DBMS for 1C Fresh. Quickly. Reliably Is free
For several years now, the button has been using 1C Fresh publication technology for working with accounting databases. We have recently written about our operating experience. Our use of PostgreSQL as a DBMS aroused interest and a number of questions, so we decided to talk about this in more detail.

At the very beginning, we used the traditional MS SQL Server 1C as a DBMS. When our Fresh grew to the need for horizontal scaling, it became clear that for economic reasons an alternative to the Microsoft product is needed. Then we carefully looked in the direction of PostgreSQL, especially since experts from 1C recommended it for use in the 1C Fresh installation. We made a simple comparison of performance on standard operations and found that the base of Enterprise Accounting (BP) 3.0, containing about 600 areas, works just as well. At that time, we switched to a schema of several virtual machines on Linux with an application server and a DBMS. About this a bit told in the article . But for various reasons, a year later, an application server on Windows and a DBMS with several information bases (IB) on Linux came to the scheme. But we dare to assure you that we had no problems with the operation of the application server on Linux, the changes are related to some of our other work features.
')
So, PostgreSQL was chosen as the database server. In this article, Button tells how we made friends with one another, and how it all worked.
In the first installation, we used PostgreSQL 8.4.3-3.1C ready-made deb packages provided by 1C, since this was the recommended version for use. But unfortunately, we encountered a dependency problem when installing on Debian Wheezy, which is an oldstable release at that time, containing apache2.2 packages (apache2.4 support in 1C was not there yet). At that time, we kept the DBMS and the application server on the same host, so we had to use oldstable. To install this version of PostgreSQL, libc6 from Debian Jessie was required. As a result of such a cross-over, a system with which you can’t do anything special, even the installation of an NFS client, broke up the dependencies necessary for work. But switching to another Linux distribution was not strategically advantageous for us. When we began to actively use microservices (for simplicity, we call them robots ) that interacted with the application server through a COM connection, dangling connections began to appear in the databases, which led to a memory leak. This problem was solved by switching to a new version of PostgreSQL, but at that moment, 1C has not yet released the distribution of this version.
We made a willful decision to switch to using the PostgreSQL 9.6 assembly from the Postgres Professional repository. Problems with dependencies and memory leaks are left behind, and we began to address issues of scalability, load balancing, and increased availability time. Currently, 1C specialists have already updated PostgreSQL assemblies, the most recent 9.6.3, this is a very current version and it is safer to use it. According to information from 1C, new assemblies will be released promptly.
We are currently working on Debian Jessie and we will continue to look at all the issues in this distribution.
We monitor the state of our system using Zabbix, it looks like this:
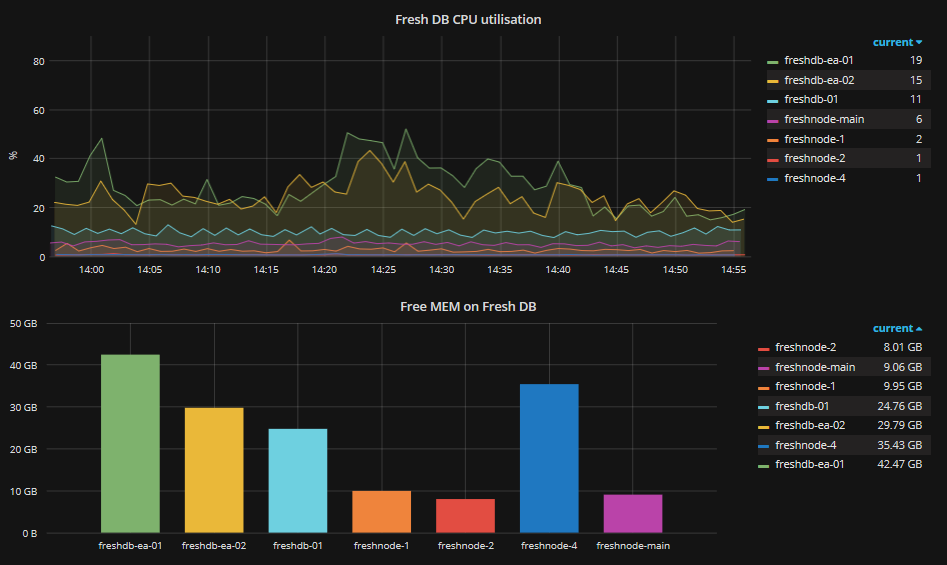
The charts still contain old servers, but the product has already been transferred from them to PostgreSQL 9.6.
