Doom 3 source code analysis

November 23, 2011 id Software has maintained its own tradition and published the source code of its previous engine.
This time it’s time for idTech4 , which was used in Prey, in Quake 4 and, of course, in Doom 3. In just a few hours, more than 400 forks of the GitHub repository were created, people began to explore the internal mechanisms of the game or port it to other platforms. I also decided to participate and created an Intel version for Mac OS X , which John Carmack kindly advertised .
')
In terms of cleanliness and commentary, this is the best release of the id Software code since the Doom iPhone codebase (which was released later, and therefore commented better). I highly recommend everyone to study this engine, compile it and experiment.
Here are my notes on what I understood. As usual, I cleaned them up, I hope they will save someone a couple of hours and encourage someone to learn the code to improve their programming skills.
Part 1: Overview
I noticed that I use more and more illustrations and less text to explain the codebase. I used to use gliffy for this, but it has annoying limitations (for example, the lack of an alpha channel). I am thinking of creating my own tool based on SVG and Javascript specifically for illustrations on 3D engines. I wonder if there is something like that already? Well, okay, back to the code ...
Introduction
Very nice to get access to the source code of this amazing engine. At the time of release in 2004, Doom III set new graphics and sound standards for real-time engines, the most notable of which was Unified Lighting and Shadows. For the first time, technology has allowed artists to express themselves on a Hollywood scale. Even eight years later, the first encounter with HellKnight at Delta-Labs-4 still looks incredibly spectacular:
First contact
The source code is now distributed via Github, which is good, because the id Software FTP server was almost always down or overloaded.
The original TTimo release is normally compiled using Visual Studio 2010 Professional. Unfortunately, MFC is missing in Visual Studio 2010 and therefore cannot be used. After the release it was somewhat disappointing, but since then the dependencies have been removed .
Windows 7 :
===========
git clone https://github.com/TTimo/doom3.gpl.git
To read and study the code, I prefer to use XCode 4.0 on Mac OS X: the search speed from SpotLight, highlighting variables and “Command-Click” to go to the right place make work more convenient than in Visual Studio. The XCode project was broken during the release, but it is very easy to fix , and now there is the Github repository of the “bad sector” user, which works well on Mac OS X Lion.
MacOS X :
=========
git clone https://github.com/badsector/Doom3-for-MacOSX-Notes: it turned out that highlighting of variables and the transition to Control-Click are also available in Visual Studio 2010 after installing Visual Studio 2010 Productivity Power Tools . I do not understand why this is not in the “vanilla” installation package.
Both code bases are now in the best condition: one click is enough to build an executable file!
- Download the code.
- Press F8 / Command-B.
- You can run!
An interesting fact: to start the game you need the
base folder with Doom 3 resources. I didn’t want to waste time extracting them from the Doom 3 CDs and updating them, so I downloaded the version from Steam. It seems that the guys from id Software did the same, because in the debug settings of the published Visual Studio project there is still "+set fs_basepath C:\Program Files (x86)\Steam\steamapps\common\doom 3" !Interesting fact: The engine was developed in Visual Studio .NET ( source code ). But there is not a single C # line in the code, and the published version requires Visual Studio 2010 Professional to be compiled.
Interesting fact: The Id Software team seems to be fans of the Matrix franchise: Quake III's working title was Trinity, and Doom III's working name was Neo. This explains why all the source code is in the
neo subfolder.Architecture
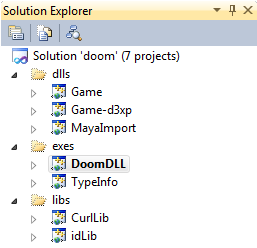
The game is divided into projects reflecting the overall architecture of the engine:
| Projects | Assembly | Notes | |
|---|---|---|---|
| Windows | Mac os x | ||
| Game | gamex86.dll | gamex86.so | Gameplay doom3 |
| Game-d3xp | gamex86.dll | gamex86.so | Doom3 eXPension gameplay (ressurection) |
| Mayaimport | Mayaimport.dll | - | Part of the resource creation toolchain: it loads at runtime to open Maya files and import monsters, camera routes and maps. |
| Doom3 | Doom3.exe | Doom3.app | Doom 3 engine |
| TypeInfo | TypeInfo.exe | - | An internal auxiliary RTTI file: generates a GameTypeInfo.h , a map of all types of Doom3 classes with the size of each element. This allows you to debug memory using the TypeInfo class. |
| CurlLib | CurlLib.lib | - | HTTP client used to download files (statically linked with gamex86.dll and doom3.exe). |
| idLib | idLib.lib | idLib.a | Id software library. Includes a parser, a lexical analyzer, a dictionary ... (statically linked to gamex86.dll and doom3.exe). |
As in all other engines, starting with idTech2, we see one binary file with closed source (doom.exe) and one open source dynamic library (gamex86.dll):

