Neural conversational models: how to teach a neural network social conversation. Lecture in Yandex
A good virtual assistant should not only solve the user's tasks, but also reasonably answer the question “How are you?”. There are a lot of replicas without an explicit goal, and to prepare an answer to each one is problematic. Neural Conversational Models is a relatively new way to create interactive systems for free communication. It is based on networks trained in large corps conversations from the Internet. Boris hr0nix Yangel tells how such models are good and how to build them.
Under the cut - the decoding and the main part of the slide.
Thank you for coming. My name is Boria Yangel, I in Yandex are engaged in applying deep learning to natural language texts and dialogue systems. Today I want to tell you about Neural Conversational Models. This is a relatively new field of research in deep learning, the task of which is to learn how to develop neural networks that talk with the interlocutor on some common topics, that is, lead what can be called a small talk. They say "Hello", discuss how you are doing, terrible weather or a film that you recently watched. And today I want to tell you what has already been done in this area, what can be done in practice, using the results, and what problems remain that need to be solved.

My report will be structured approximately as follows. First, we will talk a little about why we might need to teach neural networks to socialize, what data and neural network architectures we will need for this, and how we will train to solve this problem. In the end, let's talk a little about how to evaluate what we have as a result of, that is, about metrics.

Why learn networks to talk? Someone might think that we are learning to make artificial intelligence that will ever enslave someone.
')
But we do not set ourselves such ambitious tasks. Moreover, I strongly doubt that the methods I’m going to talk about today will help us to get very close to creating real artificial intelligence.
Instead, we set ourselves the goal of making more interesting voice and conversational products. There is a class of products, which is called, for example, voice assistants. These are applications that in the format of a dialogue help you to solve some urgent tasks. For example, find out what the weather is like now, or call a taxi or find out where the nearest pharmacy is located. You learn about how such products are made on the second report of my colleague, Zhenya Volkov, and now I am interested in this moment. It would be desirable that in these products, if the user does not need anything right now, he could have a chat with something about the system. And the product hypothesis is that if you can sometimes chat with our system, and these dialogues will be good, interesting, unique, not repetitive - then the user will return to this product more often. These products want to do.
How can they be done?
There is a way in which the creators of Siri, for example, have gone - you can take and prepare many replicas of answers, some kind of replicas that the user often says. And when you say one of these replicas and get the answer created by the editors - everything is great, it looks great, users like it. The problem is that if you take a small step away from this scenario, you immediately see that Siri is nothing more than a stupid program that can use a phrase in one replica, and in the very next remark say that she does not know the meaning of this phrase — which, at least, is strange.

Here is an example of a similar in structure to the dialogue with the bot, which I did using the methods that I will talk about today. He may never answer as interestingly and ornately as Siri, but at no point in time does he give the impression of an absolutely stupid program. And it seems that it may be better in some products. And if this is combined with the approach used by Siri and responding with editorial cues, when you can otherwise fallback to such a model, it seems that it will turn out even better. Our goal is to make such systems.

What data do we need? Let me run a little ahead and first I will say what task we will work with, because it is important for the discussion of our question. We want to make remarks in the dialogue up to the current moment, and also, perhaps, some other contextual information about the dialogue - for example, where and when this dialogue takes place - to predict what the next remark should be. That is - to predict the answer.
To solve such a problem with the help of deep learning, it would be good for us to have a corpus with dialogues. This case would be better if it was large, because deep learning with small text cases - you yourself probably know how it works. It would be nice if the dialogues were on the topics we need. That is, if we want to make a bot who will discuss your feelings with you or talk about the weather, then such dialogues should be in the dialogue box. Therefore, a case of conversations with the support service of an Internet provider will hardly suit us in solving the problem.
It would be nice to know in the corpus the author of each replica at least at the level of the unique identifier. This will help us somehow to simulate the fact that, for example, different speakers use different vocabulary or even have different properties: they are called differently, they live in different places and answer different questions differently. Accordingly, if we have any metadata about the speakers - gender, age, place of residence, and so on - then this will help us even more to model their features.
Finally, some metadata about the dialogues — time or place, if these are dialogues in the real world — are also useful. The fact is that two people can have completely different dialogues depending on the space-time context.
In literature, that is, in articles about Neural Conversational Models, two datasets are very fond of.

