Lecture about two libraries of Yandex for working with big data
A couple of weeks ago in Yandex, there was a PyData meeting dedicated to analyzing big data using Python. Including at this meeting, Vasily Agapitov made a speech - the head of the analytics tools development team at Yandex. He spoke about our two libraries: to describe and run calculations on MapReduce and to extract information from the logs.
Under the cut - decoding and part of the slide.
My name is Agapitov Vasily, I represent a data mining team.
')
In Yandex, we perform calculations on large data, in particular, data lying on MapReduce clusters. These are mainly anonymous logs of services and applications. In addition, we provide our big data processing tools to other teams. Our main consumers are development teams. For simplicity, I will call them analysts.
I want to talk about two tools, libraries, the history of their appearance, and how the world of Hadoop influenced their appearance.

Let's synchronize some understanding of terms. Data sources. We will talk exclusively about logs, so for example, let's look at some kind of access log to services.

We have horizontally located records of this log, each record has fields: vhost is the host ID, yandexuid is the visitor ID, iso_eventtime is the date and time of the call, request is the request itself, and many other fields.
Data from some fields can already be used in the calculations. From other fields, data must first be extracted and normalized. For example, the request field contains the request parameters. Each service has its own parameters. For searching, the text parameter is the most used. After we extract it from the request field, we need to normalize it, since it can be very large or have some kind of strange encoding.
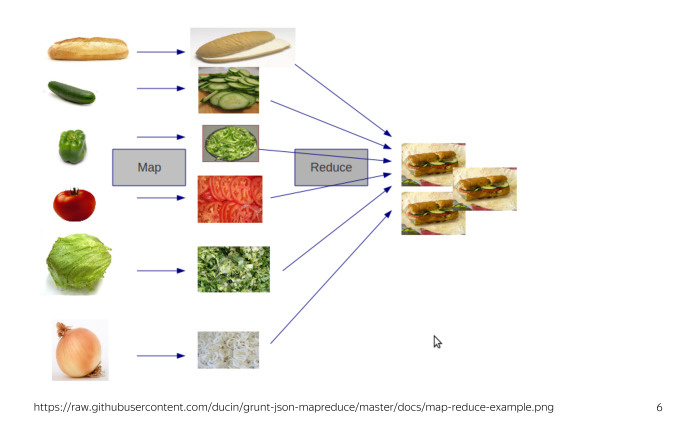
Secondly, we will consider our calculations in terms of calculations on MapReduse clusters. As you know, MapReduse is a sandwich making technology. Actually no, this is a big data processing technology. If you are not familiar with it, then for the current report you need to know that it involves processing data using two operations - Map and Reduce.
The task of the analyst is to build a calculation for log events taking into account some business logic. What difficulties can an analyst face when solving his problem on MapReduse clusters without using any libraries? First, he will have to implement business logic based on MapReduse operations. This approach adds to the calculation code that is not related to the business logic of this calculation, which significantly impairs its readability and support. Secondly, we need to first extract and normalize the data from the logs - for example, the text parameter from the request field.
How to solve the first problem? Obviously, we need some kind of library that will simplify user access to the cluster and interaction with it.
In the world of Hadoop, Pig, Hive, Cascading and some others can be referred to such libraries.
Yandex uses its own implementation of MapReduse called YT, the advantages of which you can read in an article on Habré and which provides basic MapReduse operations for data processing. But, unfortunately, YT had no analogues libraries from the world of Hadoop. We had to fix it.
At the very beginning, when we were faced with this problem, we did describe the Map-stages separately for each calculation, the Reduce-stages separately, and the connection between these stages to start the calculation on the cluster separately.

Moreover, each had its own launcher. Maintain such a zoo is very expensive. The solution for us was the Nile library, a library for describing and running calculations on a cluster. When creating it, we took the idea of Caccading from the world of Hadoop and implemented it in Python - largely because Python uses analytics for local data processing, and using one language for calculations on a cluster and for local data processing is very convenient.
If you know Cascading , then data processing at Nile will also seem familiar to you. We create a stream from the tables on the cluster, modify it, group it, for example, count some aggregates, divide the stream into several streams, combine several streams into one stream, perform other actions, then save the resulting stream with the necessary data back to the table cluster
What are Nile stream modification operations? There are a lot of them, here are the most frequently used Project to get a list of the fields we need. Filter to filter, leaving only the records we need. Groupby + aggregate to group the flow by a given set of fields and count some aggregates. Unique, random and take to build a unique, random, and with a given number of records. Join to combine the two streams by equality of a given set of fields. Split to split a stream into several streams according to some rule with further individual processing of each of them. Sort to sort. Put to put the table on a cluster.
