AWS EC2 Apache CloudStack-style public cloud using KVM hypervisor and NFS storage

Apache CloudStack is a universal virtual machine runtime management platform (often referred to as “VPS cloud control panel”). Using Apache CloudStack (hereinafter referred to as ACS) gives the administrator the ability to deploy a cloud with the required services in a short time, and after deployment, effectively manage the cloud throughout its life cycle. This article provides recommendations on cloud design that can be used in practice and is suitable for most public cloud providers who plan to build public cloud environments of small and medium sizes that have maximum administration simplicity and do not require special knowledge to debug and detect problems. This article is not a step-by-step guide to setting up Apache CloudStack.
The article is described in the form of a set of recommendations and considerations that may be useful when deploying a new cloud. This style of presentation is inspired by the fact that the author is planning to soon deploy a new cloud on this topology.
The cloud with the design described in the article is successfully used to provide commercial services for the rental of a VPS. As part of the cloud, a 16TB storage, consisting entirely of Samsung Pro 850 1TB SSD drives, organized in software RAID6, 176 Xeon E5-2670 cores, 768 GB RAM, network for 256 public addresses, is deployed.
The following describes the proposals and comments on the organization of the cloud, the purpose of which is to provide cost-effective provision of services for a VPS rental service with a monthly availability rate (SLA) of 99.7%, which allows an idle time of 2 hours per month. In the event that the goal is to ensure the provision of a cloud with a higher availability rate, it is necessary to use other cloud organization models that include various fault-tolerant cluster elements, which can also be implemented using Apache CloudStack, but is not covered in this article.
Introduction
The long-term success of a commercial cloud, both from a practical and an economic point of view, depends on the design chosen and the conscious planning of equipment and the correctly formed ratios and limits of cloud resources. At the design stage, it is required to determine what the cloud infrastructure will be and how ACS will be deployed on this infrastructure. ACS allows you to create clouds with a variety of properties, depending on the technical specifications. This article discusses creating a cloud with the following properties:
- All virtual machines are in a single shared address space (for example, on the / 24 network);
- traffic between any virtual machines spreads within a single VLAN;
- allocated addresses are directly assigned to the virtual machine (static NAT is not used);
Within ACS, these properties are satisfied by the basic zone (Basic Zone) with or without Security Groups (Security Groups), if the restriction of traffic sources and traffic assignments for virtual machines is not required.
Additionally, the cloud will use simple and proven storage components that do not require sophisticated knowledge to support them, which is achieved using the NFS storage.
Network
At the first stage, it is necessary to decide on the type and components of the network infrastructure of the cloud. Within this cloud, the resiliency of the network topology is not embedded. To implement this cloud model using a fault-tolerant network topology, it is necessary to use standard approaches to implementing a reliable network infrastructure, for example, LACP, xSTP, MRP, MLAG, stacking technologies, as well as software solutions based on bonding. Depending on the selected network equipment provider, various approaches may be recommended.
The infrastructure will be deployed using three isolated Ethernet networks and three switches:
- An IPMI network that will be used to manage physical equipment, which is necessary to solve incidents involving node failure and other abnormal situations (100 Mbit / s Ethernet ports). This network is configured using “gray” addresses, for example, 10.0.0.0/8, since it is usually necessary to restrict access to control elements from the outside to ensure greater security.
- Network for public traffic “VM-VM”, “VM-consumer”. A switch with 1 Gbit / s Ethernet or 10 Gbit / s Ethernet ports, in case high bandwidth is required for virtual machines. Usually, 1 Gbit / s ports are enough to provide general services. This network is configured using public or gray addresses (if you plan an internal cloud with an external security gateway and NAT).
- A data network for accessing NFS storage, which provides virtualization host access to virtual machine volumes, snapshots, templates, and ISO. This network is recommended to be implemented using 10 Gbit / s Ethernet ports or faster alternative technologies, for example, Infiniband. The network is configured using gray addresses,
for example, 176.16.0.0/12.
It should be noted that the network for accessing the data of virtual machine volumes must be high-performance, and performance must be determined not only by bandwidth, but also through data latency (from the virtualization server to the NFS server). For best results, we recommend using the following solutions:
- Switches for data centers that handle traffic in cut-through mode, because they provide the least latency, which means that each VM instance can receive more IOPS.
- Switches that use faster data transmission protocols, for example, Infiniband 40 Gbit / s, 56 Gbit / s, which provide not only ultra-high bandwidth, but also extremely low latency, which is practically unattainable when using standard Ethernet equipment. In this case, you must use the IPoIB protocol to provide access to the NFS storage over IP over the Infiniband network.