The first one is Open Subtitles. These are just subtitles from a huge number of American films and TV shows. What are the advantages of this dataset? There are a lot of vital dialogues in it, directly those that we need, because these are films, series, there people often say to each other: “Hello! How are you? ”, Discuss some vital issues. But since these are films and series, there is also a minus dataset. There are a lot of fiction, a lot of fantasy that needs to be carefully cleaned up, and a lot of rather peculiar dialogues. I remember, the first model that we trained in Open Subtitles, she out of place and out of place a lot about vampires for some reason said. To the question "Where are you from?" Sometimes answered: "I, your mother, are from the FBI." It seems that not everyone wants his interactive product to behave in this way.
This is not the only problem with subtitles. How is it formed? I hope many of you know what srt-files are. In fact, the authors of the dataset simply took the srt-files of these films and TV shows, all the replicas from there and recorded it in a huge text file. Generally speaking, in srt-files nothing is clear about who is saying what replica and where one dialogue ends and another begins. You can use different heuristics: for example, suppose that two consecutive replicas are always spoken by different speakers, or, for example, that if more than 10 seconds elapsed between replicas, these are different dialogues. But such assumptions are fulfilled in 70% of cases, and this creates a lot of noise in dataset.
There are works in which the authors try, for example, relying on the vocabulary of the speakers, to segment all remarks in subtitles into who says what and where one dialogue ends and another begins. But no very good results have been achieved so far. It seems that if you use additional information - for example, a video or audio track - you can do better. But I do not know of any such work.
What moral? With subtitles you need to be careful. On them, you can probably pre-teach the model, but I don’t recommend teaching to the end with all these drawbacks.
The next dataset, which is very much loved in scientific literature, is Twitter. On Twitter, every tweet knows whether it is root or is an answer to some other tweet. Root in the sense that it is not written as an answer. Accordingly, this gives us an accurate breakdown of the dialogues. Each tweet forms a tree, in which the path from the root, that is, from root tweet to the leaf, is some kind of dialogue, often quite meaningful. On Twitter, the author is known and the time of each replica, you can get additional information about users, that is, something is written there directly in the user's Twitter profile. You can patch a profile with profiles in other social networks and learn something else.
What are the cons of Twitter? First of all, it is obviously biased towards the placement and discussion of links. But it turns out that if you remove all the dialogues in which the root tweet contains a link, then the rest - it is, in many ways, not always, but often resembles the very small talk that we are trying to model. However, it also turns out that secular topics dialogues, at least on Russian Twitter — I will not vouch for English — are conducted mainly by schoolchildren.
We figured it out as follows. We trained some model on Twitter for the first time and asked her a few simple questions like “Where are you?” And “How old are you?”.

In general, to the question “Where are you?”, The only censorship answer was “At school”, while everyone else was different, perhaps, with punctuation marks. But the answer to the question "How old are you?" Finally put everything in its place. So what is the moral here? If you want to learn interactive systems on this dataset, then the problem of schoolchildren somehow needs to be solved. For example, it is necessary to filter. Your model will speak as part of the speakers - you need to leave only the necessary part or use one of the speaker clustering methods, about which I will talk a little further.
These two datasets are loved in scientific literature. And if you are going to do something in practice, then you are in many ways limited only by your imagination and the name of the company for which you work. For example, if you are Facebook, then you are lucky to have your own instant messenger, where a huge number of dialogues are just for those topics that interest us. If you are not Facebook, you still have some options. For example, you can get data from public chats in Telegram, in Slack, in some IRC channels, you can parse some forums, post some comments on social networks. You can download movie scripts that actually follow a certain format, which in principle can be automatically parsed - and even understand where one scene ends, where another ends and who is the author of a particular replica. Finally, some transcripts of TV programs can be found on the Internet, and I'm actually sure that I have listed only a small part of various sources for the interactive corpus.

