Fast data recovery. Regeneration butterfly pattern

For the codes described in the previous article about data recovery , a problem formulation was assumed, which minimizes the number of disks required for a recovery operation. In [2], the use of network coding to data storage problems is discussed, which has received considerable attention from researchers in recent years. Here it is not the optimization of the number of disks required for data recovery, but the minimization of the network traffic that occurs.
Suppose the storage system consists of n nodes. Consider a file consisting of B characters of the GF (q) field, which is encoded in nα characters over GF (q) and distributed among the nodes, so that each node stores α characters. The code is constructed in such a way that the data can be completely recovered from information from k nodes. In this case, to restore the data of a single node, it suffices to obtain β ≤ α information from d nodes [1,2], see fig. 1. The value γ = dβ is called the repair bandwidth.
In [2] it is shown that the size of data B is bounded above:

Figure 1. Regeneration Code
')
For fixed values ( B, k, d ) there is a set of pairs (α, β) that satisfy this boundary, which makes it possible to obtain a compromise on these parameters, with two extreme points: minimizing the value of the common storage nα (this point is called “recovery with minimum storage, ”or MSR , Minimum Storage Regeneration) and minimizing the range γ = dβ (this point is called“ recovery with a minimum range, ”or MBR , Minimum Bandwidth Regeneration). Codes that satisfy the above boundary are called regenerating codes. An example of the corresponding boundary is shown in Fig. 2 [2].
