Let's talk about micro-optimizations on the example of Tizen code

As a rule, when discussing the diagnostic capabilities of PVS-Studio, the recommendations provided by the analyzer regarding the micro-optimizations of C and C ++ code remain behind the scenes. Of course, micro-optimizations are not as important as diagnostics that detect errors, but it's also interesting to talk about them.
Micro-optimizations
I continue the cycle of articles related to the code analysis of the operating system Tizen. The Tizen project, (including third-party libraries) has about 72,500,000 lines of C and C ++ code. The project is interesting to me because of its size, since it allows to demonstrate various aspects of using the methodology of static code analysis.
In the previous article, " 27000 errors in the Tizen operating system ", I showed how you can estimate the number of errors that can be detected by a static code analyzer. The article also reviewed a large number of code fragments that demonstrate the capabilities of the analyzer in identifying various types of defects. However, in addition to detecting errors, the analyzer can offer a number of improvements that affect the performance of the code.
I’ll say right away that PVS-Studio does not act and cannot act as a substitute for the tools of program profiling. Only dynamic program analyzers can identify bottlenecks. Static analyzers do not know which input data the program receives and how often a particular code section is executed. Therefore, we say that the analyzer offers to perform some “ micro- optimization” of the code that does not guarantee a performance boost at all.
')
If the use of micro-optimizations should not wait for a noticeable performance increase, are they needed at all? Yes, and I have the following rationales for this:
- Appropriate analyzer diagnostics often reveal bad code. Changing it, the programmer will make the code easier, clearer and often shorter.
- There is little use of micro-optimizations in the Release version, as compilers now know how to optimize code perfectly. But in the Debug version, some micro-optimizations are not at all “micro” and allow us to speed up the operation of the application, which is very useful.
In PVS-Studio, there are still few diagnostics dedicated to micro-optimizations (see diagnostics with V801-V820 numbers), but gradually we will develop a set of these diagnostics. In the articles we rarely paid attention to them, so now, in the process of studying the Tizen code, there is a good time to talk about this topic.
So, let's look at the existing PVS-Studio warnings dedicated to micro-optimizations.
Examples of triggers
As I wrote in the previous article , I studied about 3.3% of the Tizen code. Therefore, I can predict how many alerts of a certain type PVS-Studio will issue for the entire project, multiplying the number of messages found by 30.

Please remember this factor 30 , since I will constantly use it in further calculations.
V801: It is better to redefine the function.
It is inefficient to make functions that take "heavy" arguments by value. Diagnostics are triggered when the arguments are constant and therefore will not exactly change in the body of the function.
Example from Tizen code:
inline void setLogTag(const std::string tagName) { m_tag = tagName; } PVS-Studio: V801 Decreased performance. It is better to redefine it. Consider replacing 'const ... tagName' with 'const ... & tagName'. Logger.h 110
An extra tagName object is created , which is an expensive operation. This code performs operations such as allocating memory and copying data. Moreover, these expensive operations can be avoided. The simplest option is to pass an argument over a constant link:
inline void setLogTag(const std::string &tagName) { m_tag = tagName; } So we got rid of memory allocation and string copying.
There is another option. You can remove const and not copy, but move the data:
inline void setLogTag(std::string tagName) { m_tag = std::move(tagName); } This code will be just as effective.
The variant with std :: string is of course harmless. Creating an extra line is unpleasant, but it cannot somehow affect the speed of work. However, there may be more serious situations when, for example, in vain you create an array of strings. We will take a look at one such case below, when we talk about diagnosing the V813.
In total, the analyzer issued 76 warnings for the projects I studied.
It should be borne in mind that the analyzer can sometimes produce triggers that are not of practical use. For example, the analyzer cannot distinguish a self-made smart pointer from a single-linked list element. Both there and there will be a pointer (to the line / next element). Both there and there will be an integer variable (the length of the string / value of the list item). It seems to be the same thing, but the costs of copying such objects will be fundamentally different. Of course, you can look into the copy constructor and try to understand what's what, but on the whole, this is a hopeless exercise. Therefore, it makes sense to ignore such alarms and to suppress them you should use one of the mechanisms provided by the PVS-Studio analyzer. About these mechanisms, I, perhaps, in the future, I will write a separate article.
