What is new in nginx?

Maxim Dunin ( Nginx, Inc. )
Host : I present to your attention the next speaker. Meet - Maxim Dunin. And he will talk about what's new in technology called nginx.
Disclaimer: talk about innovations in 2016. You may think that this is a long time ago, but information about changes in the changelog from the author of these very changes is always useful!
Maxim Dunin : Good afternoon! I'm Maxim Dunin. As you probably know, I am a nginx developer. Today I will read you the changelog out loud and with an expression. To begin with, let's decide which place we’ll read the changelog. Let's look at the statistics.
')

According to W3Techs, there is almost no nginx version left. There are still some comrades who hold on to Debian 6, but there are few of them, we will not rely on them. If you are still using zero versions of nginx, you should upgrade.
The first version is now almost 97%. I sincerely believe that this is good, because when I gave a similar report 3 years ago, everything was very sad, the people somehow sat very hard on old versions, we made a lot of efforts to somehow change this situation.

We look in more detail at what happens in the first version. And we see that in fact 50% of users are already on the current stable 1.10, another 5% are bold enough to use what we use and develop mainline 1.11. The rest, one way or another, have learned that even versions are stable, and somehow they are not in a hurry to update, probably simply because they use what their own distribution kits of operating systems provide and nginx do not really use or know what the new version of and why do they need to be updated.
Today I will tell you why you need to be updated, and what you got, if you have already updated to 1.10 or to 1.11.
To begin with - what appeared in the branch 1.9 and is available in version 1.10.

We have learned, finally, to use the client port in various places, have moved away from the models, that IP's will be enough for everyone, and if you work a lot with clients behind a NAT (which is now probably all), then Real_IP- the module also supports the port, and you can pull it out of the proxy protocol, you can transfer to the backend by hand via X-Real-IP.

The next question is idempotency. Who knows what idempotency is? 3 people in the hall. Cool ... Approximately Igor said this to me when I pronounced the word idempotency.

Idempotency is such a property of an object or operation when repeated to give the same result. From the point of view of http, a GET request is idempotent, because every time the same resource is returned to you, if you make a request not once, but twice, then nothing will change. If you deliberately did not try to violate the http protocol and did not hang up a transaction on a GET request, as most tellers do. For example, any statistics you have are not idempotent as a result, because a repeated GET request counts two hits. But in terms of the standard GET is idempotent. Virtually all http methods are idempotent, except POST from the main standard and two additional LOCK and PATCH methods.
Why is it important? This is important because when nginx proxies somewhere, it has a habit of repeating requests. For nonidempotent requests, this can end badly if your application expects full compliance with the standard. You can protect against this by programming some protection for POST requests to detect duplicates. Probably, you can't even, but you have to defend yourself, because, one way or another, you will most likely have doubles from the browser arrive. But, since we strive to be standard, we made it so that now nginx requests are nonidempotent by default does not repeat and behaves as the standard assumes and since some people are programming.
If nignx has already started sending a request for the backend, an error has occurred, he does not send this request again for POST requests. GET requests are great, because they have the right. POST requests are not sent. If you want to return to the old behavior, this can be done easily using the configuration. You write: "proxy_next_upstream" and add the parameter "non_idempotent".

The next question is a cache entry. We haven’t been recording in nginx for many years, because everything is usually simple with recording. You said OS: “Write data to me in a file”, OS said: “OK, I wrote it down”, and in fact saved it in a buffer and then write it down sometime.
It is not always so. If you have a lot of recordings, you can step on the fact that the OS buffers have run out and your recording is blocked. To prevent this from happening, now nginx can write through thread, if you have a lot of entries in the cache, you can use the aio_write directive to enable entry through thread. While working only through thread. Probably, someday in the future we will do it via posix aio.
Again, the cache has now learned to monitor and preemptively clear the shared memory zone of unnecessary records if it does not have enough memory.

