article of his network-generator. Here, interestingly, the image is fed to the input of the network in several resolutions, then it is run through a set of convolutions, and we get that the network averages stylization at different resolutions. Such an interesting idea.

And if to summarize, a huge plus is that only 1 run through a trained network is required. On a GPU, this is quite fast, in tens of ms this is measured, depending on the network itself or the input resolution of the picture. This, of course, is not free. We pay for it, because we need to train a separate network for each style, the networks are trained for a long time, but in this task it is still acceptable - several hours, because usually the networks, the same VGG, are trained, for example, a week. Here we have to experiment, and they will need to be carried out a lot, we need a few hours on modern maps. And at the time of how we were developing, the code was only from Ulyanov, it was on Torch, it was a Facebook library, it was on Lua, which is somewhat unusual for machine learning specialists, because everyone is used to Python, mostly. And here a certain threshold is required.
The theory we reviewed, everything seems to be great. Everything should work out. . , .

, , . , «» Google «». , . – , , HighLoad.

(.. ) , - .

Those. , , - , , . , , . , , , , .
. 100 , .. , . , 100 - . : .

Next, we pin our hopes on the creation of Ulyanov - on the neural network, which immediately stylizes. What do we want to take? Take a photo of a girl, take a beautiful mosaic style and get excellent styling. These are our expectations. But they are broken about the harsh reality.

We see that no matter how hard we twist the parameters, no matter how hard we try, the girl either bridges the entire texture, or she bugs the eye, or, in general, some cracks and wrinkles on the face. No matter how much we spin, these are still the best results, they were much worse, believe me.

, .. , -, - , . . , – – . , , . , /, , , . , VGG, , , - , , , , , , , . .

, , , , . , , , .
-, , - , – 1 , , , – . , , .

– . , , , – - . , , «» , – . – . , , , , . .

– . , , , , – , . , , , . -, . , , , loss, .. – , . . – , - . , loss, , . , , . . , .

– .. heatmap loss. - layer, - . - . , 512, , , , . , , , , , . , , , . , , , , heatmap. , loss , , . .

The second.As it turned out, the developer of machine learning can spend a couple of days to bring this style that we need to the ideal, or you can take a designer, take a photoshop and start controlling the style by changing the style image itself. Those. , , . , , , , , , , .
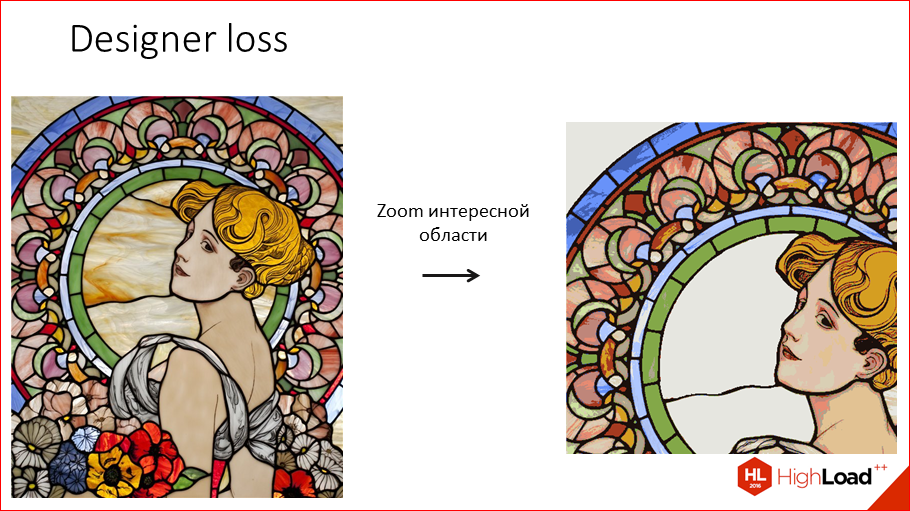
. , , , , , . , , , . .

– , - – , - . , , , 90 , , , , , . -, , , , . , , , , , . , , , , . So . .

, – .. super-resolution. – . , – – , , waifu2x. -, . , , , , , 2 .

, , super-resolution, waifu, . , , , waifu – , , , – , .. . 2 – , , , .

. 3 4- — , , .. , . , -. Forward. ( ).