And we measure the number of transactions:
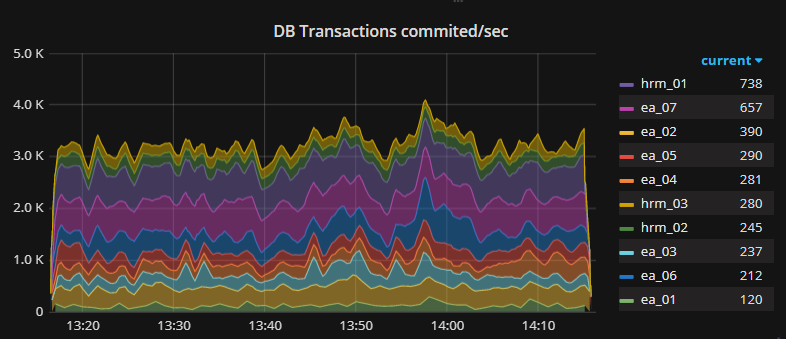
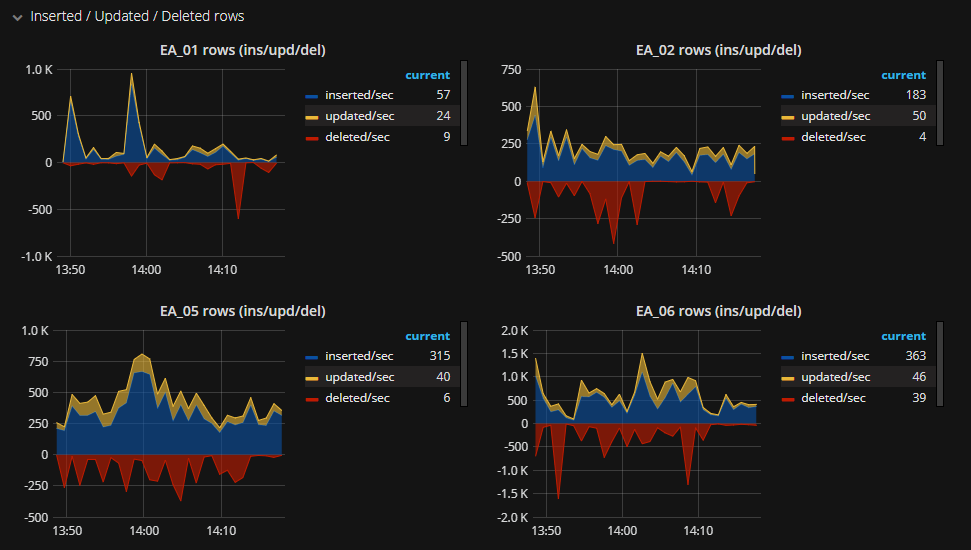
And the number of lines added, modified and deleted:
In the operation of the DBMS, we closely monitor our performance and all the settings below are born from real operation and observations. We now have 2 main DBMS servers, each of which is allocated 8 cores and 40 GB of memory. Disks with databases are located on the SSD. These resources are enough for us to maintain 7 IB BP 3.0 with the data sharing mode enabled (200-800 areas in one database). With this configuration, we have achieved a good resource utilization on the one hand and a good margin for growth and peak loads on the other.