We talked about the data. Now let's get to the main part. What neural networks do we need to learn from this data in order for us to get something that can talk? I will remind you of the problem statement. We want, according to previous remarks, which have been said up to the present moment in the dialogue, to predict what the next replica should be. And all the approaches that solve this problem can be divided into two. I call them "generating" and "ranking." In the generative approach, we model the conditional distribution of the response in a fixed context. If we have such a distribution, then in order to respond, we take its mode, say, or just sample it from this distribution. And the ranking approach is when we teach a certain function of the relevance of a response, provided the context is not necessarily probabilistic in nature. But, in principle, this conditional distribution from the generating approach can also be relevant with this function. And then we take some pool of candidates of answers and choose from it the best answer for a given context using our relevance function.
First, let's talk about the first approach - the generator.
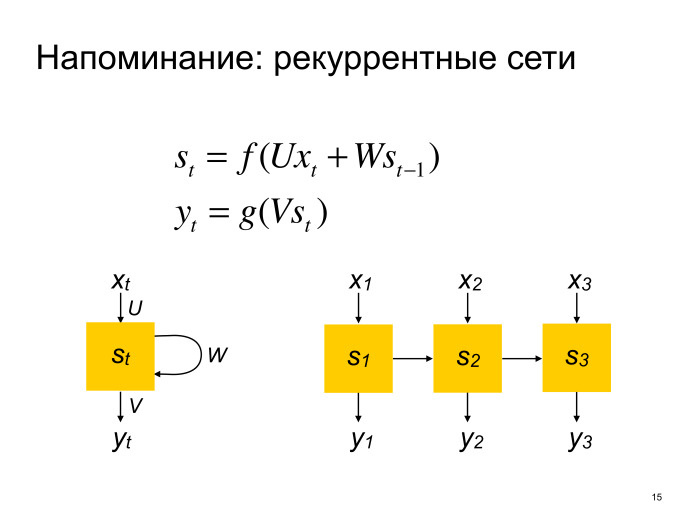
Here we need to know what recurrent networks are. I honestly hope that if you come to the report, where there are neural networks in the title, then you know what recurrent networks are - because from my confused minute explanation you are still unlikely to understand what it is. But the rules are such that I have to tell about them.
So, recurrent networks are such a neural network architecture for working with sequences of arbitrary length. It works as follows.
A recurrent network has some internal state that it updates by traversing all the elements of a sequence. Conventionally, we can assume that it passes from left to right. And as an option, the recurrent network at each step can generate some kind of output that goes somewhere further in your multilayer neural network. And in classical neural networks called vanilla RNN, the update function of the internal state is just some non-linearity over the linear transformation of the input and the previous state, and the output is also non-linear over the linear transformation of the internal state. Everyone loves to draw like this, or else unfold in sequences. We will continue to use the second notation.
In fact, nobody uses such update formulas, because if you train such neural networks, many unpleasant problems arise. Enjoy more advanced architectures. For example, LSTM (Long short-term memory) and GRU (Gated recurrent units). Further, when we say “recurrent network”, we will assume something more advanced than simple recurrent networks.

Generative approach. Our task of generating a replica in the context-based dialog can be thought of as the task of generating a string by string. That is, imagine that we take the whole context, all the previous replicas said, and simply concatenate them, separating the replicas of different speakers with some special character. It turns out the task of generating a string on a string, and such tasks are well studied in machine learning, in particular - in machine translation. And the standard architecture in machine translation is the so-called sequence-to-sequence. And state of the art in machine translation is still a modification of the sequence-to-sequence approach. It was proposed by Suckever in 2014, and later adapted by his co-authors for our task, Neural Conversational Models.
What is sequence-to-sequence? This is the recurrent architecture of the encoder-decoder, that is, these are two recurrent networks: the encoder and the decoder. The encoder reads the source string and generates some of its condensed representation. This condensed representation is input to the decoder, which already has to generate the output line or, for each output line, say what probability it has in this conditional distribution that we are trying to model.

It looks like this. Yellowish - network encoder. Suppose we have a dialogue of two speakers from two replicas of "Hello" and "Zdarov", for which we want to generate an answer. Speaker replicas will be separated by a special end-of-sentense symbol, eos. In fact, they do not always share a sentence, but historically they call it that way. Every word we first immerse in some vector space, we will do what is called vector embedding. Then this vector for each word will be fed to the input of the network encoder, and the last state of the network encoder, after it has processed the last word, will be our condensed representation of the context that we give to the input of the decoder. We can, for example, initialize the first hidden state of the network decoder with this vector or, alternatively, for example, submit it to each timestamp along with the words. The network decoder at each step generates the next word of the replica and, at the input, receives the previous word that it generated. This allows you to really model the conditional distribution better. Why? I do not want to go into details now.
Generates the decoder all until it generates the end-of-sentence token. This means that “That's enough.” And the decoder at the first step, as a rule, also receives the end-of-sentence token. And it is not clear what he needs to file at the entrance.