Most of the codebase was available from October 2004 in the Doom3 SDK , only the source code of the Doom3 executable file was missing. Modders could build
idlib.a and gamex86.dll , but the engine core was still closed.Note: The engine does not use the standard C ++ library: all containers (map, list with pointers ...) are re-implemented, but
libc is actively used.Note: In the Game module, each class inherits idClass. This allows the engine to perform internal RTTI and create instances of classes by class name.
Interesting fact: If you look at the illustration, you will notice that some necessary frameworks (such as
Filesystem ) are located in the Doom3.exe project. This presents a problem, because gamex86.dll must load and resources. These subsystems are dynamically loaded by the gamex86.dll library from doom3.exe (this is what the arrow in the illustration means). If you open the DLL in PE explorer, you can see that gamex86.dll exports one method: GetGameAPI :
Everything works in the same way as Quake2 loaded the renderer and gaming ddl , passing pointers to objects:
When Doom3.exe is loaded, it:
- Loads the DLL into the process memory space using
LoadLibrary. - Retrieves the
GetGameAPIaddress in dll usingGetProcAddresswin32. - Calls
GetGameAPI.
gameExport_t * GetGameAPI_t( gameImport_t *import ); At the end of this “connection setup”, Doom3.exe has a pointer to an
idGame object, and Game.dll has a pointer to a gameImport_t object, which contains additional links to all missing subsystems, for example idFileSystem .How Gamex86 sees objects in the Doom 3 executable:
typedef struct { int version; // API idSys * sys; // idCommon * common; // idCmdSystem * cmdSystem // idCVarSystem * cvarSystem; // idFileSystem * fileSystem; // idNetworkSystem * networkSystem; // idRenderSystem * renderSystem; // idSoundSystem * soundSystem; // idRenderModelManager * renderModelManager; // idUserInterfaceManager * uiManager; // idDeclManager * declManager; // idAASFileManager * AASFileManager; // AAS idCollisionModelManager * collisionModelManager; // } gameImport_t; How Doom 3 sees Game / Modd objects:
typedef struct { int version; // API idGame * game; // idGameEdit * gameEdit; // } gameExport_t; Notes: An excellent resource for a better understanding of each subsystem is the Doom3 SDK documentation page : it looks like it was written in 2004 by a person with a deep understanding of the code (that is, most likely, one of the development team).
Code
Before parsing, here are some statistics from
cloc :./cloc-1.56.pl neo
2180 text files.
2002 unique files.
626 files ignored.
http://cloc.sourceforge.net v 1.56 T=19.0 s (77.9 files/s, 47576.6 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 517 87078 113107 366433
C/C++ Header 617 29833 27176 111105
C 171 11408 15566 53540
Bourne Shell 29 5399 6516 39966
make 43 1196 874 9121
m4 10 1079 232 9025
HTML 55 391 76 4142
Objective C++ 6 709 656 2606
Perl 10 523 411 2380
yacc 1 95 97 912
Python 10 108 182 895
Objective C 1 145 20 768
DOS Batch 5 0 0 61
Teamcenter def 4 3 0 51
Lisp 1 5 20 25
awk 1 2 1 17
-------------------------------------------------------------------------------
SUM: 1481 137974 164934 601047
-------------------------------------------------------------------------------By the number of lines of code, it is usually impossible to say anything definite, but here it will be very useful for evaluating the work needed to understand the engine. In the code of 601 047 lines, that is, the engine is twice "more difficult" to understand than Quake III. Some statistics about the history of id Software engines in the number of lines of code:
| Code lines | Doom | idTech1 | idTech2 | idTech3 | idTech4 |
| Engine | 39079 | 143855 | 135788 | 239398 | 601032 |
| Instruments | 341 | 11155 | 28140 | 128417 | - |
| Total | 39420 | 155010 | 163928 | 367815 | 601032 |
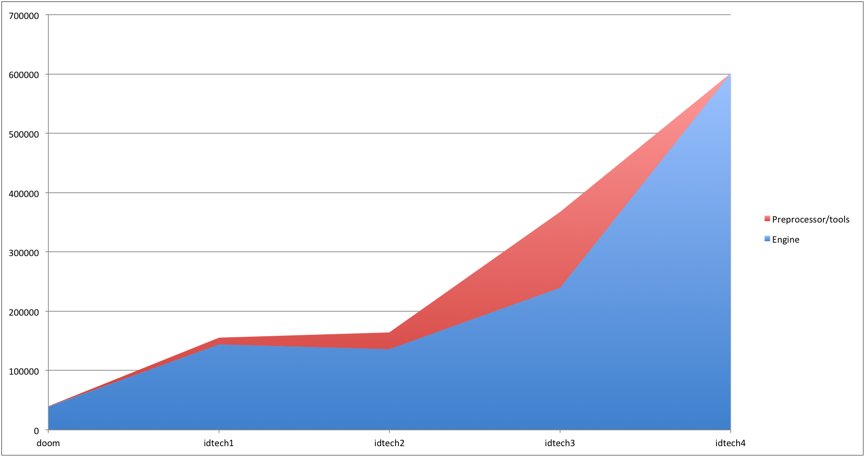
Note: A significant increase in volume in idTech3 was due to the tools from the lcc codebase (the C compiler was used to generate QVM bytecode).
Note: For Doom3, the tools are not counted, because they are included in the engine code base.
At a high level, you can see a couple of funny facts:
- For the first time in the history of id Software, the code was written in C ++ and not in C. John Carmack explained this in an interview.
- In the code abstraction and polymorphism are actively used. But an interesting trick allows you to avoid a decrease in vtable performance on some objects.
- All resources are stored in human readable text format. No more binaries. The code is actively used lexical analyzer / parser. John Carmack spoke about this in an interview.
- Templates are used in low-level helper classes (mostly in idLib), but never applied at the upper levels, so code, unlike Google V8, does not cause the eyes to bleed.
- From the point of view of commenting, this is the second quality code base of id software, only the Doom iPhone is better, perhaps because it came out later on Doom3. 30% of comments are still an outstanding result, it is very rare to find such a well-documented project! In some parts of the code (see the dmap section), there are more comments than code.