Now we need a factor of 30, about which I spoke earlier. Using it, I can calculate that for the entire Tizen project, the PVS-Studio analyzer will generate about 76 * 30 = 2280 warnings of V801.
V802: On the 32-bit / 64-bit platform, it can be reduced to
Diagnostics V802 is looking for structures and classes, the size of which can be reduced by sorting the fields in descending order of their size. Example of non-optimal structure:
struct LiseElement { bool m_isActive; char *m_pNext; int m_value; }; This structure in the 64-bit code ( LLP64 ) will occupy 24 bytes, which is associated with data alignment . If you change the sequence of fields, then its size will be only 16 bytes. The optimized version of the structure will look like this:
struct LiseElement { char *m_pNext; int m_value; bool m_isActive; }; Note that the structure is always 12 bytes in a 32-bit program, regardless of the sequence of the fields. Therefore, when checking the 32-bit configuration ( ILP32LL ), the message V802 will not be issued.
It should be noted that optimization of structures is not always possible and is not always necessary.
Optimization is not possible if you need to maintain data format compatibility. More often, this optimization is simply not needed. If objects of a non-optimal structure are created in tens or hundreds, then no useful gain will be obtained. It makes sense to think about this optimization when the number of elements is in the millions. After all, the smaller the size of each structure, the more such structures will be placed in the microprocessor caches.
As you can see, the scope of application of the V802 diagnostics is extremely small, so it is often reasonable to turn off this diagnostics so that it does not interfere. Accordingly, I see no reason to count how many non-optimal structures PVS-Studio can find in the Tizen code. I think that in more than 99% of cases it is not necessary to optimize structures. I will demonstrate here only the very possibility of such an analysis, citing one warning issued to the Tizen code.
typedef struct { unsigned char format; long long unsigned fields; int index; } bt_pbap_pull_vcard_parameters_t; PVS-Studio: V802 On 32-bit platform, it can be reduced by 24 to 16 bytes by rearranging. bluetooth api.h 1663
If the analyzer does not make mistakes, then when compiling code for the Tizen platform, the type long long unsigned should be aligned at the 8 byte boundary. To be honest, we haven’t yet clarified this point, since this platform is new for us, but this is the case in systems I know :).
So, once the variable fields is aligned on the border of 8 bytes, the structure will look like this in memory:

You can shuffle class members like this:
typedef struct { long long unsigned fields; int index; unsigned char format; } bt_pbap_pull_vcard_parameters_t; Then it will be possible to save 8 bytes and the structure will be allocated in memory as follows:
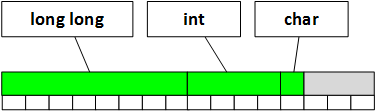
As you can see, the size of the structure has decreased.
V803. It is a form of ++ it. Replace iterator ++ with ++ iterator
In books, it is recommended to use the prefix increment of iterators in cycles, instead of postfix increment. The question of how relevant this is today is considered in the articles:
- Andrey Karpov. Is it practical to use the prefix increment operator ++ it for iterators instead of postfix increment it ++ .
- Silviu Ardelean. pre vs. post increment operator - benchmark .
A brief conclusion is this. For the release version of the application there is no difference. For the Debug version there is a difference, and a significant one. Therefore, the recommendation is relevant and it should be followed. It is often useful for the Debug version to work quickly.
Consider an example of analyzer triggering:
void ServiceManagerPrivate::loadServiceLibs() { auto end = servicesLoaderMap.end(); for(auto slm = servicesLoaderMap.begin(); slm !=end; slm++ ){ try{ ServiceFactory* factory=((*slm).second->getFactory()); servicesMap[factory->serviceName()] = factory; }catch (std::runtime_error& e){ BROWSER_LOGD(e.what() ); } } } PVS-Studio: V803 Decreased performance. In case of a slm is an iterator Replace iterator ++ with ++ iterator. ServiceManager.cpp 67
It will be useful to replace slm ++ with ++ slm . Of course, one replacement will give nothing and this should be approached systematically. For the code I tested, the analyzer issued 103 recommendations. This means that, if desired, it will be possible to modify about 3,000 places in Tizen. Due to such changes, the debug version will work a bit faster.
