How I found a bug in Intel Skylake processors
 The instructors of the Introduction to Programming course know that students find any reasons for the mistakes of their programs. Did the sorting process discard half the data? “Could it be a virus in Windows!” Did the binary search never work? “The Java compiler is behaving strangely today!” Experienced programmers know very well that a bug is usually in their own code, sometimes in third-party libraries, very rarely in system libraries, extremely rare in a compiler and never in a processor. I thought so too until recently. I have not yet encountered a bug in the Intel Skylake processors when I was debugging OCaml’s mysterious crashes.
The instructors of the Introduction to Programming course know that students find any reasons for the mistakes of their programs. Did the sorting process discard half the data? “Could it be a virus in Windows!” Did the binary search never work? “The Java compiler is behaving strangely today!” Experienced programmers know very well that a bug is usually in their own code, sometimes in third-party libraries, very rarely in system libraries, extremely rare in a compiler and never in a processor. I thought so too until recently. I have not yet encountered a bug in the Intel Skylake processors when I was debugging OCaml’s mysterious crashes.First manifestation
At the end of April 2016, shortly after the release of OCaml 4.03.0, one Very Serious Industrial User OCaml (OSIP) addressed me privately with bad news: one of our applications, written in OCaml and compiled in OCaml 4.03.0, fell randomly . Not at every launch, but sometimes segfault crashed, in different places of the code. Moreover, failures were observed only on their newest computers that run on Intel Skylake processors (Skylake is the code name of the latest generation of Intel processors at the time. Now the latest generation is Kaby Lake).
Over the past 25 years, I have been informed of many OCaml bugs, but this message was of particular concern. Why only processors skylake? In the end, I could not even reproduce the crashes in OSIP binaries on computers in my company Inria, because they all worked on older Intel processors. Why fails are not reproduced? The OSIP single-threaded application does network and disk I / O operations, so its execution must be strictly deterministic, and any bug that caused a segfault should manifest itself at each launch in the same place of the code.
My first guess was that OSIP had hardware glitches: bad memory chip? overheat? In my experience, due to such malfunctions, the computer can boot up and work normally in the GUI, but falls under load. So, I advised OSIP to run a memory check, reduce the processor clock speed and disable Hyper-Threading. The assumption about HT appeared in connection with a recent report about a bug in Skylake with AVX vector arithmetic, which appeared only when HT was turned on ( see description ).
')
OSIP did not like my advice. He objected (logically) that they ran other demanding CPU and memory tasks / tests, but only programs written in OCaml are falling. Obviously, they decided that their hardware was fine, but a bug in my program. Well, great. I still persuaded them to run a memory test that revealed no errors, but they ignored my request to turn off the HT. (Very bad, because it would save us a lot of time).
At the same time, OSIP conducted an impressive investigation using different versions of OCaml, different C compilers, which are used to compile the OCaml support system, and different operating systems. The verdict was as follows. Buggy OCaml 4.03, including early beta, but not 4.02.3. From compilers GCC is buggy, but not Clang. From operating systems - Linux and Windows, but not MacOS. Since MacOS uses Clang and the port from the Windows version on GCC works there, the reason is clearly called OCaml 4.03 and GCC.
Of course, OSIP reasoned logically: they say, in the OCaml 4.03 run-time support system there was a fragment of bad C code - with undefined behavior , as we say in business - because of which GCC generated bad machine code, since C compilers are allowed to work with indefinite behavior. This is not the first time that GCC handles undefined behavior as improperly as possible. For example, see this security vulnerability or this broken benchmark .
Such an explanation seemed plausible, but it did not explain the random nature of the failures. GCC generates bizarre code due to undefined behavior, but it is still deterministic code. The only reason for the randomness that I could come up with could be Address Space Layout Randomization (ASLR) —the OS function to randomize the address space, which changes the absolute addresses in memory each time it starts. The OCaml runtime support system uses absolute addresses in some places, including for indexing memory pages into a hash table. But the crashes remained random even after the ASLR was turned off, in particular, while the GDB debugger was running.
It was May 2016, and it was my turn to mess up my hands when OSIP sent a subtle hint - he gave access to the shell to his famous Skylake machine. First of all, I compiled a debug version of OCaml 4.03 (to which I planned to add more debugging tools later) and reassembled the OSIP application with this version of OCaml. Unfortunately, this debug version did not cause a crash. Instead, I started working with the OSIP executable file, first interactively manually under GDB (but it drove me crazy, because sometimes I had to wait a whole hour for a crash), and then with a small OCaml script that ran the program 1000 times and saved memory dumps on every failure.