When hosting multiple IBs on the same virtual machine, we are faced with administrative complexity. Each IB wanted its own server settings, any DBMS shutdown turned off all databases, and WAL archiving didn’t make any sense at all, because recovery through this mechanism would roll back all databases on the server.
To begin, each of our databases was placed in a separate PostgreSQL cluster, which allowed them to flexibly manage them, run several independent copies of PostgreSQL on one host, configure streaming replication, archive WAL, and restore data at a time (PiTR).
In practice, the deployment process looks like this:
We have a machine, with Debian 8 Jessie installed, PostgreSQL 9.6 already installed from the Postgres Professional repository.
Create our new cluster:
After that, the / db_01 directory will be created in / databases, which will house the data files, and the configuration files in /etc/postgresql/9.6/db_01/. The cluster will use PostgreSQL version 9.6. Its instance will be launched on port 5433. Now the cluster is not running, you can check it with the command:
We make changes to the configuration file of the postgresql.conf cluster, approximate parameter values can be obtained using PgTune . What one or another parameter is responsible for is described in detail in the documentation , we will only explain those parameters that PgTune does not take into account.
max_parallel_workers_per_gather it is useful to set a value equal to the number of workers that will be used in parallel for sequential reading of tables. This will speed up many read operations. Based on the number of cores on your host, exceeding this number will not give a performance boost, but on the contrary, degradation will occur.
max_locks_per_transaction is by default 64, but during the work the value was raised to 300. The parameter assigns the number of object locks allocated for the transaction. If a slave server is used, this value on it must be equal to or greater than on the master server.
If the file system is not productive enough, place pg_xlog on a separate storage.
For example, the config file of one cluster:
It is time to start the newly created cluster and start using it:
To connect via a non-standard port in the 1C Enterprise server administration snap-in, specify the following in the parameters of the information base in the "Database server" field:
It is also important not to forget about regular base maintenance. VACUUM and ANALYZE are very helpful.
Implementing a standby server is pretty simple.
Set up a master server
We make changes to the postgresql.conf configuration file, not forgetting that we are configuring our new cluster and the file is located in /etc/postgresql/9.6/db_01/
Create a new replica role:
And allow the connection for the slave server, correcting the file pg_hba.conf
After that, you need to restart the cluster:
Now it's time to set up the slave server. Suppose that its configuration is identical to the master, a cluster has been created with the same name, the data files are in a directory that is mounted similarly to the master. Stop the cluster on the slave:
In the postgresql.conf file, enable standby mode:
Clean up the directory with the data files on the slave / databases / db_01 / and make a copy of the current status of the wizard on the slave:
A recovery.conf file will be created, correct it if necessary:
In this case, we do not failover, which will automatically take on the role of the master. For the replica to start working as a wizard, just rename the recovery.conf file and restart the cluster.
We start the slave cluster:
Check that replication is on. The wal sender process will appear on the master, and the wal receiver will appear on the slave. More detailed information about replication can be obtained by running on the wizard:
On the slave, you can follow the value that shows when the last replication took place:
Initially, the backup was done by pg_dump once a day, which, together with the internal backup mechanism of the areas in 1C Fresh, gave an acceptable backup scheme. But sometimes there are situations when a large amount of work has been done between the moment of the last backup and the moment of the accident. In order not to lose these changes, archiving WAL files will help us.
To enable WAL archiving, three conditions must be met:
Wal_level must be replica or higher
Archive_mode = on parameter
The archive_command contains shell commands, for example:
So we copy the archived WAL segments into the / wal_backup / db_01 / directory
For the changes to take effect, a cluster restart is required. So, when the next WAL segment is ready, it will be copied, but in order to use it during restoration, you need a basic copy of the cluster, to which changes from the archive WAL segments will be applied. Using a simple script, we will create a base copy and put it next to the WAL files.
In order to restore a backup for a certain period of time (PiTR), stop the cluster and delete the contents
Then we unpack the base copy, check the rights and edit (or create) the recovery.conf file with the following content:
Thus, we will restore the data to the point in time 2017-06-12 21:33:00 MSK, and the breakpoint will be immediately after reaching this time.
