Delivery of billions of messages strictly once
 The only requirement for all data transmission systems is that data cannot be lost . Data can usually arrive late or can be queried again, but you can never lose it.
The only requirement for all data transmission systems is that data cannot be lost . Data can usually arrive late or can be queried again, but you can never lose it.To meet this requirement, most distributed systems guarantee at least one-time delivery . The “at least one-time delivery” provisioning techniques are usually reduced to “repeat, repeat and repeat” . You never consider the message delivered until you receive a clear confirmation from the client.
But as a user , at least a one-time delivery is not exactly what I want. I want messages delivered once . And only once.
Unfortunately, to achieve something close to exactly one-time delivery, you need an impenetrable design . The architecture provides that each case of failure must be carefully considered - it will not be possible to simply register it as part of an existing implementation after the very fact of failure. And even then it is almost impossible to implement a system in which messages are delivered only once.
')
Over the past three months, we have developed a completely new deduplication system, and as close as possible to exactly one-time delivery, faced with a large number of various failures.
The new system is able to track 100 times more messages than the old one; it differs from it in increased reliability and lower cost. This is how we did it.
Problem
Most internal Segment systems handle glitches elegantly with replay, secondary message sending, blocking, and two-stage commits . But there is one notable exception: customers who send data directly to our public API .
Clients (especially mobile) often experience communication disruptions, when they can send data, but skip the response from our API.
Imagine that you are traveling by bus and booked a room from the HotelTonight application on your iPhone. The application starts downloading data to the Segment servers, but the bus suddenly enters the tunnel and you lose connection. Some of the events you sent are already processed, but the client will never receive a response from the server.
In such cases, clients repeat sending the same events to the Segment API despite the fact that the server has technically received previously exactly the same messages.
Judging by the statistics of our server, approximately 0.6% of the events received in the last four weeks are repeated messages that we have already received.
The level of error may seem insignificant. But for an e-commerce application that generates billions of dollars in revenue, a difference of 0.6% can mean the difference between profit and loss of millions of dollars.
Message Deduplication
So, we understand the essence of the problem - you need to remove duplicate messages that are sent to the API. But how to do that?
At the theoretical level, the high-level API of any deduplication system seems simple. In Python ( aka pseudo-pseudocode ) we can represent it as follows:
def dedupe(stream): for message in stream: if has_seen(message.id): discard(message) else: publish_and_commit(message) For each message in the stream, it is first checked whether such a message was encountered earlier (by its unique identifier). If met, then discard it. If not met, then reissue the message and atomically transmit.
In order not to store all messages permanently, a “deduplication window” operates, which is defined as the storage time of our keys until their expiration date. If messages do not fit into the window, they are considered obsolete. We want to ensure that only one message with the given ID is sent in the window.
This behavior is easy to describe, but there are two details that require special attention: read / write performance and accuracy .
We want the system to deduplicate the billions of events in our data stream — and at the same time with low latency and cost effectiveness.
Moreover, we want to make sure that information about registered events is securely stored, so that we can restore it in case of failure, and that there will never be repeated messages in the output.
Architecture
To achieve this, we created a “two-stage” architecture that reads data from Kafka and removes duplicate events already registered in the four-week window.