Now you should not see the allocation errors, if suddenly you have a small zone, just nginx will store as much as it fits in the zone. He tried to do it before, but he tried to do it after the fact, i.e. when he could not allocate the next entry in the shared memory, he would say: “Let us try to delete the oldest entry”, delete it and try to allocate again. Usually it worked. If you have a high load, a lot of workflows, it could not work out simply because some other workflow managed to take up the freed up memory. Plus, it takes some time, because it involves deleting the file, respectively, syscall, leaving the disk. I do not want to do this as part of the processing of the request, I do not want the user to wait, now the cache manager can do this.
Programmed dynamic modules, finally.

The main goals that we set - is to simplify the assembly of packages in the first place. because external dependencies of individual modules greatly complicate the assembly and installation of packages. Either you make a certain monster that depends on everything in the system, or you do not include any modules that have bad external dependencies, or you collect many different packages with such modules, with other modules. In terms of packaging, the static nginx assembly is a pain.
By the way, we posted in open access the video of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, learn, share and subscribe to the YouTube channel .
The second goal, which was set, is to simplify debugging, because few people can write good modules for nginx and often, when people come to us with problems, the problem is in third-party modules. Therefore, for many years the first thing that we ask when they come to us with the words: “And my nginx is falling, everything is falling apart!”, We say: “Show us“ nginx –V ”and recommend recompiling without third-party modules and see whether the problem is reproduced. Most likely, it will not be reproduced.

Programmed, now you can quite easily build a dynamic module. For standard modules, this is included with the suffix dynamic. If you build some kind of your own or third-party module, instead of add-module you use add-dynamic-module. And then in the config download.

Modifying your module so that it can dynamically load, rather trivial. We have taken a lot of effort to make it as simple as possible for the authors of the modules, and for all of this to require minimal rework. In fact, you need to change the config-file, if you have it in the old form written to use the script of the auto-module.
If you have a complex module, you still need to make a couple of changes in the internal logic. Nothing complicated - instead of counting modules using your own cycle, you need to call the nginx-function, instead of a global variable with a list of modules, you need to use the list that now appears in the cycle.
The config is altered somehow so.

There was a direct setting of variables with the lists of modules, and there was a call to the script of the auto-module with the parameters supplied for the script. This script itself will be dealt with later - your dynamic module is assembled, the static one is assembled - and it will do everything necessary.
The next question is CPU affinity.

Nginx has long been able to CPU affinity, bin workflows specific processors. It is configured something like this. Those. You set a binary mask for each workflow, the corresponding workflow starts working on those processors that are allowed to it. It worked well when there were 2-processor machines, 4-processor machines. Now, when the machines are 64x-processor, it is already a little inconvenient to configure, because if you want to occupy the entire machine, you have 64 workflows with 64 bits in each mask, you can’t write with your hands. I have seen people who write PERL scripts to do this. We took their pain, made a simple auto pen, which decomposes the workflows of the processors one by one. If there is little automation, you can specify a mask from which nginx will select processors. This allows you to limit this layout to some processor set. If there are fewer bits in the mask than there are nginx workflows, it will simply go around.

Another problem that people occasionally encounter is caching large files. Very large files, when you have 4 GB image or 40 GB image, or multi-gigabyte video. Nginx, of course, knows how to cache such files, but does not do it very effectively, especially when it comes to range requests. If you are sent a range request for something from a 2 GB file, nginx will download the entire file to put it into the cache, put it entirely into the cache and, when it downloads to the second GB, will begin to return the answer to the client. Latency for the client is absolutely beyond the limits. Somehow I want to fight it, but again often only the beginning of the file is needed. On the contrary, if you have some video streaming with a long and boring movie, most of the clients open, download the first few MB of this stream and then close the connection. And you went and downloaded all a few GB, put it in your cache and think that they are necessary.
How to deal with it? One of the possible solutions that assumes that your files on the backend do not change - it is to download in pieces and cache, too, in pieces. We have a slice module that can download and cache in pieces.

