How to please the viewer and not lose money: make up a procurement plan with the help of ML

Another article on behalf of the participant of the school about the project implemented in the framework of the next exit:
“I am Dmitry Pasechnyuk , and I want to share my research done during the holidays as part of the GoTo School’s visiting spring shift led by Alexander Petrov, asash , technical director of E-Contenta.
')
As we know, online cinemas are quite common and are capable of generating good income. But, as in any business, this does not happen by itself. One of the important conditions for the success of an online cinema is the competent preparation of offers for viewing.
In each cinema, whether online or real cinema, there is an employee engaged in repertoire planning. It is he who determines which films will be shown on the screens. Film-rolling process has its pitfalls. In order to choose a good movie, you need to consider not only the cost of buying rights, but also a thousand other nuances. There is no system for the selection of films as such, and often films are selected based on their own “flair”, expectation rating and expert opinion.
Making a responsible decision is a heavy moral burden for a person, on the one hand, and on the other hand, there are always risks of excessive influence of personal and situational factors on the decision made.
Modern technologies are designed to facilitate the work of people, and in this case expectations are justified.
In my research, I tried to shift the task of ranking films in accordance with the expectations of the target audience of the online cinema from person to car. Of course, in the general formulation this problem is more complicated, and this solution is only the first step. In the future, I plan to continue research in this direction.
Everything in order under the cut.
Approach to solving the problem
For a list of movies for training and testing machine learning models, I used dataset from the site GroupLens (MovieLens 20M Dataset ml-20m.zip).
To obtain a list of films announced for 2018, the TMDb API (the Movie Database API developers.themoviedb.org/3/getting-started ) was used to test the algorithm.
For information about films, such as a list of actors, directors, and a brief description of their IMDb ID, SimAPI was used.
Our solution was implemented in Python using the Scikit-learn library, which contains implementations of the main machine learning algorithms.
To solve the problem from the films, the following features were singled out: one-hot encoding feature genres; shooting year; famous actor, director, and film production country; tf-idf for the 50 most powerful words in the text according to the description of the film and averaged over all the words in the description (except for stop words) word2vec.
The target variable used was the share of MovieLens, which was active in terms of grading films to the audience, which rated the specific film. Below are 15 of the most significant in predicting the popularity of the film signs and their weight, determined by the Random Forest algorithm.

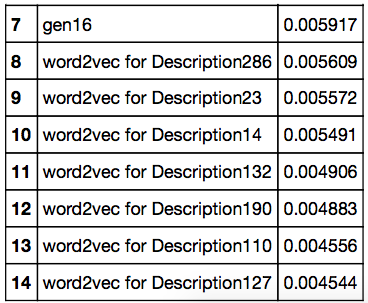
For training and validation, the original MovieLens movie sample was divided into 99: 1, and any of the films in the training sample came out of any validation sample before any film, which allowed to avoid problems such as knowing the algorithm which films would have popularity after that moment. when it becomes necessary to predict the popularity of a film that has not yet been released (at that moment we will not be able to say exactly which films will be relevant in the future).
To determine the quality of the algorithm, we used the proportion of the number of unique MovieLens users who viewed at least one of the 10, 50, 200 films identified by the algorithm as the most popular of the total audience size.
Algorithms such as Linear regression, Random forest, K-nearest neighbors, Decision tree and Gradient boosting over decisive trees were tested on the validation sample. The test results are presented in the following table:

(The line numbered 0 represents the value of a certain metric for the case when we know the target variable).
Results of the first stage
The optimal of the tested by the algorithm in terms of a certain quality metric proved to be Random Forest. The Pearson correlation coefficient between the real values of the target variable and the values predicted by the algorithm is 0.826. Below is the scatter diagram for these values.
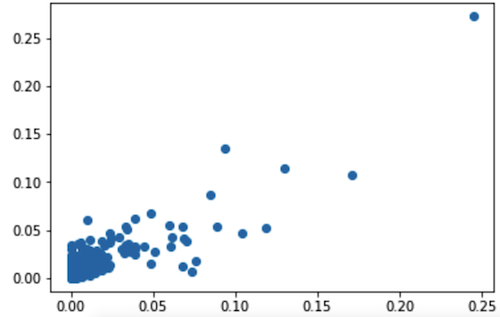
Next, we decided to check whether the results of the selected algorithm match the actual results. We got the following: if we rank films by the share of the target audience interested in the film predicted by the algorithm and output the result, we will see that those films that were in the top five really had a fairly large number of views relative to the size of the MovieLens audience. TOP 20-30, but at the same time in lower places (films ranged from 2001 to 2002 in a number of 150 pieces)