Debugging the OCaml runtime support system is not the most fun, but posthumous debugging from memory dumps is generally terrible. An analysis of 30 memory dumps showed segfault errors in seven different places, two places in OCaml GC, and five more in the application. The most popular place with 50% of crashes was the
mark_slice function in the OCaml garbage collector. In all cases, OCaml damaged the heap: there was a bad pointer in a well-formed data structure, that is, a pointer that did not point to the first field of the Caml block, but to the header or the middle of the Caml block, or even to an invalid memory address (already freed) . All 15 mark_slice failures were caused by a pointer two words ahead of a block of 4.All these symptoms were consistent with familiar errors, such as the one that the
mark_slice compiler forgot to register the memory object in the garbage collector. However, such errors would lead to reproducible failures, which depend only on the allocation of memory and the actions of the garbage collector. I didn’t understand at all what type of memory management error OCaml could cause random crashes!In the absence of better ideas, I again listened to the inner voice, which whispered: "hardware bug!". I had a vague feeling that malfunctions occur more often if the machine is under greater load, as if it were just overheating. To test this theory, I changed my OCaml script to run N copies of the OSIP program in parallel. For some runs, I also turned off the OCaml memory seal, which caused more memory consumption and more garbage collection activity. The results were not as I expected, but still amazing:
| N | System loading | With default settings | With seal off |
|---|---|---|---|
| one | 3 + epsilon | 0 failures | 0 failures |
| 2 | 4 + epsilon | 1 crash | 3 failures |
| four | 6 + epsilon | 12 failures | 19 failures |
| eight | 10 + epsilon | 17 failures | 23 failures |
| sixteen | 18 + epsilon | 16 failures |
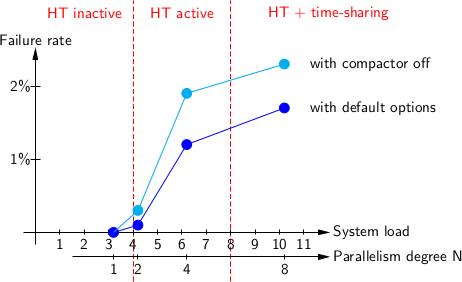
This shows the number of crashes per 1000 test program launches. See the jump between and ? And the plateau between higher values ? To explain these figures, you need to tell in more detail about the test machine Skylake. It has 4 physical cores and 8 logical cores, since HT is enabled. The two cores were busy in the background with two long-term tests (not mine), but otherwise the car was free. Consequently, the system load was where - This is the number of tests running in parallel.
When no more than four processes work at the same time, the OS scheduler distributes them equally among the four cores of the machine and stubbornly tries not to direct the two processes to two logical cores of one physical core, because this will lead to insufficient use of other physical cores. This happens in the case of as well as most of the time in the case of . If the number of active processes exceeds 4, then the OS starts applying HT, assigning processes to two logical cores on the same physical core. This is the case . Only if all 8 logical cores on the machine are occupied, the OS performs the traditional time sharing between processes. In our experiment, these are cases. and .
Now it became clear that failures begin only when Hyper-Threading is turned on, more precisely, when the OCaml program was running next to another thread (logical core) on the same physical core of the processor.
I sent OSIP the results of experiments, begging him to accept my theory that multithreading was to blame. This time, he listened and disconnected the HT in his car. After that, the failures completely disappeared: two days of continuous testing did not reveal any problems at all.
Problem solved? Yes! A happy ending? Not really. Neither I nor OSIP tried to report a problem to Intel or anyone else, because OSIP was satisfied that OCaml could be compiled with Clang, and also because he did not want unpleasant publicity in the spirit of “OSIP products fall randomly! ". I’m completely tired of this problem, and didn’t know how to report such things (Intel doesn’t have a public bug tracker, like ordinary people), and I also suspected that this was a bug of OSIP specific machines (for example, a batch of failed chips which accidentally got into the wrong basket in the factory).
Second manifestation
The year 2016 went quietly, no one else reported that the sky (sky, more precisely, Skylake - pun) falls because of OCaml 4.03, so I happily forgot about this little episode with OSIP (and continued to write terrible puns).
Then, on January 6, 2017, Angerran Dekorn and Joris Giovannangeli from Ahrefs (another Very Serious Industrial User OCaml, member of the Caml Consortium in addition) reported mysterious random crashes with OCaml 4.03.0: this is PR # 7452 in the Caml tracker.
In their example of a repeated failure, the ocamlopt.opt compiler itself sometimes crashed or produced a meaningless result when it compiled a large source file. This is not too surprising because ocamlopt.opt itself is an OCaml program compiled by the compiler ocamlopt.byte, but it was easier to discuss and reproduce the problem.
Public comments on the PR # 7452 bug show quite well what happened next, and the Ahrefs staff described their bug hunt in detail in this article . So I will highlight only the key points of this story.