Typically, such architectures are trained through learning maximum likelihood. That is, we take the conditional distribution of the answers in contexts we know in the training set and try to make the answers we know as possible as possible. That is, maximize, say, the logarithm of such a probability by the parameters of the neural network. And when we need to generate a replica, we already have the parameters of the neural network, because we have trained and fixed them. And we simply maximize the conditional distribution of the answer or sample from it. In fact, it can not be precisely promaximized, so you have to use some approximate methods. For example, there is a method of stochastic maximum search in such architectures encoder-decoder. Called beam search. I don’t have time to tell you what it is now, but the answer to this question is easy to find on the Internet.
All modifications of this architecture, which were invented for machine translation, you can try to apply for Neural Conversational Models. For example, the encoder and decoder are usually multi-layered. They work better than single-layer architecture. As I said, these are most likely LSTM or GRU networks, and not ordinary RNNs.
The encoder is usually bidirectional. That is, in fact, these are two recurrent networks that are traversed in a sequence from left to right and from right to left. Practice shows that if you go only from one direction, then until you reach the end, the network will already forget what was there first. And if you go from two sides, then you have information both on the left and on the right at each moment. It works better.
, , attention. . , , timestamp encoder - , . , - , . attention , Neural Conversational Models, , . , , . . , - , , memory networks. multi-hole potential.
, , Neural Conversational Model — , . - . , , , .
, , — «» . encoder-decoder sequence-to-sequence, . , . , « », «», « » . . ? , , , , .
Neural Conversational Models , , «» . , - , , , , .

, , — .
What does this mean in practice? , . . , . . — . , . , - .
? , , . , , , — «», « » . .
, sequence-to-sequence, , — . — .

, — , . -. , . . , , , . , «» « », , . . , sequence-to-sequence, , sequence-to-sequence, . .
, ICLR, , . . - — , . . . , . - — , , . , , Monte Carlo MMI, . , , - , MMI.
, MMI , , , , . , , . This is bad.

, , — . . , - , . Why? , . - , , . , .
, , , . - .
, , «A Persona-Based Neural Conversation Model»: . , , , - , , . , , , , - . . . , - , , .
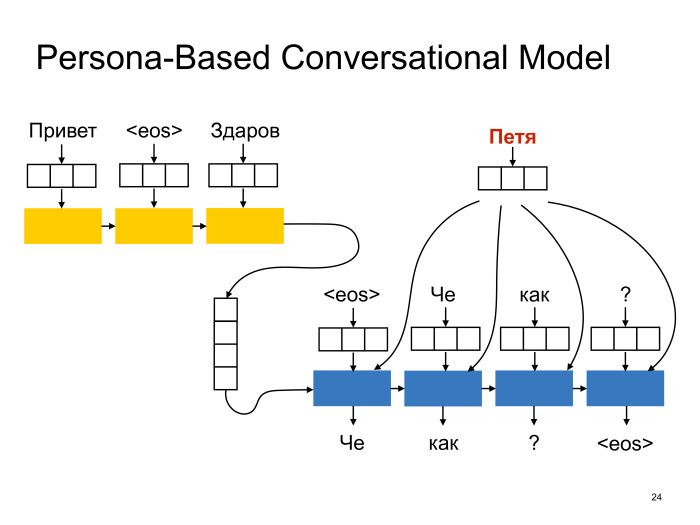
sequence-to-sequence : , , timestamp . — embedding- .
: , , - , , . , . . , , , t-SNE - - , , .
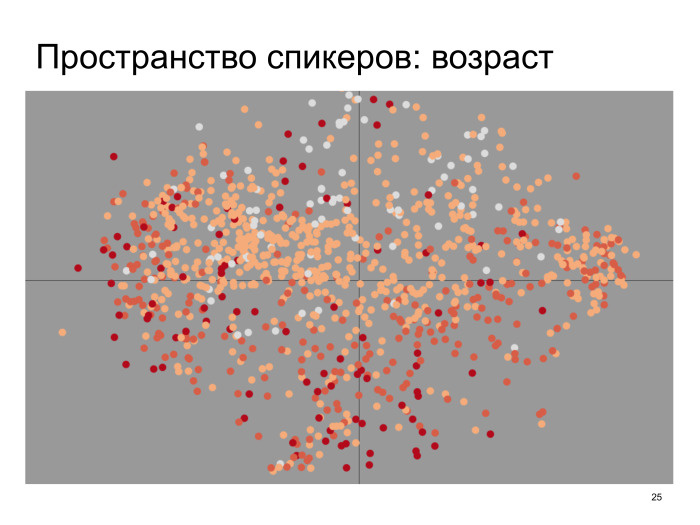
, . — , , , — , 30 , . , , . , , , , 30 - . , - . Good.