- Configure support for jumbo frames on all devices.
Special requirements for the IPMI network (1) as such are absent, and it can be implemented on the budget equipment itself.
The data network (2) within the chosen cloud model is quite simple, because ACS implements additional security at the hypervisor host level by applying the iptables and ebtables rules, which, for example, makes it possible not to configure dhcp snooping and other settings that are used for port protection when using physical broadband subscribers or hardware servers. It is recommended to use switches that provide data transmission in the store-and-forward mode and have large port buffers, which ensures high quality when transmitting a variety of network traffic. If you want to provide a high priority for certain traffic classes (for example, VoIP), then you need to configure QoS.
The physical cloud hardware within this deployment model uses a storage area network as a network for service traffic, for example, to gain access to external resources (software repositories for updating). To provide these functions, you need a router with NAT functions (NAT GW), which allows you to provide the necessary level of security and isolate the physical network in which the physical devices of the cloud are located from outside access. In addition, the Security Gateway is used to provide access to the API and the ACS user interface using the port translation mechanism.
Switching and routing equipment must be managed and connected to remote power management devices, which allows to solve the most complex cases without going to a technical site (for example, a configuration error that led to loss of communication with the switch).
The cloud network topology is shown in the following image.

Storage
Storage is a key component of the cloud, within this storage deployment model is not assumed to be fault-tolerant, which imposes additional requirements on the selection and testing of server equipment that is planned for use should give preference to equipment released by well-known manufacturers providing ready-made solutions with built-in fault tolerance (for example , specialized solutions from NetApp) or providing reliable server equipment with a proven track record ( HP, Dell, IBM, Fujitsu, Cisco, Supermicro). The cloud will use storage supporting the NFSv3 (v4) protocol.
Apache CloudStack uses two types of storage:
- Primary Storage, which is required for storing virtual machine volumes;
- Secondary Storage (secondary storage), which is designed to store images, images, templates, virtual machines.
It is necessary to carefully plan these components, the performance of the cloud will depend to the greatest extent on their performance and reliability.
Additionally, to perform a global backup of storage, it is recommended to allocate a separate server that can be used for the following purposes:
- disaster recovery;
- prevention of local user accidents related to human factors.
This component is not internal, in relation to the ACS cloud, so the article is not discussed further.
Pros and cons of deploying a cloud using primary NFS storage
NFS is a widely used file system access protocol that has proven itself over decades of use. The advantages of NFS-storage in the implementation of the public cloud service include the following properties:
- high storage performance achieved by consolidating a large number of disk devices in a single server;
- efficient use of storage space, achieved due to the possibility of selling disk space above the real volume due to the use of thin allocation using the QCOW2 format of volumes, which allows you to develop storage as needed with delay;
- the ease of allocation of disk space between virtualization hosts, achieved by the functioning of the entire storage space as a single pool;
- support for live migration of virtual machines between hosts sharing one storage;
- ease of administration.
The disadvantages include the following properties:
- single point of failure for all virtual machines sharing storage;
- careful planning of performance at the design stage is required;
- some routine procedures that require stopping the storage will cause the shutdown of all machines using this storage;
- development of routine procedures to increase free storage space (adding new disks, building a RAID, data migration between logical volumes) is required.
Primary storage
Primary storage should provide the following important operational characteristics:
- high performance for random access (IOPS);
- high bandwidth (MB / s);
- high reliability of data storage.
Usually, at the same time, three data properties can be achieved either by using specialized solutions, or by using hybrid (SSD + HDD) or full SSD storage. In the event that storage is designed using a software implementation, it is recommended to use a storage that consists entirely of SSD drives with hardware or software RAIDs of the 5th or 6th level. It is also possible to consider ready-made solutions for use, such as FreeNAS, NexentaStor, which include support for ZFS, which can give additional bonuses when implementing backup and include built-in mechanisms to save disk space due to deduplication and data compression on the fly.
If you plan to use storage implemented using GNU / Linux, the storage stack is recommended, which includes the following layers:
- software (Mdadm) or hardware RAID (LSI, Adaptec);
- LVM2 (support scaling storage), which allows you to implement the principle of Pay-As-You-Go;
- EXT4.
According to the author’s experience, it is highly not recommended to use Bcache, ZFS On Linux and FlashCache if you plan to use LVM2 snapshots for backup. In the long run, the author of the article observed kernel errors, which led to storage failure, required a restart of the cloud and could lead to loss of user data.
')
Also, the use of BTRFS is highly discouraged, since the KVM hypervisor has known performance problems with this file system.