Map and Reduce operations are also available, but are rarely required when you need to do something truly non-standard and complex.

Let's look at the initialization of Nile. It is quite simple. After the import, we create two objects - cluster and job. Cluster is required to indicate on which cluster we want to run and other approximate environment. Job - to describe the process of modifying a thread.

How to create a stream? You can create a stream in two ways: from a table on a cluster or from existing threads. The first two examples show how to create a stream from a table on a cluster. The path to the table on the cluster is passed as an argument. The last example shows how we can create a stream from two existing threads by merging them.
Let's look at some example implementation of the task on Nile.
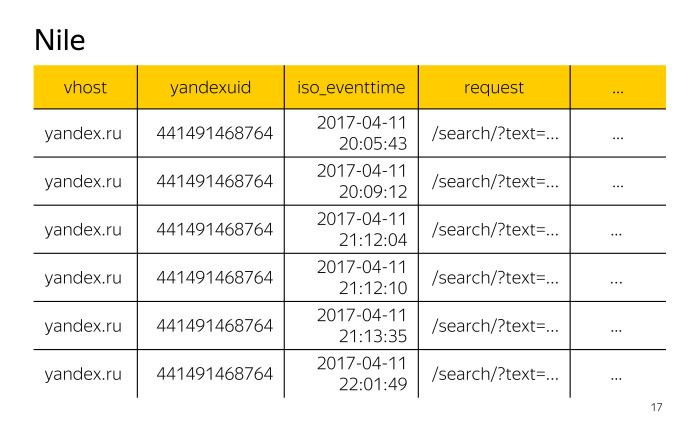
Access logs need to count the number of visitors on the host yandex.com.tr. Recall what our access logs look like. Of all the fields represented, we will be interested in the vhost fields, in order to filter and leave only the entries related to the host yandex.com.tr, and yandexuid, to count the number of visitors.
The code itself on Nile for this task will have the following form.
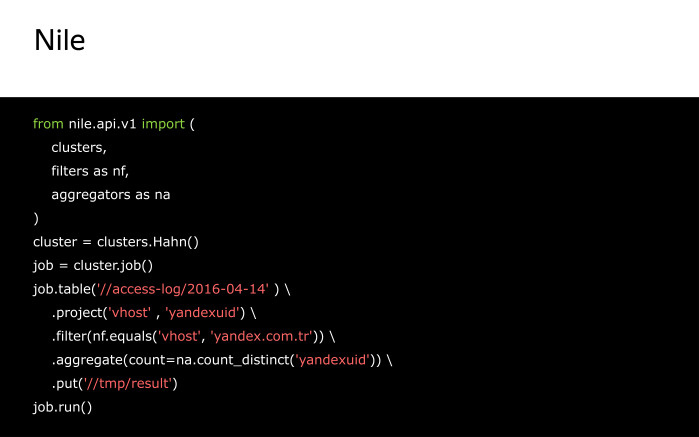
Here we create a stream from the table on the cluster, we get the vhost and yandexuid fields. We leave only records with the value of the vhost field equal to yandex.com.tr, and count the number of unique values of the yandexuid field, and then save the stream to a table on the cluster. Job.run () will start us calculating.