In combat operation, a bunch of 1C Fresh and PostgreSQL showed themselves worthily, of course, not everything was smooth right away, but we managed. The DBMS works perfectly under load, which is generated by about a hundred users, a lot of background tasks, and even our robots load and issue extracts day and night, create documents from other tools, analyze the state of several thousand areas.
Picture about the reliability of the 1C Fresh and PostgreSQL bundles:
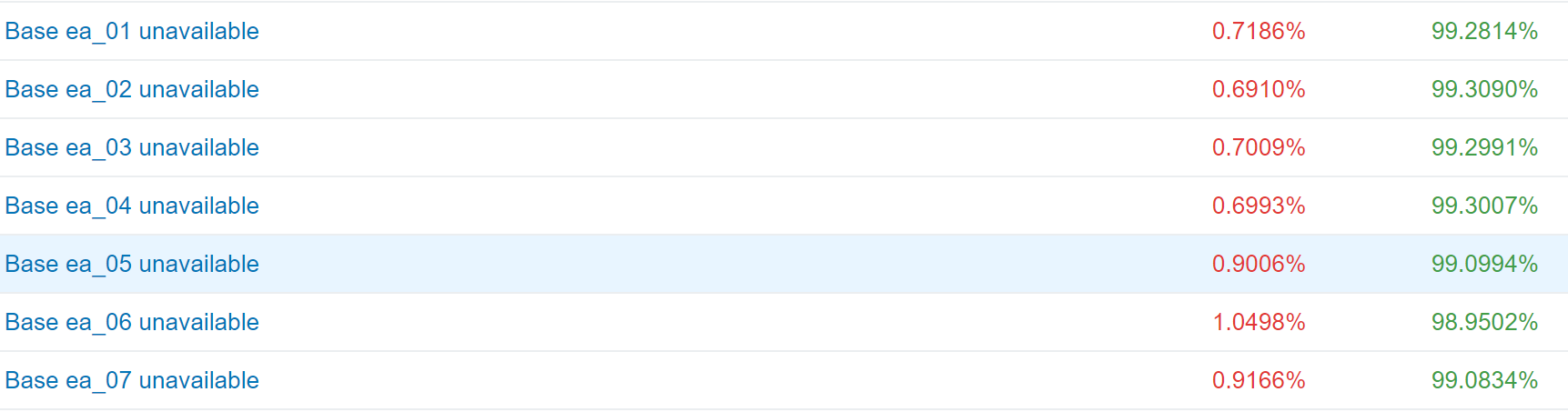
We have more than 350 GB of information databases that feel great, grow and develop. What and you want!
Introduction
At the very beginning, we used the traditional MS SQL Server 1C as a DBMS. When our Fresh grew to the need for horizontal scaling, it became clear that for economic reasons an alternative to the Microsoft product is needed. Then we carefully looked in the direction of PostgreSQL, especially since experts from 1C recommended it for use in the 1C Fresh installation. We made a simple comparison of performance on standard operations and found that the base of Enterprise Accounting (BP) 3.0, containing about 600 areas, works just as well. At that time, we switched to a schema of several virtual machines on Linux with an application server and a DBMS. About this a bit told in the article . But for various reasons, a year later, an application server on Windows and a DBMS with several information bases (IB) on Linux came to the scheme. But we dare to assure you that we had no problems with the operation of the application server on Linux, the changes are related to some of our other work features.
')
So, PostgreSQL was chosen as the database server. In this article, Button tells how we made friends with one another, and how it all worked.