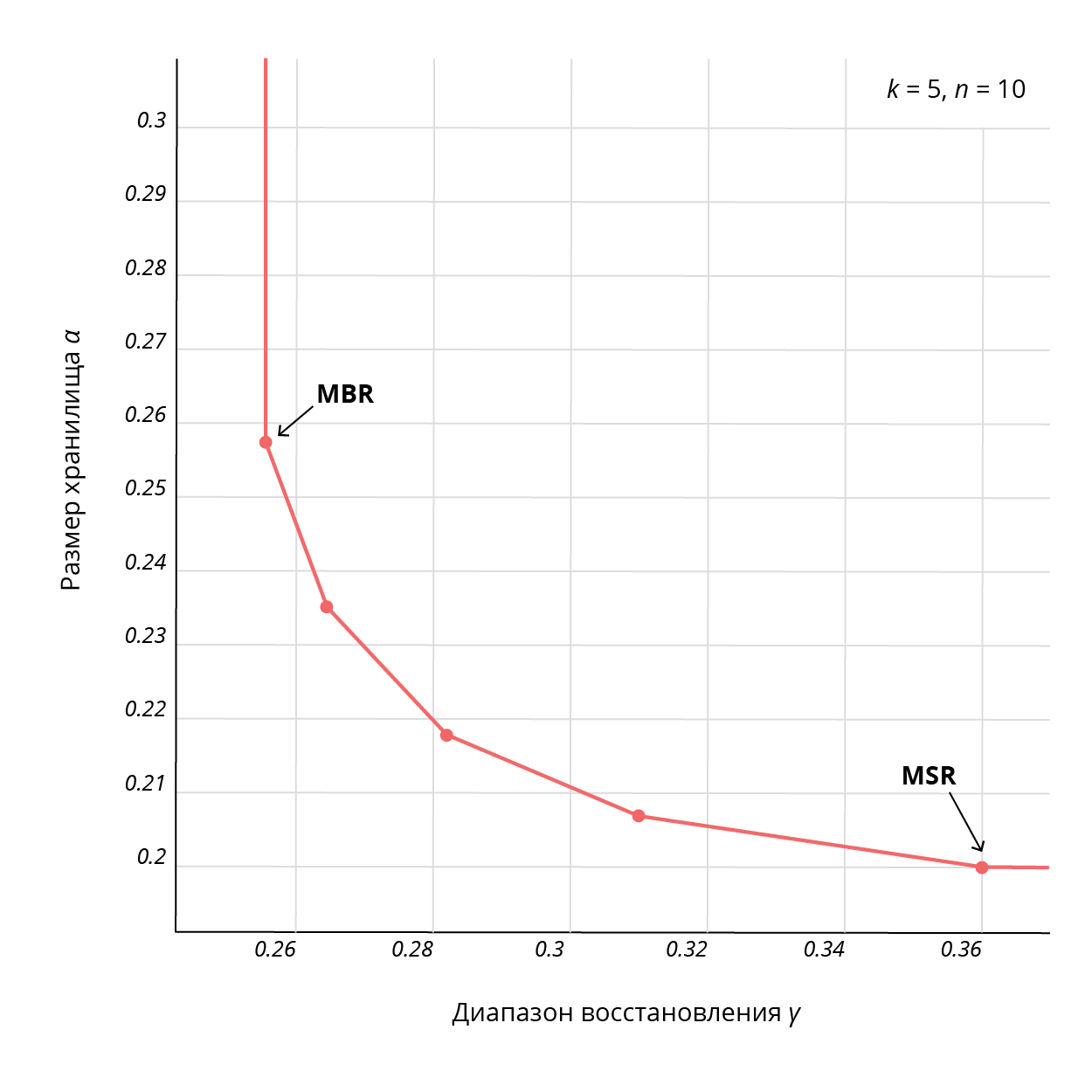
Fig. 2. MSR-MBR curve for regenerating codes
In recent years, considerable attention has been paid to the construction of codes at the MSR and MBR points, as well as codes that lie at intermediate points of the boundary [3, 6, 7]. Various designs of regenerating codes can also be found in [8-15]. The main disadvantage of these codes is poor scalability.
We optimized one of the types of regenerating codes - “butterfly” [4] (this code is systematic, it is very important for requests like random reading) for fast recovery of a single disk and improved the scalability of this design.
Butterfly coding scheme
Consider the sequence of stripes, where n is the number of data disks. The data of this set of stripes is encoded using XOR codes. The first checksum ( h ) is calculated on blocks with the same LBA on all data disks: . The second - according to the Butterfly-scheme presented in Figure 3.
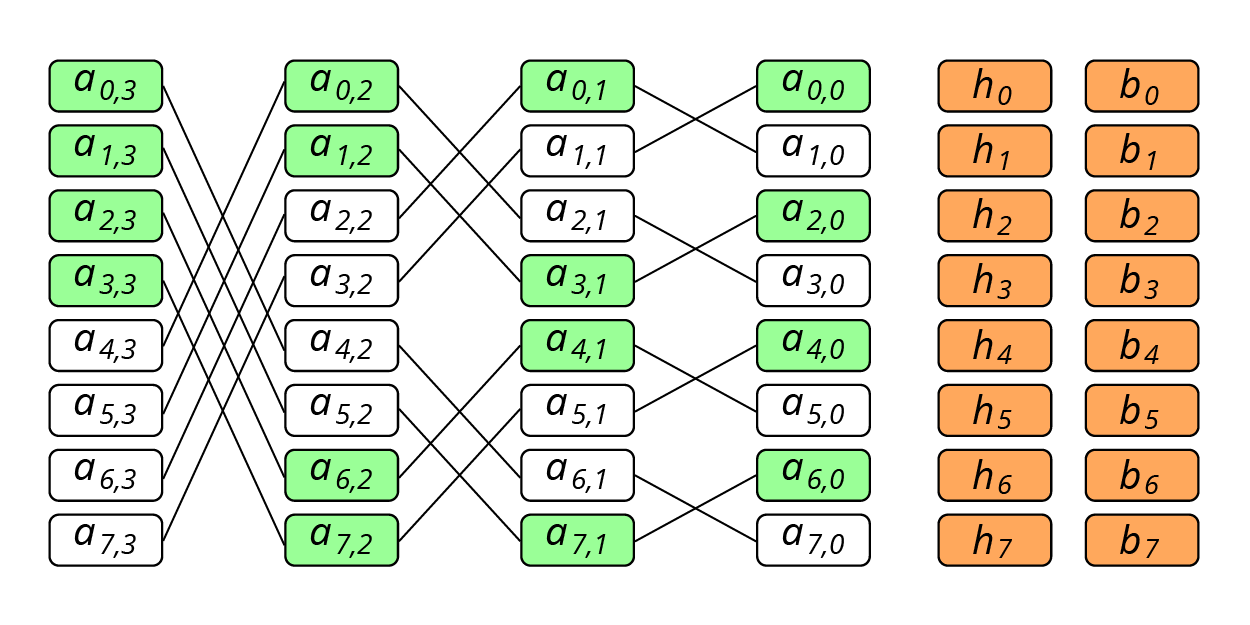
Fig. 3. Butterfly coding scheme
For example, the calculation of the checksum performed as XOR blocks . In addition, the color of the block also has a value, which is defined as: if the j- th bit in the binary representation of the number i matches its ( j-1 ) -th bit, then the block will be green. For a zero component, all even-numbered blocks will be green.
