Testing in Badoo “from the height of bird flight”

We talked many times about how we write autotests, what technologies we use, how we help developers with unit test performance, and so on. But about the strategy of the entire testing process, including manual, has never been written. It's time to fill this gap.
Testing strategies are different. They depend on many factors: selected technologies, business orientation, application logic, company culture, and much more. What is well suited for embedded systems may not be suitable for mobile applications, and what works well in accounting does not always take root remarkably in the production of aircraft software.
Someone very thoroughly approaches to documenting everything and everyone, someone thinks that the code should be well read and that is more than enough. I would like to say that many are right: if the adopted methodologies and practices work for them in the company, then this is exactly what they need.
We have the same at Badoo: many of the approaches we use work well here, in our culture and in our post-start world, where, due to the explosive growth of the company, we stepped on a bunch of different rakes and stuffed a lot of bumps. I am very pleased that a lot of what we have taken as a basis, for basic values at the very beginning, still works well and scales well.
I will talk about the process on the example of one of the teams - the Mobile Web Team. This is a platform at the junction of the web and mobile, when in the mobile browser we load a full HTML5 application that communicates with the server using a special protocol. By the way, all other Badoo client applications, including the Desktop Web, interact in a similar way with the server.
Firstly, this process is more or less common for all teams that make the product (with a few exceptions), and secondly, with a concrete example, it will be easier for you to understand what I am describing.
Process
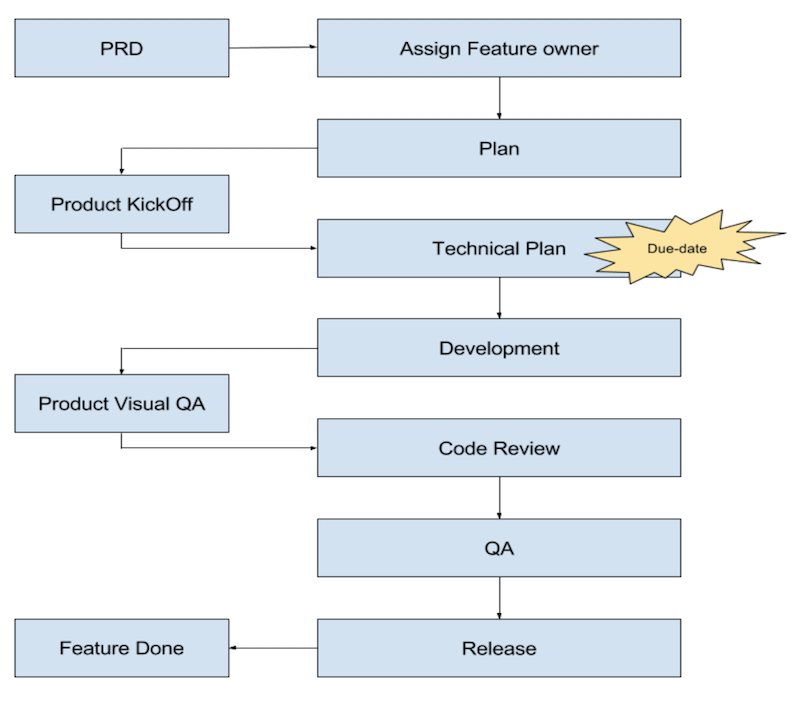
Like many other Badoo teams, the task in Mobile Web starts with a PRD (Product Requirements Document). This is the document that makes up the product manager and in which he describes how the change requested in the design should look like. New functionality, changing the behavior of the existing - to refer to all this, we use the term "feature". PRD contains the design of the interface from the designers, business logic, requirements for analytics after the launch of features and much more. This is the basis of product and product interaction.
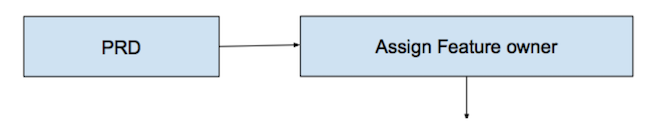
Further, the technical team leader examines the received requirements and gives the document completely or in parts (if the feature is very large) to the developers. From this point on, a feature appears - the owner of microproject manager, who is not only responsible for implementing the functionality, but also for the timing of its implementation and at the same time interacting with other teams if necessary (specifies PRD, design, etc.).
