From repository to CI / CD infrastructure in production for the week
Usually, the term “support” means only one meaning - it is the response to the troubles with hosting, replacement of bad drives, setting up web servers and DBMS, and general day-to-day administration. But, in fact, this is only the first level of control over the stability of the operation of any Internet project.
After all, even when you have already configured a failover cluster of multiple servers in different data centers, with backup of all critical data and automatic file server, there are still situations where the streamlined operation of production sites can be seriously disrupted. Do you often have to see instead of this:

')
Here it is:

And it is about this post - about security and stability of development and about what systems and principles they can provide. Or, if you use fashionable words - about DevOps and CI / CD.
In the basic scheme, when we have only one server on which the site itself is spinning, and the base for it, and all other related services, such as caching and searching, almost all things can be done manually - take updates from the repository, restart services , re-index the search base and all that.

But what to do when the project grows up? Both vertically and horizontally. When we already have ten servers with a web, three with a base, several servers for searching. We also decided to understand exactly how our customers use our service, we got a separate analytics with their own databases, frontend, and periodic tasks. And now we have more than one server, but thirty, for example. Continue to do all the little things by hand? We'll have to increase the staff of admins, because one already physically will not have enough time and attention to all supported systems.
Or you can stop being the admin craft workshop and start building production chains. Move on to the next level of abstraction, manage not individual services or programs, but servers as a whole, as the minimum unit of a common system.
For this purpose, the DevOps and CI / CD methodologies were invented. CI / CD implies a separate development site, separate staging and separate sales.
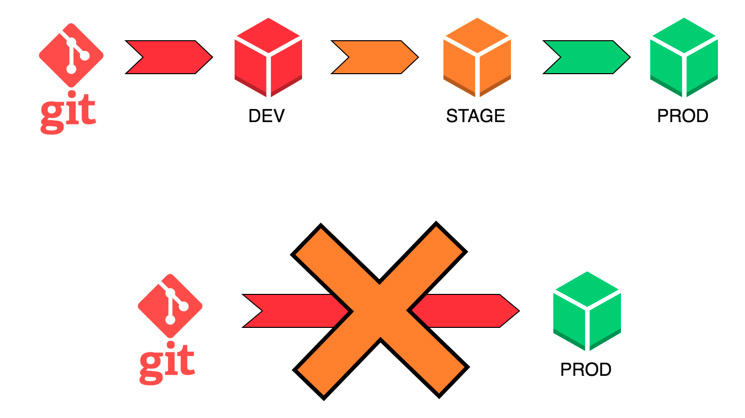
It also implies that each release necessarily goes through certain stages of life, be it manual or automated testing, installing on a stage to test its performance in an environment identical to that of the product. This eliminates the possibility that something will go wrong during the deployment itself - pulnully the wrong branch, not from that turnip, not on that server, etc. Everything is provided in advance and structured, and the influence of the human factor is minimal. It remains only to monitor the quality of the code itself and the work of the internal logic of the project.
This allows admins not to interfere in the development and display process itself and to deal with their immediate responsibilities for monitoring and reflecting on how to further expand the architecture.
Usually such things are said more in a theoretical way. Here, they say, there is such a thing as Docker. Here we can make inexpensive containers. Create, update, roll back, everything can be done without serious consequences, without touching the vital parts of the parent system, without loading with unnecessary layers and services. And then in another article - here are the Kubernetes. He can insert and pull out docker-bricks in your project independently, without manual intervention, just describe to him the configuration how it will work. Here are three lines from the official documentation. And in such a style almost all the materials. I would like to talk about how all this happens in real life, starting from the real task of providing a mechanic with a safe and stable development.
I will tell you on the example of the Edwin service, which helps to learn English using a bot in Facebook Messenger. Bot @EnglishWithEdwin determines the level of English and personalizes the curriculum based on the progress and speed of learning of each student.
By this time, the company had been developing for several months, there was a working product that was developing rapidly, and the company was preparing for the first public release. At the site where the development was carried out, services in docker containers have already been launched, databases on AWS have been raised, and it all even worked.
The head of Edwin’s development, Sergey Vasilyev, having carefully analyzed existing offers on the market, came to us with a description of the architecture of his product and requirements for reliability in operation. In addition to our main task - round-the-clock support of services - we needed to understand what was going on and organize the staging and production site with the possibility of convenient updates and general infrastructure management.