- 12 hours after the opening of the ticket, when there were already 19 comments in the discussion, Angerran Dekorn said that “all the machines that were able to reproduce the bug work on Intel processors from the Intel Skylake family”.
- The next day, I mentioned random crashes at OSIP and suggested disabling multithreading (Hyper-Threading).
- A day later, Joris Giovannangeli confirmed that the bug is not reproduced when Hyper-Threading is disabled.
- In parallel, Joris discovered that a failure occurs only if the OCaml runtime support system is built with the
gcc -O2parameter, but not thegcc -O1. Looking back, this explains the absence of failures with the debugging version of the OCaml environment and with OCaml 4.02, since both of them are built by default with thegcc -O1parameter. - I go on stage and post the following comment:
Would it be crazy to assume that the
gcc -O2setting on the OCaml 4.03 environment produces a specific sequence of instructions that causes a hardware failure (some stepping) in Skylake processors with Hyper-Threading? Perhaps this is madness. On the other hand, there is already one documented hardware problem with Hyper-Threading and Skylake (link) - Mark Shinwell contacted colleagues at Intel and managed to push the report through the customer support department.
Then nothing happened for 5 months, until ...
Opening
On May 26, 2017, user "ygrek" published a link to the following changelog from the Debian microcode package:
* New upstream microcode datafile 20170511 [...]
* Likely fix nightmare-level Skylake erratum SKL150. Fortunately,
either this erratum is very-low-hitting, or gcc/clang/icc/msvc
won't usually issue the affected opcode pattern and it ends up
being rare.
SKL150 - Short loops using both the AH/BH/CH/DH registers and
the corresponding wide register *may* result in unpredictable
system behavior. Requires both logical processors of the same
core (ie sibling hyperthreads) to be active to trigger, as
well as a "complex set of micro-architectural conditions"Errata SKL150 was documented by Intel in April 2017 and is described on page 65 in the 6th Generation Intel Processor Specification Update . A similar errata is referred to as SKW144, SKX150, SKZ7 for the Skylake and KBL095, KBW095 for the newer Kaby Lake architecture. The words "total nightmare" are not mentioned in the Intel documentation, but roughly describe the situation.
Despite the rather vague description (“a complex set of micro-architectural conditions,” and do not say!), This errata is hitting the target: is Hyper-Threading enabled? There is such a thing! Manifests pseudo-randomly? There is! Not related to either floating point or vector instructions? There is! In addition, a microcode update is ready that fixes this error, it is nicely packaged in Debian and ready to be loaded into our test machines. A few hours later, Joris Giovannangeli confirmed that the crash disappeared after updating the microcode. I launched even more tests on my newest workstation with a Skylake processor (thanks to the Inria supply department) and came to the same conclusion, because the test, which collapsed in less than 10 minutes with the old microcode, worked for 2.5 days without any problems with the new microcode .
There is one more reason to believe that SKL150 is the culprit of our problems. The fact is that the problematic code described in this errata generates GCC when compiling the OCaml runtime support system. For example, in the
byterun/major_gc.c for the sweep_slice function, sweep_slice get the following C code: hd = Hd_hp (hp); /*...*/ Hd_hp (hp) = Whitehd_hd (hd); After macro expansion, it looks like this:
hd = *hp; /*...*/ *hp = hd & ~0x300; Clang compiles this code in a banal way, using only full-width registers:
movq (%rbx), %rax [...] andq $-769, %rax # imm = 0xFFFFFFFFFFFFFCFF movq %rax, (%rbx) However, GCC prefers to use the 8-bit register
%ah to work with bits 8 to 15 of the full register %rax , leaving the remaining bits unchanged: movq (%rdi), %rax [...] andb $252, %ah movq %rax, (%rdi) These two codes are functionally equivalent. One possible reason for choosing GCC could be that its code is more compact: the 8-bit constant
$252 fits into one byte of code, while the 32-bit one, extended to 64 bits, the constant $-769 needs 4 bytes. In any case, the generated GCC code uses both %rax and %ah and, depending on the level of optimization and unsuccessful combination of circumstances, such code may end in a cycle small enough to cause a SKL150 bug.So, in the end, it's still a hardware bug. Told ya!
Epilogue
Intel has released microcode updates for Skylake and Kaby Lake processors, which fix or bypass the problem. Debian has published detailed instructions for checking whether your processor is susceptible to bugs and how to get and apply microcode updates.
The publication about the bug and the release of microcode turned out to be very timely, because several projects on OCaml began to have mysterious failures. For example, in Lwt , Coq and Coccinelle .
He wrote a number of technical sites about a hardware bug, for example, Ars Technica , HotHardware , Tom's Hardware and Hacker's News [and GeekTimes - approx. trans.].
Source: https://habr.com/ru/post/332552/
All Articles