It creates consecutive subqueries for ranges of a given size. And we can cache these ranges, small pieces, to cache using the standard cache. When returning to the client, these pieces are glued together. Everything works and caches very efficiently, but again I repeat, all this can be used only in certain specific conditions, when your backend files do not change. If your files change, then it is quite possible that the client has given half of the file, then the file has changed and what to do next? We simply have no second half. Now nginx is trying to keep track of similar situations and close connections, cursing loudly, but in general, if you have one, then you don’t need this module. It is worth using when you just have static on the backend, and you are trying to distribute and cache it.
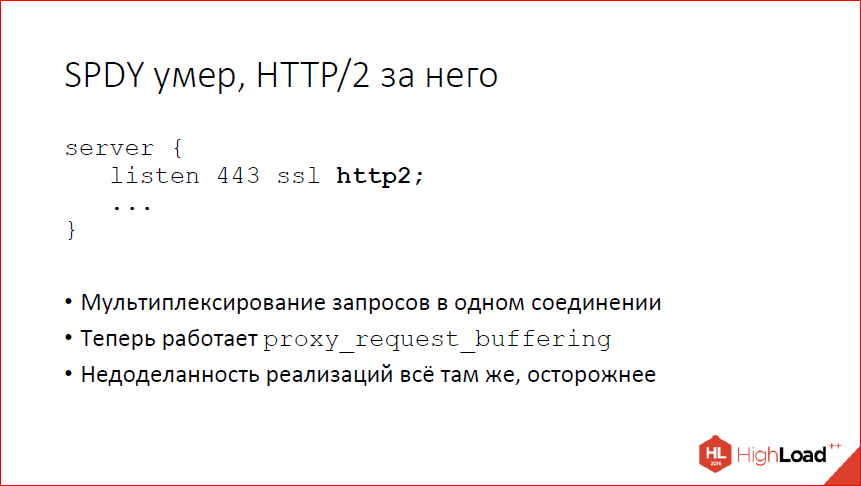
While the court deal, SPDY died, HTTP / 2 appeared instead. There are differences, but small. From the point of view of general logic, the idea is still the same - we multiplex many requests within a single connection, thereby trying to save on establishing connections and saving latency. Somehow it works, it gives something. I can not say that it works well from the point of view that there are a lot of nuances in implementations, the protocol is new, many people do it wrong, including google itself is doing it wrong in chrome. We periodically write tickets to them about the fact that they process this part of the protocol incorrectly, that part of the protocol is processed incorrectly, we build in nginx workaround for all this. Somehow it works, I am personally not a big fan of this protocol, mainly because the protocol is binary, and this is a pain in terms of debugging and development.
Now we are also able to do it normally, even removed some restrictions that were previously in SPDY, from the point of view of implementation in nginx. If you want, you can try to use. Probably, many have already tried and enjoyed. The topic is popular, they say a lot about him.
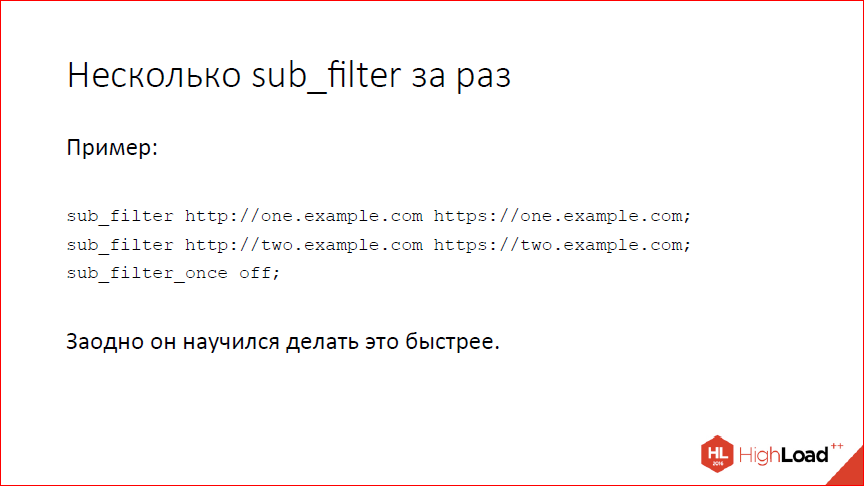
We learned to do several sub_filters at once, at the same time sub_filter was dispersed. We didn’t know how, it was bad, but now we can and it’s good, on the one hand. On the other hand, if you use sub_filter, you probably have something wrong with the architecture again. For highload this is a bad decision.