The use of containers in production at that time was not massive, and chat bots were just beginning to develop. Thus, for us it was a great opportunity to practice modern tools on the example of a real and interesting product.
How is Edwin built from the inside? Keywords - Python, PostgreSQL, Neo4j, RabbitMQ. Conventionally, the architecture can be divided into three large blocks: transport, logical and analytical.

In the first block, a documented mailer application written in python, which receives messages from Facebook via Facebook Gateway, saves them to the database and adds an event to the RabbitMQ queue.
In the second block, there are containers with the bot itself, which reads data from queues about incoming messages, processes, collects data for analysts in the third block, and with the scheduler, a dokerized Tornado application responsible for all periodic and pending tasks, like push notifications and expiration of the lifetime of the sessions.
In the third block, there are databases with data for analytics and several containers with services dealing with aggregation of data from bots and uploading to Google Analytics and other places.
But all this is only a supposed structure, since Edwin came to us, not yet having a release version of the project, in production he never glowed. It was exactly the setting of the stage- / prod-environment that we had to do.
In general, all this did not look very difficult, if it were not for one thing - while all the introductory details were discussed, the deadline time inexorably approached, and we only had a week left to realize all our wishes.
CI / CD setup
The first thing to remember is that everything is not as difficult as it seems from afar. The main thing is to understand what you are doing and why. Choose tools only for those needs that are really important, adequately assess their real needs and capabilities.
The basis of our entire system is docker-containers with services and business logic. Containers are selected for greater versatility and mobility in infrastructure management. The most popular tool for juggling docker-containers at the moment is Kubernetes from Google (at least, he is the most widely heard). But it seemed to us to be unnecessarily confused and structurally re-complicated, and therefore requiring too many gestures to maintain working capacity (and too much time for initial understanding). And since the time of putting the whole CI / CD system into service was compressed to a minimum, we decided to look for simpler and lightweight solutions.
To store container templates, it was decided to take (in fact, not even take, but simply to leave the developers, already chosen by us,) Amazon EC2 Container Registry. In general, it is not much different from the registry itself raised on the localhost. Basically by the fact that it does not need to be personally lifted on localhost.
So, we have a repository with container templates. How to make so that the expanded containers can always know about each other and can communicate with each other even with the changed network configuration, for example? At the same time, without interfering constantly in the insides of the containers themselves and their configuration?
To do this, there is such a type of software as service discovery - probably, for ease of understanding, it could be called a “business logic router”, although technically it is not a completely correct definition. A single call distribution center is established, to which all services address their neighbors' location data, agents of this center are initially placed inside containers. And all services at startup announce their location and status to the router.
How to quickly prepare new machines for containers? After all, the hosts also need to be properly configured for network loads and so on, the default kernel parameters are also often quite far from what I would like to see in my production. For this, several Ansible-recipes were written, which reduce the time spent on preparing the new site by an order of magnitude.
When the servers for containers are configured, all the necessary services are documented, it remains only to understand how to organize, in fact, “continuous integration”, without pressing 500 buttons every half hour. As a result, they stopped on a system like GoCD and a small scripting system. Why GoCD, you ask me, not Jenkins? Earlier, in other projects, we had to deal with that, and with the other, and on the totality of interactions GoCD seemed to be easier to configure than Jenkins. It is possible to create templates for tasks and pipelines, on the basis of which you can then generate different production chains for different environments.
The first day was, in general, calm. We finally got a TK for what we had to do.
Here it is, of course, to make a reservation that exactly a week is still a small trick. In the end, not in a vacuum, we exist! Admins in advance were aware of what kind of project will come to support, and which, in general, the tasks will be in the first place. So we had some time to get a little understanding of the options for choosing tools.
As a result, we quietly and measuredly study the existing servers, on which the project was developed at that time. We are hanging monitoring, figure out where that is running, how it works.
Based on the received information, we write Ansible-recipes and start installing servers for production, we start a separate VPC in Amazon, which would not overlap with the existing dev-environment in order to avoid careless actions during development. We expand containers with all necessary services - PostgreSQL, Neo4j, project code.
By the way, when developing, colleagues used PostgreSQL in the form of Amazon RDS, but for the production environment, by joint agreement, they decided to switch to regular instances with PostgreSQL - this made the situation more transparent for admins who could control the behavior of all elements of the system as much as possible. time of the subsequent growth of loads.