If there are green blocks in the resulting set, for each of them it is necessary to include a block to the right of it in the set. In other words, if a block from the main set - green, the block is also included in the set . For the blocks included in the set in this way, the color does not matter. Therefore, the calculation formula for will be like this:
The choice of just such a coding method is justified in [4]. This guarantees the recovery of two simultaneously failed components.
Using this coding method to restore a component with read data will require less. Namely, to recover blocks of the failed storage component will need to be read units, which in the limit reduces the number of reads compared to RAID-6 in 2 times.
However, if the node containing the checksum fails, recovery will need to read all the data, and in this case there will be no gain. This problem can be solved with a shift similar to a shift in RAID-6, or with randomization, which we have already used in the approach with local reconstruction codes . If in each set of stripes to make a random permutation, then the readings necessary to handle cases of component failures with checksums will be evenly distributed across all options for failures.
It is also necessary to understand that the regenerating codes have one major drawback: a strict limitation on the number of blocks in the stripe. For a disk array, this is irrelevant, because the size of the encoded block may vary, and therefore, their number may vary. But for a cluster configuration, in the node where the number of disks may be limited, the problem of scaling needs to be solved. One of the possible solutions is splitting the stripe into regenerating groups. This will increase redundancy as many times as there will be groups, but the coding sets themselves will become exponentially smaller, see fig. four.
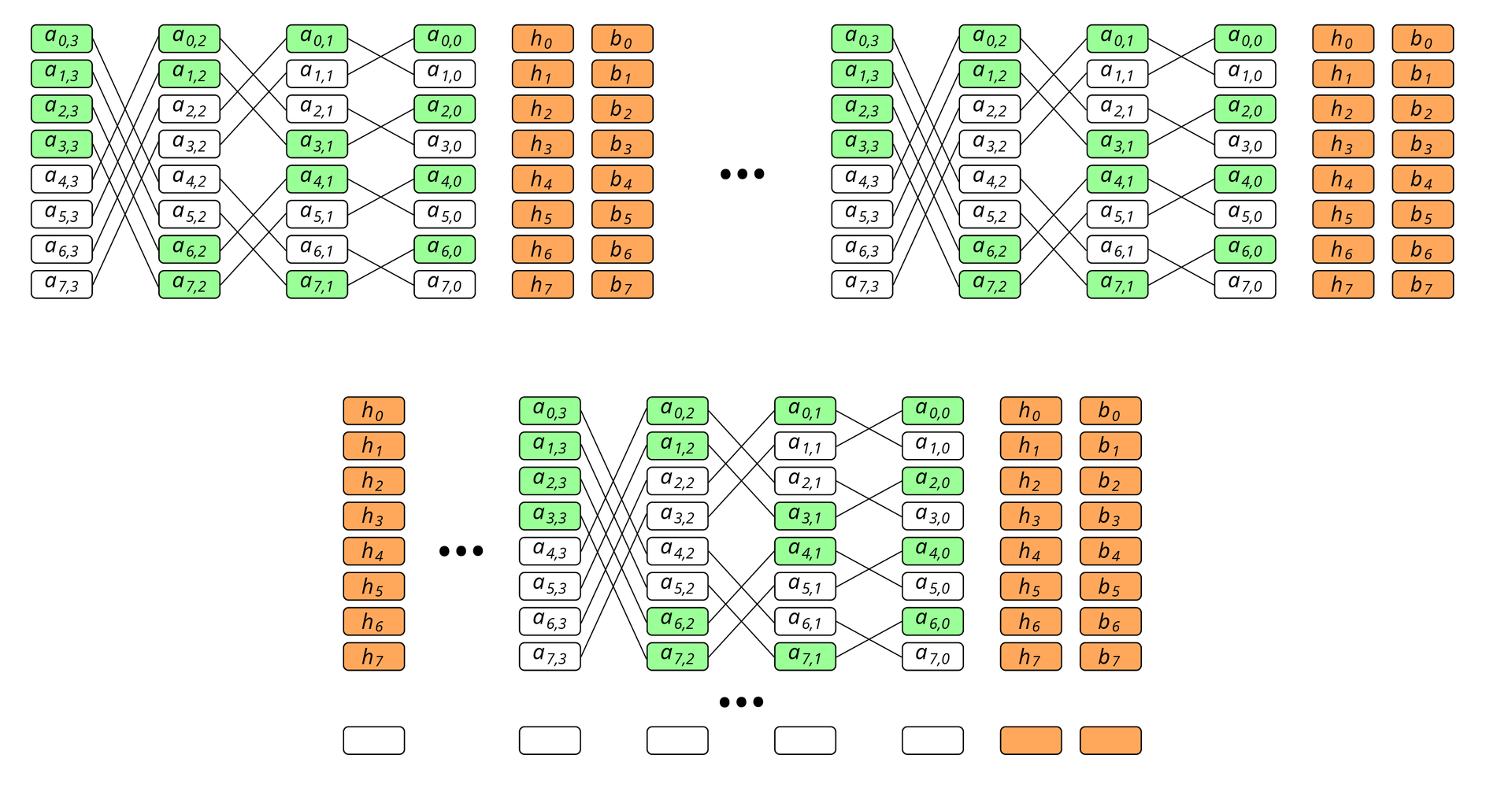
Fig. 4. Exponential reduction of stripes of the coded set