- OOP encapsulation made the code cleaner and made it easier to read.
- The days of low-level assembly optimization are over. Some tricks, for example,
idMath::InvSqrtand spatial localization optimizations have been preserved, but mostly the code simply uses the available tools (GPU shaders, OpenGL VBO, SIMD, Altivec, SMP, L2 optimization (R_AddModelSurfacesfor processing models) ...).
It is also interesting to take a look at the idTech4 Code Writing Standard ( mirror ) written by John Carmack (I am especially grateful for comments on the location of
const ).Expand the loop
Here is an analysis of the main loop with the most important parts of the engine:
idCommonLocal commonLocal; // idCommon * common = &commonLocal; // ( Init , ) int WINAPI WinMain( HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow ) { Sys_SetPhysicalWorkMemory( 192 << 20, 1024 << 20 ); //Min = 201,326,592 Max = 1,073,741,824 Sys_CreateConsole(); // , : "" ( ) . for (int i = 0; i < MAX_CRITICAL_SECTIONS; i++ ) { InitializeCriticalSection( &win32.criticalSections[i] ); } common->Init( 0, NULL, lpCmdLine ); // VRAM ( OpenGL, ) Sys_StartAsyncThread(){ // . while ( 1 ){ usleep( 16666 ); // 60 common->Async(); // Sys_TriggerEvent( TRIGGER_EVENT_ONE ); // , pthread_testcancel(); // , ( ). } } Sys_ShowConsole while( 1 ){ Win_Frame(); // / common->Frame(){ session->Frame() // { for (int i = 0 ; i < gameTicsToRun ; i++ ) RunGameTic(){ game->RunFrame( &cmd ); // GameX86.dll. for( ent = activeEntities.Next(); ent != NULL; ent = ent->activeNode.Next() ) ent->GetPhysics()->UpdateTime( time ); // } } session->UpdateScreen( false ); // { renderSystem->BeginFrame idGame::Draw // . ! renderSystem->EndFrame R_IssueRenderCommands // . . } } } } Read more about the completely disassembled cycle here . When reading the code, I used it as a map.
This is the standard for the id Software engines main cycle. With the exception of
Sys_StartAsyncThread , which means that Doom3 is multi-threaded. The task of this stream is the management of time-critical functions that the engine should not limit with the frame rate:- Sound mixing.
- Generation of user input.
Interesting fact: all idTech4 high-level objects are abstract classes with virtual methods. Typically, this reduces performance, because the address of each virtual method before calling it at runtime must be found in the vtable. But there is a “trick” to avoid this. Instances of all objects are statically created as follows:
idCommonLocal commonLocal; // idCommon * common = &commonLocal; // gamex86.dll Since the object that is statically placed in the data segment is of a known type, the compiler can optimize the search in vtable by calling the
commonLocal methods. When installing the connection (handshake), the interface pointer is used, so doom3.exe can exchange links to objects with gamex86.dll , but in this case the search costs in vtable are not optimized.Interesting fact: Having studied most of id Software's engines, I find it remarkable that one method name has NEVER changed since the doom1 engine: the method that reads mouse input and joystick data is still called
IN_frame() .Renderer
Two important parts:
- Since Doom3 uses a portal system, the
dmapcompletely different from the traditional bsp linker. I have reviewed it below in the appropriate section.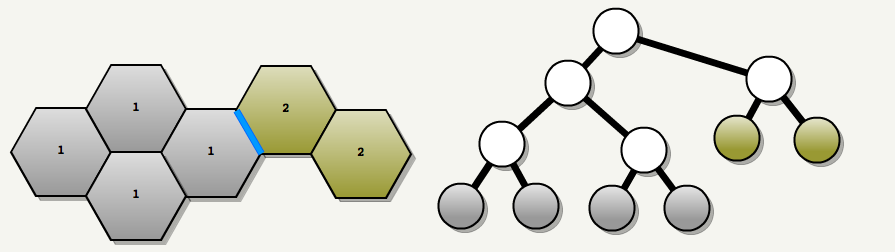
- The runtime renderer has a very interesting architecture. It is divided into two parts with a frontend and a backend (for more details, see the “Renderer” section below).
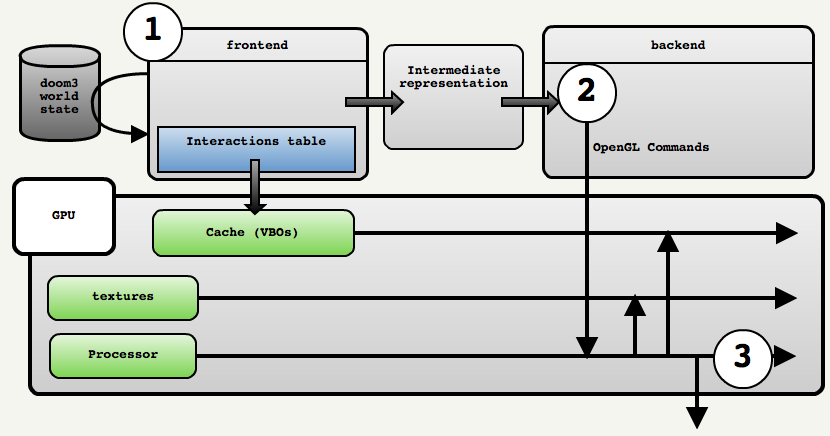
Profiling
I used Xcode Instruments to check what CPU cycles are doing. For results and analysis, see the “Profiling” section below.
Scripting and Virtual Machine
In each idTech product, the VM and the scripting language changed completely ... and id did it again (for more, see the “Script VM” section)
Interview
While reading the code, I was puzzled by some innovations, so I wrote to John Carmack and he was so kind that he answered and explained the following features in detail:
- C ++.
- Renderer splitting into two parts.
- Text resources.
- Interpreted bytecode.
In addition, I gathered on one page all the videos and interviews with the press about idTech4. All of them are collected on the interview page .
Part 2: Dmap
As with all id Software engines, maps created by a team of designers go through powerful pre-processing by the utility to increase performance at runtime.
In idTech4, this utility is called
dmap and its purpose is to read the soup from the polyhedrons from the .map file, define the areas connected by the portals and save them in the .proc file.The purpose of this tool is to use the runtime portal system in
doom3.exe . There is a terrific 1992 Seth Teller article: "Visibility Computations in Densely Occluded Polyhedral Environment" . It describes in detail and with many illustrations how the idTech4 engine works.Editor
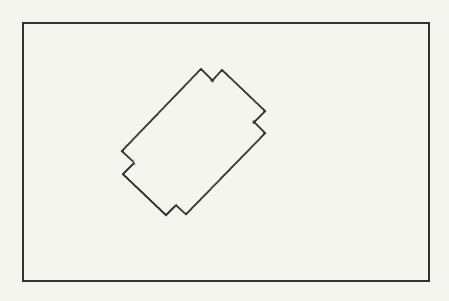
Designers create level maps using CSG (Constructive Solid Geometry): they use polyhedra, usually having six faces, and place them on the map.
