Hacking Clocktower - The First Fear
Let's take a great Japanese game in the genre of survival horror, let's figure out how it works, translate it into English and do something else with it.
ClockTower (known in Japan as Clocktower - The First Fear) is a game originally released by Human Entertainment for Super Nintendo.

')
This is one of the games of the “point and click adventure” genre, but it also became one of the founders of the survival horror genre. The plot lies in the fact that four orphans after the closure of the orphanage fell into a mansion, in which one after another began to disappear. The player controls one of the orphans, Jennifer, and tries to find a way out, his friends and find out what happens in the mansion.
The atmosphere of the game is harsh, the events in the house happen by chance, for no apparent reason (in other words, the house is enchanted), sometimes something can kill you just like that, a psychopath with garden shears pursues you throughout the house not the first such character):

In the game, there are often dangerous situations that require quick thinking, the only salvation is to survive, escape and hide, but it is also important to preserve the mind of Jennifer, otherwise she may fall and die from a heart attack (in the style of the game Illbleed).
The game was released in 1994 on SNES, re-released with expanded content on PSX in 1997, released on the Wonderswan console (but no one cares about Wonderswan), and finally released on the PC (and then re-released for the PC in 1999).
Yes, for the ROM under the SNES group Aeon Genesis, an English translation was released (it seems they were), but the version for SNES is worse than the version for PC, which had a much better sound, there is an introductory FMV movie, etc. Perhaps the only version with more content was the version on PSX, but we'll talk about it later.
To begin, let's “wean” the game from the CD!
We have a game folder that looks like this:
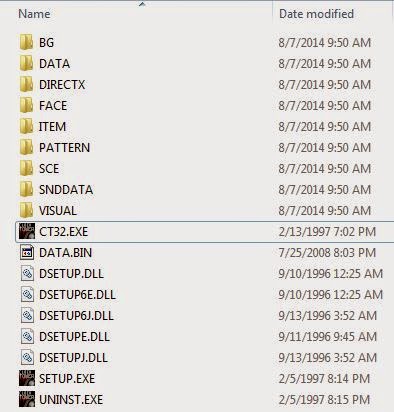
We have a BG folder, inside of which there is something similar to the backgrounds of the rooms in a split format with the accompanying .MAP files, which, I suppose, places different fragments on the screen:

We have a DATA folder containing PTN and PYX files ... I don’t know yet what it is ... maybe they are linking level screens with logic, or something like that.
There is also a folder FACE, which contains bmp with the faces of people used in the dialogues:

There is also a folder with items that Jennifer can use:

The PATTERN folder contains ABM files. I think they are used for sprite animations, but I could be wrong.
There are two files in the SCE folder: CT.ADO and CT.ADT. We will consider them - these are logical action scripts that occur throughout the game, written in our own binary scripting language ... and we will spend most of our time on them.
The SNDDATA folder contains MIDI and WAV music files and sound effects.
The VISUAL folder contains all the high resolution renders, menu options, etc. in BMP format. An intro video is also stored here.

Finally, we have the DATA.BIN file, which ... I don’t know yet what it is doing. In addition, there is an executable file of the game ct32.exe.
Running the game without a CD, we get the following message:
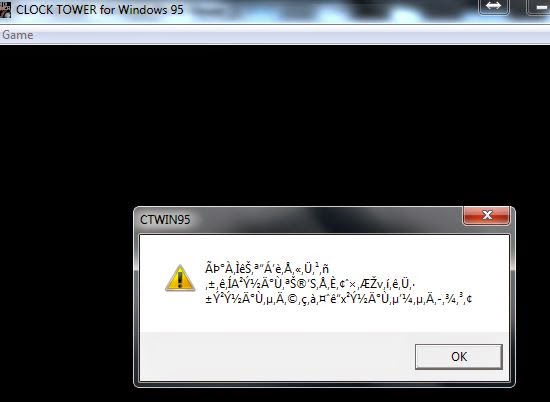
Run the game in the debugger to find this line. It turns out that she simply reports that the game does not know where the game data is located (i.e. no CD is inserted).
Looking at IDA, we see that RegQueryValueEx is being used, that is, the registry value is being read. What does the game get from there?
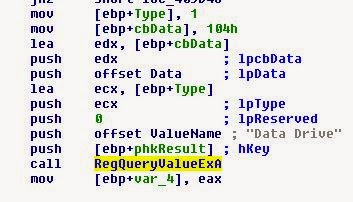
Well ... I guess that's the answer.
AT STOP.
Let's check what causes it, maybe we can set it hard in the code:
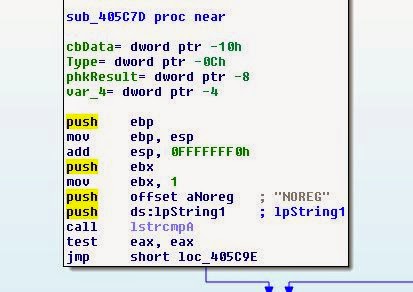
It seems that the extra work was not in vain! The game is looking for an argument NOREG. If she does not find it, then checks the registry value, skips the check, and starts the game, assuming it is in the parent directory. Here a simple patch will help us, which will make the game think that it always starts with the argument NOREG. To do this, replace jz with 0xEB (or unconditional JMP).
Run and get:
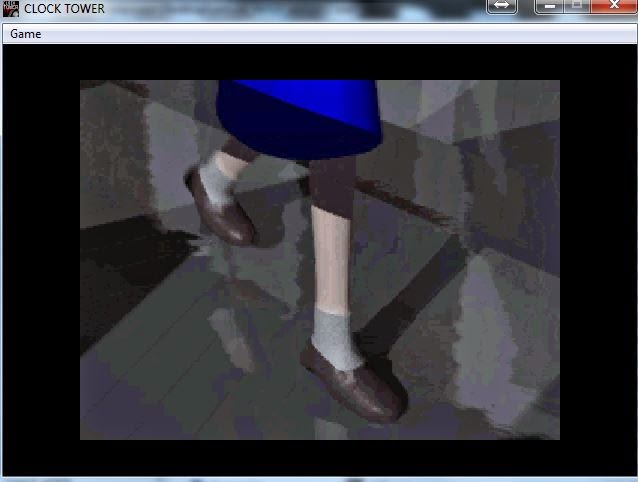
YES!
We will think a little - can we expect that all the text is in an executable file? Well, it is possible, in many games it happens. There are even a few static lines in binary files (for example, an error about the absence of a CD that we found), but I have a feeling that the texts are hidden somewhere else (maybe in DATA files?). Let's get a look:
Japanese text using the SHIFT-JIS format (very popular) usually starts with a control character in the range 0x80-0x8F ... It would be nice to start by looking for something like this in an executable file.
Then we copy these lines into a new file and open it in notepad ++, and then paste it into Google Translate:
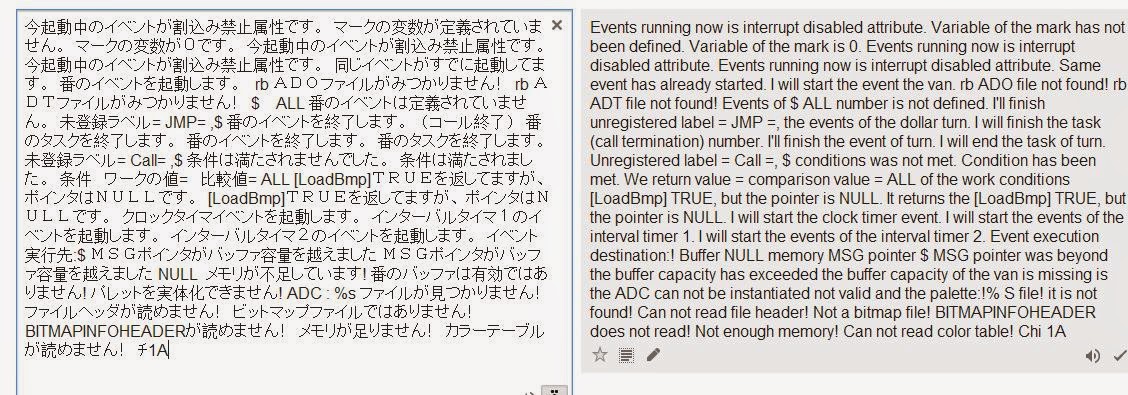
So, this is reminiscent of error messages, not game dialogs. It's time to look for other files!
Hmm, I see - there are no texts in the PTN and PYX files. Let's check the SCE folder.
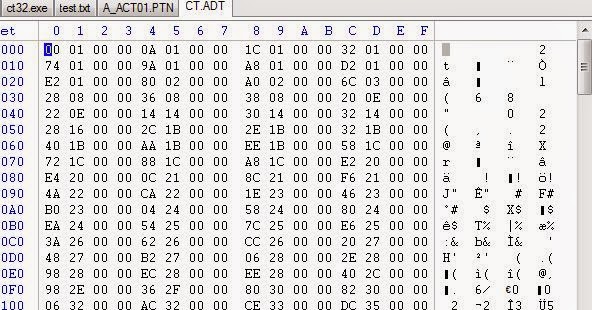
It looks like there are four-byte offsets in the CT.ADT file (they run up to the end of the file from 0x100, 4 bytes at a time).
But in the file CT.ADO ...