Finally, the last thing to consider when applying regenerating codes is the area into which information from the failed disk will be restored. The fact is that when restoring to a hot-spare disk, the recovery speed will be limited by the write speed to it, and a decrease in the number of readings will not give a significant gain. Therefore, there is a need to include an empty-block in the stripe.
Performance testing
To test the performance, we created a RAID of 22 disks with specific layouts. A RAID device was created using a device-mapper modification that changed the addressing of a block of data according to a specific algorithm. Data was recorded on the RAID array, and checksums were calculated for later recovery. A failed disk was selected. Data recovery was performed either to the corresponding empty blocks or to the hot spare disk. We compared the following schemes:
- RAID-6 is a classic RAID-6 with two checksums, data recovery on a hot spare disk.
- RAID-6E - RAID6 c empty block at the end of the stripe, data recovery on empty blocks of the corresponding stripe.
- Classic LRC + E - LRC scheme in which local groups go sequentially and end with a checksum, recovery to an empty block.
- LRC rand - to generate each LRC stripe, its number is used as the core of the random number generator, data recovery to an empty block.
- Classic Regen is a circuit with three groups of regenerating codes.
- Regen rand is a circuit with three groups of regenerating codes and randomization, data recovery to an empty block.
22 disks with the following characteristics were used for testing:
- MANUFACTURER: IBM
- PART NUMBER: ST973452SS-IBM
- CAPACITY: 73GB
- INTERFACE: SAS
- SPEED: 15K RPM
- SIZE FORM FACTOR: 2.5IN
When testing performance, the size of the stripe blocks has a big effect. When restoring, reading from disks is done at increasing addresses (sequentially), but due to declustering in random layouts, some blocks are skipped. This means that if the blocks are small, the positioning of the magnetic disk head will be done very often, and this will adversely affect the performance. Since the specific values of the data recovery speed may depend on the hard drive model, manufacturer, RPM, we presented the results in relative terms. Figure 5 shows how the performance gains come from (b) - (f) compared to classic RAID-6.