V804: the same string
There are situations when the code calculates the length of the same line two or more times. In the debug version, this is an unambiguous slowdown of the program, especially if the code is executed many times. As it will be in the Release-version is unknown, but there is a high probability that the compiler will not guess how much to combine the calls to the strlen function into one call.
Consider the sample code.
static isc_result_t buildfilename(...., const char *directory, ....) { .... if (strlen(directory) > 0U && directory[strlen(directory) - 1] != '/') isc_buffer_putstr(out, "/"); .... } PVS-Studio: V804 Decreased performance. The 'strlen' function is to calculate the length of the string. dst_api.c 1832
The length of the directory name is calculated twice. By the way, V805 warning will be issued for this code, but we'll talk about it below.
This code can be improved by adding a temporary variable to store the length:
const size_t directory_len = strlen(directory); if (directory_len > 0U && directory[directory_len - 1] != '/') isc_buffer_putstr(out, "/"); I am not saying that this is a must do. I myself think that this code can be set as it is. I just need a demo. The fact that specifically editing the code will not give a win means nothing. There may be places where such optimization can significantly speed up the work of cycles in which there is a processing of strings.
For the verified code, the analyzer issued 20 warnings. The total predicted number of warnings is 600 .
V805: It 's using the' strlen (str)> 0 'construct
Returning to the code discussed in the previous section.
if (strlen(directory) > 0U && directory[strlen(directory) - 1] != '/') PVS-Studio: V805 Decreased performance. It is not necessary to identify the string by using 'strlen (str)> 0' construct. A more efficient way is to check: str [0]! = '\ 0'. dst_api.c 1832
In addition to storing the length of the string in an intermediate variable, there is another way to optimize the code. The first call to strlen is needed to check if the string is empty or not. In fact, using the strlen function for this purpose is a redundant operation, since it suffices to check only the value of the first byte of the string. Therefore, you can optimize the code like this:
if (*directory != '\0' && directory[strlen(directory) - 1] != '/') Or so:
if (directory[0] && directory[strlen(directory) - 1] != '/') And so on. As you understand, there are a lot of options how to change the code. It doesn’t matter how the check is recorded, the main thing is that you don’t need to go through all the characters of the string to understand whether it is empty or not. Of course, the compiler can guess the programmer’s intention and optimize the check in the Release version, but you shouldn’t expect such a gift in advance.
One more example:
V805 Decreased performance. It is not necessary to identify the string by using 'strlen (str)! = 0' construct. A more efficient way is to check: str [0]! = '\ 0'. bt-util.c 376
void _bt_util_set_phone_name(void) { char *phone_name = NULL; char *ptr = NULL; phone_name = vconf_get_str(VCONFKEY_SETAPPL_DEVICE_NAME_STR); if (!phone_name) return; if (strlen(phone_name) != 0) { // <= if (!g_utf8_validate(phone_name, -1, (const char **)&ptr)) *ptr = '\0'; bt_adapter_set_name(phone_name); } free(phone_name); } PVS-Studio: V805 Decreased performance. It is not necessary to identify the string by using 'strlen (str)! = 0' construct. A more efficient way is to check: str [0]! = '\ 0'. bt-util.c 376
There is nothing special about this code. With it, I wanted to specifically demonstrate that this is a typical and extremely common way to check whether an empty string or not. In fact, I'm even surprised why there is no standard function or macro in C to detect a blank line. You can not even imagine how many such ineffective checks live in our programs. I'm going to shock you now.
In the part of Tizen I tested, the PVS-Studio analyzer revealed 415 places where the strlen function or its equivalent is used to determine if the string is empty or not.
Accordingly, the predicted number of warnings for the entire Tizen project is 12,450 .
Imagine how often the microprocessor drives stupid cycles to search for a terminal zero and clogs the caches with data that it might not be useful to it.
In my opinion, it makes sense to get rid of such inefficient calls to strlen functions. You can write:
- if (* phone_name)
- if (* phone_name! = '\ 0')
- if (phone_name [0])
- if (phone_name [0]! = '\ 0')
But I do not like such options, since such code is difficult to read. It is much better to make a special macro in C, and an inline function in C ++. Such code will be read much better:
if (is_empty_str(phone_name)) Once again, it is strange for me that for all the years the universal standard method for checking C-lines for emptiness has not been created. In my opinion, this generates a huge amount of code in many projects that could work a little faster. Agree, 12450 ineffective checks deserve attention.