, , , , , , , , . .
, , .
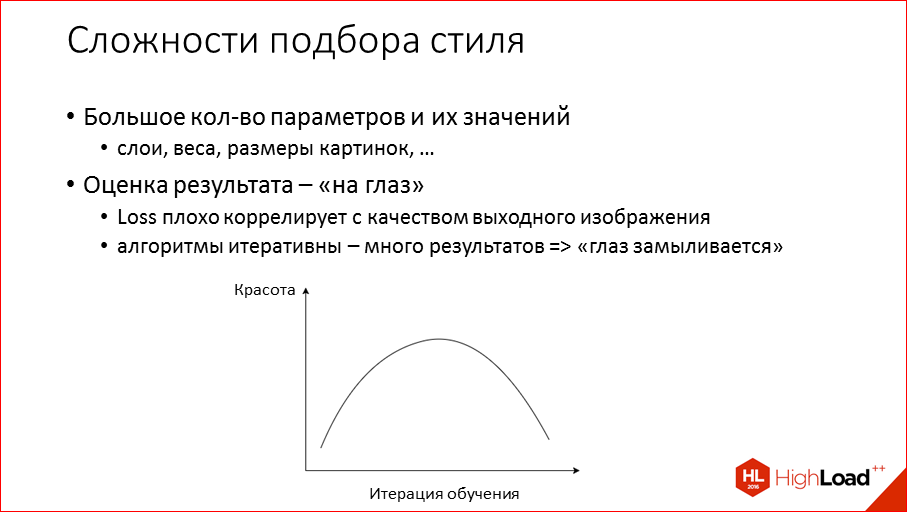
: -, , . , . , , , , , . , , . , , , , -, . , – loss' . - loss' , , . - , .. .
e, , , , , , : «, », : «, , , , ». Those. , .

. , , . FGLab node.js, - , . , .
? - , , , . , - - . . -, , . , - , - .

, - , – .

? , , . -, - . , .. GPU. - 20 , .. , 5. .. - . Redbull – . .
. , USA, .. App Store Play Market 2- , «» 2- .

, . Apple Store 1- iTunes U – , Apple « » , . . - 1- . , , , .. 1- .

– PR- – , nvidia life-, GPU Technology . , , PR.

user experience, . -, , . Those. - , - , . , , , . – , , , , .
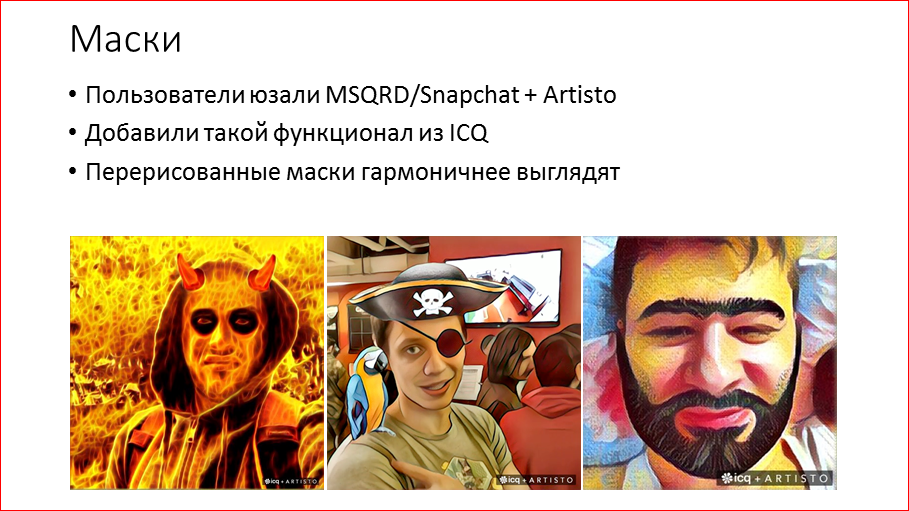
, MSQRD Snapchat Artisto, . ICQ, Mail.ru Group, . . . , , , , - , . .
And in conclusion, I will say that now we live in a time when the computational power of the algorithm allows us to analyze data, train complex networks — this is more and more penetrating into our lives. In deep learning, there is now a boom, this is a really new discovery, there is a lot of introduction of these technologies in the sphere of entertainment such as Artisto and others. But very soon it will be directly in our life in the form of manned vehicles. I’m really looking forward to medicine, when, for example, the network architectures we’ve examined today can be used as is for analyzing MRI, for analyzing ultrasound, they also work fine there. Therefore, I think in the next 5 years, it will already be possible to replace expensive specialists, who are expensive and long to learn, and they are often wrong. Such technology will be able to replace.
If you are interested in convolutional networks, then there is a very good Stanford course on this topic that can be read, everything is written briefly and clearly there. So, if you want to experiment with styling, then you can drive Style Transfer into Google - there will be all the articles, all the code that you can install and try, how it works. I am sure that as a result of my report, now you know for sure that behind these technologies of convolutional networks, in particular styling, there are fairly simple and understandable concepts, there is nothing cosmic, magic there. All these technologies related to neural networks are very interesting to work with, fascinating and, as you saw during my presentation, it is very fun.
Thank you very much!
Contacts
» Mail.Ru Group Blog
— HighLoad++ .
2017- — HighLoad++
. — , !
, AI-, .
Source: https://habr.com/ru/post/334530/
All Articles