In fact, if you do a project with small forces, and you do not have enough dedicated administrative hours, you can use RDS as well, it is quite suitable for yourself, and at the same time allows, if anything, frees up resources for more urgent tasks.
On a separate server, we install GoCD and Consul service discovery in the base version.
As I mentioned earlier, Edwin came to us already with some kind of infrastructure ready for development. For juggling containers, they used Amazon ECS, also known as EC2 Container Service. Something like Kubernetes-as-a-Service. After discussing the wishes with the developers on the future structure of the project and work with the calculations, it was decided to abandon ECS. Like many cloud pieces, it was not transparent enough to control things going on inside; there was a lack of things that were very useful in the current situation, such as the environment settings for the same container. Those. There is no possibility to use the same container in different pipelines just by redefining the environment. In the Amazonian paradigm, you have to create a separate container for each environment.
It is also impossible for some reason to use the same tasks in different chains. In general, GoCD seemed to us much more flexible.
The rest of the day we are engaged in the creation and adjustment of the pipelines for the GoCD sales environment - building the code, re-creating the containers, rolling out new containers for sale, registering the updated services in the consul.
We double-check yesterday's settings, carry out test calculations, check the connectivity of the systems - that the code is correctly retrieved from the repository, that the same code is then correctly assembled into a container, the container is started on the correct server, and then announces its status to the consul.
In general, at the moment we have a ready-made basic infrastructure, within which we can already work on a new paradigm. The GoCD panel is there, the mechanics of assembling and laying out the project in production are set up in it, Consul allows seamlessly and without any special additional time and labor costs to include new servers and services in the existing infrastructure.
Making sure that everything works as it should, we set up backup replications for databases in neighboring Accessibility Zones, and, together with the developers, we upload working data to the sales databases.
As I have already said, at this moment, in general, the minimum necessary elements of the CI / CD system are all installed and configured. We transfer to the developers all the data on the structure of the resulting system, for their part, they start testing all the mechanisms for assembling and laying out the project.
Here, by the way, comes the realization that when drawing up the TK, such an important point was forgotten as the centralized collection of all system logs from all containers and services. This is useful for background analysis of the overall project situation and tracking potential bottlenecks and impending problems.
Logs decided to collect in Kibana - a very convenient interface for all sorts of analysts. We repeatedly encountered it both on side projects and used it on our internal projects.
In a few hours, we are raising Kibana, setting up a collection of logs from services, setting up monitoring of all critical services for sale.
For the most part, from the organizational side on Friday everything was ready. We, of course, met a bunch of different minor bugs and glitches, but it had nothing to do with the system of continuous integration.
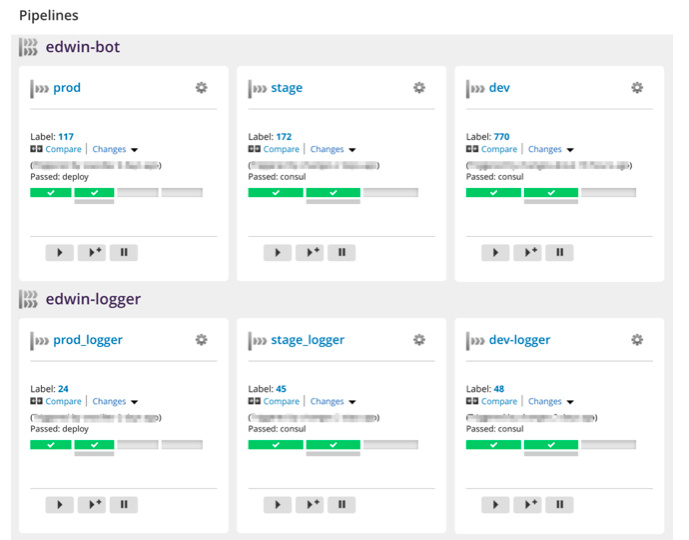
What did we get in the end? A modular project development system consisting of three stages and environments - dev, stage and prod. The whole project is divided into separate microservices, each of which has its own pipelines.
When developers release a new version, they go to the GoCD panel and simply launch the corresponding pipeline. For example, “roll out a new logger on the stage”, test there, check that everything works as it should, then roll it out on the prod. If suddenly something went wrong, then again, independently through the panel roll back the desired service to the desired version.