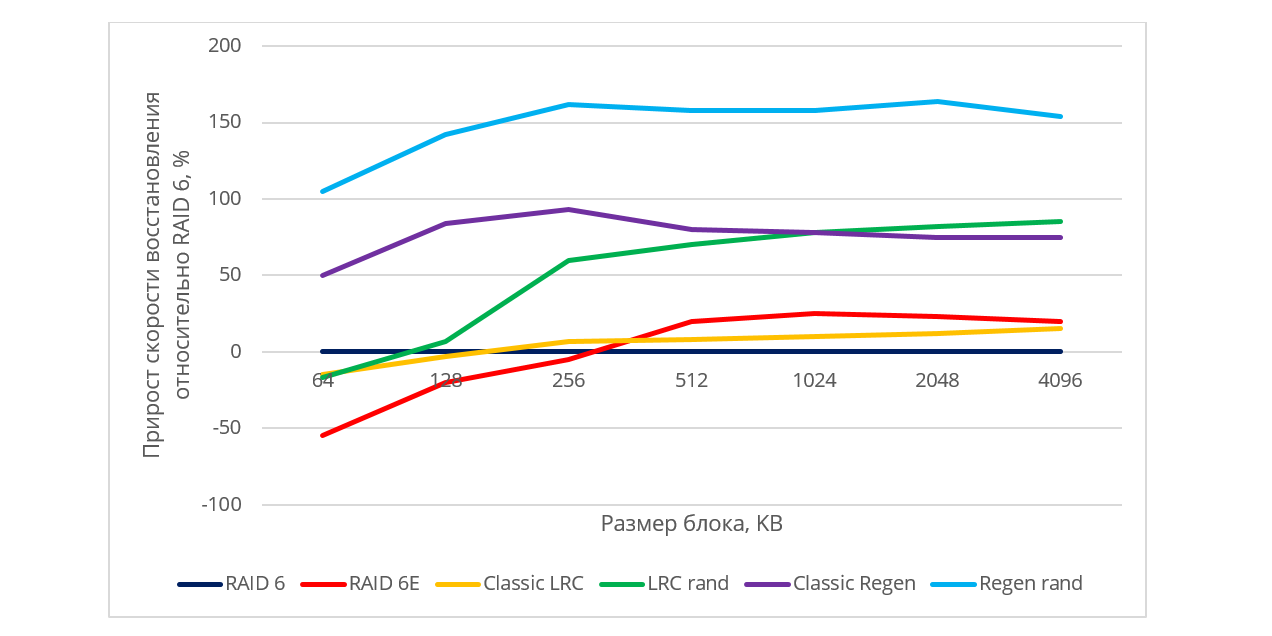
Fig. 5. Relative performance of various placement algorithms
When restoring data to a hot spare disk, we received that the recovery speed is limited by the speed of writing to disk for all circuits using hot spare. It can be noted that both the randomized LRC scheme and the regenerative codes give a rather high increase in the recovery rate compared to the non-optimal and RAID-6. Despite the fact that the regenerating codes clearly lead in the recovery rate, their main disadvantages cannot be ignored: the limitation on the number of blocks in the encoded set and high redundancy: with the empty-block in the checked configuration, redundancy was more than 30% (Fig. 6).