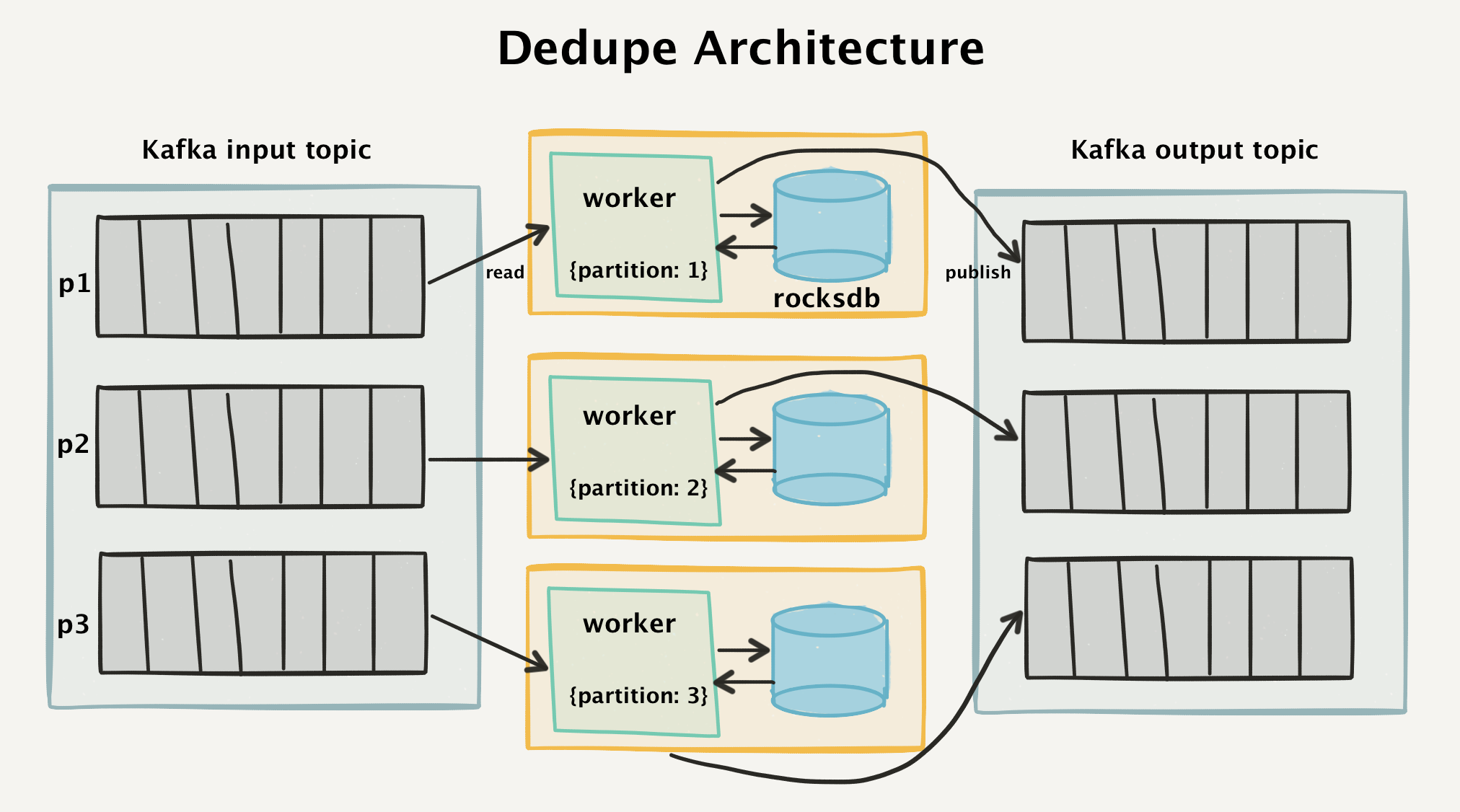
High-level deduplication architecture
Kafka topology
To understand the work of such an architecture, first take a look at the Kafka flow topology. All incoming API calls are divided into separate messages and clearly express the Kafka input section.
First, each incoming message is marked with a unique
messageId , which is generated on the client side. This is usually UUIDv4 (although we are considering switching to ksuid ). If the client does not report messageId, then we automatically assign it at the API level.We do not use vector clocks or sequence numbers, because we do not want to complicate the client side. Using UUIDs allows anyone to easily send data to our API, because almost every major programming language supports it.
{ "messageId": "ajs-65707fcf61352427e8f1666f0e7f6090", "anonymousId": "e7bd0e18-57e9-4ef4-928a-4ccc0b189d18", "timestamp": "2017-06-26T14:38:23.264Z", "type": "page" } Separate messages are logged in Kafka log for durability and repeatability. They are distributed over the messageId, so that we can be sure that the same
messageId always go to the same handler.This is an important detail when it comes to data processing. Instead of searching the central database for a key among hundreds of billions of messages, we were able to narrow the search space by orders of magnitude simply by redirecting the search query to a specific section.
Deduplication Worker is a Go program that reads Kafka input sections. She is responsible for reading messages, checking for duplicates, and if the messages are new, for sending them to the Kafka exit theme.
In our experience, it is extremely easy to manage the workers and topology of Kafka. We no longer have many large Memcached instances that require fault tolerant replicas. Instead, we used the built-in RocksDB databases, which do not need coordination at all and provide us with robust storage at an exceptionally low price. Now more about this.