The author uses the following solutions in his cloud to implement the primary storage:
- Equipment:
- Supermicro Servers with HSI from LSI
- Intel x520-DA2 Network Cards
- Drives Samsung Pro 850 1TB
- Debian GNU / Linux 8
- Software RAID5, RAID6
- Lvm2
- EXT4 file system.
This solution (Mdadm / LVM2 / Ext4) ensures stable operation when using LVM2 snapshots used for backup, without known stability problems. It is highly recommended to connect the storage to the data access network switchboard via two lines combined into a bonding interface (LACP or Master / Slave), which ensures not only high bandwidth, but also fault tolerance (when using stacks or other technologies for building fault-tolerant networks, it is recommended connection to various devices).
When deploying the primary storage, it is necessary to test its performance under maximum loads - at the same time four types of load:
- VM's planned peak load;
- data backup;
- restore a large volume of a custom VM from a backup;
- RAID array in recovery state.
CPU and memory
The processor and the available server memory also have a significant impact on increasing the performance of the primary storage. The NFS server can actively utilize the CPU cores under high loads, both for IOPS and bandwidth. When using multiple software RAIDs within a single server, the mdadm service creates a significant load on the CPU (especially when using RAID5, RAID6). It is recommended to use servers with CPU Xeon E3 or Xeon E5, for better performance it is worth considering a server with two Xeon E5 CPUs. Preference should be given to models with a high clock frequency, since neither NFS nor mdadm can effectively use multi-threading. Additionally, it is worth noting that in the case of performing a global backup of volumes using Gzip compression, some of the cores will be busy with performing these operations. As for RAM, the more RAM available on the server, the more it will be used for the buffer cache and the less reads will be sent to disk devices. In the case of using an NFS server with ZFS, CPU and RAM can affect performance more than with Mdadm / LVM2 / Ext4 due to support for data compression and deduplication on the fly.
Disk Subsystem Settings
In addition to the numerous settings of the disk subsystem, which include specific settings for RAID controllers and logical arrays, proactive reading, the scheduler, but not limited to them, we recommend reducing the time spent in the dirty data buffer memory. This will reduce damage in the event of a storage accident.
NFS service settings
The main options that are configured using NFS are the size of the data transfer unit (rsize, wsize), synchronous or asynchronous mode of saving data to disks (sync, async) and the number of service instances, which depends on the number of NFS clients, that is, virtualization hosts. Using sync mode is not recommended due to poor performance.
Network
It is recommended to use modern network cards, for example, Intel X520-DA2, as network cards for access to the storages. Optimizing the network stack consists in setting up support for the jumbo frame and distributing network card interrupts between the CPU cores.
Secondary storage
Secondary storage should provide the following important characteristics:
- high linear performance;
- high reliability of data storage.
The storage is maximally utilized when creating images and converting images into templates. In this case, the performance of the storage has a significant impact on the duration of the operation. To ensure high linear performance of the storage, software and hardware RAID arrays using RAID10, RAID6, and high-capacity SATA server disks — 3 TB and more — are recommended for use.
If software RAID is used, it is better to stop the selection on RAID10, while using high-performance hardware controllers with the BBU element, it is possible to use RAID5, RAID6.
In general, the requirements for secondary storage are not as critical as the primary storage, however, if you plan on intensive use of virtual machine volume images, careful planning of secondary storage and tests that simulate the actual load are recommended.
The author uses the following solutions in his cloud to implement secondary storage:
- Equipment:
- Supermicro servers with a hardware LSI / Adaptec RAID controller
- Intel x520-DA2 Network Cards
- 3TB Seagate Constellation ES.3 Disk Devices
- Debian GNU / Linux 8
- Hardware RAID10
- Lvm2
- EXT4 file system
Management server
The management server is a key component of the Apache CloudStack system, which is responsible for managing all cloud functions. In the framework of fault-tolerant configurations, it is recommended to use several management servers that interact with the MySQL fault-tolerant server (master-slave or mariadb galera cluster). Due to the fact that the Management Server does not store information in RAM, it is possible to implement a simple HA using MySQL replication and several management servers.
For the purposes of this article, we will assume that one reliable server is used that contains
- MySQL - DBMS for storing ACS data;
- CloudStack Management Server - Java-based application that performs all the functions of ACS;
For the management server, it is necessary to select equipment from a trusted supplier that will ensure reliable, trouble-free operation. The main performance requirements are dictated by the use of MySQL DBMS, respectively, a fast, reliable disk subsystem on SSD drives is required. The initial configuration might look like this:
- Supermicro Xeon E3-1230V5 Server, 32GB RAM with IPMI
- Intel X520-DA2
- 2 x Intel S3610 100GB SSD (RAID1)
- 2 x Seagate Constellation ES.3 3TB (RAID1)
- Lvm2
- Mdadm
- Ubuntu 16.04 Server
A pair of SSD drives is used for the system, and a second pair of SATA drives for system snapshots, dumps of ACS databases that are performed on a regular basis, for example, daily or more often.
