Exact calculation of averages and covariances by the Welford method
The Welford method is a simple and efficient way to calculate averages, variances, covariances, and other statistics. This method has a number of excellent properties:
- achieves excellent performance in precision solutions;
- it is extremely easy to remember and implement;
- This is a single-pass online algorithm, which is extremely useful in some situations.
The original article by Welford was published in 1962. Nevertheless, it is impossible to say that the algorithm is somehow widely known at the present time. And to find a mathematical proof of its correctness or experimental comparisons with other methods is not at all trivial.
This article attempts to fill these gaps.

Content
- Introduction
- 1. Errors in the calculation of the average
- 2. Legend
- 3. Calculation of averages
- 4. Calculation of covariances
- 5. Experimental comparison of methods
- Conclusion
Introduction
In the first months of my work as a developer, I was developing a machine learning method in which decision trees with linear regression models in the leaves were subjected to gradient boostering. This algorithm was chosen partly in spite of the fashionable then-winning concept of today to build huge compositions of very simple algorithms: on the contrary, we wanted to build small compositions of rather complex models.
The topic itself turned out to be so interesting for me that I later even wrote a thesis about it. To build a model of several hundred trees, one has to solve a linear regression problem tens of thousands of times, and it turned out to be difficult to achieve good quality in all cases, because the data for these models are very diverse, and the problems of multicollinearity, regularization and computational accuracy rise to full height. But one bad model in one leaf of one tree is enough for the whole composition to be completely unsuitable.
In the process of solving the problems associated with the automatic construction of a huge number of linear models, I managed to find out a number of facts that were useful to me later in a variety of situations, including those not related to the linear regression problem itself. Now I want to talk about some of these facts, and first I decided to talk about the method of Welford.
The article has the following structure. In paragraph 1, we consider the simplest task of computing the average, for example, we understand that this problem is not as simple as it seems at first glance. Paragraph 2 introduces the notation used in this article, which will be useful in sections 3 and 4 , devoted to the derivation of the Welford method formulas for, respectively, the calculation of weighted averages and weighted covariances. If you are not interested in the technical details of formulas output, you can skip these sections. Paragraph 5 contains the results of an experimental comparison of methods, and in conclusion is an example of the implementation of algorithms in C ++.
The model code for comparing methods for calculating the covariance is in my github project . A more complex code, in which the Welford method is used to solve a linear regression problem, is in another project , which will be discussed in the following articles.
1. Errors in the calculation of the average
I'll start with a classic example. Let there be a simple class that calculates the average for a set of numbers:
class TDummyMeanCalculator { private: float SumValues = 0.; size_t CountValues = 0; public: void Add(const float value) { ++CountValues; SumValues += value; } double Mean() const { return CountValues ? SumValues / CountValues : 0.; } }; Let's try to put it into practice in the following way:
int main() { size_t n; while (std::cin >> n) { TDummyMeanCalculator meanCalculator; for (size_t i = 0; i < n; ++i) { meanCalculator.Add(1e-3); } std::cout << meanCalculator.Mean() << std::endl; } return 0; } What will the program output?
| Input | Conclusion |
|---|---|
| 10,000 | 0.001000040 |
| 1,000,000 | 0.000991142 |
| 100,000,000 | 0.000327680 |
| 20,000,000 | 0.000163840 |
| 300000000 | 0.000109227 |
Starting from a certain moment, the sum ceases to change after the addition of the next term: this happens when SumValues is equal to 32768, since to represent the result of the summation to the type float simply not enough bit.
There are several ways out of this situation:
- Jump from
floattodouble. - Use one of the more complex summation methods .
- Use the Kahan method for summation.
- Finally, you can use the Welford method to directly calculate the average.
It is not so easy to find data on which a solution using a double doesn't work well. However, such data is found, especially in more complex tasks. It is also frustrating that using double increases memory costs: sometimes you need to store a large number of averages at the same time.
