Yandex opens CatBoost machine learning technology
Today, Yandex has posted in open source its own CatBoost library, developed taking into account the company's many years of experience in machine learning. With its help, it is possible to effectively train models on heterogeneous data, including those that are difficult to imagine in the form of numbers (for example, types of clouds or categories of goods). The source code, documentation, benchmarks, and necessary tools have already been published on GitHub under the Apache 2.0 license.

CatBoost is a new method of machine learning based on gradient boosting. It is implemented in Yandex for solving problems of ranking, prediction and building recommendations. Moreover, it is already used in cooperation with the European Organization for Nuclear Research (CERN) and industrial customers of Yandex Data Factory. So what makes CatBoost different from other open analogues? Why boosting and not the neural network method? How does this technology relate to the already known Matriksnet? And where are the seals? Today we will answer all these questions.
')
The term "machine learning" appeared in the 50s. This term refers to an attempt to teach a computer to solve problems that are easily given to a person, but it is difficult to formalize the way to solve them. As a result of machine learning, a computer may exhibit behavior that was not explicitly incorporated into it. In the modern world we are confronted with the results of machine learning every day many times, many of us unwittingly. It is used to build tapes in social networks, lists of “similar goods” in online stores, when issuing loans in banks and determining the cost of insurance. On machine learning technologies, there is a search for faces in photos or numerous photo filters. For the latter, by the way, neural networks are usually used, and they are written about so often that there can be an erroneous opinion that this is a “silver bullet” for solving problems of any complexity. But it is not.
Neural Networks or Gradient Boosting
In fact, machine learning is very different: there are a large number of different methods, and neural networks are just one of them. An illustration of this are the results of competitions on the Kaggle platform, where different methods win over different competitions, and the gradient boosting wins on many.
Neural networks perfectly solve certain tasks - for example, those where you need to work with homogeneous data. For example, images, sound, or text are made up of homogeneous data. In Yandex, they help us better understand search queries, look for similar pictures on the Internet, recognize your voice in the Navigator and much more. But this is not all tasks for machine learning. There is a whole layer of serious challenges that cannot be solved only by neural networks - they need a gradient boosting. This method is indispensable where there is a lot of data, and their structure is heterogeneous.
For example, if you need an accurate weather forecast, which takes into account a huge number of factors (temperature, humidity, radar data, user observations, and many others). Or, if you need to properly rank search results - this is what made Yandex in its time to develop its own machine learning method.
Matrixnet
The first search engines were not as complex as they are now. In fact, at first there was just a search for words - there were so few sites that there was not much competition between them. Then there were more pages, they became necessary to rank. Began to take into account various complications - the frequency of words, tf-idf . Then there were too many pages on any topic, the first important breakthrough occurred - we started to consider links.
Soon the Internet became commercially important, and there were many crooks trying to trick the simple algorithms that existed at that time. And there was a second important breakthrough - search engines began to use their knowledge of user behavior to understand which pages are good and which are not.
Ten years ago, the human mind was no longer enough to figure out how to rank the documents. You, probably, noticed that the quantity found on almost any query is huge: hundreds of thousands, often - millions of results. Most of them are uninteresting, useless, they only accidentally mention the words of the request or are spam at all. To answer your query, you need to instantly select the top ten of all the results found. To write a program that does this with an acceptable quality has become beyond the power of a human programmer. There was a next transition - search engines began to actively use machine learning.
Back in 2009, Yandex introduced its own Matrixnet method, based on gradient boosting. We can say that the ranking helps the collective mind of users and the " wisdom of the crowd ." Information about websites and people's behavior is transformed into many factors, each of which is used by Matrixnet to build a ranking formula. In fact, the ranking formula is now written by a car. By the way, we also use the results of the work of neural networks as separate factors (for example, this is how the Palekh algorithm, which was described last year) works.