All three environments — both dev, and stage, and prod — are isolated in different VPCs. Consul has separate data centers set up for each environment, so services cannot even walk between different environments by chance. And even with a great desire in such a situation, it is rather difficult to break the prod for example by any actions on the maiden.
Also, now you can easily increase the capacity for the project. When there is a need for new computing power, a new instance can be launched and prepared for work for approximately ten minutes.
Problems encountered
In general, despite the fact that the field of activity itself may seem rather complicated to many, with a bunch of underlying problems, almost everything turned out right away, minus only a couple of questions. Which, in general, are not really related to continuous integration.
Problems threw Amazon Web Services, which hosts this project.
When setting up the Consul, we encountered an interesting plug. Agents and access to them are registered in containers through system resolvers. But AMI Linux, used by Amazon by default, is slightly different from the default CentOS, and work with resolvers is included in the Virtual Private Cloud (VPC) network settings. When restarting the server, Amazon enforces its resolvers. To force him not to break the settings of the rezolv of the consul, we have so far failed, unfortunately. But chattr + i saved everyone, so now we live.
In general, the structure of the VPC and its networks is quite interesting, and there you can stumble upon restrictions in very unexpected places. For example, an application balancer can be created only for the accessibility zone, that is, the backends must be located in several different access zones at once. To do this, the VPC network must have a breakdown so that there are addresses in private / public and one zone, and another. A change in the breakdown of the VPC network is possible only at creation. And changing the VPC from instances is also possible only at creation.
And it turns out that when you already have a ready infrastructure with working servers within the same availability zone, there is no possibility to modify it by simply adding more servers in another zone and hanging the balancer in front. Alas, it is necessary to completely redo the entire structure from scratch.
Do not be afraid to grow and change the usual workflows if they no longer meet the requirements of the situation, the current level of development of your project. Do not be afraid that the transition to the next stage of development of the project will certainly be too burdensome for you. If you really come to your own needs and do not clutch thoughtlessly at the first available solutions that you have heard about, then this road can be easily mastered even alone.
Although, of course, many may say: “Aha-aha, they have been supporting projects like Habrahabr and Nashe Radio for ten years, and here we are being rant about simplicity!”. Yes, indeed, in our age we have seen many different things. And, perhaps, this is precisely what helps us to distinguish the simple from the complex and not to step on too many rakes. But again, if at the very beginning it is reasonable to approach the task and select the right tools, without chasing “coolness”, then you can make your life much easier.
On the other hand, you should definitely bear in mind that the scheme described (and any other based on containerisation) implies that the project must be initially ready for such manipulations. The project should consist of full-fledged microservices, the state of which can not be saved, so that they are mobile and interchangeable. Within the framework of monolithic systems, the introduction of such an approach of integration integration seems to be much more labor-intensive and less comfortable in further application.
What are our future plans for the project?
After the basic infrastructure has been established, there is a desire to connect to it also the Jira-based bugtracker so that when you roll out a new version into the prod from the Git repository, select data about requests for bugs, automatically close them and write to the release notes .
It also seems that the moment is approaching when it will be necessary to set up auto-scaling on the main working nodes, their total number is constantly growing, and saving on the number of active servers in hours of minimum load will help reduce costs.
After all, even when you have already configured a failover cluster of multiple servers in different data centers, with backup of all critical data and automatic file server, there are still situations where the streamlined operation of production sites can be seriously disrupted. Do you often have to see instead of this:
')
Here it is:
And it is about this post - about security and stability of development and about what systems and principles they can provide. Or, if you use fashionable words - about DevOps and CI / CD.
What for?
In the basic scheme, when we have only one server on which the site itself is spinning, and the base for it, and all other related services, such as caching and searching, almost all things can be done manually - take updates from the repository, restart services , re-index the search base and all that.
But what to do when the project grows up? Both vertically and horizontally. When we already have ten servers with a web, three with a base, several servers for searching. We also decided to understand exactly how our customers use our service, we got a separate analytics with their own databases, frontend, and periodic tasks. And now we have more than one server, but thirty, for example. Continue to do all the little things by hand? We'll have to increase the staff of admins, because one already physically will not have enough time and attention to all supported systems.