. , , . , , . , .

, , . , , , , . . . , , log-likelihood , . , log-likelihood , , .
: « , , , ». , . , . .
: , - , , . ? . , . , , , . , — , , sequence-to-sequence encoder-decoder.
, , : , , . , , . , , .
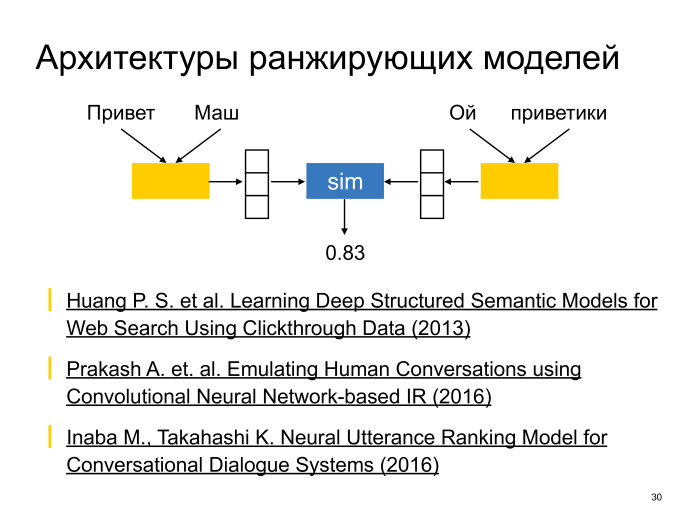
? . , — , — encoder. — , — . , , . Microsoft Research DSSM, Deep Structure Semantic Models, 2013 . Neural Conversational Models.
encoder, , , . , — sequence-to-sequence. : . .
, — - , , , .
? , , . , - , , .
? — random sampling, , , . , hard negative mining. : , , .
- «» . , , hard negative mining .
. ? - . , : Sim, , softmax - , . , , , , . tripletloss. - max margin, , , margin, SVN. .
, ? ? , - . , , , . , «» , , , . , - , . . , , , . . , . , .
? State of the art, , — , mechanical turk, : « ? 0 5». : « ?». , .