In the first installation, we used PostgreSQL 8.4.3-3.1C ready-made deb packages provided by 1C, since this was the recommended version for use. But unfortunately, we encountered a dependency problem when installing on Debian Wheezy, which is an oldstable release at that time, containing apache2.2 packages (apache2.4 support in 1C was not there yet). At that time, we kept the DBMS and the application server on the same host, so we had to use oldstable. To install this version of PostgreSQL, libc6 from Debian Jessie was required. As a result of such a cross-over, a system with which you can’t do anything special, even the installation of an NFS client, broke up the dependencies necessary for work. But switching to another Linux distribution was not strategically advantageous for us. When we began to actively use microservices (for simplicity, we call them robots ) that interacted with the application server through a COM connection, dangling connections began to appear in the databases, which led to a memory leak. This problem was solved by switching to a new version of PostgreSQL, but at that moment, 1C has not yet released the distribution of this version.
We made a willful decision to switch to using the PostgreSQL 9.6 assembly from the Postgres Professional repository. Problems with dependencies and memory leaks are left behind, and we began to address issues of scalability, load balancing, and increased availability time. Currently, 1C specialists have already updated PostgreSQL assemblies, the most recent 9.6.3, this is a very current version and it is safer to use it. According to information from 1C, new assemblies will be released promptly.
We are currently working on Debian Jessie and we will continue to look at all the issues in this distribution.
We monitor the state of our system using Zabbix, it looks like this:
The charts still contain old servers, but the product has already been transferred from them to PostgreSQL 9.6.
And we measure the number of transactions:
And the number of lines added, modified and deleted:
In the operation of the DBMS, we closely monitor our performance and all the settings below are born from real operation and observations. We now have 2 main DBMS servers, each of which is allocated 8 cores and 40 GB of memory. Disks with databases are located on the SSD. These resources are enough for us to maintain 7 IB BP 3.0 with the data sharing mode enabled (200-800 areas in one database). With this configuration, we have achieved a good resource utilization on the one hand and a good margin for growth and peak loads on the other.
Clusters in PostgreSQL
When hosting multiple IBs on the same virtual machine, we are faced with administrative complexity. Each IB wanted its own server settings, any DBMS shutdown turned off all databases, and WAL archiving didn’t make any sense at all, because recovery through this mechanism would roll back all databases on the server.
To begin, each of our databases was placed in a separate PostgreSQL cluster, which allowed them to flexibly manage them, run several independent copies of PostgreSQL on one host, configure streaming replication, archive WAL, and restore data at a time (PiTR).
In practice, the deployment process looks like this:
We have a machine, with Debian 8 Jessie installed, PostgreSQL 9.6 already installed from the Postgres Professional repository.
Create our new cluster:
# pg_createcluster 9.6 -p 5433 -d /databases/db_01 After that, the / db_01 directory will be created in / databases, which will house the data files, and the configuration files in /etc/postgresql/9.6/db_01/. The cluster will use PostgreSQL version 9.6. Its instance will be launched on port 5433. Now the cluster is not running, you can check it with the command:
# pg_lsclusters We make changes to the configuration file of the postgresql.conf cluster, approximate parameter values can be obtained using PgTune . What one or another parameter is responsible for is described in detail in the documentation , we will only explain those parameters that PgTune does not take into account.
max_parallel_workers_per_gather it is useful to set a value equal to the number of workers that will be used in parallel for sequential reading of tables. This will speed up many read operations. Based on the number of cores on your host, exceeding this number will not give a performance boost, but on the contrary, degradation will occur.
max_locks_per_transaction is by default 64, but during the work the value was raised to 300. The parameter assigns the number of object locks allocated for the transaction. If a slave server is used, this value on it must be equal to or greater than on the master server.
If the file system is not productive enough, place pg_xlog on a separate storage.
