Transition to embedded PostgreSQL in unit tests

In applications that work with databases, there naturally arises the need for tests that verify the correctness of query results. Various built-in databases come to the rescue. In this article I will talk about how we transferred unit tests from HSQLDB to PostgreSQL: why it started, what difficulties we encountered and what it gave us.
If the tests need to check the performance of sql queries, it is convenient to use the so-called embedded database. The database is created when the test is started and deleted when it is completed - thus, its life cycle is limited by the process in which it was launched (which is why they are called embedded — that is, embedded in the testing process). The advantage of such databases is that they allow you to work with a limited set of test data, which, as a rule, is much less than the amount of data even on a test server. In addition, the creation of the database, filling in the tables and the subsequent deletion of the entire infrastructure is completely transparent to the programmer: there is no need to raise and configure the test server, as well as take care of the relevance of the data, which also has a positive effect on the speed of development.
For our company, HSQLDB has historically been used for unit testing. And everything would be fine, but PostgreSQL is on the production, and it turned out that the tests do not fully reflect what is happening on the prod. Some features had to be left without testing: for example, requests using window functions could not be tested. For some tests, it was necessary to make quite clever crutches: a vivid example is the different implementation of mapping a custom array type to SQL in PostgreSQL and HSQLDB (below I will tell about this in more detail). We also faced the problem implementation of exists - there were cases when, for no reason at all, the test fell from NPE somewhere in the depths of HSQLDB.
All these problems could have been avoided if we used PostgreSQL as a database for tests. Currently, there are two implementations of PostgreSQL embedded: the postgresql-embedded library from yandex-qatools and otj-pg-embedded , provided by OpenTable . Both projects are actively developing, as evidenced by regular commits in the repository, as well as easy to use: libraries can be downloaded from the maven repository, both work under Windows, which is important for the company, where some of the developers have chosen to work. As a result, we decided to stop at otj-pg-embedded for several reasons:
- First, the OpenTable library turned out to be much faster: the launch time for the downloaded distribution is about 2 seconds, while yandex-qatools runs within 7.5 seconds - almost 4 times slower! It turned out that most of the time was spent on unarchiving the distribution at every start, while on Windows machines the start time increased to a few minutes.
- Secondly, it is enough just to change the PostgreSQL version if you need to use an older version or a custom build with extensions. By default, otj-pg-embedded 0.7.1 comes with PostgreSQL 9.5 (in version 0.8.0, currently relevant, PostgreSQL 9.6). It is not entirely clear how you can put a custom assembly in yandex-qatools.
- otj-pg-embedded is quite an old project (the first commit was in February 2012), the maintener responds promptly to requests in github.
- At yandex-qatools there are more options for configuration, at the same time otj-pg-embedded is a small library that is easy to understand, while it provides enough opportunities for configuration.
- In the OpenTable library, you can run a database instance “in one line”, which is very convenient and intuitive. In addition, in version 0.8.0, at startup, a fairly informative log is displayed showing the settings with which PostgreSQL is running.
So, having decided on the library and decisive gesture, replacing all dependencies on hsql with otj-pg-embedded, we happily launched tests and ...
First rake
The DATE sql type is handled differently.
First of all, it turned out that the tests that worked with the Date sql type (not the Timestamp , namely Date ) dropped. For example, when searching for resumes according to a certain criterion, the query returns all resumes for which the date of change is later than the specified date:
return sessionFactory.getCurrentSession().createQuery( "FROM ResumeViewHistory " + "WHERE resumeId=:resumeId AND date IN " + " (SELECT max(date) FROM ResumeViewHistory " + " WHERE resumeId=:resumeId AND date>:date)") .setInteger("resumeId", resumeId) .setDate("date", from) .list(); In the test, a resume with the current date was created and then it was checked that there is no resume with a date slightly older than the one just created:
assertTrue(resumeViewHistoryDao.findByResumeLastView( resume.getResumeId(), new DateTime().plusMinutes(1).toDate()) .isEmpty()); This test, like all other tests with a similar test, in PostgreSQL fell from AssertionError . The thing is that the date and time were compared in HSQLDB, so a one minute difference was considered significant. And in PostgreSQL, the time was reset to zero, simply turning into a date, and the query found a resume for itself, because it was created on the same day!