V806: The expression of strlen (MyStr.c_str ()) kind can be rewritten as MyStr.length ()
If there were a huge number of V805 warnings, then for scanned projects the analyzer issued only 2 warnings of V806. Let's take a look at one of these rare birds:
static void panel_slot_forward_key_event ( int context, const KeyEvent &key, bool remote_mode) { .... if (strlen(key.get_key_string().c_str()) >= 116) return; .... } PVS-Studio: V806 Decreased performance. The expression of strlen (MyStr.c_str ()) kind can be rewritten as MyStr.length (). wayland_panel_agent_module.cpp 2511
Usually this situation arises after refactoring the old C-code, which has become C ++ code. The length of a string in a variable of type std :: string is determined using strlen . The method is clearly ineffective, and even complicating code. Normal way:
if (key.get_key_string().length() >= 116) return; The code has become shorter and faster. The expected number of warnings in the project Tizen: 60 .
V807: Consider creating the same expression repeatedly
Sometimes in programs you can find an expression that includes many operators "->" and ".". For example, something like this:
To()->be.or->not().to()->be(); In Russia, this is called "programming using the train." I don’t know if there is an English analogue to this coding style, but I think in any case it’s clear why the train is mentioned here.
Such code is considered bad, and in books dedicated to the quality of the code, it is recommended to avoid it. It is even worse if such “trains” repeat many times. First, they clutter up the text of the program, and secondly, they can degrade program performance. Consider one of these cases:

PVS-Studio: V807 Decreased performance. Consider creating a reference to avoid using the same expression repeatedly. ImageObject.cpp 262
In my opinion, this code will look better if you write it like this:
for (....) { auto &keypoint = obj.__features.__objectKeypoints[keypointNum]; os << keypoint.pt.x << ' '; os << keypoint.pt.y << ' '; os << keypoint.size << ' '; os << keypoint.response << ' '; os << keypoint.angle << ' '; os << keypoint.octave << ' '; os << keypoint.class_id << '\n'; } Will such code be faster? Not. Compared to the slow data output to the stream, all other operations are insignificant, even if we are talking about the debug version.
But the second version of the code is shorter, it is easier to read and accompany.
As I said, we won’t get performance gains here. However, there may be places where such optimization can be useful. This happens if there are calls of slow long functions in the “steam train”. In such places, the compiler cannot figure out how to perform optimization and it turns out a huge number of redundant function calls.
In total, the analyzer pointed to 93 code fragments. The predicted total number of alerts is 2,700 .
V808:
The following diagnosis is very interesting. It identifies variables and arrays that are not used. Most often, such artifacts arise in the process of refactoring, when they forget to remove the declaration of a more unused variable.
An unused variable may also indicate a logical error in the program, but, in my experience, this happens rarely.
The analyzer issues a warning in the following cases:
- An array is created, but not used. This means that the function uses more stack memory than necessary. First, it may contribute to a situation where a stack overflow occurs. Secondly, it can reduce the efficiency of the cache in the microprocessor.
- Class objects are created but not used. The analyzer warns not about all objects, but about those that are guaranteed to be meaningless to create and not to use. For example, std :: string or CString . Creating and destroying such objects is a waste of CPU time and stack.
Separately, I note that the analyzer does not swear for extra variables, for example, of type float or char . In this case, an incredible amount of uninteresting false positives is obtained. There are a lot of such situations in the code, where macros or preprocessor directives are widely used #if .. # else .. # endif . Moreover, these extra variables are harmless, since the compiler will remove them in the optimization process.
Let's look at a couple of examples of alerts issued for the Tizen code:
void CynaraAdmin::userRemove(uid_t uid) { std::vector<CynaraAdminPolicy> policies; std::string user = std::to_string(static_cast<unsigned int>(uid)); emptyBucket(Buckets.at(Bucket::PRIVACY_MANAGER),true, CYNARA_ADMIN_ANY, user, CYNARA_ADMIN_ANY); } PVS-Studio: V808 'policies' object of 'vector' type created. cynara.cpp 499
The variable policies is not used. It just needs to be removed.