Kahan’s methods and other complex summation methods are good in their own way, but in the future we will see that the Welford method still works better, and, besides, it is surprisingly simple to implement. Indeed, let's look at the corresponding code:
class TWelfordMeanCalculator { private: float MeanValues = 0.; size_t CountValues = 0; public: void Add(const float value) { ++CountValues; MeanValues += (value - MeanValues) / CountValues; } double Mean() const { return MeanValues; } }; On the question of the correctness of this code, we will return in the future. In the meantime, we note that the implementation looks quite simple, but on those data that are used in our program, it also works with perfect accuracy. This is due to the fact that the difference value - MeanValues at the first iteration is exactly equal to the average, and at subsequent iterations is equal to zero.
This example illustrates the main advantage of the Welford method: all quantities involved in arithmetic operations are “comparable” in magnitude, which, as is well known, contributes to good accuracy of calculations.
| Input | Conclusion |
|---|---|
| 10,000 | 0.001 |
| 1,000,000 | 0.001 |
| 100,000,000 | 0.001 |
| 20,000,000 | 0.001 |
| 300000000 | 0.001 |
In this article we will consider the application of the Welford method to another problem - the problem of calculating covariance. In addition, we will compare various algorithms and obtain mathematical proofs of the correctness of the method.
2. Legend
The derivation of a formula can often be made very simple and straightforward if you choose the correct notation. We will try and we. We assume that two sequences of real numbers are given: x and y and the sequence of their respective weights w :
x=x1,x2,...,xn,...
y=y1,y2,...,yn,...
w=w1,w2,...,wn,...
Since we want to calculate averages and covariances, we will need notation for weighted sums and sums of products. We will try to describe them in the same way:
Sa,b,...,zn= sumni=1ai cdotbi cdot... cdotzi
Then, for example, Swn Is the sum of the weights of the first n elements Swxn - this is a weighted sum of the first n the numbers of the first sequence, and Swxyn - the sum of weighted products:
Swn= sumni=1wi
Swxn= sumni=1wi cdotxi
Swxyn= sumni=1wi cdotxi cdotyi
We also need average weights:
mwxn= frac sumni=1wi cdotxi sumni=1wi= fracSwxnSwn
mwyn= frac sumni=1wi cdotyi sumni=1wi= fracSwynSwn
Finally, we introduce the notation for non-normalized "scatter" Dwxyn and normalized covariances Cwxyn :
D_ {n} ^ {wxy} = \ sum_ i = 1} ^ {n} w_i (x_i - m_ {n} ^ {wx}) (y_i - m_ {n} ^ {wy})
Cwxyn= fracDwxynSwn= frac sumni=1wi(xi−mwxn)(yi−mwyn) sumni=1wi
3. Calculation of averages
Let us prove a weighted analogue of the formula we used above to calculate the average by the Welford method. Consider the difference mwxn+1−mwxn :
mwxn+1−mwxn= fracSwxn+1Swn+1− fracSwxnSwn= fracSwnSwxn+1−SwxnSwn+1Swn+1Swn=
= fracSwnSwxn+wn+1xn+1Swn−SwxnSwn−wn+1SwxnSwn+1Swn= fracwn+1xn+1Swn−wn+1SwxnSwn+1Swn
= fracwn+1Swn+1 Big(xn+1− fracSwxnSwn Big)= fracwn+1Swn+1(xn+1−mwxn)
In particular, if all weights are equal to one, we get that
mwxn+1=mwxn+ fracxn+1−mwxnn+1
By the way, formulas for the "weighted" case make it easy to implement operations that are different from adding exactly one successive number. For example, deleting the number x out of the set for which the average is calculated is the same as adding a number −x with weight −1 . Adding several numbers at once is the same as adding one of the average with a weight equal to the number of these numbers, and so on.
4. Calculation of covariances
We show that the classical formula for calculating the covariance is true for the weighted problem. For simplicity, we will now work with unrated values.