')
Thus, we practically at first faced with the situation when the test checked the sql query, assuming certain behavior under the specified conditions, and this behavior worked on HSQLDB and did not work on PostgreSQL. That is, in fact, this test was not only useless, because it did not give any information about the work of the query on the productive base, but was even harmful: the developer, reading the test code and seeing that there is a test for an empty result for an object created a minute later, could to think that at the DAO level the setTimestamp() method is used, and I would be very surprised to see setDate() .
LIKE + CTE
The following problem was thrown by the LIKE operator in conjunction with common table expressions. CTE (Common Table Expressions) are expressions that define temporary tables for use in a more complex query. These temporary tables are created only for the current query, which is convenient for the short-term presentation of data in one form or another. For example, the Employer (employer, or client) —one of the central entities — can be represented as a more specialized object with a reduced set of fields using CTE.
Suppose we need to find duplicate customers - that is, companies that have matches for several parameters, for example, the address of registration or the url of the site. Among other things, there is a check for the coincidence of the name of the company (or its part), then the LIKE operator comes in just here:
WITH clients(name) AS (VALUES …) SELECT employer.employer_id AS employerId, employer.name AS employerName FROM employer AS employer JOIN clients AS clients ON employer.name LIKE '%' || clients.name || '%' So, for the following list of clients:
- Alice
- Bob
- Headhunter
- Customer
- Alice cooper
- Bob marley
the result of the query was very different depending on what was inserted into the WITH statement (see table).
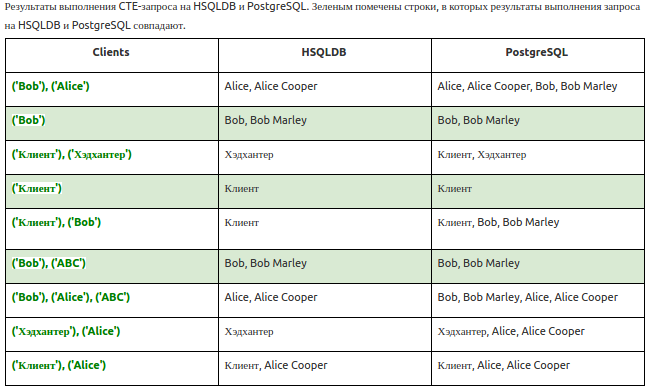
It seems that PostgreSQL always gives a predictable result, and HSQLDB has problems in all cases when more than one value falls into the temporary table, which should be joined by join. As a result, we had to correct the source data in the test, because, as can be seen from the table, PostgreSQL and HSQLDB react differently to multiple values in the temporary table, and in the test several clients were checked.
Different reaction to incorrect SQL
In our data model, there are objects that store sql code that is executed in order to find out if an object is suitable for certain conditions. Naturally, there is a desire to check the behavior of the system when it encounters incorrect sql code, so we have the appropriate test: the incorrect sql is passed to the object, and then the method that this sql executes is called.
SELECT user_id FROM user111 WHERE employer_id = :employerId Of course, the user111 table user111 not exist - this is the erroneous writing of the user table. At attempt of execution of incorrect sql RuntimeException processed, excepting object from further process; It is this behavior that was tested by dough. Indeed, when executing on HSQLDB, the code fell with an SQLException error (inherited from Exception ), which was then converted to JDBCException (inherited from RuntimeException ), this exception, in turn, was processed in the service method, removing the object being checked from the results, then additional operations were performed successfully for processed objects - and the test was completed correctly.
When the test was run on PostgreSQL, the error was still intercepted, converted to JDBCException and sent further, the incorrect object was excluded from processing, and everything would be fine, but the following actions were interrupted due to the fact that when an error of this kind occurred in the request - namely, when attempting to access a table that does not exist, PostgreSQL aborts the transaction, and other requests are no longer processed, which ultimately led to an incorrect end of the test.