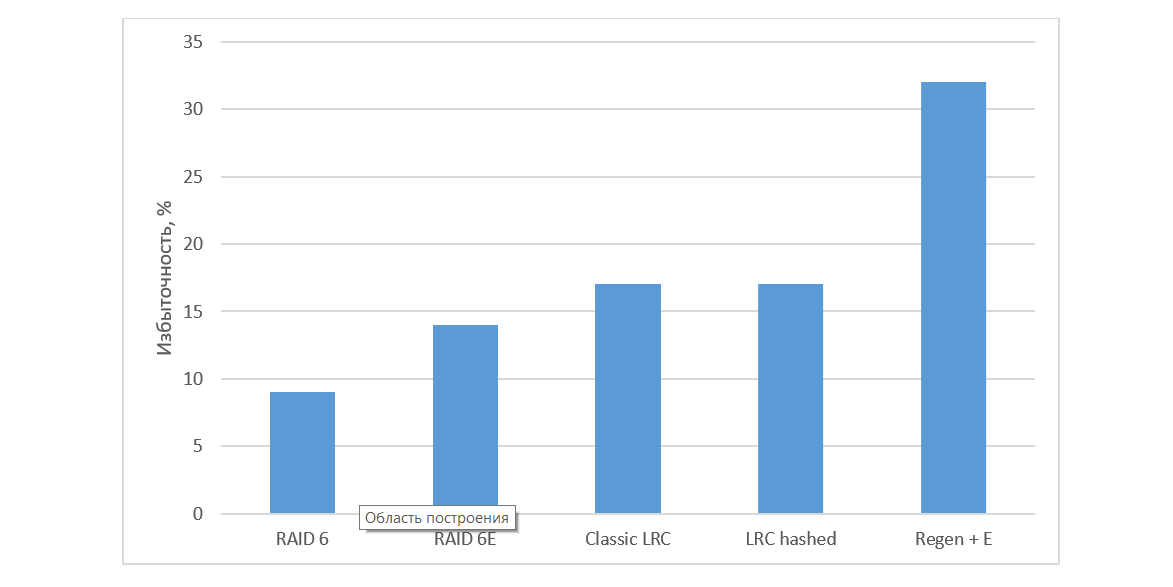
Fig. 6. Redundancy of various algorithms
Conclusion
Regenerating Butterfly-codes were successfully tested in HDFS, Ceph [5].
We considered the options for using regenerating codes on a local system, came up with a way to scale them and use them to quickly handle a single disk failure situation.
Despite the fact that the performance of this solution turned out to be the best (see Fig. 5), the requirements for redundancy (see Fig. 6) can be costly, therefore this algorithm is not suitable everywhere. Thus, it is always necessary to understand whether in a particular case one can sacrifice a place for the sake of reliability.
The presented solutions can be generalized to distributed, in particular - cloud storage system. In such systems, the advantages will be even more pronounced, since in them the bottleneck is the transmission of data over the network, which can be minimized through the presented approaches.
Literature
[1] A. Datta and FE Oggier. An overview of the codes tailor-made for networked distributed data storage. CoRR, abs / 1109.2317, 2011.
[2] A. Dimakis, P. Godfrey, Y. Wu, M. Wainwright, and K. Ramchandran. Network coding for distributed storage systems. Information Theory, IEEE Transactions on, 56 (9): 4539–4551, Sept. 2010.
[3] T. Ernvall. Exact-regenerating codes between mbr and msr points. In Information Theory Workshop (ITW), 2013 IEEE, pages 1-5, Sept 2013.
[4] E. En Gad, R. Mateescu, F. Blagojevic, C. Guyot, and Z. Bandic. Repair-Optimal MDS Array Codes Over GF (2). In Information Theory Proceedings (ISIT), IEEE International Symposium on, 2013.
[5] Lluis Pamies-Juarez, Filip Blagojevivić, Robert Mateescu, Cyril Guyot, Eyal En Gad, Zvonimir Bandic. On the Real Repair Performance of MSR Codes. In Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST '16), pages 81-94. USENIX Association, 2016.
[6] J. Li, T. Li, and J. Ren. Cloud storage. In INFOCOM, 2014 IEEE Proceedings, pages 307–315, April 2014.
[7] N. Shah, KV Rashmi, P. Kumar, and K. Ramchandran. There are no points for the distribution of storage space. Information Theory, IEEE Transactions on, 58 (3): 1837–1852, March 2012.
[8] J. Chen and K. Shum. Repairing multiple failures in the suhramchandran regenerating codes. In Information Theory Proceedings (ISIT), 2013 IEEE International Symposium, pages 1441–1445, July 2013.
[9] B. Gaston, J. Pujol, and M. Villanueva. Quasi-cyclic regenerating codes. CoRR, abs / 1209.3977, 2012.
[10] S. Jiekak, A.-M. Kermarrec, N. Le Scouarnec, G. Straub, and A. Van Kempen. Regenerating codes: A system perspective. In Reliable Distributed Systems (SRDS), 2012 IEEE 31st Symposium, pages 436– 441, Oct 2012.