We found something ... here, not only ASCII strings, similar to file paths, but also text strings in SHIFT-JIS format. The data in this file looks weird ... let's see if we can figure it out better. We have to, if we want to parse them.
We already understand a little bit how ADT works, so let's see how ADO looks like:
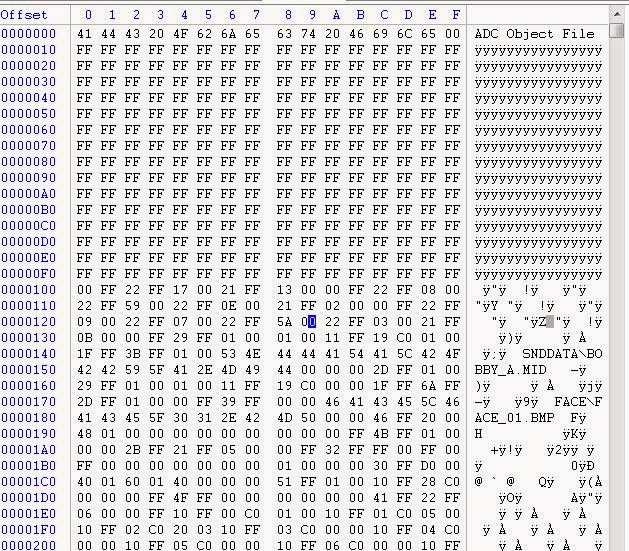
Magic begins at the very top (ADC Object File), because a bunch of 0xFF to offset by 256, then it looks like the data starts. It is time to think like a real computer scientist!
We have all these strings, a binary format with no obvious search, except possibly the ADT file. Inside there should be a control code intermingled with the data, which makes the game understand what it sees when parsing ... all this has some kind of structure.
Studying strings with .BMP, you can see that they have the same pattern:
39FF is followed by a zero two-byte value (most often, but sometimes it is 0x0100, so I think this is a value in WORD), then an ASCII string ending in a zero value, and an indent. In fact, with each BMP boot for FACE, the value of 0xFF39 is in front of it!
Let's check the executable file:
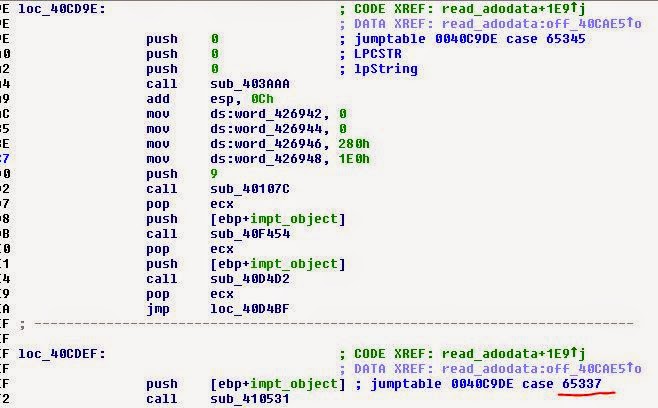
Great! We have not only this, but also other meanings. Let's check a few lines of Shift-JIS to see if we can find a pattern:

Fine! All lines start with 0xFF33, have two 16-bit values (0x0F00), followed by a line in Shift-JIS.
Note: you may notice that SHIFT-JIS is NOT terminated with a zero value, this is not possible. Some programs can handle both single-byte and multibyte character values, but in older programs this was a serious problem. As a result, as you can see, all line breaks (0x0a) are followed by 0x00. Actually behind ALL ASCII characters here goes 0x00 (and numbers or English letters). Thus, text rendering may support multi-byte interpretation of ASCII characters (0-127) and not be confused when reading data bytes with a control byte, and vice versa.
Therefore, we conclude that the logic of the game should parse the string until it somehow detects an end (possibly finding a new opcode (usually 0x28FF).
So, as we know, the ADO file is full of script opcodes and the data following them. It can theoretically be assumed that the game reads them and, based on the previous opcode, knows what data to expect. Now we can look at the switch construction in the executable file that we found above (with all cases) to select all opcodes used in the game (for a more complete understanding of the format).
We will notice the values (0xFF20, 0xFF87) and look for them in the ADO file, determining whether they have the same number of bytes of data before the next opcode. Let's try to find out if they are double-byte values, strings, and so on.
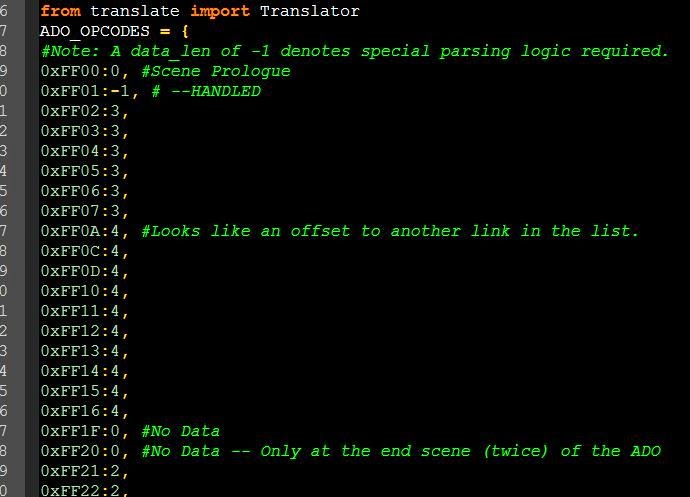
In addition, you can notice that there is a rather interesting text in the executable file:
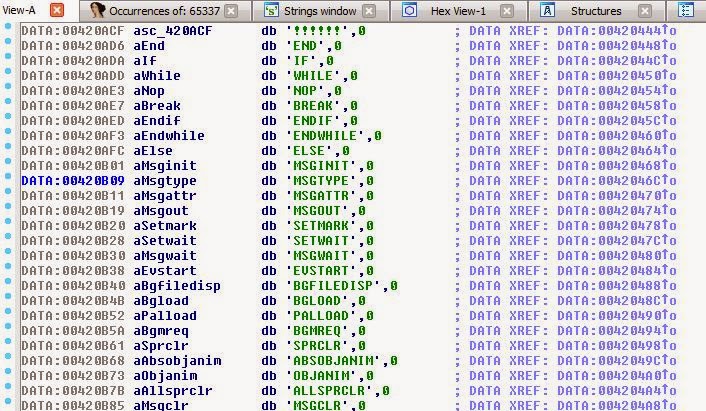
In fact, this is a list, and it looks suspiciously like opcode names. Fortunately for us, it is! Now we know the names of opcodes.
At this stage, we can start the game with a debugger and interrupt the execution on constructions in order to observe the actions of different opcodes. One of our interests is JMP ...
In fact, after the first JMP (0xFF22) there is a two-byte value 0x17.
If you watch it in the game and set it in IDA as the observed variable ADO_offset, then you can see that the game goes from this value to 0x1B32. How does she know she needs to do this? This is not a multiplier ... probably:

Aha
0x17 * 4 = 0x5C, that is, ADT is a transition table for different scenes. You will notice that the CALL function (0xFF23) works in a similar way, but after some time it returns to this offset ... The first few ADT offsets indicate 0xFF00. It seems to be very important in the game, the transitions actually skip them (they add +2 to the offset after the transition). Is it something like opcode RETN? I think yes.
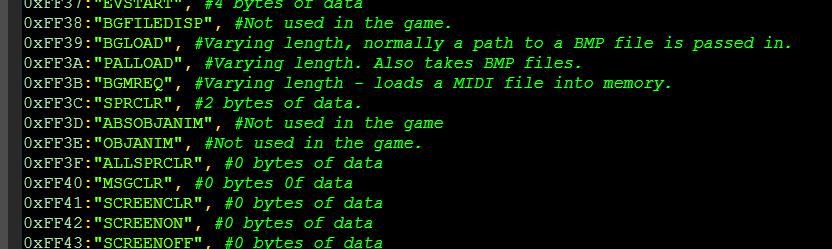
However, you will notice that the ADT file contains different values at the end, much larger than the size of the ADO file. What do they give? We will deal with this, but first we will take a closer look at the process of playing the game in order to understand how these transitions work (paying particular attention to them).
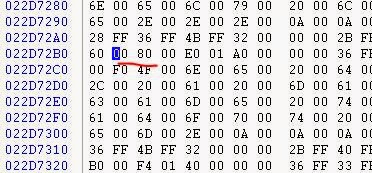
Having made a memory dump, you will notice that the ADC in-memory object file (CT.ADO) is 0x8000 int16, written in every 0x8000, or 32 KB. In addition, ADO is not changed. You can also notice in the executable file that the function parses the value and skips two bytes if it sees this value (as NOP).
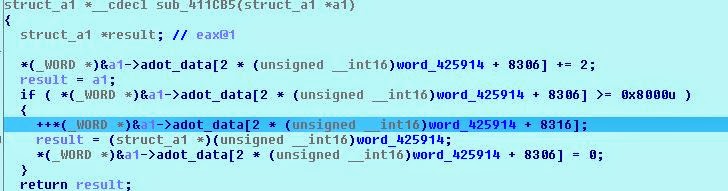
Since the game divides data into 32 KB fragments (most likely, to more segmented access to memory; we often met with double-byte values, this is important), then for ADT there must be some kind of address translation (because ADT uses to address offset 4 bytes).

There is quite a lot of mathematics here, which, if you observed in the debugger, will resemble something like this:
At first I did not find the function and reached the end of the ADT file, assuming that there is a pointer to the end of the ADO file (the last RETN has an offset of 0x253F4). In the ADT list, it is listed as 0x453F4. Looking for various other addresses, I noticed that the translation takes two significant bytes, divides them in half and inserts it back into the end.
Not bad, now we can generate ADT files (inverse operation: multiplying the most significant, depending on how many 0x8000 intervals we passed). We also have a general scheme of opcodes and we know where the lines are. Before we start disassembling, let's look at the reward and make every effort (first translation).
We know in what format the lines are stored and how to read them from the ADO file. Of course, inserting them back will require changing the ADT offsets, because the row sizes can be much larger or smaller. To begin, consider cutting ADO lines into a text file, into something very easily editable, which can then be considered another program. Create a format in which we can easily insert lines into the new ADO file and conveniently change the offsets. What do we need for this?
So, it is important for us the offset at which the line begins, the size of the source line in bytes, then the line itself, something like:
Writing cttd.py:
I renamed CT.ADO to CT_J.ADO to later generate a new file.
This program reads the ADO file, finds 0xFF33, skips 6 bytes (to bypass the opcode and two two-byte values), and then writes the initial offset of the line, the length of the line and the line itself into a new line in the new file in the new file.
You will notice that I replace all the values 0x0a (new line) with [NEWLINE]. I do this because I want the entire line to be processed on one line and I can define new lines where I want without changing the format of the text file.
For fun, let's do something stupid: we will parse this text with the help of translator. This is a Python module that loads data into Google Translate, automatically recognizes the language, translates and returns the text in the desired language:
cttt.py:
Now, let's try a couple of lines with an injector - the last program in this package parses the text file, adds a strike with zeros to all ASCII characters in the lines, reads lines into the dictionary, so that we know which offsets are involved. In addition, it recreates ADO from scratch (it reads ADT, loads all the “scenes” into the array with their offsets, copies all the data between the lines and after them), and then re-generates the ADT based on the size of the “scenes” ADO:
ctti.py:
Check how it works:

Fine!
English will be pretty awful, fortunately, I found an rtf file with translation on the Clocktower fan forum and was able to manually edit the lines based on rough translations.