If several people work on a project, then one of them is the microproject manager of development, usually the most experienced one. So that, as they say, seven babysitters have a child without an eye. In general, this is how we try to avoid a situation of collective responsibility. After all, if everyone is responsible for something, it means that no one is de facto responsible.
Before we start developing, we make a plan, this is a general scenario of how the feature will be developed, tested, released, which business metrics may be needed for analysis after launch, what experiments may be needed before the final launch, and so on. This plan is approved by the product at a special meeting, which is called KickOff: it evaluates the overall outline, clarifies and corrects the nuances, if necessary, and gives the green light to the implementation in accordance with the plan.
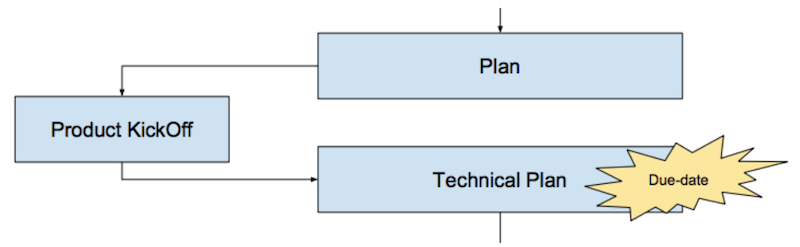
Next, the developer prepares a technical plan (either independently or with the help of colleagues and a manager). This, in essence, is the same plan that was approved earlier, but with clarifications on the technical implementation at each stage: how to optimally combine what is required with the existing functionality, what technologies and mechanisms to use, in what order it will all be released and so Further. It is at this stage that a more or less predictable implementation period appears. Its developer determines himself, agrees with the manager and subsequently tries to maintain it clearly.
Obviously, the term in this case is understood as the date when the new functionality will be available to the user: not “I need three hours for programming”, but “I will lay out the task on the third of August in the morning release”. Naturally, in order to determine such a period, it is necessary to take into account a lot of nuances and communicate with everyone who will take part in the process, think over dependencies (especially external ones), coordinate with other departments on terms and resources, and, of course, check testing time with testers.
At this stage, it is important to know that the technical lead in QA, which estimates the time for testing, gives an estimate of the time required to test one iteration (without taking into account the discoveries), that is, literally: how many man-hours are needed to assess the quality of the current task . Why are we talking about one iteration? It's simple: because we can not predict how many bugs will be and how many times we have to fix them.
It is clear that the term in the remote perspective is difficult to control. Therefore, to fix the current situation, we use the Situation field in the tasks and with different frequency for different teams, we adjust the timing. It is important to remember that when changing or adjusting the deadline, it is necessary to fix that we were forced to do this in order to be able to perform a project analysis later (in retrospect, for example) and give a more accurate forecast next time.
Only after this stage the developer can start programming.
After the developer has completed the implementation of a feature or part of it and believes that it is ready, he organizes Visual QA. This is a special meeting with the product manager, where the developer demonstrates what he did. The product can accept the feature or specify some requirements, if necessary (in this case, the feature is being finalized, and all the steps are repeated once more). At this step, we also guarantee that the developer himself checked at least positive scenarios for using the application and fixed bugs, if any. Otherwise, what will he show the product?
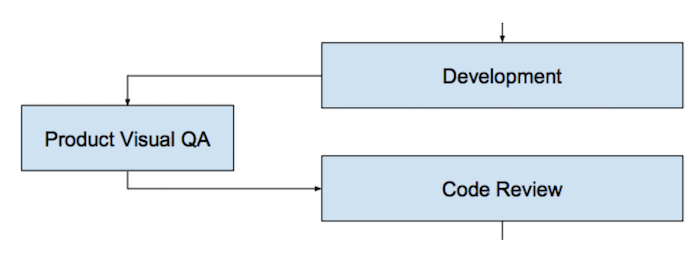
Only after a successful Visual QA with the product, the task is sent to the Code Review. Why not before? Because if the product has additional requirements, we will waste the time of other participants in the process: the reviewer, testers, etc.
Code Review is a very important step in the quality assurance process. At this stage, it is desirable that the developer not only analyzed the code for design and general agreements, but also literally “tested” it with his eyes and head, followed the script programmed by another developer. The extra “straightforward” look helps to avoid so many basic mistakes.
The next step in the process is QA. Testing in our country consists of several stages in different environments and includes manual and automated testing of various levels and elements of the system (I will tell you more about how we conduct testing, below).