An important feature of Matrixnet is that it is resistant to retraining. This allows you to take into account a lot of ranking factors and at the same time to study on a relatively small amount of data, without fear that the machine will find non-existent patterns. Other methods of machine learning allow you to either build simpler formulas with fewer factors, or they need a larger training set.
Another important feature of Matrixnet is that the ranking formula can be configured separately for fairly narrow classes of queries. For example, to improve the quality of the search only on requests for music. At the same time, ranking by other classes of queries will not deteriorate.
It was Matrixnet and its merits that formed the basis of CatBoost. But why do we even need to invent something new?
Categorical boosting
Virtually any modern gradient boost method works with numbers. Even if you have music genres, types of clouds or colors at the entrance, these data still need to be described in terms of numbers. This leads to a distortion of their essence and a potential decrease in the accuracy of the model.
We demonstrate this on a primitive example with a catalog of goods in the store. Goods are little connected with each other, and there is no such regularity between them, which would allow to order them and assign a meaningful number to each product. Therefore, in this situation, each product is simply assigned an ordinal id (for example, in accordance with the accounting program in the store). The order of these numbers does not mean anything, but the algorithm will use this order and draw false conclusions from it.
An experienced machine-learning specialist may come up with a more intelligent way of turning categorical features into numerical ones, but such preliminary preprocessing will lead to the loss of some information and lead to a deterioration in the quality of the final solution.
That is why it was important to teach the machine to work not only with numbers, but also with categories directly, the patterns between which it will reveal independently, without our manual "help". And CatBoost is designed by us so that it works equally well out of the box with both numeric and categorical features. Because of this, it shows a higher quality of training when working with heterogeneous data than alternative solutions. It can be used in various fields - from banking to industry.
By the way, the name of the technology comes from just Categorical Boosting (categorical boosting). And no cat in the development was not injured.
Benchmarks
You can talk for a long time about the theoretical differences of the library, but it’s better to show it once in practice. For clarity, we compared the work of the CatBoost library with the open counterparts XGBoost, LightGBM and H20 on a set of public datasets. And here are the results (the smaller, the better): https://catboost.yandex/#benchmark
We do not want to be unsubstantiated, therefore, along with the library, the open source contains a description of the comparison process, the code for running the method comparison, and the container with the used versions of all the libraries. Any user can repeat the experiment on their own or on their data.
CatBoost in practice
The new method has already been tested on Yandex services. It was used to improve search results, ranking the Yandex.Zen recommendations feed and for calculating the weather forecast in Meteum technology - and in all cases proved to be better than Matrixnet. In the future, CatBoost will work on other services. We will not stop here - it is better to immediately tell you about the Large Hadron Collider (LHC).
CatBoost managed to find an application in cooperation with the European Organization for Nuclear Research. The LHCb detector is used in the LHC, which is used to study the asymmetry of matter and antimatter in the interactions of heavy charming quarks. To accurately track the different particles recorded in the experiment, there are several specific parts in the detector, each of which determines the special properties of the particles. The most difficult task is to combine information from different parts of the detector into the most accurate, aggregated knowledge about the particle. This is where machine learning comes to the rescue. Using CatBoost to combine data, scientists managed to improve the quality characteristics of the final solution. CatBoost results were better than those obtained using other methods.
How to start using CatBoost?
To work with CatBoost, just install it on your computer. The library supports Linux, Windows and macOS operating systems and is available in the Python and R. programming languages. Yandex also developed the CatBoost Viewer visualization program, which allows you to monitor the learning process on graphs.
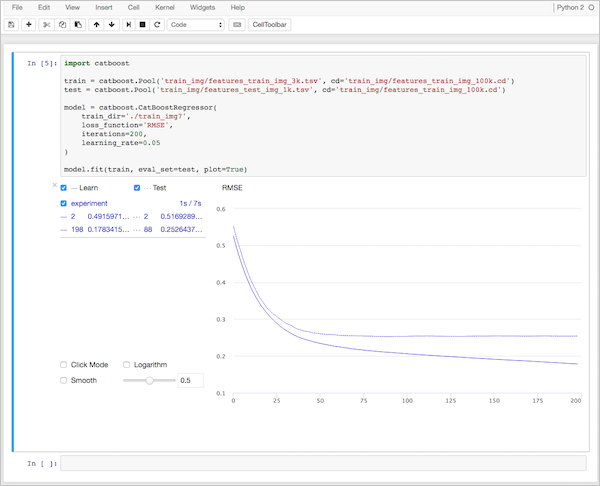
More details are described in our documentation .