Everything is translated and ready to go! Let's run:

Hell!
Something is wrong, let's drop the file in IDA and see what happens:

It looks like we are reading the ADO file into memory, but it is trying to use a pointer and cannot because there is nothing in this place.
Observe the struct a1 and the malloc it runs, probably the problem. Having rummaged a little longer, we find out that these pointers are created here:

That is, the game (based on the cmp5 opcode) creates pointers only for ADO 5 * 0x8000 fragments, but reads ADO data to EOF (this is definitely an error). As a result, we can upload an ADO file of no more than 0x28000 size. Will it stop us? Of course not! Let's take a closer look at the structure of SCE in memory ...
We can change all the cases of loading ADO pointers from 5 to 6 to add one more point, but what will happen after this last pointer? Of course, ADT offsets will begin.

We see that the offset ADT 0x00 is at struct_head + 0x2A and goes to 0x7D0 ... seriously? Pointers to 0x7D0 ??? Wait, it looks like a 0x8000.
As a result, we only have 0x4800 bytes for the ADT file. We can say that by lowering the ADT index to, say, 0x2E, we get four times more bytes to write another ADO pointer and we still have a lot of free space at the end!
Find the struct references on 0x2A and change them to 0x2E too:

Yes! I love object-oriented reverse engineering.
Great, now the game is fully translated. What's next?
We need to make binary changes to CT32.exe using a hex editor:
The next logical step is to disassemble all other opcodes to create a text file that will be read in the game / editor.
Something like this:
Then, of course, we will need to shove it all back into the ADO / ADT pair.
The PSX version of the game also uses ADO / ADT. Looks like we can convert resources and add exclusive PSX content to the PC version.
Introduction
ClockTower (known in Japan as Clocktower - The First Fear) is a game originally released by Human Entertainment for Super Nintendo.
')
This is one of the games of the “point and click adventure” genre, but it also became one of the founders of the survival horror genre. The plot lies in the fact that four orphans after the closure of the orphanage fell into a mansion, in which one after another began to disappear. The player controls one of the orphans, Jennifer, and tries to find a way out, his friends and find out what happens in the mansion.
The atmosphere of the game is harsh, the events in the house happen by chance, for no apparent reason (in other words, the house is enchanted), sometimes something can kill you just like that, a psychopath with garden shears pursues you throughout the house not the first such character):
In the game, there are often dangerous situations that require quick thinking, the only salvation is to survive, escape and hide, but it is also important to preserve the mind of Jennifer, otherwise she may fall and die from a heart attack (in the style of the game Illbleed).
The game was released in 1994 on SNES, re-released with expanded content on PSX in 1997, released on the Wonderswan console (but no one cares about Wonderswan), and finally released on the PC (and then re-released for the PC in 1999).
Yes, for the ROM under the SNES group Aeon Genesis, an English translation was released (it seems they were), but the version for SNES is worse than the version for PC, which had a much better sound, there is an introductory FMV movie, etc. Perhaps the only version with more content was the version on PSX, but we'll talk about it later.
To begin, let's “wean” the game from the CD!
Part 1 - Research
We have a game folder that looks like this:
We have a BG folder, inside of which there is something similar to the backgrounds of the rooms in a split format with the accompanying .MAP files, which, I suppose, places different fragments on the screen:
We have a DATA folder containing PTN and PYX files ... I don’t know yet what it is ... maybe they are linking level screens with logic, or something like that.
There is also a folder FACE, which contains bmp with the faces of people used in the dialogues:
There is also a folder with items that Jennifer can use:
The PATTERN folder contains ABM files. I think they are used for sprite animations, but I could be wrong.
There are two files in the SCE folder: CT.ADO and CT.ADT. We will consider them - these are logical action scripts that occur throughout the game, written in our own binary scripting language ... and we will spend most of our time on them.
The SNDDATA folder contains MIDI and WAV music files and sound effects.
The VISUAL folder contains all the high resolution renders, menu options, etc. in BMP format. An intro video is also stored here.
Finally, we have the DATA.BIN file, which ... I don’t know yet what it is doing. In addition, there is an executable file of the game ct32.exe.
Running the game without a CD, we get the following message:
Run the game in the debugger to find this line. It turns out that she simply reports that the game does not know where the game data is located (i.e. no CD is inserted).
Part 2 - Creating a NoCD
Looking at IDA, we see that RegQueryValueEx is being used, that is, the registry value is being read. What does the game get from there?
Well ... I guess that's the answer.
AT STOP.
Let's check what causes it, maybe we can set it hard in the code:
It seems that the extra work was not in vain! The game is looking for an argument NOREG. If she does not find it, then checks the registry value, skips the check, and starts the game, assuming it is in the parent directory. Here a simple patch will help us, which will make the game think that it always starts with the argument NOREG. To do this, replace jz with 0xEB (or unconditional JMP).
Run and get:
YES!
Part 3 - We are looking for in-game text
We will think a little - can we expect that all the text is in an executable file? Well, it is possible, in many games it happens. There are even a few static lines in binary files (for example, an error about the absence of a CD that we found), but I have a feeling that the texts are hidden somewhere else (maybe in DATA files?). Let's get a look:
Japanese text using the SHIFT-JIS format (very popular) usually starts with a control character in the range 0x80-0x8F ... It would be nice to start by looking for something like this in an executable file.
Then we copy these lines into a new file and open it in notepad ++, and then paste it into Google Translate:
So, this is reminiscent of error messages, not game dialogs. It's time to look for other files!