: ? , sequence-to-sequence, DSSM- , : bad, neutral good. Bad , , , , . Neutral , , . good — . - , baseline, . .
, 10% . Why it happens? , , . , -, : « ?». «42», , , . 9 10 — bad.
? , . — , . sequence-to-sequence , . , , , , , sequence-to-sequence . sequence-to-sequence - .
. Neural Conversational Models — - deep learning, . , : Facebook, Google. . , - , , . - , . , deep learning — , .
, , , . . Thank.
Under the cut - the decoding and the main part of the slide.
Thank you for coming. My name is Boria Yangel, I in Yandex are engaged in applying deep learning to natural language texts and dialogue systems. Today I want to tell you about Neural Conversational Models. This is a relatively new field of research in deep learning, the task of which is to learn how to develop neural networks that talk with the interlocutor on some common topics, that is, lead what can be called a small talk. They say "Hello", discuss how you are doing, terrible weather or a film that you recently watched. And today I want to tell you what has already been done in this area, what can be done in practice, using the results, and what problems remain that need to be solved.
My report will be structured approximately as follows. First, we will talk a little about why we might need to teach neural networks to socialize, what data and neural network architectures we will need for this, and how we will train to solve this problem. In the end, let's talk a little about how to evaluate what we have as a result of, that is, about metrics.
Why learn networks to talk? Someone might think that we are learning to make artificial intelligence that will ever enslave someone.
')
But we do not set ourselves such ambitious tasks. Moreover, I strongly doubt that the methods I’m going to talk about today will help us to get very close to creating real artificial intelligence.
Instead, we set ourselves the goal of making more interesting voice and conversational products. There is a class of products, which is called, for example, voice assistants. These are applications that in the format of a dialogue help you to solve some urgent tasks. For example, find out what the weather is like now, or call a taxi or find out where the nearest pharmacy is located. You learn about how such products are made on the second report of my colleague, Zhenya Volkov, and now I am interested in this moment. It would be desirable that in these products, if the user does not need anything right now, he could have a chat with something about the system. And the product hypothesis is that if you can sometimes chat with our system, and these dialogues will be good, interesting, unique, not repetitive - then the user will return to this product more often. These products want to do.
How can they be done?
There is a way in which the creators of Siri, for example, have gone - you can take and prepare many replicas of answers, some kind of replicas that the user often says. And when you say one of these replicas and get the answer created by the editors - everything is great, it looks great, users like it. The problem is that if you take a small step away from this scenario, you immediately see that Siri is nothing more than a stupid program that can use a phrase in one replica, and in the very next remark say that she does not know the meaning of this phrase — which, at least, is strange.
Here is an example of a similar in structure to the dialogue with the bot, which I did using the methods that I will talk about today. He may never answer as interestingly and ornately as Siri, but at no point in time does he give the impression of an absolutely stupid program. And it seems that it may be better in some products. And if this is combined with the approach used by Siri and responding with editorial cues, when you can otherwise fallback to such a model, it seems that it will turn out even better. Our goal is to make such systems.
What data do we need? Let me run a little ahead and first I will say what task we will work with, because it is important for the discussion of our question. We want to make remarks in the dialogue up to the current moment, and also, perhaps, some other contextual information about the dialogue - for example, where and when this dialogue takes place - to predict what the next remark should be. That is - to predict the answer.
To solve such a problem with the help of deep learning, it would be good for us to have a corpus with dialogues. This case would be better if it was large, because deep learning with small text cases - you yourself probably know how it works. It would be nice if the dialogues were on the topics we need. That is, if we want to make a bot who will discuss your feelings with you or talk about the weather, then such dialogues should be in the dialogue box. Therefore, a case of conversations with the support service of an Internet provider will hardly suit us in solving the problem.
It would be nice to know in the corpus the author of each replica at least at the level of the unique identifier. This will help us somehow to simulate the fact that, for example, different speakers use different vocabulary or even have different properties: they are called differently, they live in different places and answer different questions differently. Accordingly, if we have any metadata about the speakers - gender, age, place of residence, and so on - then this will help us even more to model their features.
Finally, some metadata about the dialogues — time or place, if these are dialogues in the real world — are also useful. The fact is that two people can have completely different dialogues depending on the space-time context.
In literature, that is, in articles about Neural Conversational Models, two datasets are very fond of.
The first one is Open Subtitles. These are just subtitles from a huge number of American films and TV shows. What are the advantages of this dataset? There are a lot of vital dialogues in it, directly those that we need, because these are films, series, there people often say to each other: “Hello! How are you? ”, Discuss some vital issues. But since these are films and series, there is also a minus dataset. There are a lot of fiction, a lot of fantasy that needs to be carefully cleaned up, and a lot of rather peculiar dialogues. I remember, the first model that we trained in Open Subtitles, she out of place and out of place a lot about vampires for some reason said. To the question "Where are you from?" Sometimes answered: "I, your mother, are from the FBI." It seems that not everyone wants his interactive product to behave in this way.