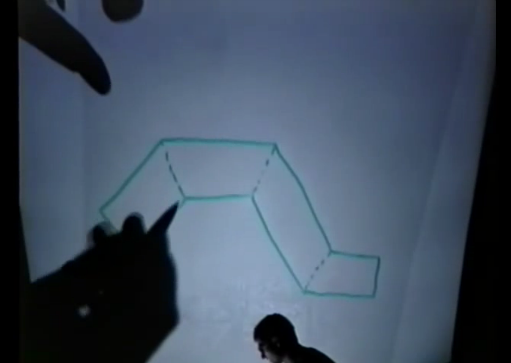
These blocks are called brushes. In the figure below, eight brushes are used (I will use the same map to explain each
dmap step).The designer may well understand what is “inside” (the first drawing), but
dmap receives only a brush soup, in which there is nothing inside or outside (the second drawing).| What the designer sees | What does Dmap see when reading brushes from a .map file? |
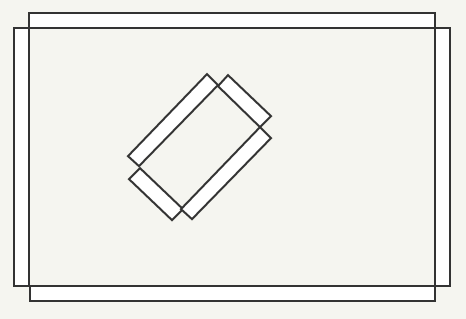 | 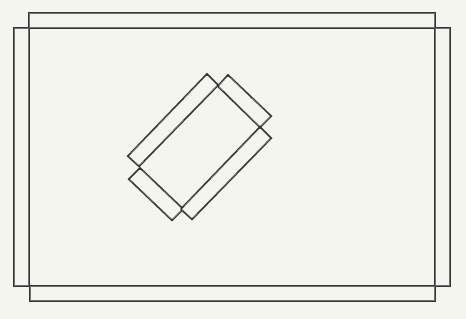 |
A brush is determined not through faces, but through planes. Defining planes instead of faces may seem inefficient, but it will be very useful later when checking whether two surfaces are on the same plane. There are no internal and external parts, because the planes are not oriented equally. The orientation of the planes may be different inside or outside the volume.
Code review
Dmap source code is very well commented, just look at this number: comments more than code!
bool ProcessModel( uEntity_t *e, bool floodFill ) { bspface_t *faces; // bsp- // faces = MakeStructuralBspFaceList ( e->primitives ); e->tree = FaceBSP( faces ); // , // MakeTreePortals( e->tree ); // FilterBrushesIntoTree( e ); // , bsp if ( floodFill && !dmapGlobals.noFlood ) { if ( FloodEntities( e->tree ) ) { // FillOutside( e ); } else { common->Printf ( "**********************\n" ); common->Warning( "******* leaked *******" ); common->Printf ( "**********************\n" ); LeakFile( e->tree ); // // "" , // -noFlood return false; } } // // , // ClipSidesByTree( e ); // , // , FloodAreas( e ); // BSP- , // , // PutPrimitivesInAreas( e ); // // , // // Prelight( e ); // - T- if ( !dmapGlobals.noOptimize ) { OptimizeEntity( e ); } else if ( !dmapGlobals.noTJunc ) { FixEntityTjunctions( e ); } // - FixGlobalTjunctions( e ); return true; } 0. Load Level Geometry
The
.map file is a list of entities. The level is the first entity in the file that has the class "worldspawn". An entity contains a list of primitives, which are almost always brushes. The remaining entities are light sources, monsters, player spawn points, weapons, etc. Version 2 // 0 { "classname" "worldspawn" // 0 { brushDef3 { ( 0 0 -1 -272 ) ( ( 0.0078125 0 -8.5 ) ( 0 0.03125 -16 ) ) "textures/base_wall/stelabwafer1" 0 0 0 ( 0 0 1 -56 ) ( ( 0.0078125 0 -8.5 ) ( 0 0.03125 16 ) ) "textures/base_wall/stelabwafer1" 0 0 0 ( 0 -1 0 -3776) ( ( 0.0078125 0 4 ) ( 0 0.03125 0 ) ) "textures/base_wall/stelabwafer1" 0 0 0 ( -1 0 0 192 ) ( ( 0.0078125 0 8.5 ) ( 0 0.03125 0 ) ) "textures/base_wall/stelabwafer1" 0 0 0 ( 0 1 0 3712 ) ( ( 0.006944 0 4.7 ) ( 0 0.034 1.90) ) "textures/base_wall/stelabwafer1" 0 0 0 ( 1 0 0 -560 ) ( ( 0.0078125 0 -4 ) ( 0 0.03125 0 ) ) "textures/base_wall/stelabwafer1" 0 0 0 } } // 1 { brushDef3 } // 2 { brushDef3 } } . . . // 37 { "classname" "light" "name" "light_51585" "origin" "48 1972 -52" "texture" "lights/round_sin" "_color" "0.55 0.06 0.01" "light_radius" "32 32 32" "light_center" "1 3 -1" } Each brush is described as a set of planes. The sides of the brush are called faces (or bends), each of which is obtained by trimming the plane with all the other planes of the brush.
Note: The very interesting and fast Plane Hashing System is used during the boot phase:
idHashIndex created on top of idPlaneSet , which you should look at.1. MakeStructuralBspFaceList and FaceBSP
The first step is to cut the map using the binary space partitioning method (Binary Space Partition). Each non-transparent face of the card is used as a dividing plane.
The following heuristics are used to select a separator:
1: if the map contains more than 5000 units: we cut it with the help of an axis-oriented plane (Axis Aligned Plane) in the middle of the space. In the figure below, the space 6000x6000 is cut three times.
2: When there are no more parts left over 5000 units: we use faces marked as “portals” (they have the
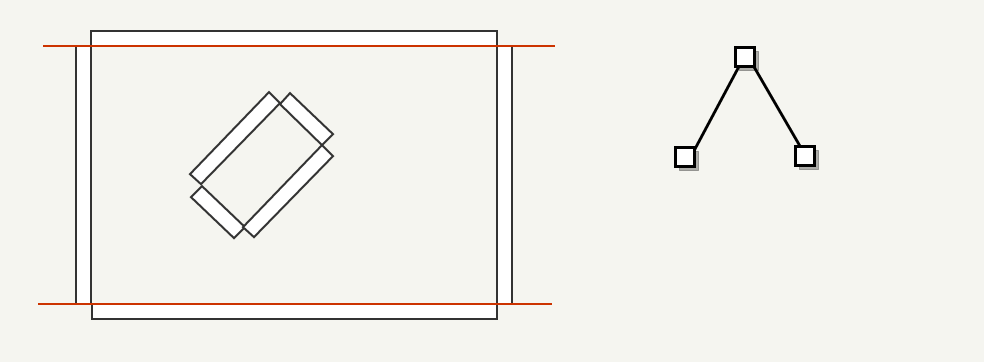
textures/editor/visportal ). In the figure below the portals are marked in blue.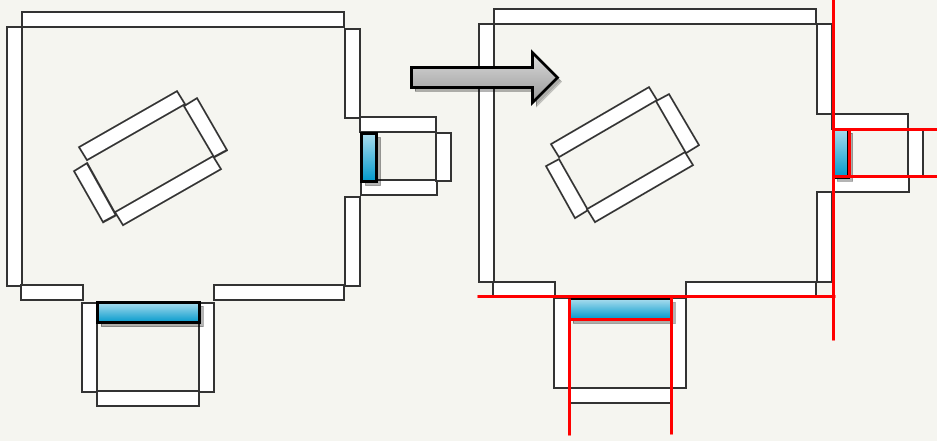
3: Use the remaining faces. We select the edge that is the most collinear with the majority of others. And we cut the smallest faces. Also preference is given to axial dividers. Separation planes are marked in red.
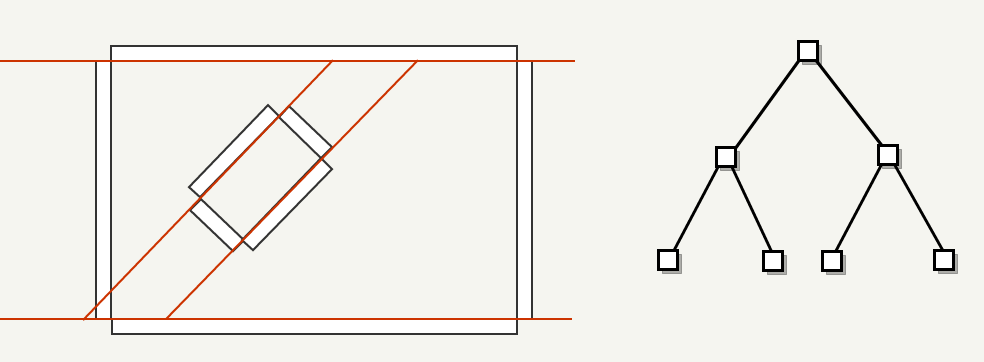
The process ends when there are no available faces: the entire sheet of the BSP-tree is a convex subspace:
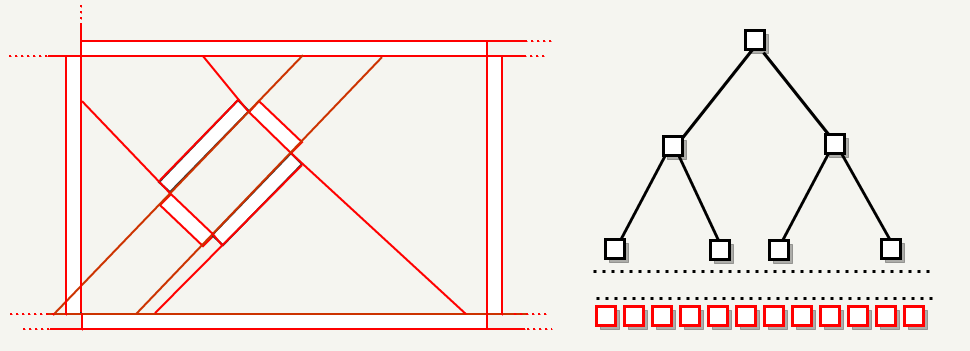
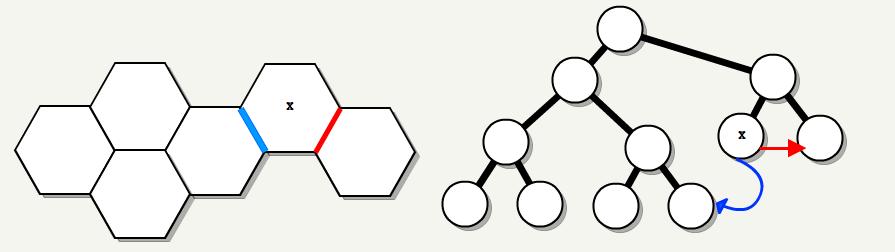
2. MakeTreePortals
Now the map is divided into convex subspaces, but these subspaces do not know anything about each other. The goal of this stage is to connect each of the leaves with its neighbors using the automatic creation of portals. The idea is to start with six portals that restrict the map: connect the “external” with the “internal” (with the BSP root). Then, for each node in the BSP, we divide each portal in the node, add a dividing plane as a portal, and repeat it recursively.
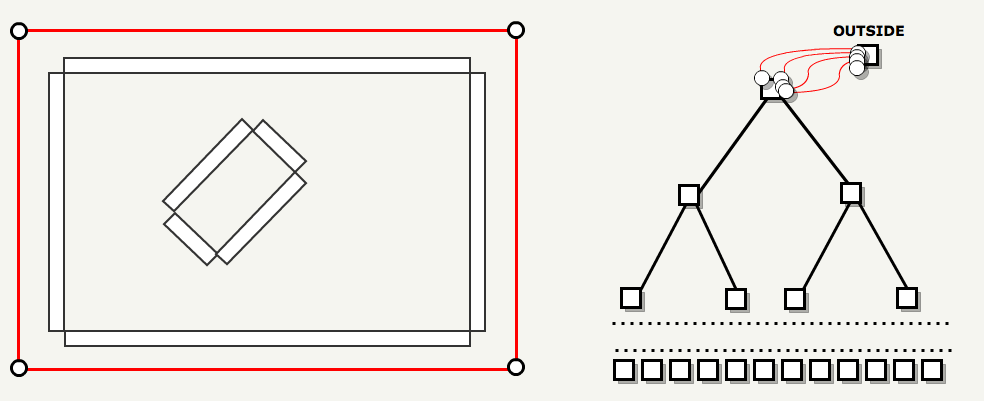
, . , , : .
-«» BSP-. . , , «» «».
, :
BSP , , :
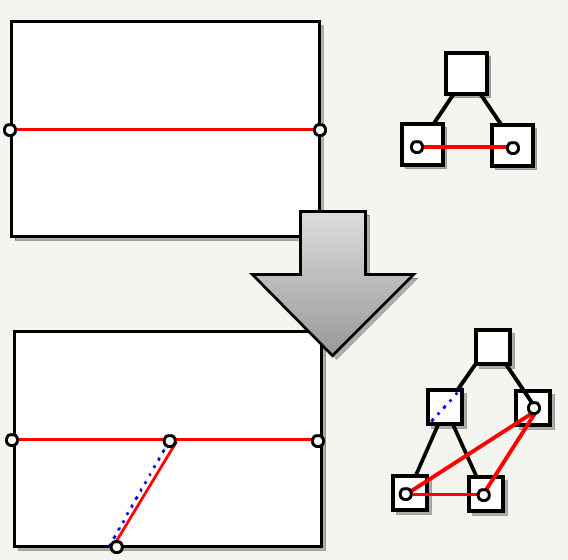
3. FilterBrushesIntoTree