RocksDB Worker
Each worker stores a local RocksDB database on its local EBS hard drive. RocksDB is a built-in key-value repository developed by Facebook and optimized for extremely high performance.
Whenever an event is retrieved from input sections, the consumer requests RocksDB to determine if such a
messageId previously been encountered.If the message is not in RocksDB, we add the key to the database, and then publish the message in the output sections of Kafka.
If the message is already in RocksDB, the worker simply does not publish it to the output sections and updates the data in the input section with the notification that it has processed the message.
Performance
In order to achieve high performance from our database, we need to correspond to three types of requests for each event processed:
- Detection of the existence of random keys that arrive at the input, but are unlikely to be stored in our database. They can be located anywhere in the key space.
- Record new keys with high performance.
- Recognition of obsolete old keys that did not fall into our “deduplication window”.
As a result, we have to continuously scan the entire database, add new keys and invalidate old keys. Ideally, this should occur within the framework of the previous data model.
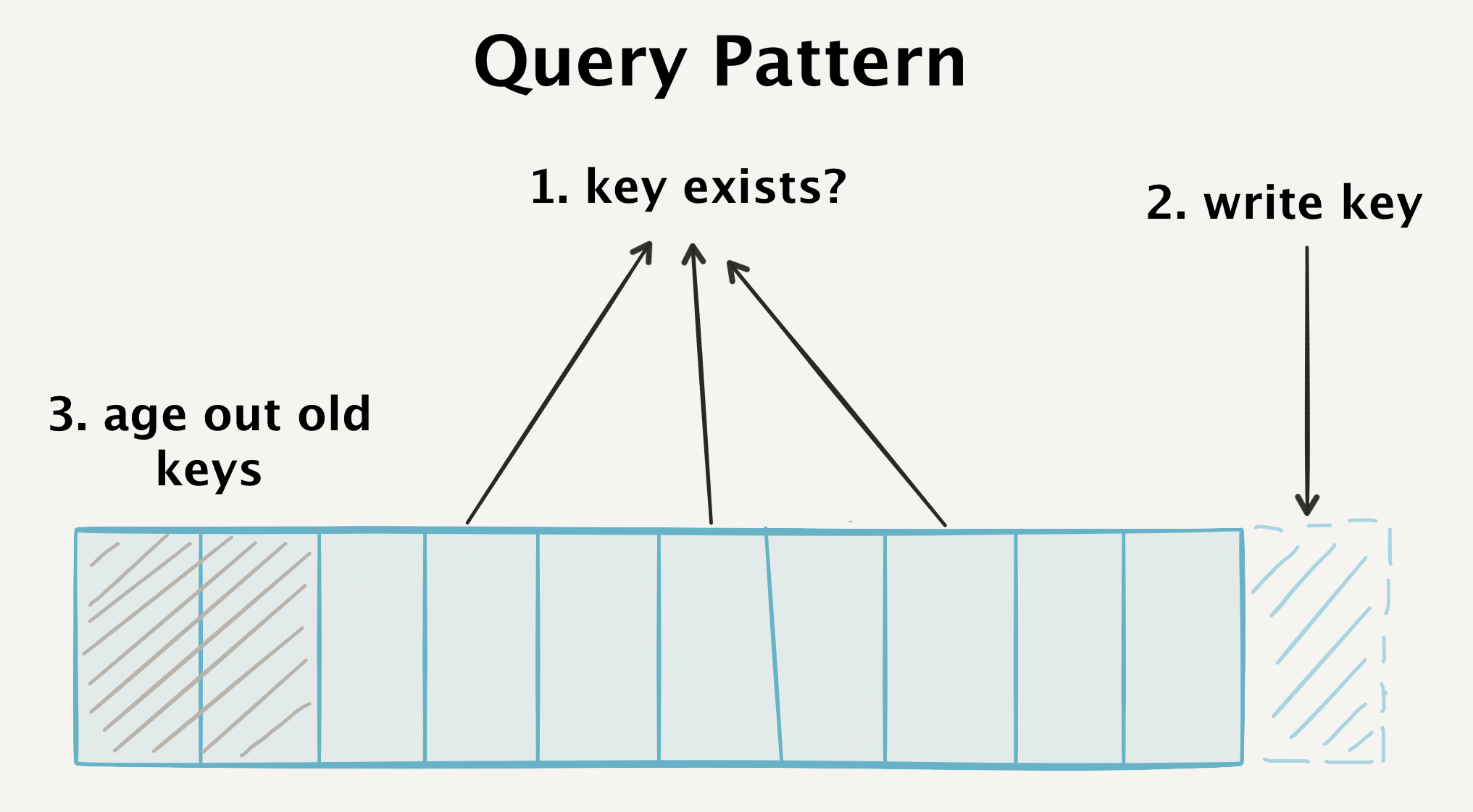
Our database must satisfy three very different types of queries.