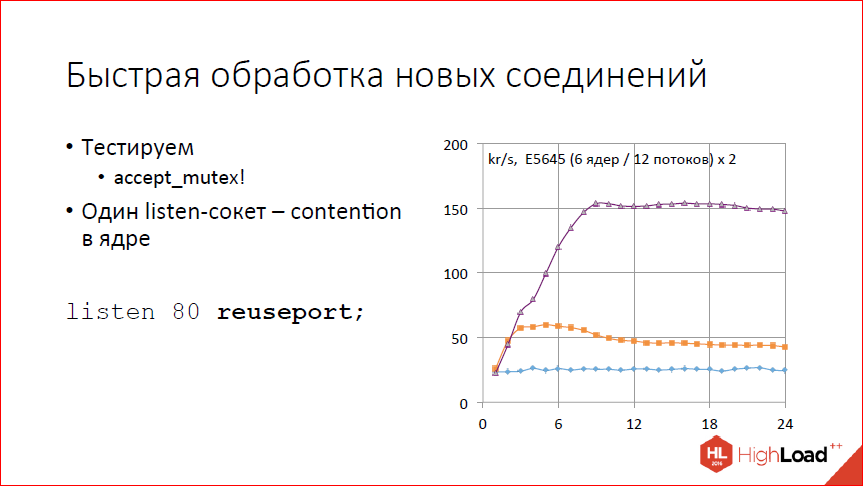
Dispersed slightly processing new compounds. More precisely, they made a handle that allows them to process faster. We look at the schedule. The graph is a test of the number of requests processed per second in thousands of requests from the number of workflows. We see that does not scale at all. Why is that? Because we have accept_mutex enabled by default, and in fact we always have one workflow running. It somehow processes 25 thousand connections per second, but cannot continue, because everything is serialized.
Turn off accept_mutex. We look - somewhere up to 2 workflows, maybe up to 3 scales, 60 thousand requests per second gives out, then everything gets worse with an increase in the number of workflows. Why is that? The processor is not over, but the system began to hurt on the listen-socket. We have one listen-socket, we get contention simply on this listen-socket.
How to solve? Add listen sockets. A simple solution. You can add by hand, spread by IP-addresses, and all you will be fine. If the hands are inconvenient or impossible, the IP address, for example, one, now it can be done using a special reuseport handle. This handle allows nginx to create its own listen-socket for each workflow using the so_ reuseport option.
Works on Linux is not very good, works on DragonFly BSD well, but, unfortunately, an unpopular OS. If you are trying to do this on Linux, it is worth bearing in mind that if you change the number of workflows, you will lose connections. If you reduce the number of worker processes, nginx will close one of the listen sockets. If any connections in this listen-socket are lying, they will close. Linux does not yet know how to redistribute these connections between other sockets.
In terms of performance, what do we get? We get quite good scaling somewhere up to 8 working processes. Then again the regiment. Why shelf? Because the client is on the same machine and eats twice as much as nginx. And when we have 8 processors occupied by nginx, and the remaining 16 are occupied by the client, the machine can no longer - that's all, its processor is over. If you want more, you need to take out the client to any other machines.