This is not the only problem with subtitles. How is it formed? I hope many of you know what srt-files are. In fact, the authors of the dataset simply took the srt-files of these films and TV shows, all the replicas from there and recorded it in a huge text file. Generally speaking, in srt-files nothing is clear about who is saying what replica and where one dialogue ends and another begins. You can use different heuristics: for example, suppose that two consecutive replicas are always spoken by different speakers, or, for example, that if more than 10 seconds elapsed between replicas, these are different dialogues. But such assumptions are fulfilled in 70% of cases, and this creates a lot of noise in dataset.
There are works in which the authors try, for example, relying on the vocabulary of the speakers, to segment all remarks in subtitles into who says what and where one dialogue ends and another begins. But no very good results have been achieved so far. It seems that if you use additional information - for example, a video or audio track - you can do better. But I do not know of any such work.
What moral? With subtitles you need to be careful. On them, you can probably pre-teach the model, but I don’t recommend teaching to the end with all these drawbacks.
The next dataset, which is very much loved in scientific literature, is Twitter. On Twitter, every tweet knows whether it is root or is an answer to some other tweet. Root in the sense that it is not written as an answer. Accordingly, this gives us an accurate breakdown of the dialogues. Each tweet forms a tree, in which the path from the root, that is, from root tweet to the leaf, is some kind of dialogue, often quite meaningful. On Twitter, the author is known and the time of each replica, you can get additional information about users, that is, something is written there directly in the user's Twitter profile. You can patch a profile with profiles in other social networks and learn something else.
What are the cons of Twitter? First of all, it is obviously biased towards the placement and discussion of links. But it turns out that if you remove all the dialogues in which the root tweet contains a link, then the rest - it is, in many ways, not always, but often resembles the very small talk that we are trying to model. However, it also turns out that secular topics dialogues, at least on Russian Twitter — I will not vouch for English — are conducted mainly by schoolchildren.
We figured it out as follows. We trained some model on Twitter for the first time and asked her a few simple questions like “Where are you?” And “How old are you?”.
In general, to the question “Where are you?”, The only censorship answer was “At school”, while everyone else was different, perhaps, with punctuation marks. But the answer to the question "How old are you?" Finally put everything in its place. So what is the moral here? If you want to learn interactive systems on this dataset, then the problem of schoolchildren somehow needs to be solved. For example, it is necessary to filter. Your model will speak as part of the speakers - you need to leave only the necessary part or use one of the speaker clustering methods, about which I will talk a little further.
These two datasets are loved in scientific literature. And if you are going to do something in practice, then you are in many ways limited only by your imagination and the name of the company for which you work. For example, if you are Facebook, then you are lucky to have your own instant messenger, where a huge number of dialogues are just for those topics that interest us. If you are not Facebook, you still have some options. For example, you can get data from public chats in Telegram, in Slack, in some IRC channels, you can parse some forums, post some comments on social networks. You can download movie scripts that actually follow a certain format, which in principle can be automatically parsed - and even understand where one scene ends, where another ends and who is the author of a particular replica. Finally, some transcripts of TV programs can be found on the Internet, and I'm actually sure that I have listed only a small part of various sources for the interactive corpus.
We talked about the data. Now let's get to the main part. What neural networks do we need to learn from this data in order for us to get something that can talk? I will remind you of the problem statement. We want, according to previous remarks, which have been said up to the present moment in the dialogue, to predict what the next replica should be. And all the approaches that solve this problem can be divided into two. I call them "generating" and "ranking." In the generative approach, we model the conditional distribution of the response in a fixed context. If we have such a distribution, then in order to respond, we take its mode, say, or just sample it from this distribution. And the ranking approach is when we teach a certain function of the relevance of a response, provided the context is not necessarily probabilistic in nature. But, in principle, this conditional distribution from the generating approach can also be relevant with this function. And then we take some pool of candidates of answers and choose from it the best answer for a given context using our relevance function.
First, let's talk about the first approach - the generator.
Here we need to know what recurrent networks are. I honestly hope that if you come to the report, where there are neural networks in the title, then you know what recurrent networks are - because from my confused minute explanation you are still unlikely to understand what it is. But the rules are such that I have to tell about them.
So, recurrent networks are such a neural network architecture for working with sequences of arbitrary length. It works as follows.
A recurrent network has some internal state that it updates by traversing all the elements of a sequence. Conventionally, we can assume that it passes from left to right. And as an option, the recurrent network at each step can generate some kind of output that goes somewhere further in your multilayer neural network. And in classical neural networks called vanilla RNN, the update function of the internal state is just some non-linearity over the linear transformation of the input and the previous state, and the output is also non-linear over the linear transformation of the internal state. Everyone loves to draw like this, or else unfold in sequences. We will continue to use the second notation.
