We copy the human brain: operation "Convolution"
What have convolution artificial neural networks (INS) already learned and how are they arranged?
1. Preface
Such articles are made to begin with an excursion into history in order to describe who invented the first ANNs, how they are arranged and pour on other, useless, for the most part, water. Boring Omit it. Most likely you can imagine, at least figuratively, how the simplest ANNs work. Let's agree to treat classic neural networks (such as a perceptron), in which there are only neurons and connections, like a black box that has an input and an output, and which can be trained to reproduce the result of a certain function. The architecture of this box is not important to us, it can be very different for different cases. The tasks they solve are regression and classification.
2. Breakthrough
What has happened in recent years that caused the rapid development of the INS? The answer is obvious - this is technical progress and the availability of computing power.
I will give a simple and very illustrative example:
2002:

Earth Simulator is one of the fastest computing systems in the world. It was built in 2002. Until 2004, this machine remained the most powerful computing device in the world.
Cost : $ 350,000,000.
Area : four tennis courts,
Performance : 35,600 gigaflops.
2015:
NVIDIA Tesla M40 / M4: GPU for Neural Networks
Cost : $ 5000
Area : fits in pocket,
Performance : Up to 2.2 Teraflops performance in single-precision operations with NVIDIA GPU Boost
The result of such a rapid growth of productivity was the general availability of resource-intensive mathematical operations, which made it possible to test the theories that had long been born in practice.
3. Convolution operation.
One of the resource-intensive theories in the implementation, or rather the method that requires very large powers, is the convolution operation.
What is it? Let's try to sort everything out:
Cats
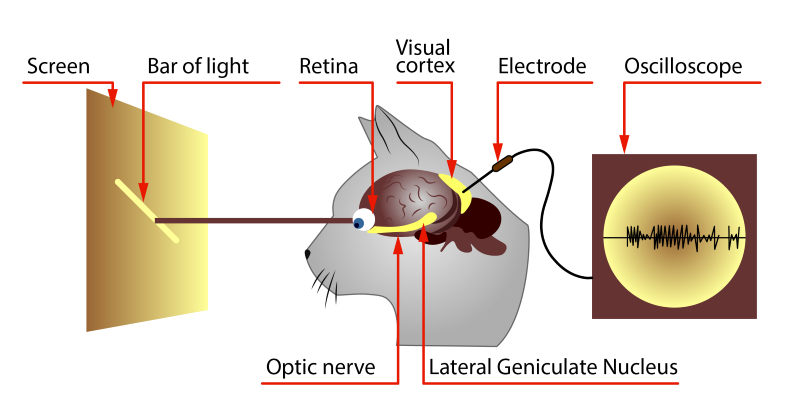
Experimenting on animals, David Hubel and Torsten Wiesel found out that the same image fragments, the simplest forms, activate the same brain areas. In other words, when the cat sees the circle, then the “A” zone is activated in it, when the square is, then “B”. And this inspired scientists to write a paper in which they presented their ideas on the principles of work of sight, and then they confirmed it with experiments:
The conclusion was something like this:
In the brain of animals there is an area of neurons that responds to the presence of a particular feature in the image. Those. before the image enters the depths of the brain, it passes the so-called feature extractor.
Maths

Graphic editors have long used mathematics to change the style of an image, but as it turned out, the same principles can be applied in the field of pattern recognition.
If we consider a picture as a two-dimensional array of points, each point is like a set of RGB values, and each value is just an 8-bit number, then we get a completely classical matrix. Now we will take and invent our own, let's call it Kernel, the matrix, and it will be like this:
')

Let's try to go through all the positions, from the beginning to the end of the image matrix and multiply our Kernel into a plot with the same size, and the results will form the output matrix.
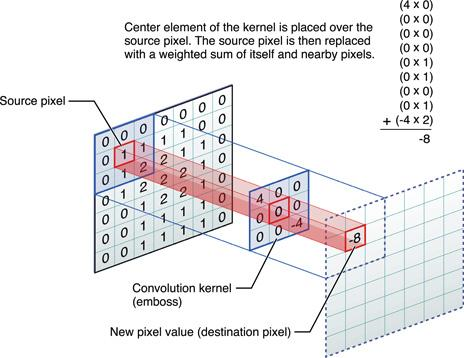
Here is what we get:

Looking at the Edge Detection section, we will see that the result is a face, i.e. we can easily pick up such Kernels, which at the output will define lines and arcs of different directions. And this is exactly what we need - features of the first level image. Accordingly, we can assume that by applying the same actions once again, we will get combinations of features of the first level - features of the second level (curves, circles, etc.) and this could be repeated many times if we were not limited in resources.
Here is an example of Kernel matrix sets:


And this is how a feature-extractor looks from layer to layer. On the fifth layer, very complex features are already being formed, for example, eyes, images of animals and other types of objects on which the extractor has been trained.