And now a more suspicious code:
static void _focused(int id, void *data, Evas_Object *obj, Elm_Object_Item *item) { struct menumgr *m = (struct menumgr *)data; Elm_Focus_Direction focus_dir[] = { ELM_FOCUS_LEFT, ELM_FOCUS_RIGHT, ELM_FOCUS_UP, ELM_FOCUS_DOWN }; int i; Evas_Object *neighbour; if (!obj || !m) return; if (m->info[id] && m->info[id]->focused) m->info[id]->focused(m->data, id); for (i = 0; i < sizeof(focus_dir) / sizeof(focus_dir[0]); ++i) { neighbour = elm_object_focus_next_object_get(obj, i); evas_object_stack_above(obj, neighbour); } } PVS-Studio: V808 'focus_dir' array was not used. menumgr.c 110
The focus_dir array is not used. This is strange, and maybe there is some kind of mistake, but maybe not. It is difficult for me to give an answer without starting a serious study of the code.
For the verified code, the analyzer issued 30 warnings. The predicted number of warnings for the entire code is 900 .
V809: The 'if (ptr! = NULL)' check can be be removed
We got to the diagnosis, which gives the most positives. Very often people write this code:
if (P) free(P); if (Q) delete Q; This code is redundant. The free function and the delete operator work perfectly well with null pointers.
The code can be simplified:
free(P); delete Q; An extra check does nothing and only slows down the code.
Here I can say that such code is faster. If the pointer is zero, then it is not necessary to go inside the free function or the delete operator and do a check somewhere inside them.
I disagree. Most of the code is written based on the fact that pointers are not null. A null pointer is usually a special / emergency situation that occurs rarely. Therefore, almost always, when we refer to free / delete , we pass a non-zero pointer there. And if so, then the preliminary check is harmful, but at the same time clutters the code.
As an example, consider the following function:
lwres_freeaddrinfo(struct addrinfo *ai) { struct addrinfo *ai_next; while (ai != NULL) { ai_next = ai->ai_next; if (ai->ai_addr != NULL) free(ai->ai_addr); if (ai->ai_canonname) free(ai->ai_canonname); free(ai); ai = ai_next; } } Here are two extra checks at once, about which the analyzer informs
- V809 Verifying that a pointer value is not NULL is not required. The 'if (ai-> ai_addr! = NULL)' check can be removed. getaddrinfo.c 694
- V809 Verifying that a pointer value is not NULL is not required. The 'if (ai-> ai_canonname)' check can be be removed. getaddrinfo.c 696
Let's remove the redundant checks:
lwres_freeaddrinfo(struct addrinfo *ai) { struct addrinfo *ai_next; while (ai != NULL) { ai_next = ai->ai_next; free(ai->ai_addr); free(ai->ai_canonname); free(ai); ai = ai_next; } } In my opinion, the code has become much simpler and more beautiful. A great example of refactoring.
In the projects I tested, the analyzer revealed 620 unnecessary checks!

This means that for all projects, the analyzer will issue about 18,600 warnings! Wow! Just imagine, you can safely delete 18600 if statements .
V810: The 'A'
#define TIZEN_USER_CONTENT_PATH tzplatform_getenv(TZ_USER_CONTENT) int _media_content_rollback_path(const char *path, char *replace_path) { .... if (strncmp(path, TIZEN_USER_CONTENT_PATH, strlen(TIZEN_USER_CONTENT_PATH)) == 0) { .... } V810 Decreased performance. The 'tzplatform_getenv (TZ_USER_CONTENT)' function was called. You can’t be saved a variable variable, which can then be used while the strncmp function is called. media_util_private.c 328
The analyzer detects the code in which there is a function call, to which the result of several calls to the same function is passed as actual arguments. Moreover, these used functions are called with the same arguments. If these functions run slowly, then the code can be optimized by placing the result in an intermediate variable.
In the above code, the tzplatform_getenv function is called twice with the same actual argument.
7 . .
V811: Excessive type casting: string -> char * -> string
, . :
std::string A = Foo(); std::string B(A.c_str()); B , , . , A . . , A . :
std::string A = Foo(); std::string B(A); This code is not only faster, but also shorter.