Another big thing added is the Stream module. It allows you to balance arbitrary connections without being tied to HTTP. In general, it can almost the same as HTTP, but a little bit simpler, a little smaller. Now we are talking about versions 1.9 and 1.10. Able to balancing arbitrary connections with the same balancing methods as HTTP, Round-robin can, IP hash can. Able to accept SSL from clients, can install SSL to backends. It knows how to limit the number of connections, knows how to limit the speed of these connections, knows how to send the client's address via a proxy protocol to the backend. It can even do a little UDP, but a little bit. You can accept a UDP packet from the client and send it to the backend, and then take back one or more packets from the backend and send it back to the client. If you need, say, to balance the DNS, then, in principle, you can do it with the help of the Stream module. If you have something complicated on UDP, then probably now you will not be happy. But arbitrary TCP connections are able to tail and mane, as you wish.

And all sorts of different things. We taught Resolver to use not only UDP, but also TCP. This allows you to work normally if you have more than 30 A-records, and the DNS response does not fit into the 512 bytes of the UDP packet. In this case, Resolver can now see that there is a bit truncate there and go on TCP to get the full list. If you are balancing using variable names, etc. and use Resolver to recognize lists of backends, it will help you a little. Upstream blocks can now be in shared memory. This allows you to keep a common state between workflows. So if one workflow sees that your backend is dead, everyone else will know about it too. If you have a con-balancing sheet, and you want to minimize the number of connections to backends, then, again, it does not work within one workflow and knows connections only in a specific workflow, but also knows all connections throughout nginx.
Shared memory now works on Windows ASLR versions, i.e. Vista and newer. If you suddenly try to use nginx under Windows, it will help you a little. But I want to note that you should not use nginx under Windows in production, please. It can be very painful. He seriously for this never sharpened.
SSLv3 is turned off by default. If you really need to can be included, but probably not.
Added the $ upstream_connect_time variable, which is a surprise - it shows the time spent on connecting to the backend.
We are able to print the full config on the "-T" key. This, as the practice of our own support has shown, is a very important and necessary feature when you have troubleshuting, and you try to figure out what doesn’t work for a client. People often simply cannot send a full config. They do not understand where to take it. We have automated this process.
And they learned how to deduce the OpenSSL version in the “-V” output. Moreover, they even learned how to display it for a reason, and look at which version of OpenSSL nginx was built with and which one it will work with now. If suddenly you had nginx compiled with one version of OpenSSL, and you are now working with another version of OpenSSL, it will show you.
Actually, more or less everything about the branch 1.9. All this is available in the stable version 1.10.2.

What we have new in 1.11. This is the mainline branch we are developing now. The latest version is 1.11.5. What appeared?

Variables appeared in Stream. In general, Stream is developing intensively. There are modules that can work with variables - map, geo, geoip, split_clients, real ip, access log, the opportunity to return some simple response from variables or just a static return string. You can now do all sorts of strange constructs with the help of maps, limit_conn, to apply the restrictions selectively. In general, almost the same thing that we can do in HTTP.
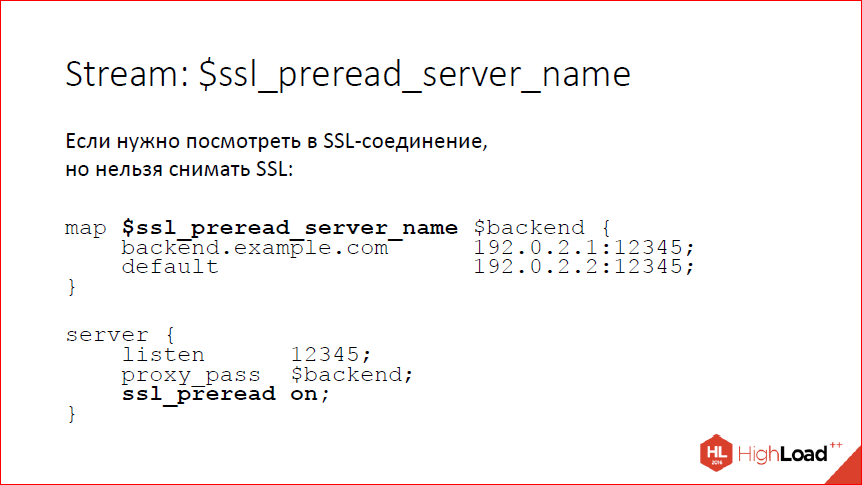
Again, in Stream, we learned to look inside the SSL-connection, while not removing the SSL. Why it may be necessary? You may need to look at the server_name that the client sent, and send the client either to one backend or to another backend. Now we are able to pull server_name out of client_hello. There is a variable for this, it is possible to balance this variable on one or another backend - on the slide an example of how to do this. This should be included explicitly, because by default we, of course, do not expect anything. If we want to wait for client_hello, then we include the directive ssl_preread, nginx will wait and, accordingly, there will be a variable ssl_preread_server_name.