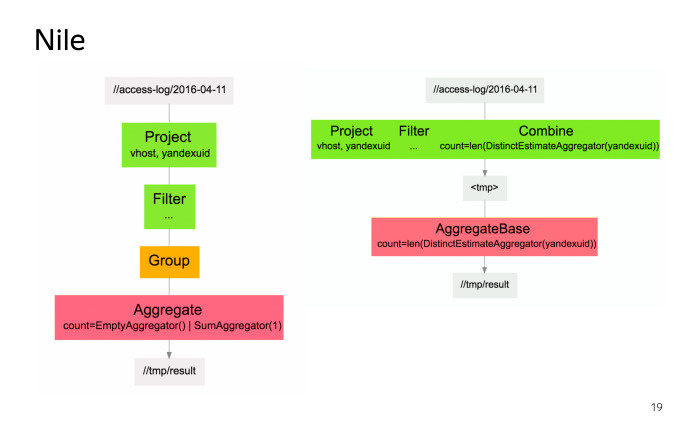
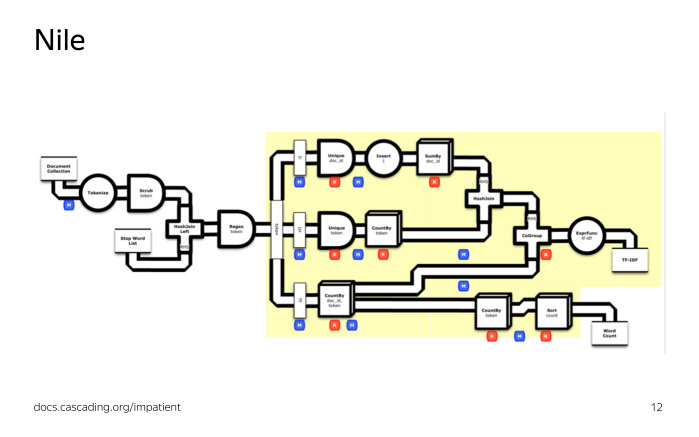
Before running the calculation on the cluster, Nile will transfer our calculation to a set of MapReduse operations. On the left is a stream transformation graph in terms of Nile, on the right in terms of MapReduse operations. In addition, Nile automatically optimizes our calculation, that is, if we have several Map operations in a row, then Nile can glue them together into one Map operation performed on the cluster. We see what happened. This is a fairly simple task, and the code for it will look relatively simple in any programming language.
To consider something more complicated, let's recall the second problem faced by analysts: the data from the logs need to be extracted and normalized.
How to solve this problem? ETL is usually used to solve this problem. Who knows what it is? 30 percent knows. Who does not know or knew, but forgot: ETL assumes that we have raw raw data, we extract the necessary records, fields and other things from them, modify them taking into account some business logic and load into the repository. In the future, we will perform all calculations on the data from the repository, that is, on the normalized data.
We have chosen a different path. We store raw data and perform calculations on them, and the process of extracting and normalizing data occurs in each calculation.
Why did we choose this path? Suppose, in the process of extracting and normalizing fields, an external library is used, and in this library there was a bug. After we fix the bug, we will need to recalculate the calculations for the past. In our approach, we simply run calculations for the past and get the right results. In the case of ETL - if this library was used in the process - we will first have to re-extract the data, process this library, put it in storage and then perform the calculations.
A good option if you can store both raw data and normalized. We, unfortunately, because of the large amount of data there is no such possibility.
At the beginning, for each calculation we performed the extraction and normalization of data individually. Then we noticed that for the same logs we often extract similar fields in approximately the same way, and we combined these rules into one QB2 library. The rules themselves were called extractors, the sets of such rules for logs - parse trees.

So, now the QB2 library provides an abstract interface to raw logs and knows about parse trees.
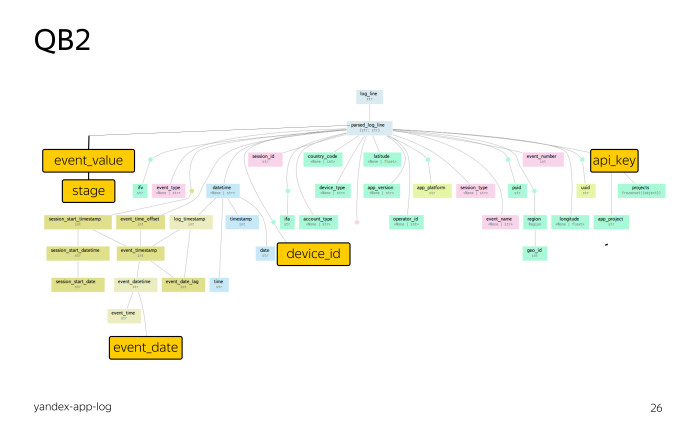
Let's take a look at the parse tree. This is a parse tree for logs of Yandex mobile applications. Do not look closely, this is a global map.
At the very top of the log entry. All other colored rectangles are virtual fields. Links are extractors. Thus, a user without the QB2 library can only access log fields. A user using the QB2 library can use both the log fields and the fields provided by the QB2 library for this log.