Now let's look at an example of how diagnostics work on the Tizen code
void PasswordUI::changeState(PasswordState state) { .... std::string text = ""; .... switch (m_state) { case PasswordState::ConfirmPassword: text = TabTranslations::instance().ConfirmPassword.c_str(); m_naviframe->setTitle("IDS_BR_HEADER_CONFIRM_PASSWORD_ABB2"); break; .... } PVS-Studio: V811 Decreased performance. Excessive type casting: string -> char * -> string. Consider inspecting the expression. PasswordUI.cpp 242
For the projects I checked, the analyzer issued 41 warnings. This means, it can be expected that the analyzer will detect in the Tizen project 1230 such inefficient copying of strings.
V812: Ineffective use of the 'count' function
For the verified projects, no V812 warnings were issued, so I’ll only briefly explain what it is.
The result of calling the functions count or count_if from the standard library is compared with zero. This can be potentially slow, because these functions need to process the entire container in order to count the number of items needed. If the value returned by the function is compared with zero, then we are wondering if there is at least 1 such element or not at all. Checking that the element is present / absent in the container can be more effectively performed using the find or find_if function .
Ineffective:
void foo(const std::multiset<int> &ms) { if (ms.count(10) != 0) Foo(); } Effectively:
void foo(const std::multiset<int> &ms) { if (ms.find(10) != ms.end()) Foo(); } V813: Constant pointer / reference
An argument representing a structure or class is passed to the function by value. The analyzer, checking the function body, came to the conclusion that this argument is not modified. For the purpose of optimization, such an argument can be passed as a constant reference. This can speed up the execution of the program, since when the function is called, only the address will be copied, not the entire class object.
The V813 diagnostics is similar to the V801, but in this case the variable is not marked as const . This means that the analyzer will have to try to figure out whether the variable in the function is modified or not. If modified, no warning is required. Occasionally there are false positives, but in general, diagnostics work well.
Consider an example of a function detected using this diagnostic.
void addDescriptions(std::vector<std::pair<int, std::string>> toAdd) { if (m_descCount + toAdd.size() > MAX_POLICY_DESCRIPTIONS) { throw std::length_error("Descriptions count would exceed " + std::to_string(MAX_POLICY_DESCRIPTIONS)); } auto addDesc = [] (DescrType **desc, int result, const std::string &name) { (*desc) = static_cast<DescrType *>(malloc(sizeof(DescrType))); (*desc)->result = result; (*desc)->name = strdup(name.data()); }; for (const auto &it : toAdd) { addDesc(m_policyDescs + m_descCount, it.first, it.second); ++m_descCount; } m_policyDescs[m_descCount] = nullptr; } PVS-Studio: V813 Decreased performance. The 'toAdd' argument should probably be rendered as a constant reference. CyadCommandlineDispatcherTest.h 63
std::vector<std::pair<int, std::string>> . , — .
, . :
void addDescriptions( const std::vector<std::pair<int, std::string>> &toAdd) , , . :
void TabService::errorPrint(std::string method) const { int error_code = bp_tab_adaptor_get_errorcode(); BROWSER_LOGE("%s error: %d (%s)", method.c_str(), error_code, tools::capiWebError::tabErrorToString(error_code).c_str()); } PVS-Studio: V813 Decreased performance. The 'method' argument should probably be rendered as a constant reference. TabService.cpp 67
. , -.
303 . , Tizen 9090 . , , .
V814: The 'strlen' function was called multiple times inside the body of a loop
The reader probably already noticed that mostly micro-optimizations are associated with strings. The reason is that most of these diagnostics are developed at the suggestion of one client, for whom efficient work with strings is important. The diagnostics that we are about to consider are no exception and are also related to strings.
The analyzer detects cycles in which the function strlen (S) or similar is called. In this case, the string S does not change, and therefore, its length can be calculated in advance.
Consider a couple of examples of how this diagnostic works. Example 1
#define SETTING_FONT_PRELOAD_FONT_PATH "/usr/share/fonts" static Eina_List *_get_available_font_list() { .... for (j = 0; j < fs->nfont; j++) { FcChar8 *family = NULL; FcChar8 *file = NULL; FcChar8 *lang = NULL; int id = 0; if (FcPatternGetString(fs->fonts[j], FC_FILE, 0, &file) == FcResultMatch) { int preload_path_len = strlen(SETTING_FONT_PRELOAD_FONT_PATH); .... } PVS-Studio: V814 Decreased performance. The 'strlen' function was called multiple times inside the body of a loop. setting-display.c 1185
, "/usr/share/fonts". , . , , , , .