, BSP — , — . BSP .
: , , EPSILON, , .
«» «» .
, , () .
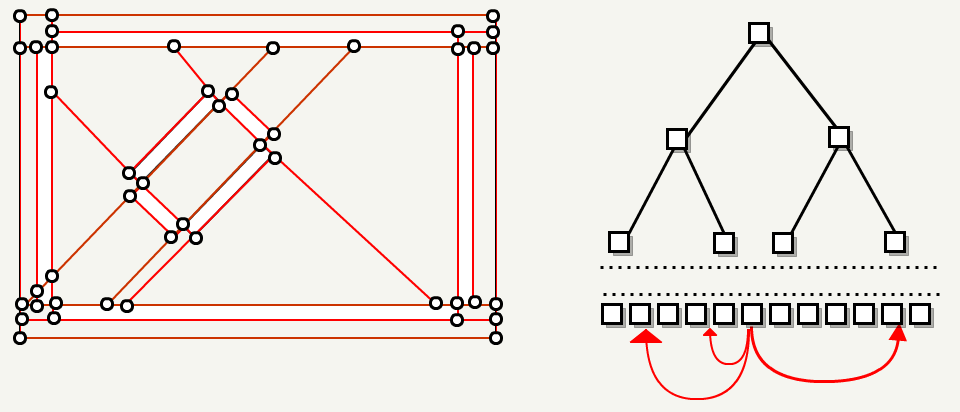
4. FloodEntities FillOutside
. .
FillOutside , .
, , : .
5. ClipSidesByTree
: BSP. , .
visibleHull .«» , .
visibleHull .6. FloodAreas
dmap : . , .: , visportals ( , 1).
dmap .. () , visportal (, areaportal), , :
().
7. PutPrimitivesInAreas
« » , 6 visibleHull, 5: — , — visibleHull.
visibleHull BSP: areaID.
: — . «func_static», . «» , ( ).
8. Prelight
dmap . .proc . , "_prelight_light" , , .map .proc : shadowModel { /* name = */ "_prelight_light_2900" /* numVerts = */ 24 /* noCaps = */ 72 /* noFrontCaps = */ 84 /* numIndexes = */ 96 /* planeBits = */ 5 ( -1008 976 183.125 ) ( -1008 976 183.125 ) ( -1013.34375 976 184 ) ( -1013.34375 976 184 ) ( -1010 978 184 ) ( -1008 976 184 ) ( -1013.34375 976 168 ) ( -1013.34375 976 168 ) ( -1008 976 168.875 ) ( -1008 976 168.875 ) ( -1010 978 168 ) ( -1008 976 167.3043518066 ) ( -1008 976 183.125 ) ( -1008 976 183.125 ) ( -1010 978 184 ) ( -1008 976 184 ) ( -1008 981.34375 184 ) ( -1008 981.34375 184 ) ( -1008 981.34375 168 ) ( -1008 981.34375 168 ) ( -1010 978 168 ) ( -1008 976 167.3043518066 ) ( -1008 976 168.875 ) ( -1008 976 168.875 ) 4 0 1 4 1 5 2 4 3 4 5 3 0 2 1 2 3 1 8 10 11 8 11 9 6 8 7 8 9 7 10 6 7 10 7 11 14 13 12 14 15 13 16 12 13 16 13 17 14 16 15 16 17 15 22 21 20 22 23 21 22 18 19 22 19 23 18 20 21 18 21 19 1 3 5 7 9 11 13 15 17 19 21 23 4 2 0 10 8 6 16 14 12 22 20 18 } 9. FixGlobalTjunctions
- , idTech4 : . - .
10.
.proc :- .
- BSP- areaID .
- .
- .
Story
dmap , Quake ( qbsp.exe ), Quake 2 ( q2bsp.exe ) Quake 3 ( q3bsp.exe ). , (PVS) :qbsp.exe.map.prt, BSP ( 2 «MakeTreePortals»).vis.exe.prt. :- .
- before filling into a sheet: a visibility check was performed by cutting off the next portal with two previous portals relative to the visibility pyramid (many believed that visibility is determined by the emission of thousands of rays, but this is a myth that many people believe now).
The illustration is always better: let's say I
qbsp.exefound six leaves connected by portals and is now executed vis.exeto generate PVS. This process will be performed for each sheet, but in this example we will consider only sheet 1.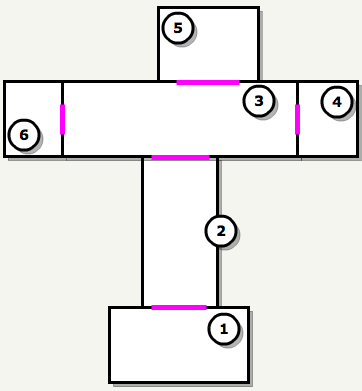
Since the sheet is always visible from itself, the initial PVS for sheet 1 will be as follows:
| Sheet identifier | one | 2 | 3 | four | five | 6 |
| Bit Vector (PVS for Sheet 1) | one | ? | ? | ? | ? | ? |
: , , . , 3 PVS:
| one | 2 | 3 | four | five | 6 | |
| (PVS 1) | one | one | one | ? | ? | ? |
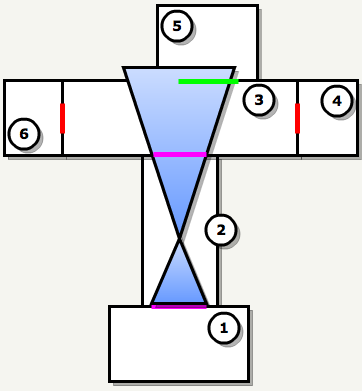
3 : n-2 n-1, .
, , 4 6 , 5 . 6. PVS 1 :
| one | 2 | 3 | four | five | 6 | |
| (PVS 1) | one | one | one | 0 | one | 0 |
idTech4 PVS , . .
: 10 GDC Vault ( ):
 .
.3:
idTech4 :
- «Unified Lighting and Shadows»: .
- «Visible Surface Determination»: VSD — PVS.
- «Multi-pass Rendering».
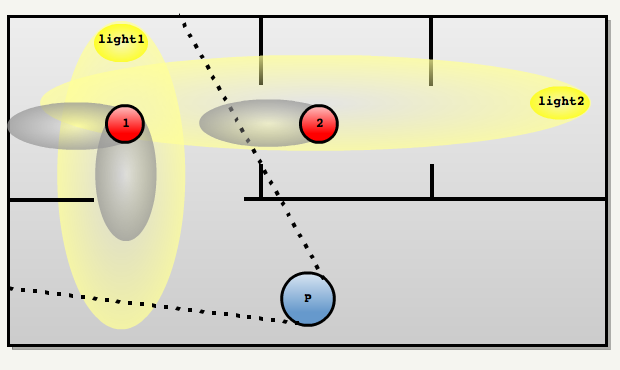
The most important in idTech4 has become a multi-pass renderer. The influence of each light source in the field of visibility is accumulated in the frame buffer of the video processor by means of additive mixing. Doom 3 takes full advantage of the fact that the color registers of the frame buffer perform saturation rather than transfer. I created my own level to illustrate additive blending. The screenshot below shows three sources of light in the room, for which three passes are made. The result of each pass is accumulated in the frame buffer. Notice the white light in the center of the screen where all the light sources are mixed. I changed the slider to isolate each pass: Pass 1: blue light source Pass 2: green light Pass 3: red light
() :
============================
1111 1111
+ 0000 0100
---------
= 0000 0011
() :
==========================
1111 1111
+ 0000 0100
---------
= 1111 1111