We learned how to limit the number of connections with specific backends, i.e. for each server you can now register max_conns, and nginx will not open more than the specified number of connections to this backend. This was originally done for NGINX Plus. Now we have kept open source just to make people happy, on the one hand, and to carry custom code on the other.

We learned to work in transparent proxy mode. Usually, if you need to transfer the client's address to the backend, you either use HTTP headers with the client's address, or, if we are talking about arbitrary connections, first send the proxy protocol header with the address to the port. This, unfortunately, is not always possible to use, there are people for whom none of this works. There are people who try to use nginx not with their backends, but just somehow to proxy the outside world.
Now you can say “transparent” in the proxy_bind directive, and it will try to make bind with the necessary option for the address that was given to it. Accordingly, if you send there remote_addr, i.e. client's address, she will bind to the client's address. Accordingly, if you built a network so that it all worked, then transparent proxy will work. But for this you need root, for this you need a specially built network. Generally, if you are working with your backends, most likely you should not try to do this. Maybe this is useful with any legacy software that teach understanding X-Forwarded-For or X-Real-IP is unrealistic.
One more thing you have learned ... Who can say how many connections can be made to one backend if we have one IP address? There is a frontend with one IP address. How many connections can I make?

65,535 by the number of ports. Because we have one destination port, and local ports, well, a maximum of 65,535. If we have, respectively, two backends - 128 thousand. If we have 10 backends, then more than half a million connections can be established, this is not a problem.
And now we write “proxy_bind” to the config and specify the IP address. Our half a million ports with ten backends turn back to 65 thousand. Why it happens?This happens because the bind system call is made before the connection, that is, it does not know exactly where we will connect and it must choose the local port. Since where exactly we are going to connect, he does not know, he has to choose a local port so that it can then connect anywhere, and we have 65,000 total local ports. Accordingly, we start to resist 65,000 just by writing in the proxy_bind config ".
How to deal with it?You can fight this. On newer versions of Linux, there is a special option IP_BIND_ADDRESS_NO_PORT, which tells bind not to choose a local port, we will not use it, we swear that we will not and, accordingly, the operating system will not choose it, but will do it as usual in the connect system call, when you already know exactly where we want to connect. This again brings us back our many thousands of connections, even if we use bind.

The next question is accept mutex. What, in general, is accept mutex? This is such a handle to combat the problem of thundering herd. If you have a listen socket and many processes, all processes are waiting for events on this listen socket, i.e. waiting for the client to come. Here, the client comes, all processes are waiting, the kernel has woken up all the processes. The client took one, some one process, and the rest woke up just like that, just spent the processor, they warmed the surrounding air, did nothing useful. The traditional method of struggle is to say only one process, so that it listens and waits for new connections, and let all the rest process the old ones and not worry about new ones.
There is a problem with this approach. Well, firstly, we don’t have so many processes that this is somehow relevant, and, secondly, there are problems. I showed one of the problems a little earlier. If we forget to turn off accept mutex, then in our tests for the number of connections per second we get a shelf that does not depend on the number of working processes, we are very surprised. Well, that is, we are not surprised, because we know what it is, and nginx users are often surprised, write us letters with questions, sometimes outraged, sometimes publish benchmarks about what nginx is bad. Well, in general, we are tired of it - it’s very long to explain and meaningless, the main thing, because there are so few processes, it is quite possible to do without all this.
In addition, accept mutex can not be used on Windows, because on Windows, we have not programmed normal work with sockets. If suddenly you started several workflows and enabled accept mutex, then on Windows everything will just be your stake. More precisely, it will not rise now, because accept mutex on Windows is forcibly turned off and ignored. Even if you try to turn it on, it will not turn on anyway.
When using listen reuseport, accept mutex is not needed, because each workflow has its own listen socket. And finally, on newer versions of Linux, the EPOLLEXCLUSIVE flag appeared in the kernel, which allows the kernel to be told not to wake up all processes, but only one. This is not valid for all programs, because you may have some other activity, i.e. the process will wake up, and he will do something else. In nginx, this works fine. So we accept mutex by default turned off, EPOLLEXCLUSIVE is now supported.