: .
The second example.
static void BN_fromhex(BIGNUM *b, const char *str) { static const char hexdigits[] = "0123456789abcdef"; unsigned char data[512]; unsigned int i; BIGNUM *out; RUNTIME_CHECK(strlen(str) < 1024U && strlen(str) % 2 == 0U); for (i = 0; i < strlen(str); i += 2) { const char *s; unsigned int high, low; s = strchr(hexdigits, tolower((unsigned char)str[i])); RUNTIME_CHECK(s != NULL); high = (unsigned int)(s - hexdigits); s = strchr(hexdigits, tolower((unsigned char)str[i + 1])); RUNTIME_CHECK(s != NULL); low = (unsigned int)(s - hexdigits); data[i/2] = (unsigned char)((high << 4) + low); } out = BN_bin2bn(data, strlen(str)/2, b); RUNTIME_CHECK(out != NULL); } PVS-Studio: V814 Decreased performance. Calls to the 'strlen' function have being made multiple times when a condition for the loop's continuation was calculated. openssldh_link.c 620
:
for (i = 0; i < strlen(str); i += 2) { At each iteration of the loop, the length of the string passed as an argument will be calculated. Perfectionist in shock.
Note . As a rule, such code is written by people who have previously worked with the Pascal language (Delphi environment). In Pascal, the end-of-cycle boundary is calculated once, therefore, there such code is appropriate and common. Details (see chapter “18. Knowledge gained in working with one language is not always applicable to another language”).
By the way, it’s not worth hoping for optimizations by the compiler here either. A pointer to the line came from outside. Yes, inside the function we cannot change the string (it is, after all, const char * ). But this does not mean that it cannot be changed by someone from the outside. Suddenly this string changes, for example, the function strchr . …
, , . Now I will explain.
int value = 1; void Foo() { value = 2; } void Example(const int &A) { printf("%i\n", A); Foo(); printf("%i\n", A); } int main() { Example(value); return 0; } A const int & , 1, 2.
Like this. , const — , , . , .
:
static void BN_fromhex(BIGNUM *b, const char *str) { static const char hexdigits[] = "0123456789abcdef"; unsigned char data[512]; unsigned int i; BIGNUM *out; const size_t strLen = strlen(str); RUNTIME_CHECK(strLen < 1024U && strLen % 2 == 0U); for (i = 0; i < strLen; i += 2) { const char *s; unsigned int high, low; s = strchr(hexdigits, tolower((unsigned char)str[i])); RUNTIME_CHECK(s != NULL); high = (unsigned int)(s - hexdigits); s = strchr(hexdigits, tolower((unsigned char)str[i + 1])); RUNTIME_CHECK(s != NULL); low = (unsigned int)(s - hexdigits); data[i/2] = (unsigned char)((high << 4) + low); } out = BN_bin2bn(data, strLen / 2, b); RUNTIME_CHECK(out != NULL); } 112 strlen , . 3360 .
PVS-Studio ? ! .
V815: Consider replacing the expression 'AA' with 'BB'
, , . , :
void f(const std::string &A, std::string &B) { if (A != "") B = ""; } :
void f(const std::string &A, std::string &B) { if (!A.empty()) B.clear(); } Release- ?
, , Visual C++ (Visual Studio 2015). . , std::basic_string::assign .

Tizen:
services::SharedBookmarkFolder FoldersStorage::getFolder(unsigned int id) { BROWSER_LOGD("[%s:%d] ", __PRETTY_FUNCTION__, __LINE__); std::string name = getFolderName(id); .... if (name != "") folder = std::make_shared<services::BookmarkFolder>( id, name, count); return folder; } PVS-Studio: V815 Decreased performance. Consider replacing the expression 'name != ""' with '!name.empty()'. FoldersStorage.cpp 134
, . :
.... std::string buffer; .... bool GpsNmeaSource::tryParse(string data) { .... buffer = ""; .... } PVS-Studio: V815 Decreased performance. Consider replacing the expression 'buffer = ""' with 'buffer.clear()'. gpsnmea.cpp 709
, . , , , (str == "") . , . - , , , (str == "") Release .