Let's look at the benefits of this library with a specific example. Consider the task. Suppose we have some Yandex mobile application identified by the API_key field value equal to 10321. We know that it writes logs to the fields, in particular, the event_value field, which contains the dictionary as a JSON object. We will be interested in the value of the stage key of this dictionary.
We need to count the number of visitors for each stage by event date. What fields does the QB2 library provide us with for this? First, API_key, application identifier. The second is device_id, the user id. And finally event_date, the date of the event, which is not obtained directly from the log entry, but by a fairly large number of conversions. Without the use of the QB2 library, we would have to perform manual conversions in every calculation where this field is required. Agree, it is inconvenient.
In addition, we need event_value fields and a stage value. They are not in our parse tree, and this is logical, because they are written only for one specific application.
We will have to supplement our parse tree to the next species by using extractors. How will the initialization change for this task? We additionally import extractors and filters. Extractors will be required to get the event_value and stage field values. Filters - to filter the records, leaving only the necessary ones.
You may ask: why in this example we used filtering from the QB2 library, although in the previous one we used filtering from Nile? QB2, like Nile, tries to optimize your calculation, namely, it tries to get the values for the fields used in filtering as early as possible. Earlier than values for other virtual fields.
Why is this done? So that we do not receive values for the rest of the virtual fields, if our record does not pass on any filtering conditions. Thus, we greatly save computational resources and speed up the calculation on the cluster.

The calculation code itself will have the following form. We here in the same way create a stream from a table on a cluster and modify it with the QB2 operator, which we initialize with the following things: the name of the parse tree, which in our case coincides with the name of the log, as well as a set of fields and filters.
In the fields, we list the API_key, device_id, and event_date fields by their names, because the QB2 library already knows how to retrieve these fields.
To extract the event_value field, we use the standard json_log_field extractor. What is he doing? By the name passed to him, he gets the value from the corresponding log field and loads it as a JSON object. We store this loaded value in the event_value field.
To get the stage, we use another standard extractor, dictItem. According to the name of the key and the name of the field passed to him, he extracts the corresponding value from this field for this key.
About filtering. We will be interested only in the records that have the device_id field value and which belong to our application, that is, the api_key field value is 10321. After applying the QB2 operator, our stream will have the following fields: api_key, device_id, event_date, event_value and stage.
Modify the resulting stream as follows. Group by a pair of event_date and stage fields and calculate the number of unique device_id values. We will put this value in the users field, after which we will save the resulting stream to the cluster. Job.run () will start the calculation.
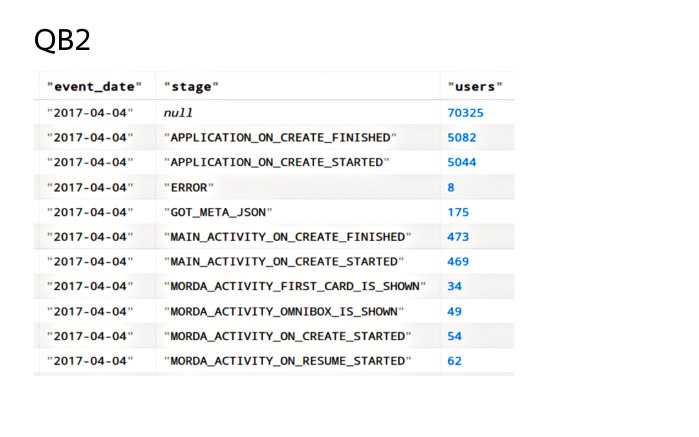
After the end of the calculation, the cluster will have a table of the following form: for each pair of event_date and stage fields in the users field there will be the number of unique values of users. Thus, the integration of the QB2 and Nile libraries solves both problems that I voiced. Thanks for attention.
Under the cut - decoding and part of the slide.
My name is Agapitov Vasily, I represent a data mining team.
')
In Yandex, we perform calculations on large data, in particular, data lying on MapReduce clusters. These are mainly anonymous logs of services and applications. In addition, we provide our big data processing tools to other teams. Our main consumers are development teams. For simplicity, I will call them analysts.
I want to talk about two tools, libraries, the history of their appearance, and how the world of Hadoop influenced their appearance.
Let's synchronize some understanding of terms. Data sources. We will talk exclusively about logs, so for example, let's look at some kind of access log to services.