Sorting problems
Here we can distinguish two classes of problems. The first is the inconsistency of the order of the entities in the test code and as a result of the request. For example, in a test there is a list of several instances, which are then created in the database and unloaded from it also as a list. So, in HSQLDB, the order in which objects were loaded from the database always coincided with the order in the source list. In PostgreSQL, the order did not coincide slightly less than in all tests where a similar construct was used, which led to the need to either use explicit sorting of the source and result lists, or compare lists without taking into account the order of elements (by the way, for these purposes it is quite convenient to use the arrayContainingInAnyOrder method from matcher framework Hamcrest).
The second problem turned out to be more serious: some tests in which database sorting was used ( ORDER BY ) stopped working. And the sorting behaved differently when running on different environments: after replacing the names of a couple of jobs, the test began to work correctly on Linux, but still did not work when running on MacOS and Windows.
Naturally, the suspicion fell on the locale settings in PostgreSQL — namely, the one that is responsible for sorting the rows in the database — LC_COLLATE . This setting does not depend on the encoding specified when creating the database: if you do not specify this parameter explicitly when the database is initialized in createdb or initdb , PostgreSQL will take the value from the operating system (by the way, you cannot change it after the database is initialized). Sorting rules can be very different: for example, take into account or not take into account spaces, as well as determining the priority of lowercase or uppercase letters.
Thus, we received tests, the results of which depend on the operating system — that is, a rather lousy situation. It would be possible to use a setting that allows sorting according to rules independent of the OS, using the standard sorting supplied with PostgreSQL, LC_COLLATE=C , but this option did not work, because in the implementation of embedded-pg from OpenTable there is no possibility to pass parameters to initdb . In the current implementation, you can change the server configuration at the start of the database, but you cannot set the collate settings there, so the problematic tests temporarily went to @Ignore . By the way, the OpenTable maintainer recognized the need for this feature, so after a brief discussion we created a PR in which we added the ability to initialize the database with different locale settings. Releases occur infrequently, but we hope that in the next version of embedded-pg this problem will be solved.
Problem of mapping custom types
As it is known, in Hibernate for storing fields of type “array” in the database, you need to write a custom type that implements the UserType interface. All you need to do is implement the necessary methods, including sqlTypes() , which determines the SQL type of the column in the database, as well as nullSafeSet() and nullSafeGet() , and add the @Type annotation indicating the custom type to the field declaration in the entity class (or by specifying this type in the mapping file).
In our projects, java.sql.Array was originally used to read and write objects of the array type, which works fine in conjunction with PostgreSQL in production. But, since mapping did not work in this way in HSQLDB, it was necessary to test entities that have arrays in their composition, we changed the implementation of user types a little. Direct implementation of nullSafeSet() and nullSafeGet() now managed strategies: the default code used was PostgreSQLArrayStrategy , which works with java.sql.Array , and during the execution of tests a custom HsqldbArrayStrategy strategy was passed to the user types, which used the HsqldbArrayStrategy pass to the user types to use the special types HsqldbArrayStrategy , which used the HsqldbArrayStrategy transfer the user types to send the HsqldbArrayStrategy special types HsqldbArrayStrategy . java.sql.Blob .
After translating the tests to PostgreSQL, we naively hoped that it would be easy to remove everything related to HSQLDB and the mapping will work by itself, but, of course, it was not so simple. In production, the class AbstractJdbcConnection used to get the sql type corresponding to the java type, which correctly resolves the types of arrays without any additional settings. Unfortunately, in the case of tests, this approach worked only half: the connection used only when performing the tests directly. At the same time, when creating a test base, another type definition mechanism works, namely, their mapping occurs during the creation of the SessionFactory , when metadata that represents the ORM model is initialized. This mechanism still needed to explicitly specify the type of arrays in the dialect description, otherwise Hibernate simply could not create a table with an array field:org.hibernate.MappingException: No Dialect mapping for JDBC type: 2003
The problem was that we could not specify the sql type for the arrays in the dialect file, because we had two ( String and Integer ), and only one type could be connected in this way, for example:
registerColumnType(Types.ARRAY, "integer[$l]"); I had to look for a workaround: for each user-defined type, an array type identifier was created, for example, string arrays were associated with type 200301 , and arrays of integers — with type 200302 . This identifier was returned in the sqlTypes() method:
public class EnumArrayUserTypeString extends EnumArrayUserType { public static final int VARCHAR_ARRAY_SQL_TYPE = 200301; @Override public int[] sqlTypes() { return new int[] {VARCHAR_ARRAY_SQL_TYPE}; } //... } Then the types were registered in a dialect:
public class HHPostgreSQLDialect extends PostgreSQL9Dialect { public HHPostgreSQLDialect() { registerColumnType(EnumArrayUserTypeString.VARCHAR_ARRAY_SQL_TYPE, "varchar[$l]"); registerColumnType(EnumArrayUserTypeInteger.INT_ARRAY_SQL_TYPE, "integer[$l]"); } // ... } After these manipulations, Hibernate was finally satisfied and created the necessary tables without any problems.