Generally speaking, the main part of the performance gain comes from the performance of the database - so it makes sense to understand the RocksDB device, which is why it performs the work so well.
RocksDB is a log-structured tree (LSM-tree) , that is, it continuously adds new keys to the write-ahead log on disk, and also stores sorted keys in memory as part of memtable .

Keys are sorted in memory as part of memtable
Key collection is an extremely fast process. New items are written directly to disk by appending to the log (for direct saving and restoring in case of failure), and data records are sorted in memory to provide quick search and batch recording.
Whenever a sufficient number of records arrive in memtable , they are saved to disk as SSTable (sorted rows table). Since the strings have already been sorted in memory, they can be directly flushed to disk.
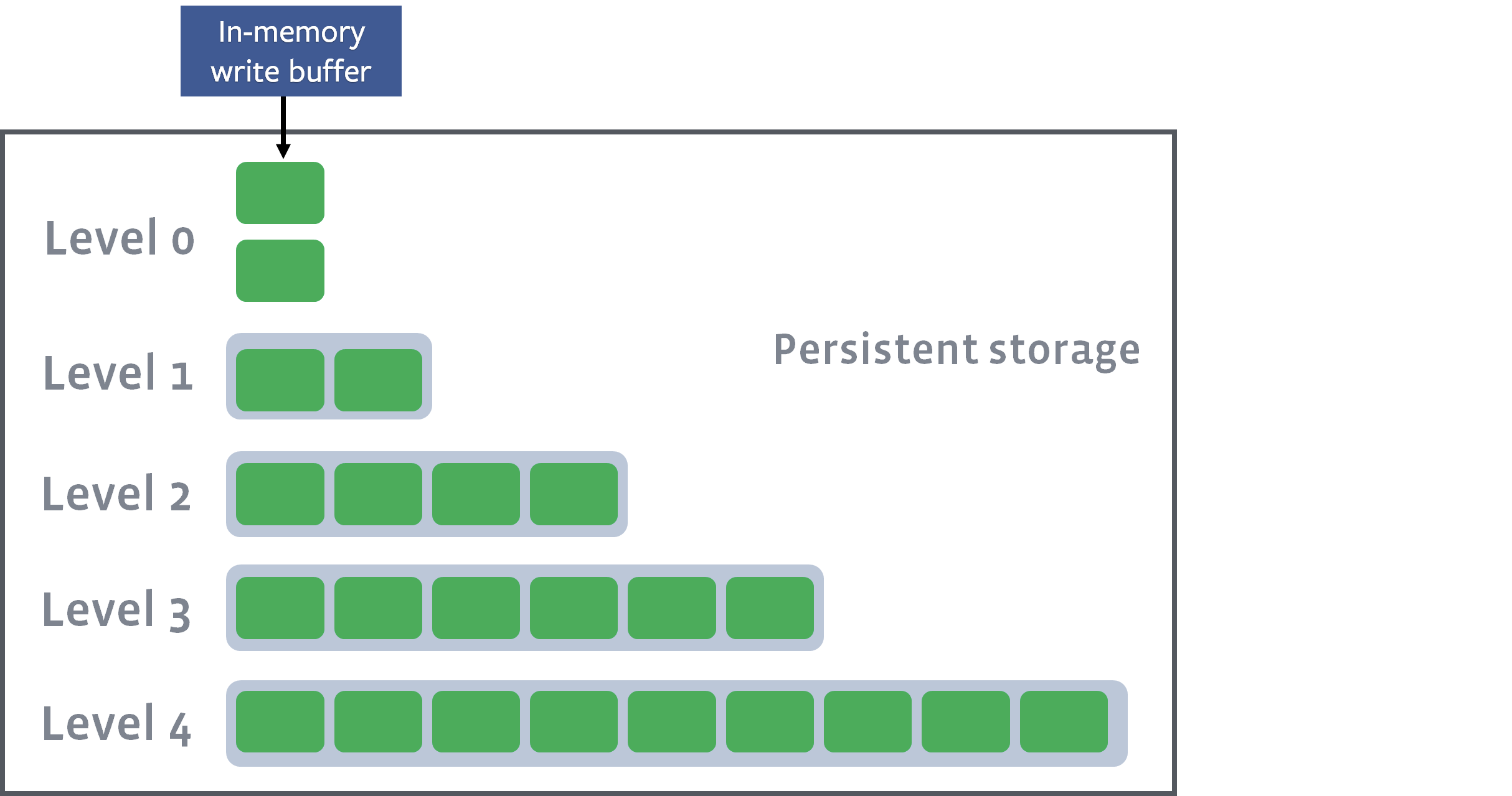
The current state of the memtable is reset to disk as SSTable at level zero (Level 0)
Here is an example of such a reset from our working logs:
[JOB 40] Syncing log #655020
[default] [JOB 40] Flushing memtable with next log file: 655022
[default] [JOB 40] Level-0 flush table #655023: started
[default] [JOB 40] Level-0 flush table #655023: 15153564 bytes OK