We have horizontally located records of this log, each record has fields: vhost is the host ID, yandexuid is the visitor ID, iso_eventtime is the date and time of the call, request is the request itself, and many other fields.
Data from some fields can already be used in the calculations. From other fields, data must first be extracted and normalized. For example, the request field contains the request parameters. Each service has its own parameters. For searching, the text parameter is the most used. After we extract it from the request field, we need to normalize it, since it can be very large or have some kind of strange encoding.
Secondly, we will consider our calculations in terms of calculations on MapReduse clusters. As you know, MapReduse is a sandwich making technology. Actually no, this is a big data processing technology. If you are not familiar with it, then for the current report you need to know that it involves processing data using two operations - Map and Reduce.
The task of the analyst is to build a calculation for log events taking into account some business logic. What difficulties can an analyst face when solving his problem on MapReduse clusters without using any libraries? First, he will have to implement business logic based on MapReduse operations. This approach adds to the calculation code that is not related to the business logic of this calculation, which significantly impairs its readability and support. Secondly, we need to first extract and normalize the data from the logs - for example, the text parameter from the request field.
How to solve the first problem? Obviously, we need some kind of library that will simplify user access to the cluster and interaction with it.
In the world of Hadoop, Pig, Hive, Cascading and some others can be referred to such libraries.
Yandex uses its own implementation of MapReduse called YT, the advantages of which you can read in an article on Habré and which provides basic MapReduse operations for data processing. But, unfortunately, YT had no analogues libraries from the world of Hadoop. We had to fix it.
At the very beginning, when we were faced with this problem, we did describe the Map-stages separately for each calculation, the Reduce-stages separately, and the connection between these stages to start the calculation on the cluster separately.
Moreover, each had its own launcher. Maintain such a zoo is very expensive. The solution for us was the Nile library, a library for describing and running calculations on a cluster. When creating it, we took the idea of Caccading from the world of Hadoop and implemented it in Python - largely because Python uses analytics for local data processing, and using one language for calculations on a cluster and for local data processing is very convenient.
If you know Cascading , then data processing at Nile will also seem familiar to you. We create a stream from the tables on the cluster, modify it, group it, for example, count some aggregates, divide the stream into several streams, combine several streams into one stream, perform other actions, then save the resulting stream with the necessary data back to the table cluster
What are Nile stream modification operations? There are a lot of them, here are the most frequently used Project to get a list of the fields we need. Filter to filter, leaving only the records we need. Groupby + aggregate to group the flow by a given set of fields and count some aggregates. Unique, random and take to build a unique, random, and with a given number of records. Join to combine the two streams by equality of a given set of fields. Split to split a stream into several streams according to some rule with further individual processing of each of them. Sort to sort. Put to put the table on a cluster.
Map and Reduce operations are also available, but are rarely required when you need to do something truly non-standard and complex.
Let's look at the initialization of Nile. It is quite simple. After the import, we create two objects - cluster and job. Cluster is required to indicate on which cluster we want to run and other approximate environment. Job - to describe the process of modifying a thread.
How to create a stream? You can create a stream in two ways: from a table on a cluster or from existing threads. The first two examples show how to create a stream from a table on a cluster. The path to the table on the cluster is passed as an argument. The last example shows how we can create a stream from two existing threads by merging them.
Let's look at some example implementation of the task on Nile.
Access logs need to count the number of visitors on the host yandex.com.tr. Recall what our access logs look like. Of all the fields represented, we will be interested in the vhost fields, in order to filter and leave only the entries related to the host yandex.com.tr, and yandexuid, to count the number of visitors.
The code itself on Nile for this task will have the following form.
Here we create a stream from the table on the cluster, we get the vhost and yandexuid fields. We leave only records with the value of the vhost field equal to yandex.com.tr, and count the number of unique values of the yandexuid field, and then save the stream to a table on the cluster. Job.run () will start us calculating.
Before running the calculation on the cluster, Nile will transfer our calculation to a set of MapReduse operations. On the left is a stream transformation graph in terms of Nile, on the right in terms of MapReduse operations. In addition, Nile automatically optimizes our calculation, that is, if we have several Map operations in a row, then Nile can glue them together into one Map operation performed on the cluster. We see what happened. This is a fairly simple task, and the code for it will look relatively simple in any programming language.
To consider something more complicated, let's recall the second problem faced by analysts: the data from the logs need to be extracted and normalized.