CatBoost is the first Russian machine learning technology of such a scale that has become available in open source. Putting the library in open access, we want to contribute to the development of machine learning. We hope that the community of experts will appreciate the technology and take part in its development.
CatBoost is a new method of machine learning based on gradient boosting. It is implemented in Yandex for solving problems of ranking, prediction and building recommendations. Moreover, it is already used in cooperation with the European Organization for Nuclear Research (CERN) and industrial customers of Yandex Data Factory. So what makes CatBoost different from other open analogues? Why boosting and not the neural network method? How does this technology relate to the already known Matriksnet? And where are the seals? Today we will answer all these questions.
')
The term "machine learning" appeared in the 50s. This term refers to an attempt to teach a computer to solve problems that are easily given to a person, but it is difficult to formalize the way to solve them. As a result of machine learning, a computer may exhibit behavior that was not explicitly incorporated into it. In the modern world we are confronted with the results of machine learning every day many times, many of us unwittingly. It is used to build tapes in social networks, lists of “similar goods” in online stores, when issuing loans in banks and determining the cost of insurance. On machine learning technologies, there is a search for faces in photos or numerous photo filters. For the latter, by the way, neural networks are usually used, and they are written about so often that there can be an erroneous opinion that this is a “silver bullet” for solving problems of any complexity. But it is not.
Neural Networks or Gradient Boosting
In fact, machine learning is very different: there are a large number of different methods, and neural networks are just one of them. An illustration of this are the results of competitions on the Kaggle platform, where different methods win over different competitions, and the gradient boosting wins on many.
Neural networks perfectly solve certain tasks - for example, those where you need to work with homogeneous data. For example, images, sound, or text are made up of homogeneous data. In Yandex, they help us better understand search queries, look for similar pictures on the Internet, recognize your voice in the Navigator and much more. But this is not all tasks for machine learning. There is a whole layer of serious challenges that cannot be solved only by neural networks - they need a gradient boosting. This method is indispensable where there is a lot of data, and their structure is heterogeneous.
For example, if you need an accurate weather forecast, which takes into account a huge number of factors (temperature, humidity, radar data, user observations, and many others). Or, if you need to properly rank search results - this is what made Yandex in its time to develop its own machine learning method.
Matrixnet
The first search engines were not as complex as they are now. In fact, at first there was just a search for words - there were so few sites that there was not much competition between them. Then there were more pages, they became necessary to rank. Began to take into account various complications - the frequency of words, tf-idf . Then there were too many pages on any topic, the first important breakthrough occurred - we started to consider links.
Soon the Internet became commercially important, and there were many crooks trying to trick the simple algorithms that existed at that time. And there was a second important breakthrough - search engines began to use their knowledge of user behavior to understand which pages are good and which are not.
Ten years ago, the human mind was no longer enough to figure out how to rank the documents. You, probably, noticed that the quantity found on almost any query is huge: hundreds of thousands, often - millions of results. Most of them are uninteresting, useless, they only accidentally mention the words of the request or are spam at all. To answer your query, you need to instantly select the top ten of all the results found. To write a program that does this with an acceptable quality has become beyond the power of a human programmer. There was a next transition - search engines began to actively use machine learning.
Back in 2009, Yandex introduced its own Matrixnet method, based on gradient boosting. We can say that the ranking helps the collective mind of users and the " wisdom of the crowd ." Information about websites and people's behavior is transformed into many factors, each of which is used by Matrixnet to build a ranking formula. In fact, the ranking formula is now written by a car. By the way, we also use the results of the work of neural networks as separate factors (for example, this is how the Palekh algorithm, which was described last year) works.