For example, the config file of one cluster:
# ----------------------------- # PostgreSQL configuration file # ----------------------------- #------------------------------------------------------------------------------ # FILE LOCATIONS #------------------------------------------------------------------------------ data_directory = '/db/disk_database_db_01/db_01' hba_file = '/etc/postgresql/9.6/db_01/pg_hba.conf' ident_file = '/etc/postgresql/9.6/db_01/pg_ident.conf' external_pid_file = '/var/run/postgresql/9.6-db_01.pid' #------------------------------------------------------------------------------ # CONNECTIONS AND AUTHENTICATION #------------------------------------------------------------------------------ listen_addresses = '*' port = 5433 max_connections = 100 unix_socket_directories = '/var/run/postgresql' ssl = true ssl_cert_file = '/etc/ssl/certs/ssl-cert-snakeoil.pem' ssl_key_file = '/etc/ssl/private/ssl-cert-snakeoil.key' #------------------------------------------------------------------------------ # RESOURCE USAGE (except WAL) #------------------------------------------------------------------------------ shared_buffers = 1536MB work_mem = 7864kB maintenance_work_mem = 384MB dynamic_shared_memory_type = posix shared_preload_libraries = 'online_analyze, plantuner,pg_stat_statements' #------------------------------------------------------------------------------ # WRITE AHEAD LOG #------------------------------------------------------------------------------ wal_level = replica wal_buffers = 16MB max_wal_size = 2GB min_wal_size = 1GB checkpoint_completion_target = 0.9 #------------------------------------------------------------------------------ # REPLICATION #------------------------------------------------------------------------------ max_wal_senders = 2 wal_keep_segments = 32 #------------------------------------------------------------------------------ # QUERY TUNING #------------------------------------------------------------------------------ effective_cache_size = 4608MB #------------------------------------------------------------------------------ # RUNTIME STATISTICS #------------------------------------------------------------------------------ stats_temp_directory = '/var/run/postgresql/9.6-db_01.pg_stat_tmp' #------------------------------------------------------------------------------ # CLIENT CONNECTION DEFAULTS #------------------------------------------------------------------------------ datestyle = 'iso, dmy' timezone = 'localtime' lc_messages = 'ru_RU.UTF-8' # locale for system error message # strings lc_monetary = 'ru_RU.UTF-8' # locale for monetary formatting lc_numeric = 'ru_RU.UTF-8' # locale for number formatting lc_time = 'ru_RU.UTF-8' # locale for time formatting default_text_search_config = 'pg_catalog.russian' #------------------------------------------------------------------------------ # LOCK MANAGEMENT #------------------------------------------------------------------------------ max_locks_per_transaction = 300 # min 10 #------------------------------------------------------------------------------ # VERSION/PLATFORM COMPATIBILITY #------------------------------------------------------------------------------ escape_string_warning = off standard_conforming_strings = off #------------------------------------------------------------------------------ # CUSTOMIZED OPTIONS #------------------------------------------------------------------------------ online_analyze.threshold = 50 online_analyze.scale_factor = 0.1 online_analyze.enable = on online_analyze.verbose = off online_analyze.min_interval = 10000 online_analyze.table_type = 'temporary' plantuner.fix_empty_table = false It is time to start the newly created cluster and start using it:
# pg_ctlcluster 9.6 db_01 start To connect via a non-standard port in the 1C Enterprise server administration snap-in, specify the following in the parameters of the information base in the "Database server" field:
hostname port=5433It is also important not to forget about regular base maintenance. VACUUM and ANALYZE are very helpful.
Stream replication
Implementing a standby server is pretty simple.