Dwxyn= sumni=1wi(xi−mwxn)(yi−mwyn)=Swxyn−mwxnSwyn−Swxnmwyn+Swnmwxnmwyn
From here it is easy to see that
Dwxyn=Swxyn− fracSwxnSwynSwn
This formula is extremely convenient, including for the online algorithm, however, if the values Swxyn and SwxnSwyn/Swn will be close and at the same time large in absolute value, its use will lead to significant computational errors.
Let's try to derive a recurrent formula for Dwxyn , in a sense, a similar formula of Welford for the medium. So:
Dwxyn+1=Swxyn+wn+1xn+1yn+1−wn+1xn+1 fracSwyn+1Swn+1− fracSwxnSwyn+1Swn+1=
=Swxyn+wn+1xn+1(yn+1−mwyn+1)− fracSwxnSwyn+1Swn+1
Consider the last term:
fracSwxnSwyn+1Swn+1= Big( frac1Swn− fracwn+1SwnSwn+1 Big)SwxnSwyn+1= fracSwxnSwyn+1Swn−wn+1mwxnmwyn+1=
= fracSwxnSwynSwn+wn+1yn+1 fracSwxnSwn−wn+1mwxnmwyn+1= fracSwxnSwynSwn+wn+1mwxn cdot(yn+1−mwyn+1)
Substitute the resulting expression for Dwxyn+1 :
Dwxyn+1=Swxyn+wn+1xn+1(yn+1−mwyn+1)− fracSwxnSwynSwn−wn+1mwxn cdot(yn+1−mwyn+1)=
= Big[Swxyn− fracSwxnSwynSwn Big]+wn+1(xn+1−mwxn)(yn+1−mwyn+1)=
=Dwxyn+wn+1(xn+1−mwxn)(yn+1−mwyn+1)
The code that implements the calculations using this formula, in the absence of weights, looks very simple. It is necessary to update two average values, and also the sum of works:
double WelfordCovariation(const std::vector<double>& x, const std::vector<double>& y) { double sumProducts = 0.; double xMean = 0.; double yMean = 0.; for (size_t i = 0; i < x.size(); ++i) { xMean += (x[i] - xMean) / (i + 1); sumProducts += (x[i] - xMean) * (y[i] - yMean); yMean += (y[i] - yMean) / (i + 1); } return sumProducts / x.size(); } Also interesting is the question of updating the value of the actual covariance, i.e. normalized value:
Cwxyn+1= frac sumn+1i=1wi(xi−mwxn+1)(yi−mwyn+1) sumn+1i=1wi= fracDwxyn+1Swn+1=
= frac1Swn+1 cdot Big(Dwxyn+wn+1(xn+1−mwxn))(yn+1−mwyn+1) Big)=
= fracDwxynSwn+1+ fracwn+1Swn+1(xn+1−mwxn)(yn+1−mwyn+1)
Consider the first term:
fracDwxynSwn+1= Big( frac1Swn− fracwn+1Swn+1Swn Big)Dwxyn= fracDwxynSwn Big(1− fracwn+1Swn+1 Big)=Cwxyn Big(1− fracwn+1Swn+1 Big)
Back now to the review Cwxyn+1 :
Cwxyn+1=Cwxyn Big(1− fracwn+1Swn+1 Big)+ fracwn+1Swn+1(xn+1−mwxn)(yn+1−mwyn+1)
This can be rewritten, for example, as follows:
Cwxyn+1=Cwxyn+ fracwn+1Swn+1 Big((xn+1−mwxn)(yn+1−mwyn+1)−Cwxyn Big)
It turned out a formula that really has an amazing similarity with the formula for updating the average!
5. Experimental comparison of methods
I wrote a small program that implements three ways to calculate the covariance:
- "Standard" algorithm that directly calculates values Swxyn , Swxn and Swyn .
- Algorithm using the Kahan method.
- Algorithm using the method of Welford.