In the event that intensive use of the API is planned and if the S3 API is activated, it is recommended to use a server with a high-performance CPU or two CPUs. In addition, in the ACS control server panel itself, it is recommended to configure a restriction on the intensity of use of the API by users and provide additional server protection using the Nginx proxy server.
Apache CloudStack Topology Organization
The overall topological structure of ACS is a hierarchical embedding of entities.
- Zone
- Stand
- Cluster
- Host
The image shows an example of the implementation of such a topological structure for a dc1 data center.
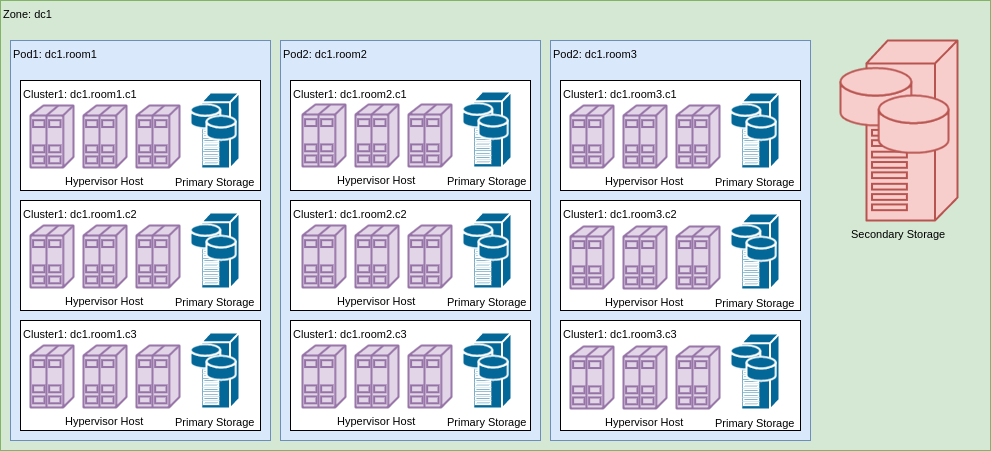
Base zone
ACS Zone defines a set of services that the cloud provides to the user. Zones are of two types - Basic (Basic) and Advanced (Advanced), which allows you to organize different clouds that provide either basic services or a wider range of features, including VPN, elastic balancing, NAT, VPC. The base zone provides the following functions:
- IP address management and DHCP service;
- DNS service (resolver and zone);
- management of passwords and keys set in virtual machines;
- router (optional);
- security groups.
It is also possible to configure other network offers with which you can create basic zones that have different properties, for example, with an external DHCP server.
Stand
Stands represent the next level of topology organization. Depending on the actual organization, the stand can be both a room and alternative entities, for example, a row, a stand. What is meant by a stand is determined primarily by the following factors:
- the number of addresses to be allocated to virtual machines within the booth, the addresses allocated to one booth cannot be transferred to another booth, for example, when allocating a network booth / 22 (1024 addresses), it is necessary to ensure that there is equipment in the booth that can service all address data;
- reservations - a specific stand can be allocated for an account;
- geometric considerations;
- separation of failure domains.
For a network of 1024 virtual machines, one stand is sufficient if all the equipment is placed in one rack, but there can be 4 if there are clear arguments for dividing the network / 22 into 4 x / 24, for example, using different L3 aggregation devices. There may be an arbitrary number of clusters in the stand, so there are no obvious restrictions on planning.
Cluster
A cluster defines a hypervisor to be used for service provisioning. This approach is quite convenient, especially if you plan to use the capabilities of various hypervisors to the maximum, for example:
- KVM - general purpose virtual machines without virtual machine status snapshots, only volume snapshots (AWS-like);
- Xenserver
- virtual machines with graphics accelerators
- virtual machines with snapshot support and dynamic scaling;
- Hyper-V — virtual machines for providing Windows OS services.
Within the considered deployment model, a cluster is an element at the level of which the distribution of a denial of service is limited by allocating the primary NFS storage to the cluster, which makes it possible to ensure that if the primary storage fails, the failure does not extend beyond the cluster. To achieve this goal, when adding primary storage to a cloud, its scope must be specified as a Cluster, and not as a Zone. It should be noted that since the primary storage belongs to the cluster, live migration of virtual machines can be performed only between cluster hosts.