At first, the developers themselves tried to select Kernel, but it soon became clear that it can be obtained by training, and this is much more efficient.
Underwater rocks
Having understood how the cats' brains work and how to apply the mathematical apparatus, we decided to create our own extractor feature! But ... having thought how many features we need to extract, how many levels of extraction we need and, having figured that in order to find complex images we have to analyze combinations of features “each with each”, we realized that we don’t have enough memory to store all this.
Mathematicians came to the rescue again and came up with a pooling operation. Its essence is simple - if in a certain area there is a high-level feature, then others can be thrown away.

Such an operation not only helps to save memory, but also eliminates debris and noise in the image.
In practice, the layers of convolution and merge alternate several times.
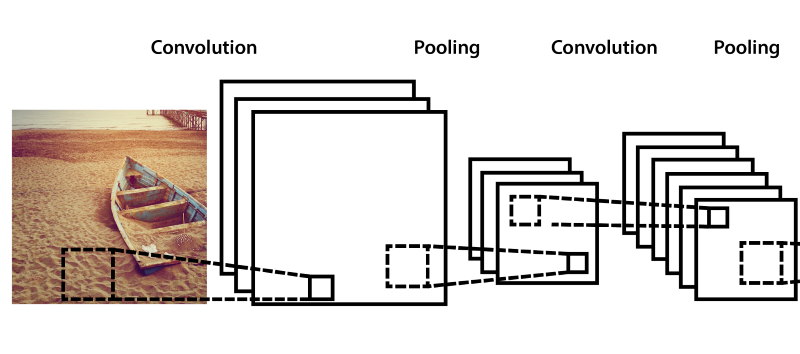
Final architecture
By applying everything described above, you can get a completely working architecture of a feature extractor, no worse than a cat in the head, moreover, at present, computer vision recognition accuracy in some cases reaches> 98%, and, as scientists have calculated, accuracy human image recognition averages 97%. The future has come, Skynet is coming!
Here are examples of several schemes of real feature extractors:
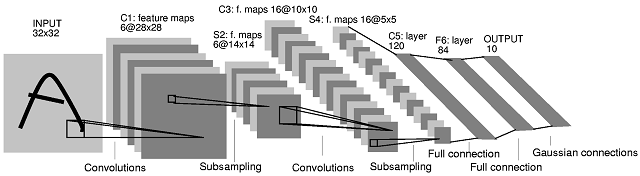

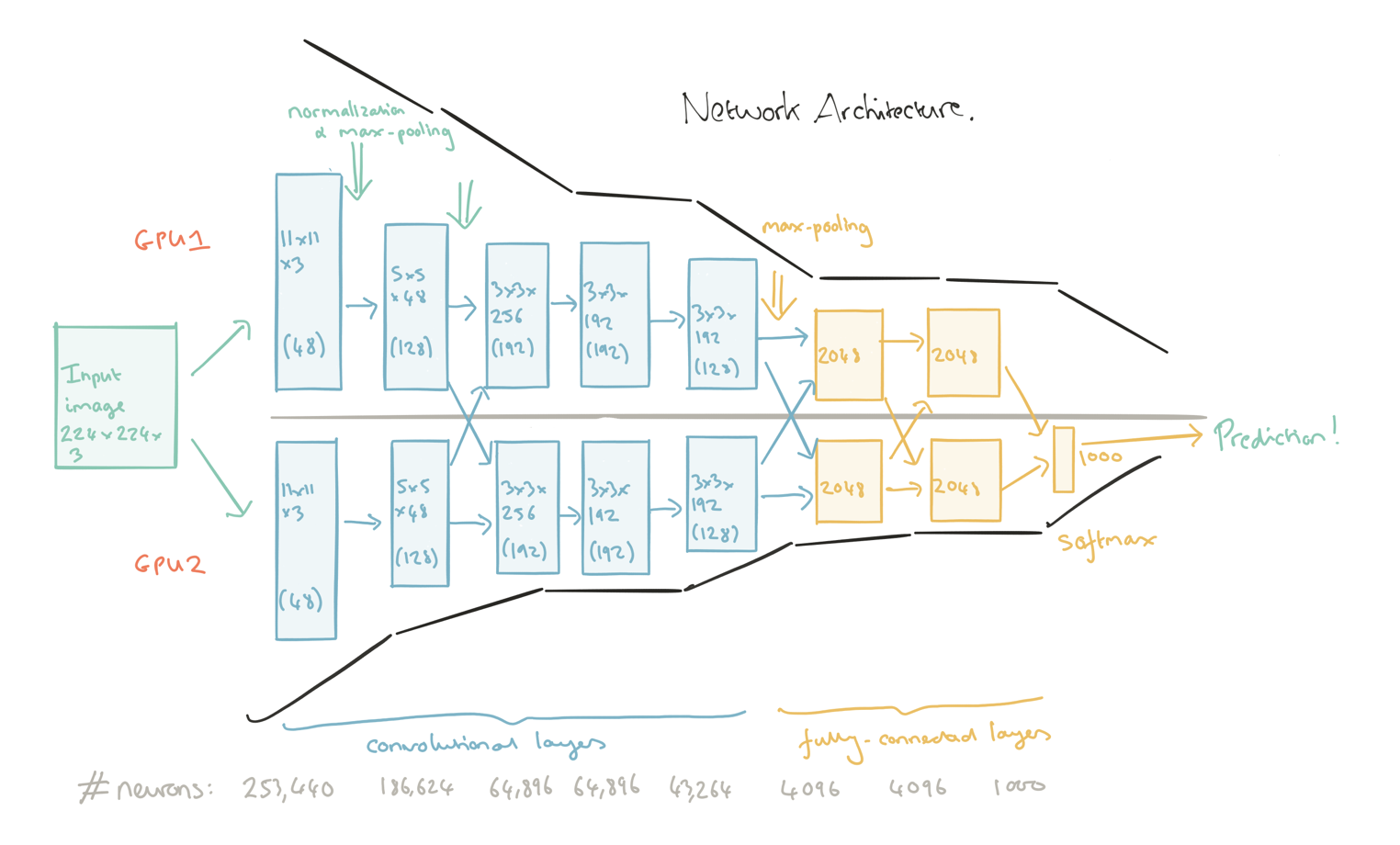
As you can see, at each end there are 2-3 more layers of neurons at the end. They are not part of the extractor, they are our black box from the preface. Only here, when recognizing the input of the box, not just the colors of the pixels, as in the simplest networks, are served, but the fact of the presence of a complex feature that the extractor was trained on. Well, it’s also easier for you to determine what is in front of you, for example, the face of a person, if you see the nose, eyes, ears, hair, than if you were called separately the color of each pixel?
This video simply demonstrates how feature extractors work:
4. Who runs the show?
1. Tensorflow
Free software library for machine learning. Virtually everything that makes Google’s services so smart uses this library.
An example of what Inception-v3 gives (Google's image classifier, built on Tensorflow) and trained on the ImageNet image set:

2. MS Cognitive Services (The Microsoft Cognitive Toolkit)
Microsoft has gone the other way, it provides ready-made APIs, both for money and for free, for the purpose of familiarization, but limiting the number of requests. API - very extensive, solve dozens of tasks. All this can be tried right on their website.
You can, of course, use MSCT in the same way as TF, even the syntax and the idea are very similar, both describe the stubs column, but why waste time when you can use already trained models?
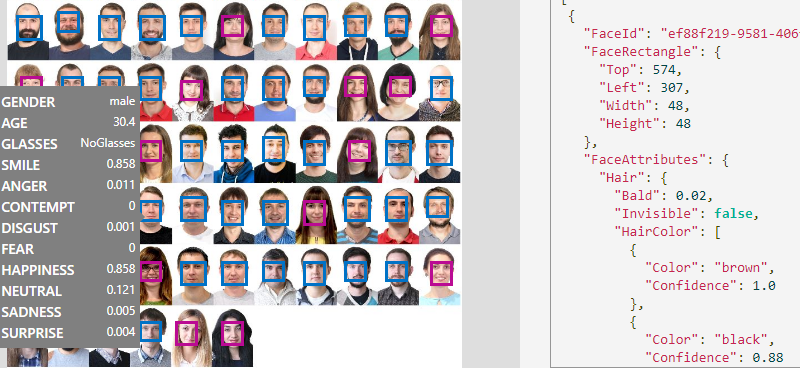
3. Caffe (Caffe2)
An open library, a framework on which to build any architecture. Until recently, was the most popular. There are many ready-made (trained) free network models on this framework.
A striking example of the use of Caffe:
Rober Bond, using a network that has been trained in cat recognition, built an automated propeller for cats from his lawn, which, when he detects a cat in a video, pours water on him.

There are many more different libraries popular in their time, wrappers, add-ons: BidMach, Brainstorm, Kaldi, MatConvNet, MaxDNN, Deeplearning4j, Keras, Lasagne (Theano), Leaf, but Tensorflow is considered the leader due to its rapid growth over the past two years .
5. Scopes (instead of the conclusion)
At the end of the article I want to share some vivid examples of the use of convolutional networks:
| Application area | Comments | Links |
|---|---|---|
| Handwriting Recognition | Accuracy of a person - 97.5% CNN - 99.8% | Visualization of images of a trained network in TF , JS interactive visualization of convolution work , MNIST |
| Computer vision | CNN recognizes not only simple objects in the photo, but also emotions, actions, and also analyzes video for autopilots (semantic segmentation). | Emotions , Semantic segmentation , Skype Caption bot , Google Image search |
| 3D reconstruction | Creating 3D models for video | Deep stereo |
| Entertainment | Stylization and generation of images | Deep dream , Deep style , Style transfer to video , Generation of faces , Generation of various objects |
| A photo | Improving quality, color | Face Hallucination , Colorizing |
| The medicine | Drug creation | |
| Security | Detection of abnormal behavior (Convolution + Recurrence) | Example 1 , 2 , 3 |
| Games | As a result, the network plays steeper than the professional, knocking out a hole and specifically driving the ball there. | Atari breakout |
Source: https://habr.com/ru/post/333772/
All Articles