Hmm, I see - there are no texts in the PTN and PYX files. Let's check the SCE folder.
It looks like there are four-byte offsets in the CT.ADT file (they run up to the end of the file from 0x100, 4 bytes at a time).
But in the file CT.ADO ...
We found something ... here, not only ASCII strings, similar to file paths, but also text strings in SHIFT-JIS format. The data in this file looks weird ... let's see if we can figure it out better. We have to, if we want to parse them.
Part 4 - Dive into ADO / ADT
We already understand a little bit how ADT works, so let's see how ADO looks like:
Magic begins at the very top (ADC Object File), because a bunch of 0xFF to offset by 256, then it looks like the data starts. It is time to think like a real computer scientist!
We have all these strings, a binary format with no obvious search, except possibly the ADT file. Inside there should be a control code intermingled with the data, which makes the game understand what it sees when parsing ... all this has some kind of structure.
Studying strings with .BMP, you can see that they have the same pattern:
39FF is followed by a zero two-byte value (most often, but sometimes it is 0x0100, so I think this is a value in WORD), then an ASCII string ending in a zero value, and an indent. In fact, with each BMP boot for FACE, the value of 0xFF39 is in front of it!
Let's check the executable file:
Great! We have not only this, but also other meanings. Let's check a few lines of Shift-JIS to see if we can find a pattern:
Fine! All lines start with 0xFF33, have two 16-bit values (0x0F00), followed by a line in Shift-JIS.
Note: you may notice that SHIFT-JIS is NOT terminated with a zero value, this is not possible. Some programs can handle both single-byte and multibyte character values, but in older programs this was a serious problem. As a result, as you can see, all line breaks (0x0a) are followed by 0x00. Actually behind ALL ASCII characters here goes 0x00 (and numbers or English letters). Thus, text rendering may support multi-byte interpretation of ASCII characters (0-127) and not be confused when reading data bytes with a control byte, and vice versa.
Therefore, we conclude that the logic of the game should parse the string until it somehow detects an end (possibly finding a new opcode (usually 0x28FF).
So, as we know, the ADO file is full of script opcodes and the data following them. It can theoretically be assumed that the game reads them and, based on the previous opcode, knows what data to expect. Now we can look at the switch construction in the executable file that we found above (with all cases) to select all opcodes used in the game (for a more complete understanding of the format).
We will notice the values (0xFF20, 0xFF87) and look for them in the ADO file, determining whether they have the same number of bytes of data before the next opcode. Let's try to find out if they are double-byte values, strings, and so on.
In addition, you can notice that there is a rather interesting text in the executable file:
In fact, this is a list, and it looks suspiciously like opcode names. Fortunately for us, it is! Now we know the names of opcodes.
At this stage, we can start the game with a debugger and interrupt the execution on constructions in order to observe the actions of different opcodes. One of our interests is JMP ...
In fact, after the first JMP (0xFF22) there is a two-byte value 0x17.
If you watch it in the game and set it in IDA as the observed variable ADO_offset, then you can see that the game goes from this value to 0x1B32. How does she know she needs to do this? This is not a multiplier ... probably:
Aha
0x17 * 4 = 0x5C, that is, ADT is a transition table for different scenes. You will notice that the CALL function (0xFF23) works in a similar way, but after some time it returns to this offset ... The first few ADT offsets indicate 0xFF00. It seems to be very important in the game, the transitions actually skip them (they add +2 to the offset after the transition). Is it something like opcode RETN? I think yes.
However, you will notice that the ADT file contains different values at the end, much larger than the size of the ADO file. What do they give? We will deal with this, but first we will take a closer look at the process of playing the game in order to understand how these transitions work (paying particular attention to them).
Having made a memory dump, you will notice that the ADC in-memory object file (CT.ADO) is 0x8000 int16, written in every 0x8000, or 32 KB. In addition, ADO is not changed. You can also notice in the executable file that the function parses the value and skips two bytes if it sees this value (as NOP).
Since the game divides data into 32 KB fragments (most likely, to more segmented access to memory; we often met with double-byte values, this is important), then for ADT there must be some kind of address translation (because ADT uses to address offset 4 bytes).
There is quite a lot of mathematics here, which, if you observed in the debugger, will resemble something like this:
At first I did not find the function and reached the end of the ADT file, assuming that there is a pointer to the end of the ADO file (the last RETN has an offset of 0x253F4). In the ADT list, it is listed as 0x453F4. Looking for various other addresses, I noticed that the translation takes two significant bytes, divides them in half and inserts it back into the end.
Not bad, now we can generate ADT files (inverse operation: multiplying the most significant, depending on how many 0x8000 intervals we passed). We also have a general scheme of opcodes and we know where the lines are. Before we start disassembling, let's look at the reward and make every effort (first translation).
Part 4: CTTDTI Turn
We know in what format the lines are stored and how to read them from the ADO file. Of course, inserting them back will require changing the ADT offsets, because the row sizes can be much larger or smaller. To begin, consider cutting ADO lines into a text file, into something very easily editable, which can then be considered another program. Create a format in which we can easily insert lines into the new ADO file and conveniently change the offsets. What do we need for this?
So, it is important for us the offset at which the line begins, the size of the source line in bytes, then the line itself, something like:
0xE92 25 blahblahblah Writing cttd.py:
''' CTD - Clocktower Text Dumper by rFx ''' import os,sys,struct,binascii f = open("CT_J.ADO","rb") data = f.read() f.close() g = open("ct_txt.txt","wb") for i in range(0,len(data)-1): if(data[i] == '\x33' and data[i+1] == '\xff'): # 6 - , . i+=6 str_offset = i str_end = data[i:].index('\xff') -1 newstr = data[i:i+str_end] strlen = len(newstr) newstr = newstr.replace("\x0a\x00","[NEWLINE]") # ASCII, . newstr = newstr.replace("\x00","") g.write("%#x\t%d\t" % (str_offset,strlen)) g.write(newstr) g.write("\n") g.close() I renamed CT.ADO to CT_J.ADO to later generate a new file.
This program reads the ADO file, finds 0xFF33, skips 6 bytes (to bypass the opcode and two two-byte values), and then writes the initial offset of the line, the length of the line and the line itself into a new line in the new file in the new file.
You will notice that I replace all the values 0x0a (new line) with [NEWLINE]. I do this because I want the entire line to be processed on one line and I can define new lines where I want without changing the format of the text file.
For fun, let's do something stupid: we will parse this text with the help of translator. This is a Python module that loads data into Google Translate, automatically recognizes the language, translates and returns the text in the desired language:
cttt.py:
#!/usr/bin/env python # -*- encoding: utf-8 -*- ''' Clocktower Auto Translator by rFx ''' import os,sys,binascii,struct from translate import Translator translator = Translator(to_lang="en") #Set to English by Default f = open("ct_txt.txt","rb") g = open("ct_txt_proc2.txt","wb") proc_str = [] for line in f.readlines(): proc_str.append(line.rstrip()) for x in range(0,len(proc_str)): line = proc_str[x] o,l,instr = line.split("\t") ts = translator.translate(instr.decode("SHIFT-JIS").encode("UTF-8")) ts = ts.encode("SHIFT-JIS","replace") proc_str[x] = "%s\t%s\t%s" % (o,l,ts) g.write(proc_str[x]+"\n") #for pc in proc_str: # g.write(pc) g.close() Now, let's try a couple of lines with an injector - the last program in this package parses the text file, adds a strike with zeros to all ASCII characters in the lines, reads lines into the dictionary, so that we know which offsets are involved. In addition, it recreates ADO from scratch (it reads ADT, loads all the “scenes” into the array with their offsets, copies all the data between the lines and after them), and then re-generates the ADT based on the size of the “scenes” ADO:
ctti.py:
''' Clocktower Text Injector by rFx ''' import os,sys,struct,binascii def is_ascii(s): return all(ord(c) < 128 for c in s) def get_real_offset(offset): # high_val = offset & 0xFFFF0000 high_val /= 2 low_val = offset & 0xFFFF return high_val+low_val def get_fake_offset(offset): # mult = int(offset / 0x8000) shft_val = 0x8000 * mult low_val = offset & 0xFFFF return offset + shft_val f = open("CT_J.ADO","rb") data = f.read() f.close() offset_vals = [] adt_list = [] newdata = "" f = open("ct_txt_proc.txt","rb") lines = f.readlines() o,l,s = lines[0].split("\t") first_offset = int(o,16) o,l,s = lines[0].split("\t") last_offset_strend = int(o,16) + int(l) newdata = data[:first_offset] for i in range(0,len(lines)): line = lines[i] offset, osl, instr = line.split("\t") offset = int(offset,16) instr = instr.rstrip('\n') instr = instr.replace("[NEWLINE]","\x0a") # ASCII. instr = instr.decode("SHIFT-JIS") newstr = "" for char in instr: if(is_ascii(char)): newstr+=char+'\x00' else: newstr+=char instr = newstr instr = instr.encode("SHIFT-JIS") newstrlen = len(instr) osl = int(osl) strldiff = newstrlen - osl # if(i < len(lines)-1): nextline = lines[i+1] nextoffset,nsl,nstr = nextline.split("\t") offset_vals.append({"offset":offset,"val":strldiff}) nextoffset = int(nextoffset,16) newdata += instr+data[offset+osl:nextoffset] else: offset_vals.append({"offset":offset,"val":strldiff}) newdata += instr + data[offset+osl:] # EOF f.close() # ADO. g = open("CT.ADO","wb") g.write(newdata) g.close() # ADT. f = open("CT_J.ADT","rb") datat = f.read() f.close() g = open("CT.ADT","wb") for i in range(0,len(datat),4): cur_offset = get_real_offset(struct.unpack("<I",datat[i:i+4])[0]) final_adj = 0 for offset in offset_vals: if(cur_offset > offset["offset"]): final_adj += offset["val"] g.write(struct.pack("<I",get_fake_offset(cur_offset + final_adj))) g.close() Check how it works:
Fine!
English will be pretty awful, fortunately, I found an rtf file with translation on the Clocktower fan forum and was able to manually edit the lines based on rough translations.
Everything is translated and ready to go! Let's run:
Hell!
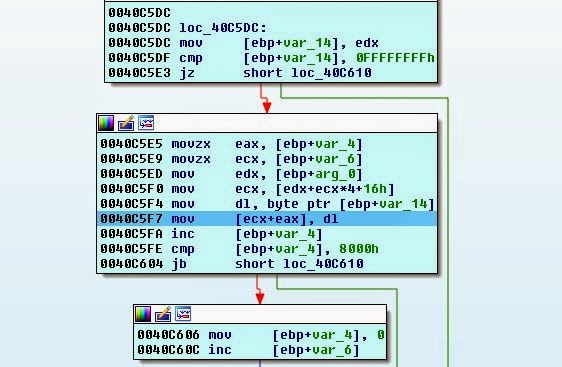
Something is wrong, let's drop the file in IDA and see what happens:
It looks like we are reading the ADO file into memory, but it is trying to use a pointer and cannot because there is nothing in this place.
Observe the struct a1 and the malloc it runs, probably the problem. Having rummaged a little longer, we find out that these pointers are created here:
That is, the game (based on the cmp5 opcode) creates pointers only for ADO 5 * 0x8000 fragments, but reads ADO data to EOF (this is definitely an error). As a result, we can upload an ADO file of no more than 0x28000 size. Will it stop us? Of course not! Let's take a closer look at the structure of SCE in memory ...
We can change all the cases of loading ADO pointers from 5 to 6 to add one more point, but what will happen after this last pointer? Of course, ADT offsets will begin.
We see that the offset ADT 0x00 is at struct_head + 0x2A and goes to 0x7D0 ... seriously? Pointers to 0x7D0 ??? Wait, it looks like a 0x8000.
As a result, we only have 0x4800 bytes for the ADT file. We can say that by lowering the ADT index to, say, 0x2E, we get four times more bytes to write another ADO pointer and we still have a lot of free space at the end!
Find the struct references on 0x2A and change them to 0x2E too:
Yes! I love object-oriented reverse engineering.
Great, now the game is fully translated. What's next?
We need to make binary changes to CT32.exe using a hex editor:
529B: 74 EB BC7B: 2A 2E BC8D: D0 CC BD35: 2A 2E BD62: 2A 2E D4DA: 2A 2E D4FC: 2A 2E DA58: 2A 2E DA79: 2A 2E 103DA: 2A 2E 10407: 2A 2E 104F8: 2A 2E 105BB: 2A 2E 105E8: 2A 2E 10703: 2A 2E 10730: 2A 2E 115FA: 2A 2E 116B2: 05 06 116E8: 05 06 11720: 2A 2E 11729: D0 CC 1195D: 05 06 1C50F: 20 00 Work for the future - Part 5 - SCEDASM - SCE disassembler
The next logical step is to disassemble all other opcodes to create a text file that will be read in the game / editor.
Something like this:
''' Clocktower ADC Object File Disassembler by rFx ''' import os,sys,binascii,struct ADO_FILENAME = "CT_J.ADO" ADT_FILENAME = "CT_J.ADT" ADO_OP = { 0xFF00:"RETN", #Scene Prologue - 0 bytes of data. - Also an END value... the game looks to denote endings. 0xFF01:"UNK_01", # varying length data 0xFF02:"UNK_02", # 3 bytes of data 0xFF03:"UNK_03", # 3 bytes of data 0xFF04:"UNK_04", # 3 bytes of data 0xFF05:"UNK_05", # 3 bytes of data 0xFF06:"UNK_06", # 3 bytes of data 0xFF07:"UNK_07", # 3 bytes of data 0xFF0A:"UNK_0A", # 4 bytes of data. Looks like an offset to another link in the list? 0xFF0C:"UNK_0C", # 4 bytes of data 0xFF0D:"UNK_0D", # 4 bytes of data 0xFF10:"UNK_10", # 4 bytes of data 0xFF11:"UNK_11", # 4 bytes of data 0xFF12:"UNK_12", # 4 bytes of data 0xFF13:"UNK_13", # 4 bytes of data 0xFF14:"UNK_14", # 4 bytes of data 0xFF15:"UNK_15", # 4 bytes of data 0xFF16:"UNK_16", # 4 bytes of data 0xFF1F:"UNK_1F", # 0 bytes of data 0xFF20:"ALL", # 0 bytes of data. Only at the end of the ADO (twice) #All opcodes above this are like... prologue opcodes (basically in some other list) 0xFF21:"ALLEND", # 2 bytes of data 0xFF22:"JMP", # 2 bytes of data - I think it uses the value for the int offset in adt as destination +adds 2 0xFF23:"CALL", # 6 bytes of data 0xFF24:"EVDEF", # Not used in the game 0xFF25:"!!!!!!", #Not used in the game 0xFF26:"!!!!!!", #Not used in the game 0xFF27:"!!!!!!", #Not used in the game 0xFF28:"!!!!!!", #0 bytes of data. 0xFF29:"END_IF", # 4 bytes of data 0xFF2A:"WHILE", # 4 bytes of data 0xFF2B:"NOP", # 0 bytes of data 0xFF2C:"BREAK", # Not used in the game 0xFF2D:"ENDIF", # 2 bytes of data 0xFF2E:"ENDWHILE", # 2 bytes of data 0xFF2F:"ELSE", # 2 bytes of data 0xFF30:"MSGINIT", # 10 bytes of data 0xFF31:"MSGTYPE", # Not used in the game 0xFF32:"MSGATTR", # 16 bytes of data 0xFF33:"MSGOUT", # Varying length, our in-game text uses this. :) 0xFF34:"SETMARK", #Varying length 0xFF35:"SETWAIT", #Not used in the game 0xFF36:"MSGWAIT", #0 bytes of data 0xFF37:"EVSTART", #4 bytes of data 0xFF38:"BGFILEDISP", #Not used in the game. 0xFF39:"BGLOAD", #Varying length, normally a path to a BMP file is passed in. 0xFF3A:"PALLOAD", #Varying length. Also takes BMP files. 0xFF3B:"BGMREQ", #Varying length - loads a MIDI file into memory. 0xFF3C:"SPRCLR", #2 bytes of data. 0xFF3D:"ABSOBJANIM", #Not used in the game 0xFF3E:"OBJANIM", #Not used in the game. 0xFF3F:"ALLSPRCLR", #0 bytes of data 0xFF40:"MSGCLR", #0 bytes 0f data 0xFF41:"SCREENCLR", #0 bytes of data 0xFF42:"SCREENON", #0 bytes of data 0xFF43:"SCREENOFF", #0 bytes of data 0xFF44:"SCREENIN", # Not used in the game. 0xFF45:"SCREENOUT", # Not used in the game. 0xFF46:"BGDISP", # Always 12 bytes of data. 0xFF47:"BGANIM", #14 bytes of data. 0xFF48:"BGSCROLL",#10 bytes of data. 0xFF49:"PALSET", #10 bytes of data. 0xFF4A:"BGWAIT", #0 bytes of data. 0xFF4B:"WAIT", #4 bytes of data. 0xFF4C:"BWAIT", #Not used in the game. 0xFF4D:"BOXFILL", #14 bytes of data. 0xFF4E:"BGCLR", # Not used in the game. 0xFF4F:"SETBKCOL", #6 bytes of data. 0xFF50:"MSGCOL", #Not used in the game. 0xFF51:"MSGSPD", #2 bytes of data. 0xFF52:"MAPINIT", #12 bytes of data. 0xFF53:"MAPLOAD", #Two Paths... Sometimes NULL NULL - Loads the background blit bmp and the map file to load it. 0xFF54:"MAPDISP", #Not used in the game. 0xFF55:"SPRENT", #16 bytes of data. 0xFF56:"SETPROC", #2 bytes of data. 0xFF57:"SCEINIT", #0 bytes of data. 0xFF58:"USERCTL", #2 bytes of data. 0xFF59:"MAPATTR", #2 bytes of data. 0xFF5A:"MAPPOS", #6 bytes of data. 0xFF5B:"SPRPOS", #8 bytes of data. 0xFF5C:"SPRANIM", #8 bytes of data. 0xFF5D:"SPRDIR", #10 bytes of data. 0xFF5E:"GAMEINIT", #0 bytes of data. 0xFF5F:"CONTINIT", #0 bytes of data. 0xFF60:"SCEEND", #0 bytes of data. 0xFF61:"MAPSCROLL", #6 bytes of data. 0xFF62:"SPRLMT", #6 bytes of data. 0xFF63:"SPRWALKX", #10 bytes of data. 0xFF64:"ALLSPRDISP", #Not used in the game. 0xFF65:"MAPWRT", #Not used in the game. 0xFF66:"SPRWAIT", #2 bytes of data. 0xFF67:"SEREQ", #Varying length - loads a .WAV file. 0xFF68:"SNDSTOP", #0 bytes of data. 0xFF69:"SESTOP", #Varying length - specifies a .WAV to stop or ALL for all sounds. 0xFF6A:"BGMSTOP", #0 bytes of data. 0xFF6B:"DOORNOSET", #0 bytes of data. 0xFF6C:"RAND", #6 bytes of data. 0xFF6D:"BTWAIT", #2 bytes of data 0xFF6E:"FAWAIT", #0 bytes of data 0xFF6F:"SCLBLOCK", #Varying length - no idea. 0xFF70:"EVSTOP", #Not used in the game. 0xFF71:"SEREQPV", #Varying length - .WAV path input, I think this is to play and repeat. 0xFF72:"SEREQSPR", #Varying length - .WAV path input, I think this is like SEREQPV except different somehow. 0xFF73:"SCERESET", #0 bytes of data. 0xFF74:"BGSPRENT", #12 bytes of data. 0xFF75:"BGSPRPOS", #Not used in the game. 0xFF76:"BGSPRSET", #Not used in the game. 0xFF77:"SLANTSET", #8 bytes of data. 0xFF78:"SLANTCLR", #0 bytes of data. 0xFF79:"DUMMY", #Not used in the game. 0xFF7A:"SPCFUNC", #Varying length - usage uncertain. 0xFF7B:"SEPAN", #Varying length - guessing to set the L/R of Stereo SE. 0xFF7C:"SEVOL", #Varying length - guessing toe set the volume level of SE 0xFF7D:"BGDISPTRN", #14 bytes of data. 0xFF7E:"DEBUG", #Not used in the game. 0xFF7F:"TRACE", #Not used in the game. 0xFF80:"TMWAIT", #4 bytes of data. 0xFF81:"BGSPRANIM", #18 bytes of data. 0xFF82:"ABSSPRENT", #Not used in the game. 0xFF83:"NEXTCOM", #2 bytes of data. 0xFF84:"WORKCLR", #0 bytes of data. 0xFF85:"BGBUFCLR", #4 bytes of data. 0xFF86:"ABSBGSPRENT", #12 bytes of data. 0xFF87:"AVIPLAY", #This one is used only once - to load the intro AVI file. 0xFF88:"AVISTOP", #0 bytes of data. 0xFF89:"SPRMARK", #Only used in PSX Version. 0xFF8A:"BGMATTR",#Only used in PSX Version. #BIG GAP IN OPCODES... maybe not even in existence. 