GitLab CI for continuous integration and delivery in production. Part 1: our pipeline
So, GitLab CI : what else can you tell about it? On Habré there are already articles about installation, about setting up runners, about command use, about GitLab Flow. Perhaps, there are not enough descriptions of how GitLab CI is used in a real project, where several teams are involved. And in the modern world of software development, this is true: there are (at least) developers, testers, DevOps and release engineers. With a similar division into teams, we have been working for several years. In this article, I will talk about how, using and improving the capabilities of GitLab CI, we have implemented and used in production for a team of several teams continuous integration processes (CI) and, in part, application delivery (CD).
Our pipeline
If you came across CI systems earlier, then the notion of pipeline is familiar to you - this is the sequence of performing the stages (here and further in the article for the stage, I use the translation “stage”) , each of which includes several tasks (here and further in the article job - “ task ") . From the moment changes are made to the code to rollback into production, the application takes turns in the hands of various teams - similar to how it happens on the pipeline. Hence the term pipeline (“conveyor” is one of the literal translation options) . In our case, it looks like this:
')
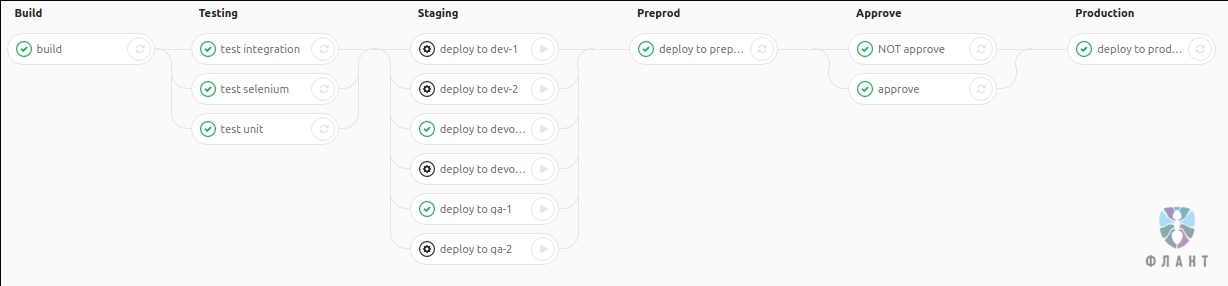
A brief explanation of the stages used:
- build - build the application;
- testing - autotests;
- staging - application deployment for developers, DevOps, testers;
- pre-production - deployment to “pre-production” for a team of testers;
- approve - “fuse”, due to which the release engineer of the customer can refuse to deploy a certain tag in production;
- production - deployment to production.
Note : There is nothing completely universal, so this pipeline is probably not suitable for your particular case: it is either redundant or simple. However, the purpose of the article is not to describe the only correct option suitable for everyone. The goal is to give an example of how you can work in GitLab CI with several teams and what opportunities there are to implement such a pipeline. Based on this information, you can develop your own GitLab CI configuration.
How is it used?
I'll start with the story of the pipeline from the point of view of its use - what can be called a user story. Here it turns out that in fact we have even two pipelines: shortened for branches and full for tags. And this is what these sequences look like:
- Developers put the application code in branches with the prefix feature_ , and DevOps engineers put the infrastructure code in the branches with the prefix infra_ . Each git push to these branches starts the application build process ( build stage) and automated tests ( testing stage).
- Tasks at the next stages are not called automatically, but are defined as tasks with manual start (manual).
- At the staging stage, you can start a task and roll out a compiled and tested application to a simplified environment. This can be done by developers, DevOps engineers, testers. At the same time, in order to roll out on the environment of testers, all tests must be passed.
- After successfully passing the tests and rollout to one of the staging environments, you can roll out the application in pre-production - this is done only by testers, DevOps engineers, or release engineers.
- With the accumulation of successfully tested features, the release engineer prepares a new version and creates a tag in the repository. A pipeline for a tag differs from a pipeline for a branch in two additional stages.
- After successful assembly, tests and roll-out in pre-production, additional manual tests of the new version, showing to the customer and other “bullying” over the application are carried out. If everything went well, the release engineer launches the approve task. If something went wrong, the release engineer starts the task not approve .
- Rolling out the application in production is possible only after a successful rollout in the pre-production and the completion of the approve task. A rollout on production can be launched by a release engineer or a DevOps engineer.

The role of the release engineer in pipeline
Pipeline and stages in detail
Tasks at the build stage build the application. To do this, we use our own development - the Open Source- dapp utility (read about its main features and see this article + video ) , which speeds up the incremental build well. Therefore, the build starts automatically for branches with the prefixes feature_ (application code), infra_ (infrastructure code) and tags, and not just for several traditionally “master” branches (master / develop / production / release).