Or you can stop being the admin craft workshop and start building production chains. Move on to the next level of abstraction, manage not individual services or programs, but servers as a whole, as the minimum unit of a common system.
For this purpose, the DevOps and CI / CD methodologies were invented. CI / CD implies a separate development site, separate staging and separate sales.
It also implies that each release necessarily goes through certain stages of life, be it manual or automated testing, installing on a stage to test its performance in an environment identical to that of the product. This eliminates the possibility that something will go wrong during the deployment itself - pulnully the wrong branch, not from that turnip, not on that server, etc. Everything is provided in advance and structured, and the influence of the human factor is minimal. It remains only to monitor the quality of the code itself and the work of the internal logic of the project.
This allows admins not to interfere in the development and display process itself and to deal with their immediate responsibilities for monitoring and reflecting on how to further expand the architecture.
Usually such things are said more in a theoretical way. Here, they say, there is such a thing as Docker. Here we can make inexpensive containers. Create, update, roll back, everything can be done without serious consequences, without touching the vital parts of the parent system, without loading with unnecessary layers and services. And then in another article - here are the Kubernetes. He can insert and pull out docker-bricks in your project independently, without manual intervention, just describe to him the configuration how it will work. Here are three lines from the official documentation. And in such a style almost all the materials. I would like to talk about how all this happens in real life, starting from the real task of providing a mechanic with a safe and stable development.
About whom?
I will tell you on the example of the Edwin service, which helps to learn English using a bot in Facebook Messenger. Bot @EnglishWithEdwin determines the level of English and personalizes the curriculum based on the progress and speed of learning of each student.
By this time, the company had been developing for several months, there was a working product that was developing rapidly, and the company was preparing for the first public release. At the site where the development was carried out, services in docker containers have already been launched, databases on AWS have been raised, and it all even worked.
The head of Edwin’s development, Sergey Vasilyev, having carefully analyzed existing offers on the market, came to us with a description of the architecture of his product and requirements for reliability in operation. In addition to our main task - round-the-clock support of services - we needed to understand what was going on and organize the staging and production site with the possibility of convenient updates and general infrastructure management.
The use of containers in production at that time was not massive, and chat bots were just beginning to develop. Thus, for us it was a great opportunity to practice modern tools on the example of a real and interesting product.
Project structure
How is Edwin built from the inside? Keywords - Python, PostgreSQL, Neo4j, RabbitMQ. Conventionally, the architecture can be divided into three large blocks: transport, logical and analytical.
In the first block, a documented mailer application written in python, which receives messages from Facebook via Facebook Gateway, saves them to the database and adds an event to the RabbitMQ queue.
In the second block, there are containers with the bot itself, which reads data from queues about incoming messages, processes, collects data for analysts in the third block, and with the scheduler, a dokerized Tornado application responsible for all periodic and pending tasks, like push notifications and expiration of the lifetime of the sessions.
In the third block, there are databases with data for analytics and several containers with services dealing with aggregation of data from bots and uploading to Google Analytics and other places.
But all this is only a supposed structure, since Edwin came to us, not yet having a release version of the project, in production he never glowed. It was exactly the setting of the stage- / prod-environment that we had to do.
In general, all this did not look very difficult, if it were not for one thing - while all the introductory details were discussed, the deadline time inexorably approached, and we only had a week left to realize all our wishes.
CI / CD setup
The first thing to remember is that everything is not as difficult as it seems from afar. The main thing is to understand what you are doing and why. Choose tools only for those needs that are really important, adequately assess their real needs and capabilities.
The basis of our entire system is docker-containers with services and business logic. Containers are selected for greater versatility and mobility in infrastructure management. The most popular tool for juggling docker-containers at the moment is Kubernetes from Google (at least, he is the most widely heard). But it seemed to us to be unnecessarily confused and structurally re-complicated, and therefore requiring too many gestures to maintain working capacity (and too much time for initial understanding). And since the time of putting the whole CI / CD system into service was compressed to a minimum, we decided to look for simpler and lightweight solutions.
To store container templates, it was decided to take (in fact, not even take, but simply to leave the developers, already chosen by us,) Amazon EC2 Container Registry. In general, it is not much different from the registry itself raised on the localhost. Basically by the fact that it does not need to be personally lifted on localhost.