, :

: , Photoshop (Linear Dodge OpenGL) .
(bumpmapping) 2012 :

Architecture
idTech, , ( ):
- :
- , .
- (
def_view_t) / VBO . - RC_DRAW_VIEW.
- :
- RC_DRAW_VIEW .
- VBO.
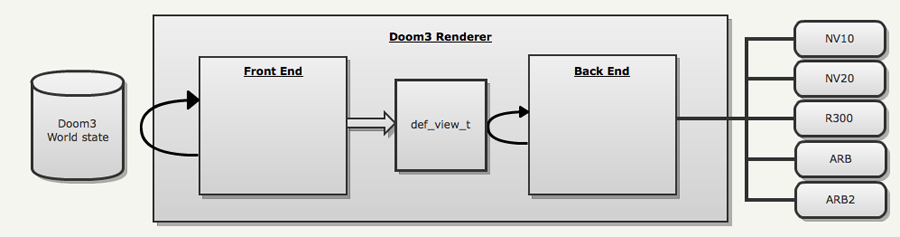
- LCC , - Quake3:
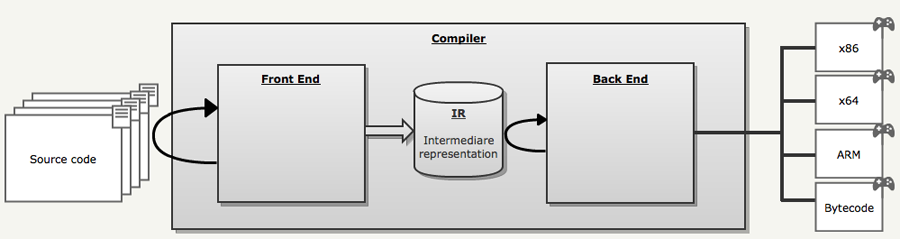
, LCC, , SMP-. , — . , - .
: — , , C++ C ( ):
- . idTech4 Quake3 ( C), C++. idtech4 C++.
Quake Doom3? , , Mac OS X:
- (void)quakeMain; , ,
, :
- :
- , , . .
- , , . VBO .
- . OpenGL , . VBO .
- OpenGL .
Doom3
: (Visible Surface Determination, VSD). — , . . , ( « »). , OpenGL.
Here is how it looks in code:
- idCommon::Frame - idSession::UpdateScreen - idSession::Draw - idGame::Draw - idPlayerView::RenderPlayerView - idPlayerView::SingleView - idRenderWorld::RenderScene - build params - ::R_RenderView(params) // { R_SetViewMatrix R_SetupViewFrustum R_SetupProjection // . static_cast<idRenderWorldLocal *>(parms->renderWorld)->FindViewLightsAndEntities() { PointInArea // BSP FlowViewThroughPortals // , , . } R_ConstrainViewFrustum // Z- . R_AddLightSurfaces // , , ( ) R_AddModelSurfaces // ( ) R_RemoveUnecessaryViewLights R_SortDrawSurfs // qsort C. C++ . R_GenerateSubViews R_AddDrawViewCmd } : C C++.
, . visplanes :
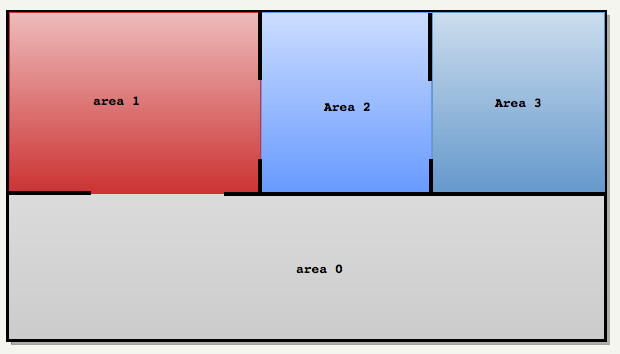
.proc .map , . , :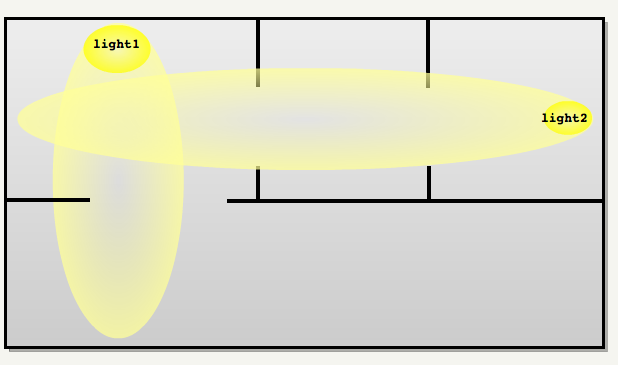
1 :
=========
- 0
- 1
2 :
=========
- 1
- 2
- 3, . .
:
- , BSP-
PointInArea. FlowViewThroughPortals: . . Realtime rendering :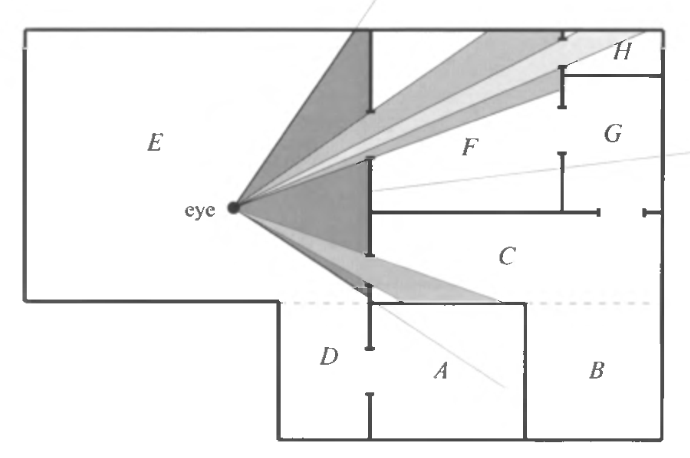
, , , :( /) :
==================================
1 - 0
1 - 1
1 - 1
2 - 1
2 - 1
: « 2 — 2», 2 .R_AddLightSurfaces, , .( /) :
==================================
1 - 0
1 - 1
1 - 1
2 - 1
2 - 1
2 - 2R_AddModelSurfaces: , VBO , . ( ).- «» .
R_AddDrawViewCmdRC_DRAW_VIEW, .
Doom3
: Doom3 :
- R10 (GeForce256)
- R20 (GeForce3)
- R200 (Radeon 8500)
- ARB (OpenGL 1.X)
- ARB2 (OpenGL 2.0)
For 2012, only ARB2 is supported by modern video processors: standards ensured not only portability, but also increased the lifespan of the game.
If the video card supported bumpmapping (a tutorial on using Hellknight, which I wrote several years ago) and reflection maps, idtech4 included them, but they all tried to save pixel fillrate speed (fillrate) with the following operations as much as possible :
- OpenGL Scissor test (separately for each light source created by the front end)
- Filling the Z-buffer in the first stage.
Below is the expanded backend code:
idRenderSystemLocal::EndFrame R_IssueRenderCommands RB_ExecuteBackEndCommands RB_DrawView RB_ShowOverdraw RB_STD_DrawView { RB_BeginDrawingView // z-, .. RB_DetermineLightScale RB_STD_FillDepthBuffer // ( ) . // , _DrawInteractions { 5 GPU specific path switch (renderer) { R10 (GeForce256) R20 (geForce3) R200 (Radeon 8500) ARB (OpenGL 1.X) ARB2 (OpenGL 2.0) } // qglStencilFunc( GL_ALWAYS, 128, 255 ); RB_STD_LightScale // (, , ....) int processed = RB_STD_DrawShaderPasses( drawSurfs, numDrawSurfs ) // RB_STD_FogAllLights(); // _currentRender if ( processed < numDrawSurfs ) RB_STD_DrawShaderPasses( drawSurfs+processed, numDrawSurfs-processed ); } To go step by step through the backend, I took the famous screen from the Doom3 level and stopped the engine at each stage of rendering:

