GitLab CI for continuous integration and delivery in production. Part 2: Overcoming Difficulties

This article continues the first part , containing a detailed description of our pipeline:
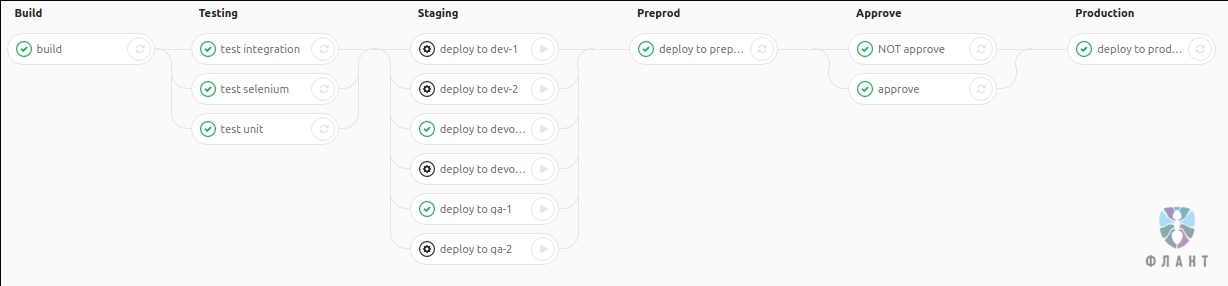
... and talks about the problems that we faced for its implementation, and their solution.
')
So, I stopped at the fact that the created .gitlab-ci.yml does not allow to fully implement the pipeline, since the GitLab CI does not provide directives for separating tasks by users and for describing the dependencies of performing tasks on the status of performing other tasks, and also does not allow Allow
.gitlab-ci.yml for individual users only.1. Protect .gitlab-ci.yml from changes
Any user who has permission to
git push can change .gitlab-ci.yml and break production. This problem is discussed in GitLab tickets: at least in # 24794 and # 20826 at the suggestion of our colleague.It’s hard to say if the protection will ever be implemented out of the box, but at the moment we have implemented its simplified version using a small patch : only some users can push commit commits with changes to
.gitlab-ci.yml - usually this is the DevOps command because assembly and deployment in their area of responsibility.In addition to applying the patch, you will need to add the
ci_admin boolean column to the user table. Whoever is set to true in the column can do git push with changes in .gitlab-ci.yml .2. Variables for task script
The second problem, which turned out to be solved quite easily, is the
GITLAB_USER_ID and GITLAB_USER_EMAIL environment variables for the task script with the user ID and its mail. These variables can be used to determine if a user can run a task. Implemented as a solution to ticket # 21825 , taken to the main branch (upstream) and available in GitLab CI since version 8.12: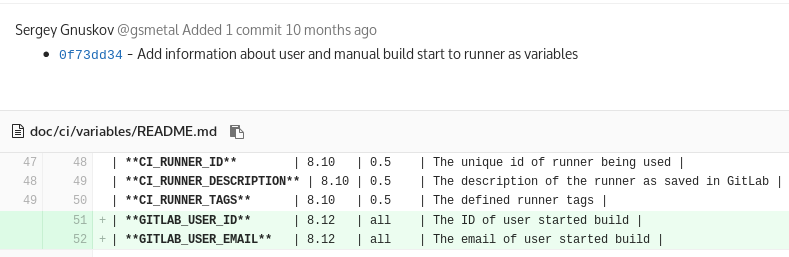
3. Dependencies between stages
One more problem on the way to implementation can be considered some confusion in automatic and manual tasks, in dependencies between the stages. Automatic tasks are always started when the pipeline is started, their launch depends only on the result of the automatic tasks at the previous stage. At the same time, manual tasks and the status of their execution are completely ignored.
That is, firstly, automatic tasks are started only at the moment of creating the pipeline, and secondly, it is impossible to do such a process, when successful execution of a manual task would start automatic tasks located further in the pipeline. Documentation essentially describes the behavior of automatic tasks. Manual tasks live “by themselves” and can be started at any time, regardless of the status of the tasks at the previous stages.
There are several tickets to this account, where it is proposed to change the behavior of manual and automatic tasks:
- # 25892: [CI] Stages after a manual stage should not be started automatically
- # 26499: upstream job is retried
- # 20594: Manual job ignore dependencies
But it seems that these proposals contradict each other. Even in our case, we need manual tasks that can be run independently, and manual tasks that need to respond to the successful completion of one or more tasks. After some thought, the idea arose to use task artifacts and to check for the presence of files from previous stages in scripts.
Task artifacts are files specified in the
artifact directive that will be available (after successfully completing the task) to all other tasks in subsequent stages. Here, however, there are pitfalls: the files from all tasks of the stage will be available at further stages and you cannot remove something from this set. At the same time, task artifact files are not available in other tasks of the same stage.Let's take a closer look at two examples. First, by the example of the testing and staging stages:

According to the description of the pipeline, the deployment tasks to the testers' environments ( deploy to qa- * ) can be run only after all the tests have been completed, and the remaining tasks do not have such dependencies. To implement this logic, at the end of the successful execution of tests, a
touch file with the name of the task is made, and at the beginning of the tasks execution deployed to qa- * , at the staging stage, the presence of these files is checked.For example, here are the listings of the test integration and deployed to qa-1 tasks:
test integration: stage: testing tags: [deploy] script: - mkdir -p .ci_status - echo "test integration" - touch .ci_status/test_integration artifacts: paths: - .ci_status/ deploy to qa-1: tags: [deploy] stage: staging when: manual script: - if [ ! -e .ci_status/test_unit -o ! -e .ci_status/test_integration -o ! -e .ci_status/test_selenium ]; then echo " "; exit 1; fi - echo "execute job ${CI_BUILD_NAME}" - touch .ci_status/deploy_to_qa_1 artifacts: paths: - .ci_status/ The directive
artifact added, which defines the paths in the repository, saved by GitLab CI to the archive after the task has been completed and unarchived before the next task. In order not to list all the files, the directory is specified .ci_status , which does not hurt to create during the execution of the task ( mkdir -p ).Source : a .gitlab-ci.yml file with staging dependency on testing is available here .
The second example is a bit more complicated - the dependence of the production stage on the approve stage:
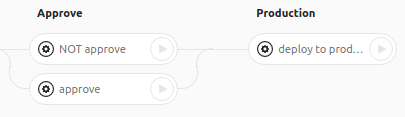
Tasks approve and not approve create files that are checked by the production task. This can be done in the same way as in the previous example, but I want the tasks NOT approve and approve to work as a switch. This work is hampered by the fact that it is impossible to delete artifact files from another task. Therefore, tasks do not just create a file, but write a timestamp into it. At the beginning of the deploy to production task, a check is performed: if the approve timestamp task is larger in the file, then you can continue, if not, the task ends with an error.
approve: script: - mkdir -p .ci_status - echo $(date +%s) > .ci_status/approved artifacts: paths: - .ci_status/ NOT approve: script: - mkdir -p .ci_status - echo $(date +%s) > .ci_status/not_approved artifacts: paths: - .ci_status/ deploy to production: script: - if [[ $(cat .ci_status/not_approved) > $(cat .ci_status/approved) ]]; then echo " -"; exit 1; fi - echo "deploy to production!" After the task is completed, appove is successfully deployed to production :

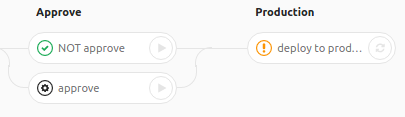
After completing the task NOT approve, the task deployed to production following it fails with an error:
Sources :
- the .gitlab-ci.yml variant with the dependence of the production stage on the approve stage;
- the complete version of the resulting .gitlab-ci.yml with only directives and stage dependencies.
What's next?
It remains not voiced requirement to allow individual tasks only to some users. At this stage, it became clear how this can be implemented: you need a REST API, which can be queried via curl with the transfer of variables
GITLAB_USER_ID and GITLAB_USER_EMAIL . Creating such a REST API is beyond the scope of this article.In these examples, the script that checks dependencies is stored in
.gitlab-ci.yml . This is very inconvenient if there are a lot of projects and something needs to be fixed, for example, if a new environment for qa or pre-production environments becomes larger. We decided this by rendering the scripts into one external script, which is not stored in each repository, but installed on machines with runners.There are several environment variables available for this script. Based on these variables, the script decides what type of task is launched, checks the files from the previous stages to see if this task can be run. If necessary, it checks access for the user through an external REST service. The script contains instructions that you need to perform for the task and after their successful execution creates files to which the next task will respond.
Usually there are not so many variations of tasks in the pipeline, our script knows about three things:
- assembly instructions
- instructions for deployment,
- instructions approve and not approve .
Instructions also receive environment variables and can adjust to a specific task. Since there are a great many options for building and deploying in environments, and the number of projects in GitLab is also different for everyone, I consider the implementation of such a script unnecessary. However, if there are questions - let's discuss in the comments.
Instead of conclusion
I hope that this article will reveal new interesting features of GitLab CI for you and give you a starting point for implementing your own cool pipelines.

PS Do not forget to check
.gitlab-ci.yml at https://-/ci/lint . Help save time!Source: https://habr.com/ru/post/332842/
All Articles