And finally, the release features. For many tasks, this is not the last stage, then there may be various improvements, A / B tests, analysis of user behavior and feature optimization. Retrospective and utility analysis features for business and the application as a whole. There are features that "do not take off"; we modify them or remove them from applications, this is normal practice. And those features that have successfully passed all the previous stages become the main functionality of our applications.
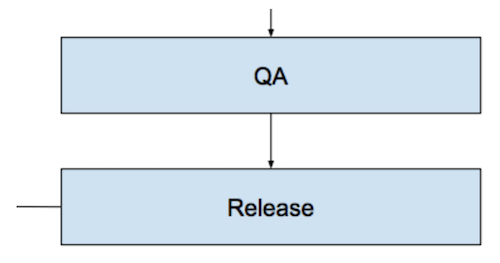
Here is the complete scheme of the described process.
Testing
From the description of the process it is clear what the life cycle of the feature looks like, from what stages it is composed. And, in my experience, most of these stages are understood (plus or minus) correctly by all participants in the process. What PRD looks like, how tasks are distributed, how code-review is done, etc. - this is all understandable, and many use it in their teams.
But when it comes to QA, full discord begins. Different people at different levels sometimes have absolutely fantastic ideas about the work of “these strange guys from QA”. Well, when the situation is understood as "they are doing something there, poking, clicking, and then bringing us bugs." It also happens that the developer himself thoughtfully checks the results of his work and declares: “I don’t need testers - I’m sure of the quality of my product”. But such cases are few.
There have been situations in my practice when developers thought that testers "find too many bugs and prevent us from releasing." It may be that the developer says: “Find me all the bugs, we will fix them, and that's all” or “You check, you know better than me how our product works”. The question immediately arises: how did you write the code then, if you do not know how it works?
In general, few people really understand how the testing process takes place. Let's try to figure it out.
What is quality?
First you need to agree that all the bugs can not be found. This is an axiom with which even the most obstinate individuals agree, common sense cannot be deceived.
If we imagine a “bug chart” in the time interval, then we’ll get something like this scheme:
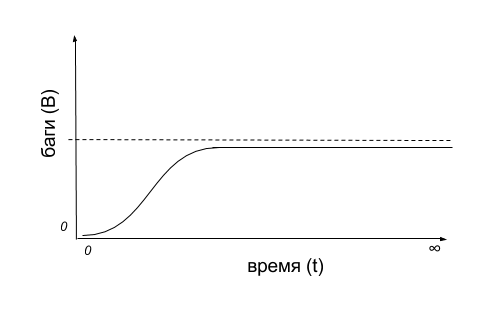
The number of found bugs (B) is small at first - as long as we get acquainted with the system or prepare the environment. Then it can even grow in a unit of time (t), when we found the “sick” part of the application. But then at some point in time, no matter what mechanisms or methods we use, we find less and less bugs. As a result, time goes to infinity, and all system bugs will not be found anyway.
One can imagine a situation where we are not limited in time and possess unlimited resources, but from the wording it is already clear that such a situation is very much synthetic: too many assumptions and the lack of any connection with the harsh reality. In the real world of start-ups and high competition, the majority seeks to get the benefit in the shortest possible time, and the task is most likely put this way: to find as many bugs as possible in the shortest possible time.
There is such an important concept as the speed of finding bugs: S = B / t. It is conditional, but many seek to optimize it immediately. Apparently, because it is intuitive. That is why there are such things as Smoke testing, automated testing (yes, not only for testing regression), tools and methodologies are developed, which make it possible to more accurately identify potentially “risky” places of products ( equivalence classes, for example ). And most importantly, to give as soon as possible the fullest possible assessment of the quality of your product.
And since we immediately agreed that it is impossible to find all the bugs, and we are limited in time, it is obvious that somewhere on the graph there should be an intersection point B and t that would show the current state of product quality in order to answer the question: enough test or need to continue?
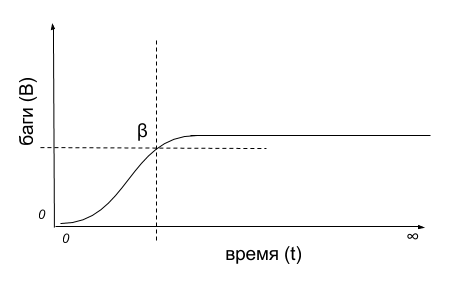
So what is this, this is an ideal value β = ƒ (B, t)?