In fact, nobody uses such update formulas, because if you train such neural networks, many unpleasant problems arise. Enjoy more advanced architectures. For example, LSTM (Long short-term memory) and GRU (Gated recurrent units). Further, when we say “recurrent network”, we will assume something more advanced than simple recurrent networks.
Generative approach. Our task of generating a replica in the context-based dialog can be thought of as the task of generating a string by string. That is, imagine that we take the whole context, all the previous replicas said, and simply concatenate them, separating the replicas of different speakers with some special character. It turns out the task of generating a string on a string, and such tasks are well studied in machine learning, in particular - in machine translation. And the standard architecture in machine translation is the so-called sequence-to-sequence. And state of the art in machine translation is still a modification of the sequence-to-sequence approach. It was proposed by Suckever in 2014, and later adapted by his co-authors for our task, Neural Conversational Models.
What is sequence-to-sequence? This is the recurrent architecture of the encoder-decoder, that is, these are two recurrent networks: the encoder and the decoder. The encoder reads the source string and generates some of its condensed representation. This condensed representation is input to the decoder, which already has to generate the output line or, for each output line, say what probability it has in this conditional distribution that we are trying to model.
It looks like this. Yellowish - network encoder. Suppose we have a dialogue of two speakers from two replicas of "Hello" and "Zdarov", for which we want to generate an answer. Speaker replicas will be separated by a special end-of-sentense symbol, eos. In fact, they do not always share a sentence, but historically they call it that way. Every word we first immerse in some vector space, we will do what is called vector embedding. Then this vector for each word will be fed to the input of the network encoder, and the last state of the network encoder, after it has processed the last word, will be our condensed representation of the context that we give to the input of the decoder. We can, for example, initialize the first hidden state of the network decoder with this vector or, alternatively, for example, submit it to each timestamp along with the words. The network decoder at each step generates the next word of the replica and, at the input, receives the previous word that it generated. This allows you to really model the conditional distribution better. Why? I do not want to go into details now.
Generates the decoder all until it generates the end-of-sentence token. This means that “That's enough.” And the decoder at the first step, as a rule, also receives the end-of-sentence token. And it is not clear what he needs to file at the entrance.
Typically, such architectures are trained through learning maximum likelihood. That is, we take the conditional distribution of the answers in contexts we know in the training set and try to make the answers we know as possible as possible. That is, maximize, say, the logarithm of such a probability by the parameters of the neural network. And when we need to generate a replica, we already have the parameters of the neural network, because we have trained and fixed them. And we simply maximize the conditional distribution of the answer or sample from it. In fact, it can not be precisely promaximized, so you have to use some approximate methods. For example, there is a method of stochastic maximum search in such architectures encoder-decoder. Called beam search. I don’t have time to tell you what it is now, but the answer to this question is easy to find on the Internet.
All modifications of this architecture, which were invented for machine translation, you can try to apply for Neural Conversational Models. For example, the encoder and decoder are usually multi-layered. They work better than single-layer architecture. As I said, these are most likely LSTM or GRU networks, and not ordinary RNNs.
The encoder is usually bidirectional. That is, in fact, these are two recurrent networks that are traversed in a sequence from left to right and from right to left. Practice shows that if you go only from one direction, then until you reach the end, the network will already forget what was there first. And if you go from two sides, then you have information both on the left and on the right at each moment. It works better.
, , attention. . , , timestamp encoder - , . , - , . attention , Neural Conversational Models, , . , , . . , - , , memory networks. multi-hole potential.
, , Neural Conversational Model — , . - . , , , .
, , — «» . encoder-decoder sequence-to-sequence, . , . , « », «», « » . . ? , , , , .
Neural Conversational Models , , «» . , - , , , , .
, , — .
What does this mean in practice? , . . , . . — . , . , - .
? , , . , , , — «», « » . .
, sequence-to-sequence, , — . — .
, — , . -. , . . , , , . , «» « », , . . , sequence-to-sequence, , sequence-to-sequence, . .
, ICLR, , . . - — , . . . , . - — , , . , , Monte Carlo MMI, . , , - , MMI.
, MMI , , , , . , , . This is bad.
, , — . . , - , . Why? , . - , , . , .
, , , . - .
, , «A Persona-Based Neural Conversation Model»: . , , , - , , . , , , , - . . . , - , , .
sequence-to-sequence : , , timestamp . — embedding- .
: , , - , , . , . . , , , t-SNE - - , , .
, . — , , , — , 30 , . , , . , , , , 30 - . , - . Good.
. , , . , , . , .
, , . , , , , . . . , , log-likelihood , . , log-likelihood , , .
: « , , , ». , . , . .
: , - , , . ? . , . , , , . , — , , sequence-to-sequence encoder-decoder.
, , : , , . , , . , , .
? . , — , — encoder. — , — . , , . Microsoft Research DSSM, Deep Structure Semantic Models, 2013 . Neural Conversational Models.
encoder, , , . , — sequence-to-sequence. : . .
, — - , , , .
? , , . , - , , .
? — random sampling, , , . , hard negative mining. : , , .
- «» . , , hard negative mining .
. ? - . , : Sim, , softmax - , . , , , , . tripletloss. - max margin, , , margin, SVN. .
, ? ? , - . , , , . , «» , , , . , - , . . , , , . . , . , .
? State of the art, , — , mechanical turk, : « ? 0 5». : « ?». , .
: ? , sequence-to-sequence, DSSM- , : bad, neutral good. Bad , , , , . Neutral , , . good — . - , baseline, . .
, 10% . Why it happens? , , . , -, : « ?». «42», , , . 9 10 — bad.
? , . — , . sequence-to-sequence , . , , , , , sequence-to-sequence . sequence-to-sequence - .
. Neural Conversational Models — - deep learning, . , : Facebook, Google. . , - , , . - , . , deep learning — , .
, , , . . Thank.
Source: https://habr.com/ru/post/333912/
All Articles