So if you have absolutely fresh Linux, you have not lost anything, you have solid pluses, if you don’t have Linux or something a bit older, then you, in general, have not lost anything either, you have solid pluses, because if you run any benchmarks, you will see the actual behavior of the system, not the accept mutex behavior.
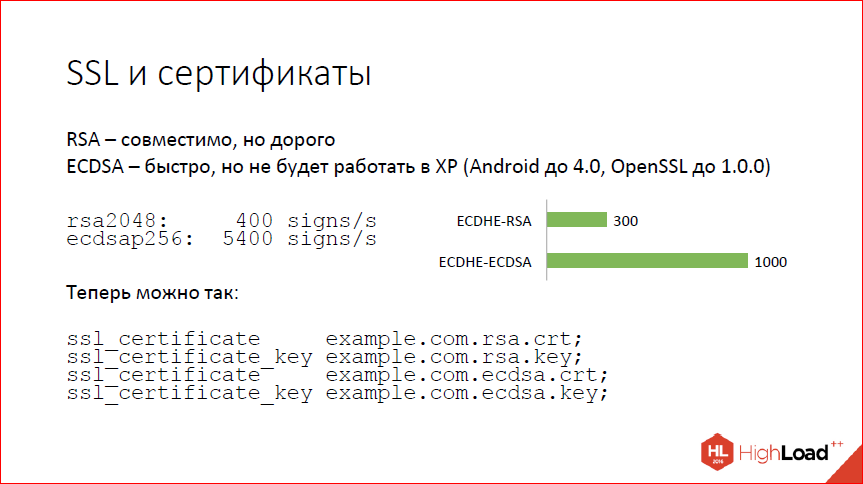
The next question is SSL and certificates. SSL is the kind of thing where most of the time is spent on a handshake. And the handshake comes down to checking the authenticity of the certificate. Certificates are modern - RSA and ECDSA, i.e. on elliptic curves. RSA is good, but expensive, and elliptic curves are fast and, in general, also good, but not everywhere. In particular, does not work on Windows XP. As all sorts of statistics services show, Windows XP is now still between 5 and 10%. So, if you switch to ECDSA-certificates, you will be a misfortune, you will lose 5% of clients. Probably, if you are a big company, you cannot afford it.
What to do?Here are tsiferki (on the slide). We start via SSL speed, we see that the two-kilobyte RSA gives 400 signatures on the kernel, we can do, and ECDSA - 5000 or more, and this is not really the limit. This tsiferki from a fairly old version of OpenSSL. Of course, when you put forward forward secrecy before that, things will get a little worse. On real handshakes with nginx tsiferki are not so impressive, but still 300 handshakes per second in the case of RSA, 1000 handshake per second on the core - in the case of ECDSA. Growth three times.
What we want to get, now we can do this. You can tell nginx: “Here are two certificates for you, work with them,” and nginx will present them as needed to the client. If the customer is new and knows ECDSA, ECDSA will be used, everything will be fast. If the customer is old,then we will use RSA for it.
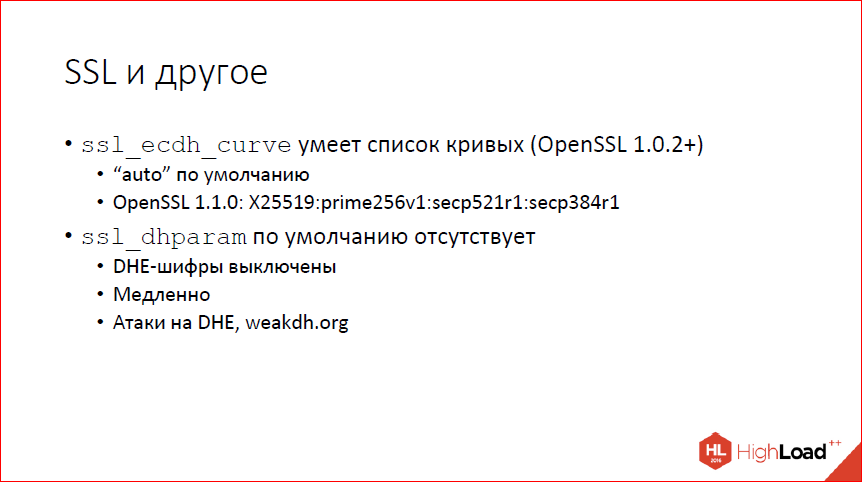
In addition, in SSL you can now set several curves at the same time, if you have quite fresh OpenSSL. By default, if there used to be prime256v1, now the mysterious word is “auto”. “Auto” depends on which version of OpenSSL you are using. In a completely fresh one, there will first be a Bernstein 25519 curve, then the same prime256v1, which was earlier by default. I strongly recommend not to touch, it just makes sense to know that there is such a pen. But do not touch.
dhparam - parameters for Diffie-Hellman ordinary classic. By default, we now do not provide. If previously kilobit parameters were protected inside nginx, now they do not exist, and by default you have DHE codes, i.e. Diffie-Hellman forward secrecy is disabled. This is actually good, because they are slow compared to elliptic curves and there is every reason to believe that there are attacks even on a sufficiently large bit depth, because they are predictable.