But it is not, ideal - it is different for all projects. Moreover, it varies from task to task, even within a single, well-coordinated team. It depends on the mass of the external environment, starting with implementation technologies, the culture within each specific team and ending with marketing activities, deadlines and the decision of the customer “Come on, and so it will come down”.
Everything would be even sadder if the minimal “universal” value of β was also unknown. And it is and is formulated easily and clearly to everyone: “The product has a fairly good quality if the user is ready to buy it.” And I mean not only a purchase for money: if the user is ready to use your product, if he is ready to open it again after the fall of the application and continue to use it, then good β has been achieved.
But then already come into force many additional conditions. Does your product have competitors in the market? What category of users will use your product? Are you ready to invest additional funds in perfectionism? Are you waiting for a press conference with a demonstration of your new superidea? When is the increase in load planned? And so on.
Who “makes” quality?
If you noticed, since the beginning of the previous section, I have never mentioned testers. I did it intentionally, because any necessary level of β is quite achievable even in the case when there is no such structure as QA in the company. And there’s nothing to say about the minimum level of quality - the developer must provide it.
In the Mobile Web team, our minimum β achieved is additionally controlled by trickery with Visual QA. Before transferring the task to the next participants in the process, the developer must himself come to the product manager and show him the result of his work. And the first scrupulous user of his product is the customer himself, the one who wrote PRD.
The added bonus of communicating with the product at this stage is that it can cut off something unimportant. For example, for the first launch of a new idea, he may well be ready to try out a concept - a beautiful interface that is not verified to the ideal, to every pixel, but quite acceptable to itself and demonstrates the efficiency of the “semi-finished product” idea. And in the Visual QA process, the readiness criteria can be refined. The main thing is not to forget to reflect this in the PRD, so that the other participants in the process are not surprised at the inconsistency.
When I came to Badoo, we immediately agreed: in our company, developers are responsible for quality. This beautiful principle to this day is regularly reminded of old employees and told by new ones. And in many discussions this argument helps me to convince people at different levels that it is necessary to do this way and not otherwise.
Why developers? Why, then, do we need testers? Let's figure it out.
First of all, testers do not make bugs: either there are bugs in the product, or there are none. You can try to reduce their number by influencing the process, you can improve the engineering culture, use general rules and recommendations (code formatting is a vivid example, no matter how sometimes it seems redundant (tabs or spaces, kekeke). But initially competent planning and architecture of a future project enormously affect the quality of the final product.
But be that as it may, developers directly apply their hands to the code, and it depends on them whether there will be bugs or not. Testers in the following steps can simply find them. And they may not be found, even if they use all the fashionable approaches and the latest versions of the tools.
A tester is like insurance in a circus with an acrobat. Acrobat does all the hard work, spinning on trapezes, and the insurer stands below and does nothing (just like a tester). The acrobat can do his trick without insurance, but with insurance he is much calmer, he knows that in case of an error he will not be allowed to fall. This is what they mean when they say: “We are one team, we work together on the same thing,” etc. The team is one, that’s right, but all responsibility and most important is the decision whether insurance is needed or not. lies on the shoulders of an acrobat. And in our case - on the shoulders of the developer.
In addition, placing the responsibility for quality on the developer, we also avoid a situation that is sometimes very comfortable - to find someone to blame. “Who is to blame?” - “Vasya. Because you did not find my bug. ” In fact, there is no sense to look guilty. From this it will not be easier for anyone - here we need a constructive. A constructive can only be this: what to do next time, so that this does not happen again? And the answer to this question should be given by the developer himself as the source of the problem: what prevented him this time, and how to ensure that the next time this “something” did not prevent him? In this case, the emphasis should be placed on the fact that the solution must be reliable. The decision to “Ask Vasya the next time to be more careful” is a bad one. It does not guarantee anything: we are all human, and the next time Vasya can make a mistake just like now. But the decision to “Cover this section with an autotest” or “Rewrite the method so that it takes parameters of only a certain type” can be very effective.
Thus, testing should be perceived as an indicator, as an additional tool in a rich set of developers who can help him answer the question: is the code ready for display for production or not ready yet? And blaming the protractor for not measuring the angle incorrectly is at least not constructive.
How is the testing process?