So, we have a repository with container templates. How to make so that the expanded containers can always know about each other and can communicate with each other even with the changed network configuration, for example? At the same time, without interfering constantly in the insides of the containers themselves and their configuration?
To do this, there is such a type of software as service discovery - probably, for ease of understanding, it could be called a “business logic router”, although technically it is not a completely correct definition. A single call distribution center is established, to which all services address their neighbors' location data, agents of this center are initially placed inside containers. And all services at startup announce their location and status to the router.
How to quickly prepare new machines for containers? After all, the hosts also need to be properly configured for network loads and so on, the default kernel parameters are also often quite far from what I would like to see in my production. For this, several Ansible-recipes were written, which reduce the time spent on preparing the new site by an order of magnitude.
When the servers for containers are configured, all the necessary services are documented, it remains only to understand how to organize, in fact, “continuous integration”, without pressing 500 buttons every half hour. As a result, they stopped on a system like GoCD and a small scripting system. Why GoCD, you ask me, not Jenkins? Earlier, in other projects, we had to deal with that, and with the other, and on the totality of interactions GoCD seemed to be easier to configure than Jenkins. It is possible to create templates for tasks and pipelines, on the basis of which you can then generate different production chains for different environments.
Development process
Monday, February 6
The first day was, in general, calm. We finally got a TK for what we had to do.
Here it is, of course, to make a reservation that exactly a week is still a small trick. In the end, not in a vacuum, we exist! Admins in advance were aware of what kind of project will come to support, and which, in general, the tasks will be in the first place. So we had some time to get a little understanding of the options for choosing tools.
As a result, we quietly and measuredly study the existing servers, on which the project was developed at that time. We are hanging monitoring, figure out where that is running, how it works.
Based on the received information, we write Ansible-recipes and start installing servers for production, we start a separate VPC in Amazon, which would not overlap with the existing dev-environment in order to avoid careless actions during development. We expand containers with all necessary services - PostgreSQL, Neo4j, project code.
By the way, when developing, colleagues used PostgreSQL in the form of Amazon RDS, but for the production environment, by joint agreement, they decided to switch to regular instances with PostgreSQL - this made the situation more transparent for admins who could control the behavior of all elements of the system as much as possible. time of the subsequent growth of loads.
In fact, if you do a project with small forces, and you do not have enough dedicated administrative hours, you can use RDS as well, it is quite suitable for yourself, and at the same time allows, if anything, frees up resources for more urgent tasks.
Tuesday, February 7
On a separate server, we install GoCD and Consul service discovery in the base version.
As I mentioned earlier, Edwin came to us already with some kind of infrastructure ready for development. For juggling containers, they used Amazon ECS, also known as EC2 Container Service. Something like Kubernetes-as-a-Service. After discussing the wishes with the developers on the future structure of the project and work with the calculations, it was decided to abandon ECS. Like many cloud pieces, it was not transparent enough to control things going on inside; there was a lack of things that were very useful in the current situation, such as the environment settings for the same container. Those. There is no possibility to use the same container in different pipelines just by redefining the environment. In the Amazonian paradigm, you have to create a separate container for each environment.
It is also impossible for some reason to use the same tasks in different chains. In general, GoCD seemed to us much more flexible.
The rest of the day we are engaged in the creation and adjustment of the pipelines for the GoCD sales environment - building the code, re-creating the containers, rolling out new containers for sale, registering the updated services in the consul.
Wednesday, February 8
We double-check yesterday's settings, carry out test calculations, check the connectivity of the systems - that the code is correctly retrieved from the repository, that the same code is then correctly assembled into a container, the container is started on the correct server, and then announces its status to the consul.
In general, at the moment we have a ready-made basic infrastructure, within which we can already work on a new paradigm. The GoCD panel is there, the mechanics of assembling and laying out the project in production are set up in it, Consul allows seamlessly and without any special additional time and labor costs to include new servers and services in the existing infrastructure.
Making sure that everything works as it should, we set up backup replications for databases in neighboring Accessibility Zones, and, together with the developers, we upload working data to the sales databases.
Thursday, February 9
As I have already said, at this moment, in general, the minimum necessary elements of the CI / CD system are all installed and configured. We transfer to the developers all the data on the structure of the resulting system, for their part, they start testing all the mechanisms for assembling and laying out the project.