Since Doom3 uses bumpmapping and reflection maps over diffuse textures, rendering the surface can use a search in three textures. Up to 5-7 light sources can affect a pixel, so it’s not crazy to assume that up to 21 texture searches per pixel can be assumed ... even without redrawing. The first stage of the backend is needed to achieve 0 redraws: turning off all shaders, writing only to the depth buffer and rendering the whole geometry:

The depth buffer is now full. From this point on, the depth recording is disabled and the depth test is enabled.
Rendering primarily in z-buffer may seem counterproductive, but in fact it is extremely useful to save fillrate:
- .
- .
- ( ), . .
Note that the color buffer is cleared and filled with black: in its natural form, the world of Doom3 is totally black, because there is no “ambient” lighting — to be visible, the polygon / surface must interact with the light source. That explains why Doom3 was so dark!
After that, the engine will perform 11 passes (one for each light source.
I divided the rendering process into parts. The pictures below show each individual light source passage.

Effect of light source 1

Effect of light source 2

Effect of light source 3

Effect of light source 4

Effect of light source 5

Effect of light source 6

Effect of light source 7

Effect of light source 8

Effect of light source 9

Influence of the light source 10

Influence of the light source 11

Last pass: passage of ambient lighting
And now what happens in the video processor frame buffer:

After passing the light source 1

After passing the light source 2

After passing the light source 3

After passing the light source 4

After passing the light source 5

After the passage of the light source 6

after passage of the light source 7

after passage of the light source 8

after the passage of the light source 9

after passage of the light source 10

after passage of the light source 11

after passage of the light source 12
R follows the light source 13 passes
Buffer templates and Scissors test:
, . depth-fail/depth pass Creative Labs. (depth pass), . - depth fail, — !
fillrate, , scissor test OpenGL. , - .
8. , : .