So, the task successfully passed all the previous stages of the process and got to testing. What's next? This question often arises not only among people who are not directly involved in testing, but also among the specialists themselves. Especially after some courses in which they talked so vividly about the types of testing, methodologies, black-gray-white boxes, unit-integration-system testing, etc. How to organize checks? Where to begin?
An important issue is also the moment when the task should be returned for revision. After the first bug? Or after the tenth? Or maybe after a complete check of all the scenarios? It is clear that from a business point of view, I also want to keep the value of β at an optimal level (remember: in the minimum time to find the maximum number of bugs?).
Some companies use a fixed set of test scenarios. Some even have test analysts who write these same scripts themselves either by themselves or with the help of other (often less qualified) testers.
Such scenarios look like a sequence of steps and a list of results to which they lead. Often scripts can be in the form of Given-When-Then , but this is optional. Go to such a section of the menu under a user with administrator rights, click on the green button, get such a screen as a result, check that “Hello, world” is displayed on it.
Such an approach can be justified if you are ready to save on the quality of employees. You can recruit people with quite a bit of experience in working on a computer, and in a mobile - even from the street, almost everyone has telephones.
But at the same time, this approach has several disadvantages. Obviously, to ensure optimal β, this approach is even harmful. The passage of scripts is constant for a test session, and with the advent of new scripts in the list, it only increases. In addition, the approach has flaws related to the psychology of the average person: on the one hand, it narrows the angle of vision to what was previously described, and even elementary things start to be missed simply because they are not fixed in the form of scenarios; on the other hand, people have a property, having checked one script, mark similar ones as checked ("I just checked authorization by e-mail, it works. Why should I also check authorization by phone number? There are not a hundred last launches of problems it was never ").
In one of my previous companies, the approach to re-opening tasks was the following: found a bug - send the task for revision. We even had a formal regulation document drawn up by my manager, which contained a list of things, after which the task should be rediscovered:
- Is the code in the task not designed according to coding standards? For revision!
- No unit tests? For revision!
- Unit tests fail? For revision!
- Is the text on the screen worded differently than in the assignment? For revision!
- The interface in the product does not match the layout? For revision!
- ?????
- PROFIT!
This approach is also not optimal in terms of the parameter β. We increase the total time for testing the task due to the fact that each time, after each defect, we add additional developer work time. On context switching from the task in which he is engaged now. While the task is waiting in the queue for other tasks. On another stage is the Code Review. On a lot of other, not always justified, interaction. Well, after the task returns to testing again, it will have to be tested again, which means that all the checks that have already been done are repeated, and this is the testing time. Consequently, the time t required for the entire testing process is doubled, tripled, and so on with each reopening of the task. And if at the same time predefined test scenarios are used, then it’s quite a disaster.
Therefore, in Badoo, we monitor the task reopening counter and try to keep its value decreasing. To rediscover the task is expensive in terms of the time spent by all participants in the process (although if you look at the situation only from the point of view of the testers' comfort, this approach looks very tempting).
But woe to the head, who demands a minimum number of re-discoveries from his subordinates, without explaining the reason. In this case, substitution of targets may work, and instead of eliminating the cause of the disease, we will treat the symptoms. Instead of improving engineering culture and figuring out how to make sure that the next time we don’t step on this rake, we can come to a situation where numbers become an end in themselves. How this affects the work is obvious: the developer is trying to deceive the system. He does not translate the task to the tester, but comes to him with the request a la “Poke or you will pereotkroesh, but they will punish me”, and the β indicator suffers again - testing not only happens opaque, it also becomes controlled complicated. Time t becomes undefined. In general, be extremely careful with this.
In another large and well-known company, time t was generally minimized in a cunning way. There is a budget “for mistakes”, but there is no testing at all. From the first day of work, any developer has access to the layout of the code in production and, having checked everything himself, crossing himself and praying to his gods, at a certain moment simply sends his product immediately to the users. After that, he, of course, keeps track of what is happening, and if something breaks, rolls back his changes, takes care of the problems and repeats the process again. I even heard that if the budget is not spent completely for a certain period, the management reminds its employees that they need to “take more risks”.
I do not undertake to comment on whether this is good or bad, since I did not see the process from the inside. But I am sure that for some types of business, with a certain tolerance and ponderability of management, this approach is quite applicable. Moreover, the fact that this company is quite well in the market and in general is a leader in its industry, suggests that they are completely satisfied.