[JOB 40] Try to delete WAL files size 12238598, prev total WAL file size 24346413, number of live WAL files 3.Each SSTable table remains unchanged — after it is created, it never changes — thanks to this, the entry of new keys occurs so quickly. No need to update files, and the record does not generate new records. Instead, several SSTable tables at the same “level” are merged into one file during the out-of-band compacting phase.
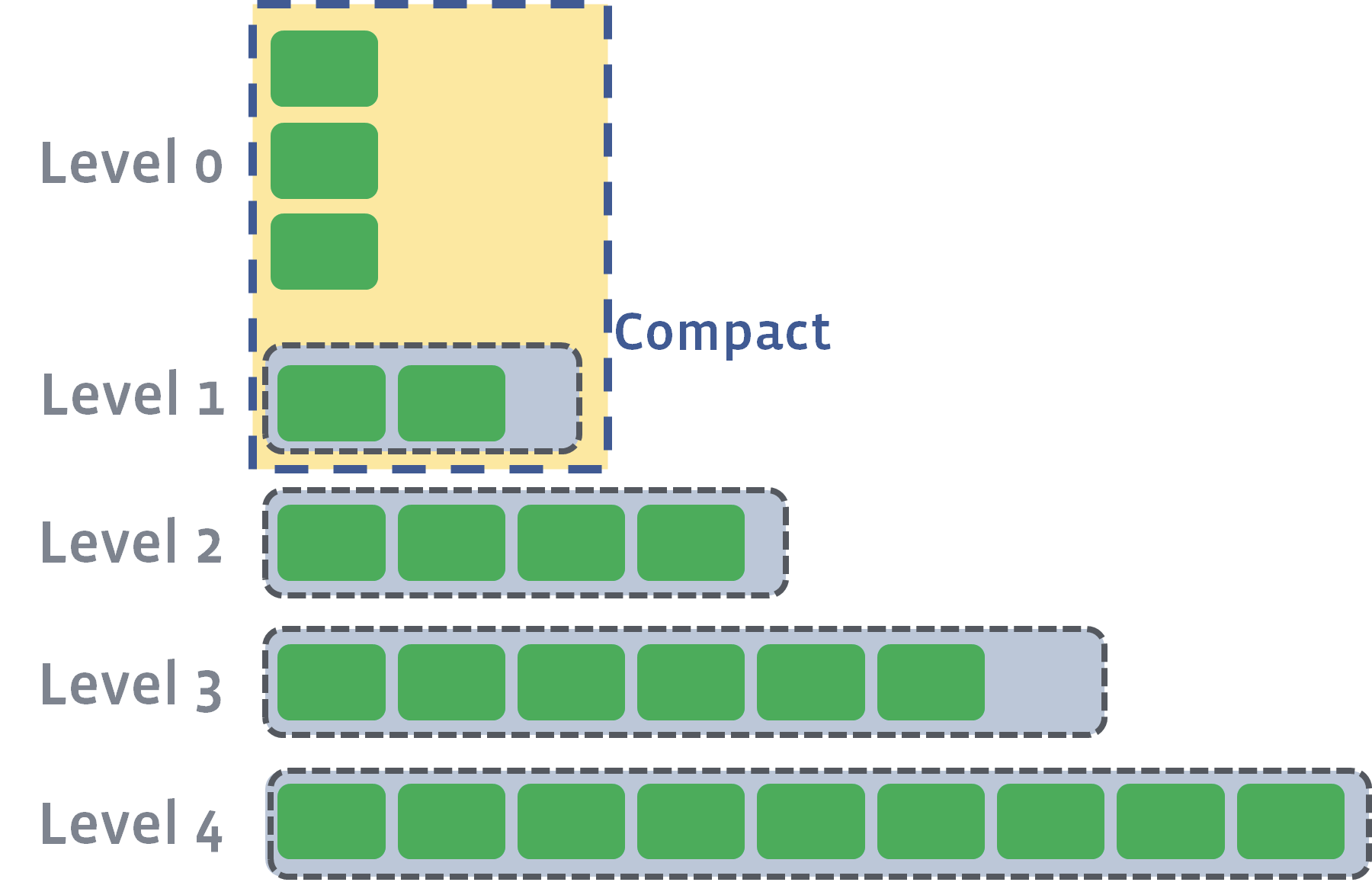
When individual SSTable tables are consolidated from one level, their keys are merged together, and then the new file is transferred to a higher level. In our working logs you can find examples of such seals. In this case, process 41 compacts four zero-level files and combines them into a larger first-level file.
/data/dedupe.db$ head -1000 LOG | grep "JOB 41"
[JOB 41] Compacting 4@0 + 4@1 files to L1, score 1.00
[default] [JOB 41] Generated table #655024: 1550991 keys, 69310820 bytes
[default] [JOB 41] Generated table #655025: 1556181 keys, 69315779 bytes
[default] [JOB 41] Generated table #655026: 797409 keys, 35651472 bytes
[default] [JOB 41] Generated table #655027: 1612608 keys, 69391908 bytes
[default] [JOB 41] Generated table #655028: 462217 keys, 19957191 bytes
[default] [JOB 41] Compacted 4@0 + 4@1 files to L1 => 263627170 bytesAfter the completion of compaction, the combined SSTable tables become the final set of database records, and the old SSTable tables are unlinked.
If you look at the working instance, we will see how this forward-looking journal is updated, as well as how separate SSTable tables are written, read, and merged.