Here, by the way, comes the realization that when drawing up the TK, such an important point was forgotten as the centralized collection of all system logs from all containers and services. This is useful for background analysis of the overall project situation and tracking potential bottlenecks and impending problems.
Logs decided to collect in Kibana - a very convenient interface for all sorts of analysts. We repeatedly encountered it both on side projects and used it on our internal projects.
In a few hours, we are raising Kibana, setting up a collection of logs from services, setting up monitoring of all critical services for sale.
Friday, February 10
For the most part, from the organizational side on Friday everything was ready. We, of course, met a bunch of different minor bugs and glitches, but it had nothing to do with the system of continuous integration.
results
What did we get in the end? A modular project development system consisting of three stages and environments - dev, stage and prod. The whole project is divided into separate microservices, each of which has its own pipelines.
When developers release a new version, they go to the GoCD panel and simply launch the corresponding pipeline. For example, “roll out a new logger on the stage”, test there, check that everything works as it should, then roll it out on the prod. If suddenly something went wrong, then again, independently through the panel roll back the desired service to the desired version.
All three environments — both dev, and stage, and prod — are isolated in different VPCs. Consul has separate data centers set up for each environment, so services cannot even walk between different environments by chance. And even with a great desire in such a situation, it is rather difficult to break the prod for example by any actions on the maiden.
Also, now you can easily increase the capacity for the project. When there is a need for new computing power, a new instance can be launched and prepared for work for approximately ten minutes.
Problems encountered
In general, despite the fact that the field of activity itself may seem rather complicated to many, with a bunch of underlying problems, almost everything turned out right away, minus only a couple of questions. Which, in general, are not really related to continuous integration.
Problems threw Amazon Web Services, which hosts this project.
When setting up the Consul, we encountered an interesting plug. Agents and access to them are registered in containers through system resolvers. But AMI Linux, used by Amazon by default, is slightly different from the default CentOS, and work with resolvers is included in the Virtual Private Cloud (VPC) network settings. When restarting the server, Amazon enforces its resolvers. To force him not to break the settings of the rezolv of the consul, we have so far failed, unfortunately. But chattr + i saved everyone, so now we live.
In general, the structure of the VPC and its networks is quite interesting, and there you can stumble upon restrictions in very unexpected places. For example, an application balancer can be created only for the accessibility zone, that is, the backends must be located in several different access zones at once. To do this, the VPC network must have a breakdown so that there are addresses in private / public and one zone, and another. A change in the breakdown of the VPC network is possible only at creation. And changing the VPC from instances is also possible only at creation.
And it turns out that when you already have a ready infrastructure with working servers within the same availability zone, there is no possibility to modify it by simply adding more servers in another zone and hanging the balancer in front. Alas, it is necessary to completely redo the entire structure from scratch.
Conclusions and plans
Do not be afraid to grow and change the usual workflows if they no longer meet the requirements of the situation, the current level of development of your project. Do not be afraid that the transition to the next stage of development of the project will certainly be too burdensome for you. If you really come to your own needs and do not clutch thoughtlessly at the first available solutions that you have heard about, then this road can be easily mastered even alone.
Although, of course, many may say: “Aha-aha, they have been supporting projects like Habrahabr and Nashe Radio for ten years, and here we are being rant about simplicity!”. Yes, indeed, in our age we have seen many different things. And, perhaps, this is precisely what helps us to distinguish the simple from the complex and not to step on too many rakes. But again, if at the very beginning it is reasonable to approach the task and select the right tools, without chasing “coolness”, then you can make your life much easier.
On the other hand, you should definitely bear in mind that the scheme described (and any other based on containerisation) implies that the project must be initially ready for such manipulations. The project should consist of full-fledged microservices, the state of which can not be saved, so that they are mobile and interchangeable. Within the framework of monolithic systems, the introduction of such an approach of integration integration seems to be much more labor-intensive and less comfortable in further application.
What are our future plans for the project?
After the basic infrastructure has been established, there is a desire to connect to it also the Jira-based bugtracker so that when you roll out a new version into the prod from the Git repository, select data about requests for bugs, automatically close them and write to the release notes .
It also seems that the moment is approaching when it will be necessary to set up auto-scaling on the main working nodes, their total number is constantly growing, and saving on the number of active servers in hours of minimum load will help reduce costs.
Source: https://habr.com/ru/post/333650/
All Articles