KVM Hypervisor Limitations with Apache CloudStack
The KVM hypervisor has a number of restrictions that may hinder its implementation, however, the prevalence shows that these restrictions are not considered by most providers as blocking. The main limitations are as follows:
- dynamic scaling of virtual machines is not supported, that is, to change the number of cores and RAM, you must stop the machine and start it;
- full virtual machine snapshots are not supported with disks (this limitation is exactly Apache CloudStack, since QEMU / KVM itself supports this feature);
- There is no support for virtual graphics accelerators, so if you plan to provide VDI, together with the infrastructure from NVidia, then KVM will not work.
When planning a cluster, it is important to proceed from the ultimate storage capabilities that will be used with the cluster. ACS allows you to use multiple repositories within a cluster, but the author does not recommend using this option from his own experience. The best is the approach in which the cluster is designed as a kind of compromise between needs and possibilities. Often there is a desire to make clusters too large, which can lead to the fact that the failure domains become too wide.
Cluster design can be done based on understanding the needs of the average virtual machine. For example, in one of the existing clouds, users, on average, order a service that looks like [2 cores, 2GB RAM, 60GB SSD]. If you try to calculate the requirements for the cluster, based on the storage volume (without taking into account the requirements for IOPS), you can get the following numbers:
- Storage 24 x 1TB SSD (RAID6 + 1HS) - 21 TB
- The number of instances of VM - 350 = 21000/60
- RAM - 700 GB = 350 x 2
- Cores - 700 = 350 x 2
- 2 x Xeon E5-2699V4 / 160 GB RAM node - 88 Vcores (166 with 1 to 2 oversubscription)
- The number of nodes (+1 reserve) - 5 + 1
The final cluster will look like this:
- Storage: Storage 24 x 1TB SSD (RAID6 + 1HS)
- Virtualization Server 6 x Server 2 x Xeon E5-2699V4 / 160 GB RAM
As part of this cluster will be able to serve up to 350 standard virtual machines. If you plan to allocate resources for the maintenance of 1000 machines, you need to deploy three clusters. In the case of a real cloud with product differentiation, a calculation is needed that most accurately reflects the forecast of market needs.
In the calculation example, the economic component is not taken into account. In the actual calculation of the CPU model and the amount of RAM per node should be chosen in such a way as to minimize the payback period of the cluster and ensure quality of service agreed with the product owner.
In the event that the total storage size is chosen by another or users acquire VPS with smaller or larger volumes, then the computing power requirements of the cluster can change significantly.
Virtualization server
Virtualization server is designed to run virtual machines. The configuration of a virtualization server can vary considerably from cloud to cloud and depends on the type of computing offers (VPS configurations available to users) and their purpose. Within a single cluster, it is desirable to have one-type, interchangeable virtualization servers with compatible CPUs (or ensure compatibility among the lowest CPU among all), which will ensure live migration of virtual machines between nodes and the availability of cluster resources when one of the nodes fails.
In that case, if you plan to run many small virtual machines with low and medium load, it is desirable to use servers with a large number of cores and memory, for example, 2 x Xeon E5-2699V4 / 256GB RAM. At the same time, it is possible to achieve a good resource density and high quality of service for virtual machines with 1, 2, 4, 8 cores, normal use (not for solving computing tasks) and to achieve high quality of service with significant oversubscription by CPU (2-8 times) . In this case, planning can be done based on the amount of RAM, not the number of cores.
If you plan to deploy high-frequency, multi-core, high-loaded virtual machines, then you need to choose servers that provide the necessary CPU resources. In this case, planning should be made on the basis of the number of cores available without re-signing, and the amount of RAM should correspond to the necessary need. For example, consider the Xeon E3-1270V5 / 64GB RAM server, which can be used to provide high-frequency virtual machine services:
- 1 x CPU 3.6 GHz / 8 GB RAM
- 2 x CPU 3.6 GHz / 16 GB RAM
- 4 x CPU 3.6 GHz / 32 GB RAM
- 8 x CPU 3.6 GHz / 64 GB RAM
, 2 x Xeon E5V4, , CPU, RAM.
RAM
Apache CloudStack . , , , Linux , , , . — KSM, ZRAM ZSwap, RAM, (1:2 ) CPU. , SSD .
, , Intel X520-DA2. jumbo frame CPU.
CPU.
. — Linux Bridge Open Vswitch. Apache CloudStack , , Linux Bridge .
Apache CloudStack , — API UI, JavaScript jQuery. , , UI , . , CloudStack-UI , , Apache CloudStack. Angular v4 Material Design Lite Apache v2.0.
Conclusion
Apache CloudStack . NFS 99.7% . , , .
Source: https://habr.com/ru/post/332528/
All Articles