The log and most recent SSTable tables take up the lion's share of I / O operations.
If you look at the SSTable statistics on the production server, you will see four "levels" of files, with increasing file sizes at each higher level.
** Compaction Stats [default] ** Level Files Size(MB} Score Read(GB} Rn(GB} Rnp1(GB} Write(GB} Wnew(GB} Moved(GB} W-Amp -------------------------------------------------------------------------------------------- L0 1/0 14.46 0.2 0.0 0.0 0.0 0.1 0.1 0.0 0.0 L1 4/0 194.95 0.8 0.5 0.1 0.4 0.5 0.1 0.0 4.7 L2 48/0 2551.71 1.0 1.4 0.1 1.3 1.4 0.1 0.0 10.7 L3 351/0 21735.77 0.8 2.0 0.1 1.9 1.9 -0.0 0.0 14.3 Sum 404/0 24496.89 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2 Int 0/0 0.00 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2 Rd(MB/s} Wr(MB/s} Comp(sec} Comp(cnt} Avg(sec} KeyIn KeyDrop 0.0 15.6 7 8 0.925 0 0 20.9 20.8 26 2 12.764 12M 40 19.4 19.4 73 2 36.524 34M 14 18.1 16.9 112 2 56.138 52M 3378K 18.2 18.1 218 14 15.589 98M 3378K 18.2 18.1 218 14 15.589 98M 3378K RocksDB stores the Bloom indexes and filters of specific SSTable tables in these tables themselves - and they are loaded into memory. These filters and indexes are then queried for a specific key, and then the complete SSTable table is loaded into memory as part of the LRU.
In the absolute majority of cases, we see new messages that make our system of deduplication a classic case of using Bloom filters.
