PostgreSQL multi-tiered backup with Barman and synchronous transfer of transaction logs

Yandex.Money stores a lot of important information for comfortable user experience. Profile settings and subscriptions for penalties also need to be backed up, which is what the link from Barman Backup & Recovery for PostgreSQL and pg_receivexlog does for us .
In this article I will talk about why the architecture became what it was, and also tell you how to implement such a script for your PostgreSQL database.
How it was, and why it is not cool
Before the changes described in the article, the backup of the payment system was removed from the master database at one of our data centers (DC). In general, a payment system consists of a set of individual services, databases and applications. All this stuff is reserved according to the importance of the data. Since the article is more practical, I’ll consider one of many DBMSs as an example without increased security requirements - it stores user profile settings, translation history, authentication preferences, and so on.
As a backup tool in use, we love Barman, a flexible and stable product. In addition, it is made by people involved in the development of our beloved PostgreSQL.
The problem with backup only from active nodes is that if the master was switched to the second DC (where there were no backups), then the backup server of the first DC was slowly and for a long time collecting copies from the new master over the network. And the potential loss of the most recent transactions during recovery began to raise more and more concerns as the number of users grew.
Doing right
So, we will solve the following tasks:
Ensuring the availability of backups in case of failure of the DC or backup server.
- Preventing loss of transactions when the master server fails.
The scale of our task was 20 PostgreSQL 9.5 servers (10 masters and 10 slaves) serving 36 databases with a total capacity of about 3 TB. But the described scenario is also suitable for a couple of servers with critical databases.
Since version 2.1, Barman Backup & Recovery now has the ability to record a stream of transactions not only from the master, but also from the slave servers (replicas).
The general scheme of the new solution is presented below; it is rather uncomplicated: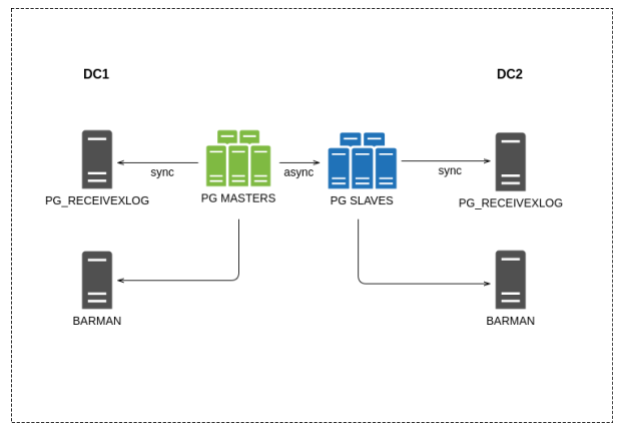
There is one backup server in each DC, their configuration is common (one of the advantages of Barman).
The configuration process is as follows:
1. Connect to the database server and install postgresql-9.5-pgespresso with the help of the package manager - an extension for the integration of Barman Backup & Recovery with PostgreSQL. All commands are for Ubuntu, for other distributions there may be differences:
apt-get install postgresql-9.5-pgespresso 2. Install the pg_espresso extension in PostgreSQL:
postgres@db1:5432 (postgres) # CREATE EXTENSION pgespresso 3. Now on the server with Barman, you need to create a file that describes the backup settings for the db1 server - db1.conf in the /etc/barman.d/ directory with the following contents:
[db1] ssh_command = ssh postgres@db1 conninfo = host=pgdb1 user=postgres port=5432 backup_options = concurrent_backup ; pg_espresso archiver = off ; archive_command streaming_archiver = on ; slot_name = barman ; 4. Next, you need to create a replication slot to ensure that the wizard does not delete the transaction logs that have not yet been received by the replica:
$ barman receive-wal --create-slot db1 5. And check that Barman sees the server and takes transaction logs from it:
$ barman check db1 If all commands are executed correctly, then as a result of the verification command, you should get something similar:
Server db1: PostgreSQL: OK superuser: OK PostgreSQL streaming: OK wal_level: OK replication slot: OK directories: OK retention policy settings: OK backup maximum age: OK (no last_backup_maximum_age provided) compression settings: OK failed backups: OK (there are 0 failed backups) minimum redundancy requirements: OK (have 7 backups, expected at least 7) ssh: OK (PostgreSQL server) pgespresso extension: OK pg_receivexlog: OK pg_receivexlog compatible: OK receive-wal running: OK archiver errors: OK Now Barman will pick up magazines and make backups from replicas. All PostgreSQL databases with user profiles, payment history, subscriptions to fines, authentication settings, etc., fall into the backup.
The squad did not notice the loss of a fighter
Let me remind you that zero RPO when restoring is very important for us, so we decided to back up Barman with an additional mechanism - pg_receivexlog . This process is on a separate server — not on a server with a database — and continuously transfers copies of transaction logs from the master node to a separate repository transaction log store. And so for each DC separately.
The peculiarity of the mechanism is that the DBMS does not confirm the application to write the data to the database until it receives confirmation from pg_receivexlog about the successful copying of the transaction.
Without this, the probability of the following scenario would remain:
For example, Innokenty pays 100 rubles for cellular communication, the operation is successfully carried out by our payment system (PS).
Immediately after the backend, an accident occurs and we roll back the backup, including the transaction logs.
- But since the transfer occurred right before the accident, this transaction was not backed up and will no longer be reflected in the history of operations on the Innocentia wallet.
It turns out that the PS knows about the payment, the money is not lost, but the operation itself in history does not look. Of course, this is inconvenient and discouraging. The operation would have to be made manually through the support service.
Now how to set up a miracle mechanism for synchronous transfer of logs:
1. Create a slot for the log collector:
pg_receivexlog --create-slot -S pgreceiver --if-not-exists -h db1 2. Start the log collection service from the PostgreSQL server:
pg_receivexlog -S pgreceiver -d "host=db1 user=postgres application_name=logreceiver" -D /var/lib/postgresql/log/db1/ --verbose --synchronous *-S: . ;* *-d: ;* *-D: , ;* *—synchronous: ;* 3. After starting, pg_receivexlog will try to save transaction logs to the directory in synchronous mode. There may be several such collectors, one per PostreSQL server. But in order for the synchronous mode to work, you need to specify the parameter in the PostgreSQL configuration in the DBMS settings on the master node:
synchronous_standby_names = 'logreceiver, standby' 4. But if the server with the log collector fails, the master node can continue processing user transactions, it is better to specify a replica for the second server. On the replica in recovery.conf, you need to specify where to get the transaction logs if the master node is unavailable:
restore_command = 'scp postgres@logreceiver:/var/lib/postgresql/log/db1/%f* %p' Of course, if the log collection server fails, the speed of the entire system will slightly decrease, because instead of sending logs to the log collector in the same DC, the master will have to send them with confirmation to another DC. However, stability is more important.
As a summary, I’ll give some specifics about the time and volume of backups as described in the article. The full backup of the servers mentioned above is removed at Yandex.Money daily and weighs about 2 TB, for which the backup server needs 5-10 hours to process. In addition, there is a constant backup of transaction logs by moving their files to the repository.
')
Source: https://habr.com/ru/post/333844/
All Articles