In our company, we are very widely using Exploratory testing and Ad hoc testing (intuitive testing). This is when the tester examines a product or feature in the process of testing and, using the experience gained and basic knowledge, determines which corners of the test product he should look at and how to act on them. Due to this, professionals in our team get accustomed very well with the “flair” and talent of the tester, but on the other hand, this rules out the possibility of hiring people “from the street”. Our testers are professionals with a capital letter, which are expensive in the market. Probably, this may be a drawback for some companies trying to save on quality.
We do not have a predefined list of test scenarios. Instead, we use two approaches. First, automate everything you can; and secondly, we use checklists. Self-tests help minimize the time t required to verify the functional, especially regression, and checklists make it possible not to forget about important parts of the product during research testing. It is important that checklists are not written in the format “Go there, click on such and such a button and check that a yellow plate appeared”, but were just a reminder. “Check the user from Zimbabwe 80 years old when searching for red cars,” “The girl sees the comments hidden for boys” and “The authorization form has changed - check it by cleaning the cookies” - these are good reminders that non-declaratively show us vulnerable parts of the application, allowing fully apply your imagination.
In order to determine the correct time to reopen the task, I recommend using the following pyramid:

First we check all positive scenarios. Does the application do what is stated? Does it do it exactly as stated? After all, if the developer wrote a new basket on the website of the online store, and nothing can be put into this basket, this means that the functionality does not work, and the price of his work is 0 rubles 0 kopecks, even if he worked all weekends deep into the night and was very tired . Such a "product" of the user is not interested, and in our highly competitive environment, he will leave and will not return.
Moreover, as you remember, in our company the developer is responsible for the quality. Plus, we strive for the minimum number of re-opening tasks. Therefore, we require developers to self-test positive scenarios. And Visual QA helps us in this again. Before giving the task to the following participants of the process (for review of the code, for testing and further), the developer must come to the product manager and show him the result of his work. Obviously, he is interested in everything to work as indicated by the product manager in PRD.
Accordingly, if during the testing process we find flaws in positive usage scenarios, the task is rediscovered. This is the first reason to reopen the task.
Automated tests - if they are not available for the task, or they do not pass - this is also that stage of the test, which can lead to the reopening of the task. It is clear that in the general list of tests the scenarios are different, and there are negative ones among them. But automated tests pass quickly (and we are constantly working on optimizing them) and can be performed in parallel with manual checks, which means for a common goal - to optimize β - they work very well already at this stage. Consequently, it is up to the developer to ensure that tests pass in the branch of his task.
After checking the positive scenarios, we proceed to the negative. The area of this site in the pyramid is larger - accordingly, it may take more time to test these scenarios. At this stage, we are checking for non-standard user behavior. Somewhere he could have made a mistake in the planned buying scenario, and the system let him do it. Somewhere, he just accidentally poked at the wrong place, and he logged out. I entered the last name in the phone number field and the application crashed. In general, we are trying in every way to "break the system" and test "protection from the fool." Information security checks, by the way, also fall into this category.
The approach to the re-opening of the task, respectively, is the following: they checked the negative scenarios, collected everything they found on the ticket, rediscovered the task.
When checking negative scenarios, we try to be guided by common sense and check most of the likely scenarios. In the case of the next part of the pyramid - Corner cases, as we call them - the line between them and negative scenarios is not so obvious. This should include very very specific from the user's point of view moments, sometimes even controversial. For example, check if the Exclusive touch option for iOS is set. , , , Android. .
Corner cases. , , , (, , ) , . , , , , Code Review. - , , . / , , - . , , – , , .
Automation
, β , S, . Mobile Web, , ( , ).
.
, – . , . AIDA . , , , . , AIDA , .
. – , S, – . , ? , , « » .
, , . – , . – . , , , . – , , , – .
, . , « » , , , , . . , – . , , .
, . , « ». , - , . : ( ), , . , - , ? : « , «» «», – . . , , « » — , , .
( ) ( Automation Pyramid , Page Object , Data-driven-testing , Model-based-testing . .). , , – , . , , , . – .
Conclusion
, , . , , , . , « » .
, , , β – , , . , S . . – .
, , , , β, , . « ?». , , , ( - , , ).
. , , . , , . , . , .
Thanks for attention!
')
Source: https://habr.com/ru/post/334034/
All Articles