Performance issues
For a snack - the most burning question: what happened to the test performance? After all, HSQLDB was located directly in the memory, and embedded-pg - although the built-in, but in fact, full-fledged database, which creates a whole bunch of files at the start!
The first results were quite depressing: on machines with SSD, when running all the tests in the module, the speed dropped by 25–30%, on older machines with SATA everything was even worse (slowing down to 40%). The situation became noticeably better if the tests were run in several threads:mvn clean test -T C1
- but still did not cause delight, especially among those who had previously banished tests in multi-threaded mode.
We noticed suspicious logs when testing a project consisting of several modules: as soon as surefire started testing the next module, a new database instance was launched, with all the consequences: creating a data schema, filling in tables with test data - in general, many expensive I / O-operations. This seemed strange because the singleton holder was responsible for creating the base instance, which was written according to all the rules, including the volatile field for the instance storage and double-check locking in the receive method. What was our surprise when it turned out that this singleton was not exactly a singleton when the maven-surefire-plugin was involved!
By default, when testing the next module, surefire creates a new JVM process. In this process, all tests related to the module are performed; when testing is complete, surefire moves on to the next module that will be executed in the new JVM. The configuration of this behavior is controlled by the forkCount parameter, which by default is 1 (one new JVM per module). If this parameter is set to 0, then all modules will be executed in the same JVM.
It became clear that when using forkCount=1 we received a new PostgreSQL instance at the start of each module. Then it was decided to try to use one JVM for all tests, but in this case it turned out that an instance is created every time the next module starts! The reason for this was the so-called Isolated Classloader, which was used by surefire in the case of forkCount=0 . Despite the explicit instructions to use the system classifier ( useSystemClassloader=true ), in this case the surefire switches to isolated (by the way, reporting this in the logs, and the documentation on this behavior emphasizes - see Class Loading and Forking in Maven Surefire ). So, for each module, a separate classifier is created, which loads all the classes anew and, accordingly, re-creates our singleton instance with reference to the base instance. Thus, the problem was due to the internal mechanism of work surefire, and we decided to focus on those aspects of performance that could be corrected.
Temporary files in ram
First, we decided to transfer temporary files that embedded-pg creates during its operation from disks to memory, that is, to place them in a partition mounted as RAM FS. This approach was supposed to improve the situation at least on machines with slow disks, especially since by that time it was already used in tests to speed up another DBMS, Apache Cassandra - so there was no need to reinvent the wheel, it was necessary only to slightly expand and unify the code . The only "but": the old code was guided only by Linux, which supports the tmpfs file system. On Macs, there is also an analogue tmpfs, but, unlike Linux, MacOS does not have a partition that is created with such a default file system, like /dev/shm or /run in Linux. It's pretty easy to create, but it required the actions of developers, and I wanted everything to work transparently. Windows : , ( , ), RAM FS “ ” , , , RamDisk, PostgreSQL. , , , , ( 5%), .
, , : HSQLDB, in-memory database — , , PostgreSQL — jdbc url ! , Connection , , , ? c3p0 — , HSQLDB. , , .
PostgreSQL
PostgreSQL:
autovacuum;- (
preparedThreshold=X) — 1 4; - , ,
shared_bufferseffective_cache_size( , ). , , — , RAM, .
What is the result?
HSQLDB PostgreSQL, , . , , , — , , , .
, : - , , . - — , maven-surefire-plugin PostgreSQL. : , , - - .
UPD: , yandex-qatools " «»" — — . Lanwen !
Source: https://habr.com/ru/post/333616/
All Articles