7. scissor fillrate.
<img src=« fd.fabiensanglard.net/doom3/renderer/DOOM3-Context3-Static-StencilBuffer2.png »
—
RB_STD_DrawShaderPasses : , . . . , . 2004 . , Doom III :Stages:
- .
- .
- .
- , , !
, , , - . , , . : idTech4 . RoQ: , , id Software.
:
RoQ 2005 :
- 30 .
- 512x512:
idCinematicLocal::ImageForTimeOpenGL.
.
- Doom 1 !
: Doom3 (, ..).
...
— , .
4:
XCode : Instruments . ( ).
Overview

, :
- , .
- , .
- ( 8% ), CoreAudio
idAudioHardwareOSX(: OpenAL, ).
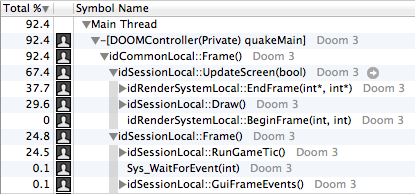
Doom 3 …
QuakeMain ! , , Quake 3 Mac OS X . :- 65% (
UpdateScreen). - 25% : , id Software.
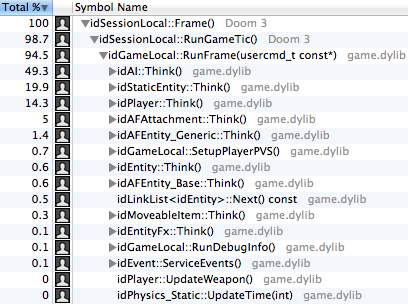
gamex86.dll ( game.dylib Mac OS X):
25% , . :
- (): . - , , .
- The physics engine is more complicated (linear complementarity solvers), and therefore more costly compared to previous games. It is executed for each object and includes ragdoll modeling and resolving interactions.
Renderer
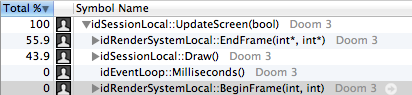
As written above, the renderer consists of two parts:
- Frontend (
idSessionLocal::Draw) takes 43.9% of the rendering process. It's worth noting that thisDrawis a rather inappropriate name, because the frontend does not perform a single OpenGL draw call! - Backend (
idRenderSessionLocale:EndFrame) takes 55.9% of the rendering process.
The load distribution is quite balanced, and this is not surprising:
- The frontend performs many calculations relating to the definition of visible surfaces.
- Also, the frontend is engaged in animating models and finding shadow silhouettes.
- .
- (:
glDrawElements).
:
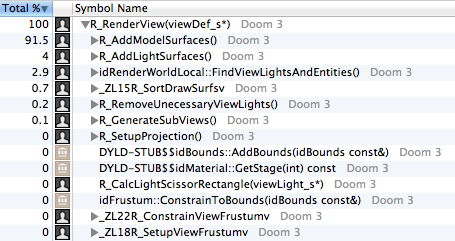
:
, ́ (91%) VBO (
R_AddModelSurfaces ). (4%) ( R_AddLightSurfaces ). (2,9%) : BSP .:
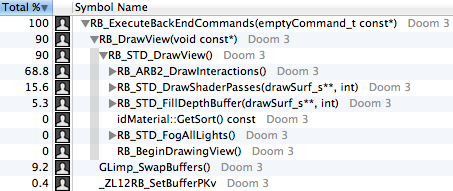
:
, (
GLimp_SwapBuffers ) (10%) , . 5% — , Z- ( RB_STS_FillDepthBuffer ).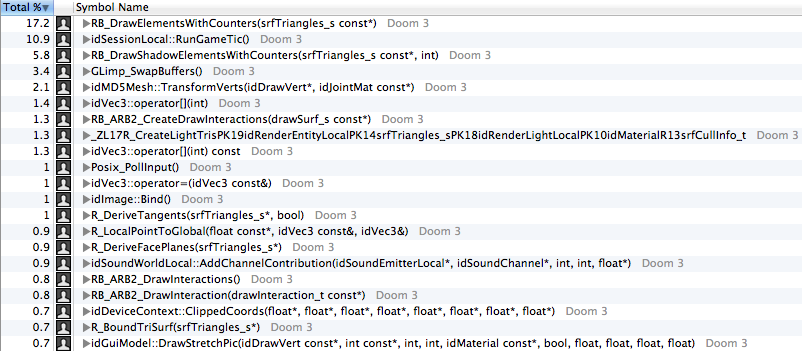
Instruments , .
4:
, idTech1 idTech3, :
- idTech1: QuakeC, .
- idTech2: C, x86 ( ).
- idTech3: C, LCC -, QVM (Quake Virtual Machine). x86 - .
idTech4 , :
Doom3 Scripting SDK .
Architecture
Here is a general picture:
Compilation: at boot time,
idCompilerone predefined file is transferred .script. A series of directives #includecreates a script stack containing the lines of all scripts and the source code of all functions. It is scanned idLexer, generating base tokens (tokens). Tokens come in idParserand generate one huge byte code that is stored in the singleton idProgram: it represents the virtual machine's RAM and contains VM segments .textand .data.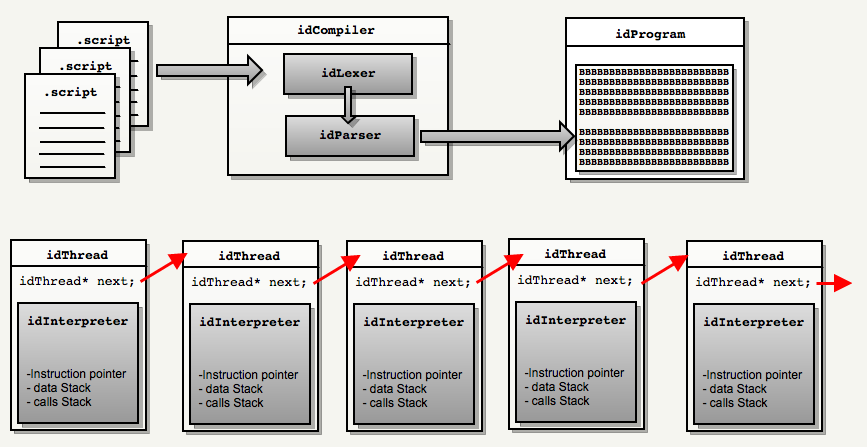
Virtual machine: During execution, the engine assigns each thread the
idThreadtime of the real CPU (one after the other) until it reaches the end of the linked list. Each idThreadcontainsidInterpreterstoring the state of the virtual machine CPU. Unless the interpreter goes mad and does not perform more than 5 million instructions, it will not be able to empty the CPU: this is joint multitasking.Compiler
The compilation pipeline is similar to what you will see when reading any other compiler, such as Google V8 or Clang, except for the absence of a preprocessor. Therefore, functions such as “pass comments”, macros, directives (# include, # if) must be executed in the lexical analyzer and in the parser.
Since it is
idLexeractively used by the entire engine for parsing all text resources (maps, entities, camera routes), it is very primitive. For example, it returns a total of five types of tokens:- TT_STRING
- TT_LITERAL
- TT_NUMBER
- TT_NAME
- TT_PUNCTUATION
Therefore, the parser does much more work than in the “standard” compiler pipeline.
When you start the game idCompiler loads the first script
script/doom_main.script, the series #includecreates a stack of scripts, connected into one huge script.It seems that the engine parser is a standard descending parser with a recursive descent. It seems that the grammar of the scripting language is LL (1), requiring 0 returns (even though the lexical analyzer has the ability to cancel the reading of one lexeme). If you have already read this book , then do not get lost ... and if not, then this is a good reason to start to understand.
Interpreter
idThread , , . . idThread idInterpreter , , ( /, ).idInterpreter::Execute , : . idThread::Execute bool idInterpreter::Execute(void) { doneProcessing = false; while( !doneProcessing && !threadDying ) { instructionPointer++; st = &gameLocal.program.GetStatement( instructionPointer ); //op - (unsigned short), 65 535 switch( st->op ) { . . . } } } ,
idInterpreter , idThread::Execute , , . Another World .: - x86, . , Doom3 JIT- x86, Quake3.
Source: https://habr.com/ru/post/333836/
All Articles