0xFFA0:"UNK_A0", #12 bytes of data. 0xFFB0:"UNK_B0", #12 bytes of data. 0xFFDF:"UNK_DF", #2 bytes of data. 0xFFE0:"UNK_E0", #0 bytes of data. 0xFFEA:"UNK_EA", #0 bytes of data. 0xFFEF:"UNK_EF" #12 bytes of data. } if(__name__=="__main__"): print("#Disassembling ADO/ADT...") #Read ADO/ADT Data to memory. f = open(ADO_FILENAME,"rb") ado_data = f.read() f.close() f = open(ADT_FILENAME,"rb") adt_data = f.read() f.close() scene_count = -1 #Skip ADO Header i = 256 while i < (len(ado_data) -1): cur_val = struct.unpack("<H",ado_data[i:i+2])[0] if(cur_val in ADO_OP.keys()): #0xFF00 if(cur_val == 0xFF00): scene_count +=1 print("#----SCENE %d (Offset %#x)" % (scene_count,i)) print(ADO_OP[cur_val]) i+=2 elif(cur_val == 0xFF1F or cur_val == 0xFF20 or cur_val == 0xFF84 or cur_val == 0xFFEA or cur_val == 0xFFE0 or cur_val == 0xFF88 or cur_val == 0xFF78 or cur_val == 0xFF73 or cur_val == 0xFF6E or cur_val == 0xFF6B or cur_val == 0xFF6A or cur_val == 0xFF68 or cur_val == 0xFF60 or cur_val == 0xFF5F or cur_val == 0xFF5E or cur_val == 0xFF57 or cur_val == 0xFF4A or cur_val == 0xFF43 or cur_val == 0xFF42 or cur_val == 0xFF41 or cur_val == 0xFF40 or cur_val == 0xFF36 or cur_val == 0xFF3F or cur_val == 0xFF36 or cur_val == 0xFF2B or cur_val == 0xFF28): print(ADO_OP[cur_val]) i+=2 #0xFF22 elif(cur_val == 0xFF22 or cur_val == 0xFF51 or cur_val == 0xFF21 or cur_val == 0xFF2D or cur_val == 0xFF2E or cur_val == 0xFF2F or cur_val == 0xFF3C or cur_val == 0xFF56 or cur_val == 0xFF58 or cur_val == 0xFF59 or cur_val == 0xFF66 or cur_val == 0xFF6D or cur_val == 0xFF83 or cur_val == 0xFFDF): i+=2 jmpdata = struct.unpack("<H",ado_data[i:i+2])[0] print("%s %d" % (ADO_OP[cur_val],jmpdata)) i+=2 #0xFF23 elif(cur_val == 0xFF23): i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_2 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_3 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 print("%s %#x %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3)) elif cur_val == 0xFF29 or cur_val == 0xFF2A or cur_val == 0xFF37: i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_2 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 print("%s %d %d" % (ADO_OP[cur_val],val_1,val_2)) elif cur_val in range(0xFF02,0xFF08): i+=2 pri_val = struct.unpack("b",ado_data[i])[0] i+=1 sec_val = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 print("%s %d %d" % (ADO_OP[cur_val],pri_val,sec_val)) elif cur_val in range(0xFF0A,0xFF17): i+=2 pri_val = struct.unpack("<I",ado_data[i:i+4])[0] i+=4 print("%s %#x" % (ADO_OP[cur_val],pri_val)) elif (cur_val == 0xFF30): i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_2 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_3 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_4 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_5 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 print("%s %#x %#x %#x %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5)) elif (cur_val == 0xFF33): i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_2 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 endstr_offset = ado_data[i:].index("\xff") endstr_offset -=1 instr = ado_data[i:i+endstr_offset] i+= len(instr) #Decode to UTF-8 instr = instr.replace("\x0a\x00","[NEWLINE]") instr = instr.replace("\x00","[NULL]") instr = instr.decode("SHIFT-JIS") instr = instr.encode("UTF-8") print("%s %#x %#x ``%s``" % (ADO_OP[cur_val],val_1,val_2,instr)) elif (cur_val == 0xFF32): i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_2 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_3 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_4 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_5 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_6 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_7 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_8 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 print("%s %#x %#x %#x %#x %#x %#x %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5,val_6,val_7,val_8)) elif(cur_val == 0xFF34): i+=2 endval_offset = ado_data[i:].index("\xff") - 1 instr = ado_data[i:i+endstr_offset] i+= len(instr) print("%s %s" % (ADO_OP[cur_val],binascii.hexlify(instr))) i+=2 elif(cur_val in range(0xFF39,0xFF3C) or cur_val == 0xFF67): i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 endstr_offset = ado_data[i:].index("\xff") - 1 instr = ado_data[i:i+endstr_offset] i+= len(instr) if(instr.find("\x00\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_2 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0] val_3 = struct.unpack("b",instr[instr.index("\x00")+2:])[0] print("%s %#x %s %#x %#x" % (ADO_OP[cur_val],val_1,finstr,val_2,val_3)) elif(instr.find("\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_2 = struct.unpack("b",instr[instr.index("\x00")+1:])[0] print("%s %#x %s %#x" % (ADO_OP[cur_val],val_1,finstr,val_2)) elif(cur_val == 0xFF69): i+=2 endstr_offset = ado_data[i:].index("\xff") - 1 instr = ado_data[i:i+endstr_offset] i+= len(instr) if(instr.find("\x00\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_2 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0] val_3 = struct.unpack("b",instr[instr.index("\x00")+2:])[0] print("%s %s %#x %#x" % (ADO_OP[cur_val],finstr,val_2,val_3)) elif(instr.find("\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_2 = struct.unpack("b",instr[instr.index("\x00")+1:])[0] print("%s %s %#x" % (ADO_OP[cur_val],finstr,val_2)) elif(cur_val == 0xFF71 or cur_val == 0xFF72): i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_2 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_3 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 endstr_offset = ado_data[i:].index("\xff") - 1 instr = ado_data[i:i+endstr_offset] i+= len(instr) if(instr.find("\x00\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_4 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0] val_5 = struct.unpack("b",instr[instr.index("\x00")+2:])[0] print("%s %#x %#x %#x %s %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,finstr,val_4,val_5)) elif(instr.find("\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_4 = struct.unpack("b",instr[instr.index("\x00")+1:])[0] print("%s %#x %#x %#x %s %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,finstr,val_4)) elif(cur_val == 0xFF87): i+=2 val_1 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_2 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_3 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_4 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 val_5 = struct.unpack("<H",ado_data[i:i+2])[0] i+=2 endstr_offset = ado_data[i:].index("\xff") - 1 instr = ado_data[i:i+endstr_offset] i+= len(instr) if(instr.find("\x00\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_6 = struct.unpack("b",instr[instr.index("\x00")+1:instr.index("\x00")+2])[0] val_7 = struct.unpack("b",instr[instr.index("\x00")+2:])[0] print("%s %#x %#x %#x %#x %#x %s %#x %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5,finstr,val_6,val_7)) elif(instr.find("\x00\x00") != -1): finstr = instr[:instr.index("\x00")] val_6 = struct.unpack("b",instr[instr.index("\x00")+1:])[0] print("%s %#x %#x %#x %#x %#x %s %#x" % (ADO_OP[cur_val],val_1,val_2,val_3,val_4,val_5,finstr,val_6)) #NOT DONE YET else: i+=1 else: i+=1 Then, of course, we will need to shove it all back into the ADO / ADT pair.
Work for the future - Part 6 - PSX version
The PSX version of the game also uses ADO / ADT. Looks like we can convert resources and add exclusive PSX content to the PC version.
Source: https://habr.com/ru/post/332882/
All Articles