Bloom's filters say whether the key is “probably belongs to the set” or “definitely does not belong to the set”. To produce a response, the filter saves many bits after applying different hash functions for each item that occurred before. If all the bits from the hash function converge with the set, then it gives the answer "probably belongs to the set".
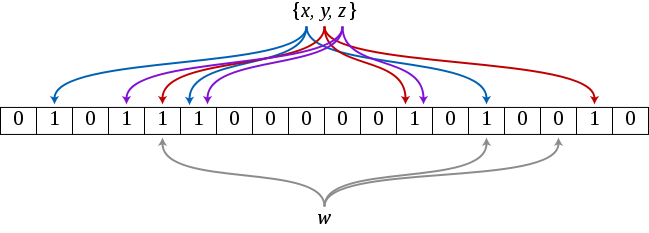
Query the letter w in the Bloom filter when our set contains only {x, y, z}. The filter returns the answer "does not belong to the set", since one of the bits does not converge
If the answer is “probably belongs to the set”, then RocksDB can query the source data from our SSTable tables and determine if the item really is in the set. But in most cases, we can generally avoid querying any tables, because the filter returns the answer "definitely does not belong to the set."
When we access RocksDB, we create a MultiGet request for all the relevant
messageId we want to query. We create it as part of a package for the sake of performance and to avoid many parallel blocking operations. It also allows us to package data from Kafka, and usually avoids random entries in favor of sequential ones.This explains how read / write tasks demonstrate high performance — but the question still remains how stale data is considered obsolete.
Delete: bind to size, not time
In our deduplication process, we need to decide, restrict the system according to the strict “deduplication window” or the total size of the database on disk.
To avoid a system crash due to excessive deduplication for all users, we decided to choose a size limit , rather than a time interval limit . This allows you to set a maximum size for each RocksDB instance and handle sudden ramps or load increases. A side effect is that the time interval can be reduced to less than 24 hours, and our engineer’s duty officer is called at this boundary.
We periodically recognize as obsolete old keys from RocksDB in order to prevent it from growing to unlimited size. To do this, we store the secondary key index in order of number, so that we can delete the oldest keys first.
Instead of using the RocksDB TTL, which would require saving a fixed TTL when opening the database, we delete the objects themselves by the sequence number of each nested key.
Since ordinal numbers are stored as a secondary index, we can quickly query them and “mark” them as deleted. Here is our deletion function after the transfer of its sequence number.
func (d *DB) delete(n int) error { // open a connection to RocksDB ro := rocksdb.NewDefaultReadOptions() defer ro.Destroy() // find our offset to seek through for writing deletes hint, err := d.GetBytes(ro, []byte("seek_hint")) if err != nil { return err } it := d.NewIteratorCF(ro, d.seq) defer it.Close() // seek to the first key, this is a small // optimization to ensure we don't use `.SeekToFirst()` // since it has to skip through a lot of tombstones. if len(hint) > 0 { it.Seek(hint) } else { it.SeekToFirst() } seqs := make([][]byte, 0, n) keys := make([][]byte, 0, n) // look through our sequence numbers, counting up // append any data keys that we find to our set to be // deleted for it.Valid() && len(seqs) < n { k, v := it.Key(), it.Value() key := make([]byte, len(k.Data())) val := make([]byte, len(v.Data())) copy(key, k.Data()) copy(val, v.Data()) seqs = append(seqs, key) keys = append(keys, val) it.Next() k.Free() v.Free() } wb := rocksdb.NewWriteBatch() wo := rocksdb.NewDefaultWriteOptions() defer wb.Destroy() defer wo.Destroy() // preserve next sequence to be deleted. // this is an optimization so we can use `.Seek()` // instead of letting `.SeekToFirst()` skip through lots of tombstones. if len(seqs) > 0 { hint, err := strconv.ParseUint(string(seqs[len(seqs)-1]), 10, 64) if err != nil { return err } buf := []byte(strconv.FormatUint(hint+1, 10)) wb.Put([]byte("seek_hint"), buf) } // we not only purge the keys, but the sequence numbers as well for i := range seqs { wb.DeleteCF(d.seq, seqs[i]) wb.Delete(keys[i]) } // finally, we persist the deletions to our database err = d.Write(wo, wb) if err != nil { return err } return it.Err() } To further guarantee a high write speed, RocksDB does not return immediately and does not remove the key (you remember that the SSTable tables are immutable!). Instead, RocksDB adds a “gravestone” to the key, which is then removed in the process of compacting the base. Therefore, we can quickly recognize obsolete entries during sequential write operations and avoid clogging memory when deleting old items.