How to solve this problem? ETL is usually used to solve this problem. Who knows what it is? 30 percent knows. Who does not know or knew, but forgot: ETL assumes that we have raw raw data, we extract the necessary records, fields and other things from them, modify them taking into account some business logic and load into the repository. In the future, we will perform all calculations on the data from the repository, that is, on the normalized data.
We have chosen a different path. We store raw data and perform calculations on them, and the process of extracting and normalizing data occurs in each calculation.
Why did we choose this path? Suppose, in the process of extracting and normalizing fields, an external library is used, and in this library there was a bug. After we fix the bug, we will need to recalculate the calculations for the past. In our approach, we simply run calculations for the past and get the right results. In the case of ETL - if this library was used in the process - we will first have to re-extract the data, process this library, put it in storage and then perform the calculations.
A good option if you can store both raw data and normalized. We, unfortunately, because of the large amount of data there is no such possibility.
At the beginning, for each calculation we performed the extraction and normalization of data individually. Then we noticed that for the same logs we often extract similar fields in approximately the same way, and we combined these rules into one QB2 library. The rules themselves were called extractors, the sets of such rules for logs - parse trees.
So, now the QB2 library provides an abstract interface to raw logs and knows about parse trees.
Let's take a look at the parse tree. This is a parse tree for logs of Yandex mobile applications. Do not look closely, this is a global map.
At the very top of the log entry. All other colored rectangles are virtual fields. Links are extractors. Thus, a user without the QB2 library can only access log fields. A user using the QB2 library can use both the log fields and the fields provided by the QB2 library for this log.
Let's look at the benefits of this library with a specific example. Consider the task. Suppose we have some Yandex mobile application identified by the API_key field value equal to 10321. We know that it writes logs to the fields, in particular, the event_value field, which contains the dictionary as a JSON object. We will be interested in the value of the stage key of this dictionary.
We need to count the number of visitors for each stage by event date. What fields does the QB2 library provide us with for this? First, API_key, application identifier. The second is device_id, the user id. And finally event_date, the date of the event, which is not obtained directly from the log entry, but by a fairly large number of conversions. Without the use of the QB2 library, we would have to perform manual conversions in every calculation where this field is required. Agree, it is inconvenient.
In addition, we need event_value fields and a stage value. They are not in our parse tree, and this is logical, because they are written only for one specific application.
We will have to supplement our parse tree to the next species by using extractors. How will the initialization change for this task? We additionally import extractors and filters. Extractors will be required to get the event_value and stage field values. Filters - to filter the records, leaving only the necessary ones.
You may ask: why in this example we used filtering from the QB2 library, although in the previous one we used filtering from Nile? QB2, like Nile, tries to optimize your calculation, namely, it tries to get the values for the fields used in filtering as early as possible. Earlier than values for other virtual fields.
Why is this done? So that we do not receive values for the rest of the virtual fields, if our record does not pass on any filtering conditions. Thus, we greatly save computational resources and speed up the calculation on the cluster.
The calculation code itself will have the following form. We here in the same way create a stream from a table on a cluster and modify it with the QB2 operator, which we initialize with the following things: the name of the parse tree, which in our case coincides with the name of the log, as well as a set of fields and filters.
In the fields, we list the API_key, device_id, and event_date fields by their names, because the QB2 library already knows how to retrieve these fields.
To extract the event_value field, we use the standard json_log_field extractor. What is he doing? By the name passed to him, he gets the value from the corresponding log field and loads it as a JSON object. We store this loaded value in the event_value field.
To get the stage, we use another standard extractor, dictItem. According to the name of the key and the name of the field passed to him, he extracts the corresponding value from this field for this key.
About filtering. We will be interested only in the records that have the device_id field value and which belong to our application, that is, the api_key field value is 10321. After applying the QB2 operator, our stream will have the following fields: api_key, device_id, event_date, event_value and stage.
Modify the resulting stream as follows. Group by a pair of event_date and stage fields and calculate the number of unique device_id values. We will put this value in the users field, after which we will save the resulting stream to the cluster. Job.run () will start the calculation.
After the end of the calculation, the cluster will have a table of the following form: for each pair of event_date and stage fields in the users field there will be the number of unique values of users. Thus, the integration of the QB2 and Nile libraries solves both problems that I voiced. Thanks for attention.
Source: https://habr.com/ru/post/332688/
All Articles