[11] KV Rashmi, N. Shah, and P. Kumar. Optimal exact-regenerating codes for a computermatrix construction. Information Theory, IEEE Transactions on, 57 (8): 5227–5239, Aug 2011.
[12] K. Shum and Y. Hu. Exact minimum-repair-bandwidth cooperative regenerating codes for distributed storage systems. In Information Theory Proceedings (ISIT), 2011 IEEE International Symposium, pages 1442–1446, July 2011.
[13] K. Shum and Y. Hu. Functional-repair-by-transfer regenerating codes. In Information Theory Proceedings (ISIT), 2012 IEEE International Symposium, pages 1192–1196, July 2012.
[14] KW Shum and Y. Hu. Cooperative regenerating codes. CoRR, abs / 1207.6762, 2012.
[15] C. Suh and K. Ramchandran. Exact-repair mds code construction using interference alignment. Information Theory, IEEE Transactions on, 57 (3): 1425–1442, March 2011.
[2] A. Dimakis, P. Godfrey, Y. Wu, M. Wainwright, and K. Ramchandran. Network coding for distributed storage systems. Information Theory, IEEE Transactions on, 56 (9): 4539–4551, Sept. 2010.
[3] T. Ernvall. Exact-regenerating codes between mbr and msr points. In Information Theory Workshop (ITW), 2013 IEEE, pages 1-5, Sept 2013.
[4] E. En Gad, R. Mateescu, F. Blagojevic, C. Guyot, and Z. Bandic. Repair-Optimal MDS Array Codes Over GF (2). In Information Theory Proceedings (ISIT), IEEE International Symposium on, 2013.
[5] Lluis Pamies-Juarez, Filip Blagojevivić, Robert Mateescu, Cyril Guyot, Eyal En Gad, Zvonimir Bandic. On the Real Repair Performance of MSR Codes. In Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST '16), pages 81-94. USENIX Association, 2016.
[6] J. Li, T. Li, and J. Ren. Cloud storage. In INFOCOM, 2014 IEEE Proceedings, pages 307–315, April 2014.
[7] N. Shah, KV Rashmi, P. Kumar, and K. Ramchandran. There are no points for the distribution of storage space. Information Theory, IEEE Transactions on, 58 (3): 1837–1852, March 2012.
[8] J. Chen and K. Shum. Repairing multiple failures in the suhramchandran regenerating codes. In Information Theory Proceedings (ISIT), 2013 IEEE International Symposium, pages 1441–1445, July 2013.
[9] B. Gaston, J. Pujol, and M. Villanueva. Quasi-cyclic regenerating codes. CoRR, abs / 1209.3977, 2012.
[10] S. Jiekak, A.-M. Kermarrec, N. Le Scouarnec, G. Straub, and A. Van Kempen. Regenerating codes: A system perspective. In Reliable Distributed Systems (SRDS), 2012 IEEE 31st Symposium, pages 436– 441, Oct 2012.
[11] KV Rashmi, N. Shah, and P. Kumar. Optimal exact-regenerating codes for a computermatrix construction. Information Theory, IEEE Transactions on, 57 (8): 5227–5239, Aug 2011.
[12] K. Shum and Y. Hu. Exact minimum-repair-bandwidth cooperative regenerating codes for distributed storage systems. In Information Theory Proceedings (ISIT), 2011 IEEE International Symposium, pages 1442–1446, July 2011.
[13] K. Shum and Y. Hu. Functional-repair-by-transfer regenerating codes. In Information Theory Proceedings (ISIT), 2012 IEEE International Symposium, pages 1192–1196, July 2012.
[14] KW Shum and Y. Hu. Cooperative regenerating codes. CoRR, abs / 1207.6762, 2012.
[15] C. Suh and K. Ramchandran. Exact-repair mds code construction using interference alignment. Information Theory, IEEE Transactions on, 57 (3): 1425–1442, March 2011.
Source: https://habr.com/ru/post/333766/
All Articles