Set up a master server
We make changes to the postgresql.conf configuration file, not forgetting that we are configuring our new cluster and the file is located in /etc/postgresql/9.6/db_01/
listen_addresses = '*'
wal_level = replica
max_wal_senders = 3
wal_keep_segments = 128Create a new replica role:
postgres=# CREATE ROLE replica WITH REPLICATION PASSWORD 'MyBestPassword' LOGIN; And allow the connection for the slave server, correcting the file pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD host replication replica 192.168.0.0/24 md5 After that, you need to restart the cluster:
# pg_ctlcluster 9.6 db_01 restart Now it's time to set up the slave server. Suppose that its configuration is identical to the master, a cluster has been created with the same name, the data files are in a directory that is mounted similarly to the master. Stop the cluster on the slave:
# pg_ctlcluster 9.6 db_01 stop In the postgresql.conf file, enable standby mode:
hot_standby = on
Clean up the directory with the data files on the slave / databases / db_01 / and make a copy of the current status of the wizard on the slave:
# cd /databases/db_01 # rm -Rf /databases/db_01 # su postgres -c "pg_basebackup -h master.domain.local -p 5433 -U replica -D /databases/db_01 -R -P --xlog-method=stream" A recovery.conf file will be created, correct it if necessary:
standby_mode = 'on'
primary_conninfo = 'user=replica password=MyBestPassword host=master.domain.local port=5433 sslmode=prefer sslcompression=1 krbsrvname=postgres'In this case, we do not failover, which will automatically take on the role of the master. For the replica to start working as a wizard, just rename the recovery.conf file and restart the cluster.
We start the slave cluster:
# pg_ctlcluster 9.6 db_01 start Check that replication is on. The wal sender process will appear on the master, and the wal receiver will appear on the slave. More detailed information about replication can be obtained by running on the wizard:
SELECT *,pg_xlog_location_diff(s.sent_location,s.replay_location) byte_lag FROM pg_stat_replication s; On the slave, you can follow the value that shows when the last replication took place:
SELECT now()-pg_last_xact_replay_timestamp(); WAL Backup and Archiving
Initially, the backup was done by pg_dump once a day, which, together with the internal backup mechanism of the areas in 1C Fresh, gave an acceptable backup scheme. But sometimes there are situations when a large amount of work has been done between the moment of the last backup and the moment of the accident. In order not to lose these changes, archiving WAL files will help us.
To enable WAL archiving, three conditions must be met:
Wal_level must be replica or higher
Archive_mode = on parameter
The archive_command contains shell commands, for example:
archive_command = 'test ! -f /wal_backup/db_01/%f && cp %p /wal_backup/db_01/%f'So we copy the archived WAL segments into the / wal_backup / db_01 / directory
For the changes to take effect, a cluster restart is required. So, when the next WAL segment is ready, it will be copied, but in order to use it during restoration, you need a basic copy of the cluster, to which changes from the archive WAL segments will be applied. Using a simple script, we will create a base copy and put it next to the WAL files.
#!/bin/bash db="db_01" wal_arch="/wal_backup" datenow=`date '+%Y-%m-%d %H:%M:%S'` mkdir /tmp/pg_backup_$db su postgres -c "/usr/bin/pg_basebackup --port=5433 -D /tmp/pg_backup_$db -Ft -z -Xf -R -P" test -e ${wal_arch}/$db/base.${datenow}.tar.gz && rm ${wal_arch}/$db/base.${datenow}.tar.gz cp /tmp/pg_backup_$db/base.tar.gz ${wal_arch}/$db/base.${datenow}.tar.gz In order to restore a backup for a certain period of time (PiTR), stop the cluster and delete the contents
# pg_ctlcluster 9.6 db_01 stop # rm -Rf /databases/db_01 Then we unpack the base copy, check the rights and edit (or create) the recovery.conf file with the following content:
restore_command = 'cp /wal_backup/db_01/%f %p'
recovery_target_time = '2017-06-12 21:33:00 MSK'
recovery_target_inclusive = true
Thus, we will restore the data to the point in time 2017-06-12 21:33:00 MSK, and the breakpoint will be immediately after reaching this time.
Conclusion
In combat operation, a bunch of 1C Fresh and PostgreSQL showed themselves worthily, of course, not everything was smooth right away, but we managed. The DBMS works perfectly under load, which is generated by about a hundred users, a lot of background tasks, and even our robots load and issue extracts day and night, create documents from other tools, analyze the state of several thousand areas.
Picture about the reliability of the 1C Fresh and PostgreSQL bundles:
We have more than 350 GB of information databases that feel great, grow and develop. What and you want!
Source: https://habr.com/ru/post/333480/
All Articles