Ensuring the correctness of the data
We have already discussed how speed, scaling and cheap search are provided in billions of messages. The last fragment remains - how to ensure the correctness of the data in case of various failures.
EBS images and applications
To protect our RocksDB instances from damage due to a programmer error or failure of EBS, we periodically take snapshots of each of our hard drives. Although EBS replicates on its own, this measure protects against damage caused by some internal mechanism. If we need a specific instance, the client can be paused, at which time the corresponding EBS disk is detached and then reattached to the new instance. As long as we keep the partition ID unchanged, reattaching the disk remains a completely painless procedure, which still ensures the data is correct.
In the event of a worker crash, we rely on the forward write log built into RocksDB to keep the message alive. Messages are not allowed from the input section unless we have a guarantee that RocksDB has reliably saved the message in the log.
Reading the output section
You may have noticed that until that moment there was not that “atomic” step, which allows you to guarantee that messages are delivered strictly once. At any moment there is a possibility that our worker will fail: when writing to RocksDB, when publishing to the output section, or when confirming incoming messages.
We need an atomic “commit” point that will uniquely cover transactions for all of these separate systems. A certain “source of truth” is required for our data.
This is where reading from the output section comes into play.
If for some reason a worker fails or an error occurs in Kafka and then restarted, the first thing to do is to check with the “source of truth” about whether an event has occurred: this source is the output section .
If the message is found in the output section, but not in RocksDB (and vice versa), then the deduplication worker will make the necessary edits to synchronize the database and RocksDB. In fact, we use the output section at the same time as the forward-looking log and the ultimate source of truth, while RocksDB captures and verifies it.
In real work
Now our deduplication system has been in production for three months now and we are incredibly pleased with the results. If in numbers, then we have:
- 1,5 RocksDB
- 4-
- 60 RocksDB
- 200
The system as a whole is fast, efficient and fault tolerant - and with a very simple architecture.
In particular, the second version of our system has several advantages over the old deduplication system.
Previously, we stored all keys in Memcached and used the atomic operator to check and set the value of the CAS record (check-and-set) to set non-existent keys. Memcached served as a point of fixation and "atomicity" when publishing keys.
Although this scheme worked quite well, it required a large amount of memory to fit all of our keys. Moreover, it was necessary to choose between accepting random Memcached failures or doubling our cost of creating memory-hungry fail-safe copies.
The Kafka / RocksDB scheme provides almost all the advantages of the old system, but with increased reliability. Summing up, here are the main achievements:
Data storage on the disk: saving the entire set of keys or full indexing in the memory were unacceptable roads. Transferring more data to disk and using different levels of files and indexes, we were able to significantly reduce the cost. Now we can switch to a “cold” storage (EBS) in case of failure, and not support the work of additional “hot” instances in case of a failure.
Selection of sections:of course, in order to narrow our search space and avoid loading too many indexes into memory, a guarantee is required that certain messages are sent to the correct workers. Partitioning in Kafka allows you to consistently route these messages along the correct routes, so that we can much more efficiently cache data and generate queries.
Accurate recognition of obsolete keys : in Memcached, we would set a TTL for each key to determine its lifetime, and then rely on the Memcached process to exclude keys. In the case of large data packets, this would threaten a lack of memory and irregular CPU usage due to the large number of key exceptions. By instructing the client to delete the keys, we can gracefully avoid the problem by reducing the “deduplication window”.
Kafka : - , . Kafka « » . ( Kafka) Kafka, . Kafka , , .
:by making packet I / O operations for calls to Kafka and RocksDB, we were able to greatly improve performance using sequential read and write. Instead of random access, which was previously with Memcached, we have achieved much higher throughput by improving disk performance and storing only indexes in memory.
In general, we are quite satisfied with the guarantees that the deduplication system we have created. Using Kafka and RocksDB as the basis for streaming applications is increasingly becoming the norm . And we are happy to continue the development of new distributed applications on this foundation.
Source: https://habr.com/ru/post/332448/
All Articles