, . , , . , , , .
In total, the PVS-Studio analyzer issued 63 warnings of this type for verified projects. If the developers consider these warnings worthy of attention, then all of them will be around 1890 .
V816: By reference rather than by value
An exception is more efficient to intercept, not by value, but by reference. At the same time, this avoids some other errors. For example, you can avoid the problem of "cutting" (slice). However, this topic is beyond the scope of this diagnostic. To combat the cut-off there is a diagnosis of V746 .
Diagnostic response example:
std::string make_message(const char *fmt, ...) { .... try { p = new char[size]; } catch (std::bad_alloc) { Logger::getInstance().log("Error while allocating memory!!"); return std::string(); } .... } PVS-Studio: V816 LoggerTools.cpp 37
Better to write:
} catch (std::bad_alloc &) { 84 . : 2500 .
V817: It is more efficient to search for 'X' character rather than a string
. , 2 . The first:
void URIEntry::_uri_entry_editing_changed_user(void* data, Evas_Object*, void*) { .... if ((entry.find("http://") == 0) || (entry.find("https://") == 0) || (entry.find(".") != std::string::npos)) { // <= self->setDocIcon(); } else { .... } PVS-Studio: V817 It is more efficient to seek '.' character rather than a string. URIEntry.cpp 211
, . Those. :
|| (entry.find('.') != std::string::npos)) { :
char *_gl_info__detail_title_get( void *data, Evas_Object *obj, const char *part) { .... p = strstr(szSerialNum, ","); .... } PVS-Studio: V817 It is more efficient to seek ',' character rather than a string. setting-info.c 511
strchr :
p = strchr(szSerialNum, ','); PVS-Studio 37 , . Tizen: 1110 .
, , PVS-Studio 6.16 V818, V819, V820. Tizen . , :
- V818 . It is more efficient to use an initialization list rather than an assignment operator.
- V819 . Decreased performance. Memory is allocated and released multiple times inside the loop body.
- V820 . The variable is not used after copying. Copying can be replaced with move/swap for optimization.
Results
, , PVS-Studio, . , - . ( std::string , CString ..). , .
, Tizen .
- V801 — 2280
- V803 — 3000
- V804 — 600
- V805 — 12450
- V806 — 60
- V807 — 2700
- V808 - 900
- V809 - 18600
- V811 - 1230
- V813 - 9090
- V814 - 3360
- V815 - 1890
- V816 - 2500
- V817 - 1110
TOTAL: about 59,000 warnings
I don’t urge to start reading all these warnings and correct the code. I understand that such edits will not improve at least some noticeable performance of the operating system. Moreover, if you make so many edits, there is a high risk of accidentally breaking something by making a typo.
Nevertheless, I find these analyzer warnings useful. Using them wisely allows you to write simpler and more efficient code.
My opinion: it makes no sense to touch the old code. However, it is worthwhile to develop a new code taking into account these diagnostics of micro-optimizations. This article well shows that you can write code a little better in so many places.
Conclusion
We offer to install PVS-Studio and try to check your projects. Under Windows, the demo version will be immediately available to you. To try the Linux version, email us and we will send you a temporary license key.
Thank you all for your attention.
Additional recommended materials
- Andrey Karpov. 27000 errors in the Tizen operating system .
- Sergey Vasiliev. How can PVS-Studio help in finding vulnerabilities?
- Andrey Karpov. We provide the PVS-Studio analyzer to security experts .
- Andrey Karpov. PVS-Studio team: code audit and other services .
- Sergey Khrenov. PVS-Studio as a plugin for SonarQube .
- Catherine Milovidova. Bug of the month: relay race from PC-Lint to PVS-Studio .

If you want to share this article with an English-speaking audience, then please use the link to the translation: Andrey Karpov. Exploring Microoptimizations Using Tizen Code as an Example
Read the article and have a question?
Often our articles are asked the same questions. We collected answers to them here: Answers to questions from readers of articles about PVS-Studio, version 2015 . Please review the list.
Source: https://habr.com/ru/post/333474/
All Articles