The next stage, staging, is a set of environments for developers, DevOps engineers, and testers. Here, several tasks are announced that deploy applications from branches with the prefixes feature_ and infra_ in trimmed environments for quick testing of new functionality or infrastructure changes (the application build code is stored in the application repository).
The pre-production and production stages are available only for tags. Typically, the tag hangs after release engineers receive several merge requests from the tested branches. In general, we can say that we use GitLab Flow with the only difference that there is no automatic deployment to production and therefore there are no separate branches, but tags are used.
The approve stage is two tasks: approve and not approve . The first includes the ability to deploy to production, the second - off. These tasks are to ensure that in case of problems in production it was clear that the deployment did not just happen, but with the consent of the release engineer. However, the point is not in depriving someone of a premium, but in the fact that the release itself is often not carried out directly by the release engineer, but by the DevOps team. The release engineer, running the approve task, thereby resolves to “push the button” of the deploy to production command to the DevOps team. It can be said that this stage brings to the surface that which could remain in the postal correspondence or orally.
Such an interaction scheme showed itself well in the work, but had to work hard to implement it. As it turned out, GitLab CI does not support some of the necessary things out of the box ...
Development of .gitlab-ci.yml
After reviewing the documentation and various articles, you can quickly jot down this version of .gitlab-ci.yml , corresponding to the described stages of the pipeline:
stages: - build - testing - staging - preprod - approve - production ## build stage build: stage: build tags: [deploy] script: - echo "Build" ## testing stage test unit: stage: testing tags: [deploy] script: - echo "test unit" test integration: stage: testing tags: [deploy] script: - echo "test integration" test selenium: stage: testing tags: [deploy] script: - echo "test selenium" ## staging stage .staging-deploy: &staging-deploy tags: [deploy] stage: staging when: manual script: - echo $CI_BUILD_NAME deploy to dev-1: <<: *staging-deploy deploy to dev-2: <<: *staging-deploy deploy to devops-1: <<: *staging-deploy deploy to devops-2: <<: *staging-deploy deploy to qa-1: <<: *staging-deploy deploy to qa-2: <<: *staging-deploy ## preprod stage deploy to preprod: stage: preprod tags: [deploy] when: manual script: - echo "deploy to preprod" ## approve stage approve: stage: approve tags: [deploy] when: manual script: - echo "APPROVED" NOT approve: stage: approve tags: [deploy] when: manual script: - echo "NOT APPROVED" ## production stage deploy to production: stage: production tags: [deploy] when: manual script: - echo "deploy to production!" Everything is quite simple and most likely understandable. The following directives are used for each task:
stage- defines the stage to which the task belongs;script- actions that will be performed when the task starts;when- type of the task (manualmeans that the task will be launched from the pipeline manually);tagsare tags that, in turn, determine on which runner the task will be launched.
Note : Runner is part of the GitLab CI, similar to other CI systems, i.e. an agent that receives tasks from GitLab and executes their
script .
Slide Pro Runners from the Coding the Next Build Presentation (ⓒ 2016 Niek Palm)
By the way, have you noticed this block ?
.staging-deploy: &staging-deploy tags: [deploy] stage: staging when: manual script: - echo $CI_BUILD_NAME It demonstrates the ability of the YAML format to define common blocks and connect them to the right place at the right level. See the documentation for details.
In the description of the pipeline, it was said that the approve and production stages are available only for tags. In
.gitlab-ci.yml this can be done using the only directive. It defines the branches for which the pipeline will be created, and using the tags keyword you can allow the creation of a pipeline for tags. Unfortunately, the only directive is only for tasks - it cannot be specified when describing the stage.Thus, tasks at the stages of build , testing , staging , pre-production , which should be available for the infra_ , feature_ branches and tags, take the following form:
test unit: stage: testing tags: [deploy] script: - echo "test unit" only: - tags - /^infra_.*$/ - /^feature_.*$/ And the tasks in the approve and production stages, which are available only for tags, have the following form:
deploy to production: stage: production tags: [deploy] script: - echo "deploy to production!" only: - tags In the full version, the
only directive is passed to the general block (an example of such .gitlab-ci.yml is available here ).What's next?
On this, the creation of
.gitlab-ci.yml for the described pipeline is inhibited because GitLab CI does not provide directives, firstly, to separate tasks by users, and secondly, to describe the dependencies of performing tasks on the status of performing other tasks. I would also like to allow only individual users to change .gitlab-ci.yml .Full implementation of the conceived became possible only thanks to several patches to GitLab and the use of task artifacts. Read more about this in the next part of the article: “ GitLab CI for continuous integration and delivery in production. Part 2: Overcoming Difficulties . ”
Source: https://habr.com/ru/post/332712/
All Articles