The data in the task are formed as follows: two numbers are selected, mx and my - average of two samples. Then two more numbers are selected, dx and dy - accordingly, deviations. The input algorithms are given a sequence of numbers of the form
xi=mx pmdx,
yi=my pmdy,
moreover, the signs of deviations change at each iteration, so that the true covariance is calculated as follows:
Cxyn= frac sumni=1(xi−mx)(yi−my)n=dx cdotdy
The true covariance is constant and does not depend on the number of terms, so we can calculate the relative error of calculation for each method at each iteration. So, in the current implementation dx=dy=1 , and averages take values of 100000 and 1000000.
The first graph shows the dependence of the relative error when using the naive method for an average of 100 thousand. This graph demonstrates the inconsistency of the naive method: starting from a certain moment, the error begins to grow rapidly, reaching completely unacceptable values. On the same data methods Kahana and Welford do not allow significant errors.

The second graph is constructed for the Kahan method with an average of one million. The error does not grow with an increase in the number of terms, but although it is significantly lower than the error of the "naive" method, it is still too large for practical applications.
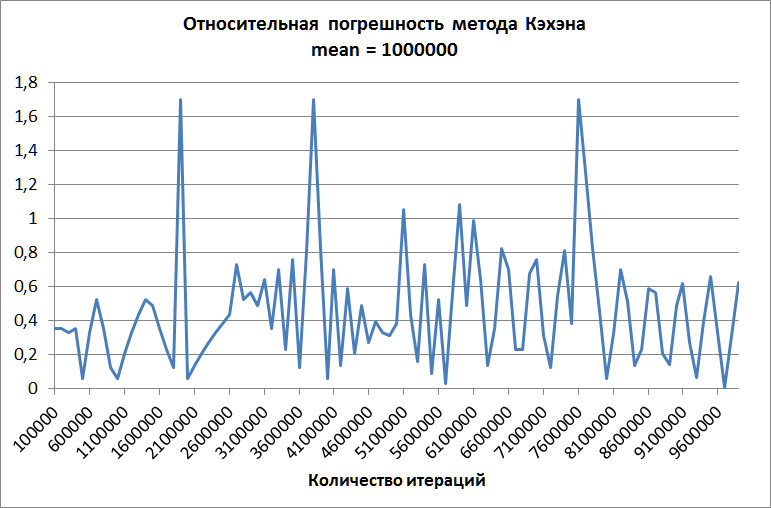
Welford's method, in turn, and on this data demonstrates perfect accuracy!
Conclusion
In this article, we compared several ways to calculate the covariance and made sure that the Welford method gives the best results. In order to use it in practice, it suffices to remember only the following two implementations:
class TWelfordMeanCalculator { private: double Mean = 0.; size_t Count = 0; public: void Add(const float value) { ++Count; Mean += (value - Mean) / Count; } double GetMean() const { return Mean; } }; class TWelfordCovariationCalculator { private: size_t Count = 0; double MeanX = 0.; double MeanY = 0.; double SumProducts = 0.; public: void Add(const double x, const double y) { ++Count; MeanX += (x - MeanX) / Count; SumProducts += (x - MeanX) * (y - MeanY); MeanY += (y - MeanY) / Count; } double Covariation() const { return SumProducts / Count; } }; The use of these methods can save a lot of time and effort in situations where the data is arranged rather "unsuccessfully." You may encounter problems with the accuracy of calculations in arbitrarily unexpected situations, even with the implementation of the one-dimensional kMeans algorithm.
In the next article, we will consider the application of the considered methods in the problem of restoring linear regression, let's talk about the speed of calculations and how the common implementations of machine learning methods deal with "bad" data.
Literature
- github.com: Different covariation calculation methods
- machinelearning.ru: The addition of a large set of numbers that differ significantly in size
- ru.wikipedia.org: Kahan Algorithm
- en.wikipedia.org: Algorithms for calculating variance: Online algorithm
')
Source: https://habr.com/ru/post/333426/
All Articles