An important feature of Matrixnet is that it is resistant to retraining. This allows you to take into account a lot of ranking factors and at the same time to study on a relatively small amount of data, without fear that the machine will find non-existent patterns. Other methods of machine learning allow you to either build simpler formulas with fewer factors, or they need a larger training set.
Another important feature of Matrixnet is that the ranking formula can be configured separately for fairly narrow classes of queries. For example, to improve the quality of the search only on requests for music. At the same time, ranking by other classes of queries will not deteriorate.
It was Matrixnet and its merits that formed the basis of CatBoost. But why do we even need to invent something new?
Categorical boosting
Virtually any modern gradient boost method works with numbers. Even if you have music genres, types of clouds or colors at the entrance, these data still need to be described in terms of numbers. This leads to a distortion of their essence and a potential decrease in the accuracy of the model.
We demonstrate this on a primitive example with a catalog of goods in the store. Goods are little connected with each other, and there is no such regularity between them, which would allow to order them and assign a meaningful number to each product. Therefore, in this situation, each product is simply assigned an ordinal id (for example, in accordance with the accounting program in the store). The order of these numbers does not mean anything, but the algorithm will use this order and draw false conclusions from it.
An experienced machine-learning specialist may come up with a more intelligent way of turning categorical features into numerical ones, but such preliminary preprocessing will lead to the loss of some information and lead to a deterioration in the quality of the final solution.
That is why it was important to teach the machine to work not only with numbers, but also with categories directly, the patterns between which it will reveal independently, without our manual "help". And CatBoost is designed by us so that it works equally well out of the box with both numeric and categorical features. Because of this, it shows a higher quality of training when working with heterogeneous data than alternative solutions. It can be used in various fields - from banking to industry.
By the way, the name of the technology comes from just Categorical Boosting (categorical boosting). And no cat in the development was not injured.
Benchmarks
You can talk for a long time about the theoretical differences of the library, but it’s better to show it once in practice. For clarity, we compared the work of the CatBoost library with the open counterparts XGBoost, LightGBM and H20 on a set of public datasets. And here are the results (the smaller, the better): https://catboost.yandex/#benchmark
We do not want to be unsubstantiated, therefore, along with the library, the open source contains a description of the comparison process, the code for running the method comparison, and the container with the used versions of all the libraries. Any user can repeat the experiment on their own or on their data.
CatBoost in practice
The new method has already been tested on Yandex services. It was used to improve search results, ranking the Yandex.Zen recommendations feed and for calculating the weather forecast in Meteum technology - and in all cases proved to be better than Matrixnet. In the future, CatBoost will work on other services. We will not stop here - it is better to immediately tell you about the Large Hadron Collider (LHC).
CatBoost managed to find an application in cooperation with the European Organization for Nuclear Research. The LHCb detector is used in the LHC, which is used to study the asymmetry of matter and antimatter in the interactions of heavy charming quarks. To accurately track the different particles recorded in the experiment, there are several specific parts in the detector, each of which determines the special properties of the particles. The most difficult task is to combine information from different parts of the detector into the most accurate, aggregated knowledge about the particle. This is where machine learning comes to the rescue. Using CatBoost to combine data, scientists managed to improve the quality characteristics of the final solution. CatBoost results were better than those obtained using other methods.
How to start using CatBoost?
To work with CatBoost, just install it on your computer. The library supports Linux, Windows and macOS operating systems and is available in the Python and R. programming languages. Yandex also developed the CatBoost Viewer visualization program, which allows you to monitor the learning process on graphs.
More details are described in our documentation .
CatBoost is the first Russian machine learning technology of such a scale that has become available in open source. Putting the library in open access, we want to contribute to the development of machine learning. We hope that the community of experts will appreciate the technology and take part in its development.
Source: https://habr.com/ru/post/333522/
All Articles