Algorithm improvement
After receiving a list of films ranked by popularity, we became interested in which genre dominates the top positions in the list. It turned out that most of the films in the top positions are dramas. For this reason, if we simply took N films from the top of the list and only showed these films in the cinema, we would most likely lose a certain part of the audience, because some people like to watch not only dramas, but documentaries or horrors.
We assumed that the optimal way out of this problem would be the following scheme of forming a set of films: for each film, consider its “popularity” as the product of the result returned by our algorithm for this movie by the “popularity” of the genre of this movie.
First of all, we built a histogram for each genre, on which the abscissa plotted the number of films X of this genre, and the ordinate plotted the share of people who watched X films of this genre from 1993 to 2003 from the general audience of MovieLens. The results are presented below:

Next, it was necessary to choose the metric of popularity of the genre. The optimal variant of those tested was the normalized amount of movie views of this genre by each person from the MovieLens audience. As a result, each of the genres received the following “popularity” points:

The results of the second stage
We decided to compare the results demonstrated by the improved version of the algorithm with the original version of the algorithm, and obtained the following results. If you plot a graph, where the number of films that need to be selected to form film distribution tape is plotted on the x-axis, and the ordinate axis <the quality of the original algorithm> is <the quality of the new algorithm>, then we get the following result:

As can be seen from the graph, the algorithm improved by us in the course of operation demonstrates higher quality on the segment X ∈ [60, 225], while demonstrating the same results for large values of X.
In general, this algorithm can be used to generate long-term lists of films for purchase.
Testing the algorithm in real conditions
Testing was conducted on the list of films announced for 2018, obtained using The Movie DB API in the amount of 128 pieces. It may not make sense to select fewer than 60 films from a given number, and together with the fact that in real conditions the “margin of profit” of the new algorithm may shift somewhat to the right, it was decided to test the original algorithm. If you display a ranked list of movies and scores of their “popularity”, you get the following:
The first 24 films in the list

Last 24 movies listed
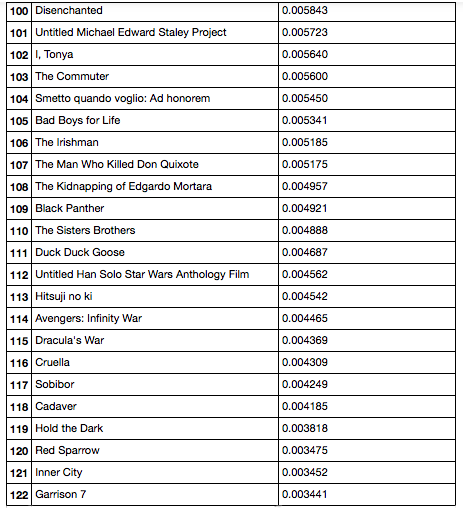
If you look at this list, then in its first part you can see quite promising films, for example, at positions 4, 8, 9, 10, 12, 17, 18. If you look at the latest films in the list, then these films are not generally they are clearly attractive, their content is also not very impressive, except that with the exception of the film at position 114. Why did this happen? - if you look at the list of signs of this film, you can see that the directors of this film are not in the list of all directors (which can only say that there were no films of this series in the training set), and also no information about the genres (perhaps TMDb API and / or SimAPI, just did not find information about this movie).
Perspectives
Initially, the task of ranking new films in terms of popularity was set by us. This algorithm will be part of the production solution. At the same time, this is not the end of the work.
In the future, we plan to increase the number of signs, including by including the movie search history on Google and Yandex, data on film reviews (average tone of reviews on the most popular services), as well as data on the success of films close to what is considered in terms of content. descriptions. It is also possible to predict the share of the audience interested in the film, averaging the probability that a particular movie will be viewed by everyone (from all, or from some share of all) by the user. ”
Thank you for your attention, and Dmitry for the article. We will be glad to any ideas of projects from you for new schools, write to school@goto.msk.ru.
Source: https://habr.com/ru/post/333746/
All Articles