There are problems in dynamic modules. In the implementation that is in the stable version now, the problem is related to the fact that the structures in nginx depend on the build option. Nginx, if it doesn’t need something there, it removes something from the structure, allows you to make the structure smaller, and nginx quickly. This leads to the fact that if you assemble a module, then you need to assemble it with the same assembly options as the main nginx where you are going to load this module.
In a package building situation, this works fine. When you build the main nginx and there are a lot of bags with different modules for it, you can control the build options and build everything in the same way. It is not always convenient when you want to add your own module for any arbitrary packages. It is possible, but not always convenient. And, again, for each nginx assembly you have to do your own module assembly. Now we have a special option configure --with-compat, which enables compatibility mode for dynamic loading of modules, and all the relevant fields, regardless of the build options, are present in the nginx structures. Accordingly, modules and nginx become binary compatible, even if you have changed some assembly options, the main thing is that with-compat is among the options, then you can build your module and load it into any other nginx,compiled with the with-compat option too.
In addition, it is now possible to assemble modules like this and load them into our commercial product NGINX Plus. If earlier, because of the same problem, you yourself could not assemble modules for NGINX Plus, because there were other structures inside, now you can assemble your own modules and load them into our commercial NGINX Plus.

And all sorts of different things:
- EPOLLRDHUP on Linux. Now we can rely on it, if we see that the kernel is fresh, it saves syscalls upon detection, and the client has not closed the connection.
- HTTP / 2 improve, supplement.
- Map learned to work with arbitrary combinations of variables and strings.
- For vindictive people, the $ request_id variable appeared, which can be used to identify a specific request.
All this is in 1.11.5. And the development continues.

Fresh nignx can be downloaded from our website. If you are using FreeBSD, you can install from ports, if you are using Linux, then the system packages are likely to be old, although the situation has improved slightly lately. We provide our own assembly. You can take on our site. For modules that have external dependencies, we now have separate packages with external dependencies.
Thanks for attention!
Contacts
» Mdounin@mdounin.ru
» Nginx company blog
This report is a transcript of one of the best speeches at a professional conference of developers of high-loaded systems HighLoad ++ .
Now we are already preparing a conference for 2017, the largest HighLoad ++
in history. If the cost of tickets is interesting and important to you - buy now while the price is not yet high!
Source: https://habr.com/ru/post/334194/
All Articles