About analytics and silver bullets or “What does Rambler / Top 100 have to do with it?”

Hello! I tamlid project Rambler / Top 100. This is a longrid about how we designed the architecture of the updated web analytics service, what difficulties we encountered along the way and how we struggled with them. If you are interested in such baswords as Clickhouse , Aerospike , Spark , welcome under cat.
Last year, Rambler and Top-100 turned 20 years old - quite a long time, during which the service had several major updates and the last one happened a long time ago. The previous version of Rambler / Top 100 is morally obsolete in terms of interfaces, code and architecture. When planning a restart, we were aware of the fact that we could not do cosmetic repairs - we had to build a new service almost from scratch.
')
Search solutions
Let us return briefly to the past, at the beginning of 2016, when the composition of the restart of Rambler / Top 100 was determined and the release date was scheduled. By restarting, we had to repeat the functionality of the previous version of Top-100, as well as supplement the service with several new reports on the behavior of visitors needed to solve the analytical tasks of the Rambler & Co services.
At that time, we had an understanding of how to build architecture with batch calculations once a day. The architecture was as simple as three kopecks: at night, a set of Hive scripts runs, reads raw logs, generates a predefined set of aggregates for them from the previous day, and floods them all into HBase.
Understanding perfectly well that the statistics for the next morning, this is literally yesterday, we looked for and researched various options for the systems that would ensure the availability of data for analytics with a small interval (5-10 minutes or less). To achieve this, it was necessary to solve a number of problems:
- calculation of constantly updated data in close to real time;
- pasting target events with page views and sessions;
- query processing with arbitrary data segmentation;
- All of the above need to be done quickly and hold many simultaneous requests.
Let's take a closer look at each problem.
Data from users arrive constantly, and they should be available as quickly as possible. This means that the database engine should quickly insert data, and they should be immediately available for queries. There is a need to consider the sessions of users who strongly go beyond the timeframe of one micro-batch . That is, we need a session storage mechanism, and the data itself should be poured into the database not at the end of the user session, but as events arrive. At the same time, the database should be able to group this data into sessions and page views. It is also important that the database engine provides the ability to glue and change entities after recording (for example, a target event occurred during the session, the user clicked on a block).
There are situations in which you need to quickly make aggregate queries with a user-defined segmentation. For example, a user of analytics wants to know how many people log in with IE6 from Udmurtia, we have to calculate and show it. This means that the base should allow storage of rather weakly aggregated or not aggregated entities at all, and reports on them should be built on the fly. Considering the total amount of data, a sampling mechanism is needed (sampling and calculation of data from this sample instead of counting over the entire population).
At the same time, we should not forget about the growth of data volume in the future: the architecture should keep our load at the start and scale horizontally. The load at the time of designing the architecture is 1.5-2TB of raw logs and 700 million - 1 billion events per day. Additionally, it is very important that the database compresses the data well.
After reviewing a bunch of articles, documentation, talking with smart salespeople and reviewing a couple of dozen reports from various BigData conferences, we came to a not too happy conclusion. At that time, there were three systems on the market that met our requirements: Druid, HP Vertica and Kudu + Impala.
Druid was opensource'ny and according to reviews rather smart, but very crude. Vertica was suitable in all respects and was much steeper than the druid in terms of functionality, but the cost of the base on our data volumes was very heavy. About Kudu + Impala found very little information, it’s scary to use a project with such a quantity of documentation in production.
Another limiting factor is time. We could not afford to develop a new system for several years: we would not have waited for the existing Top 100 users. It was necessary to act quickly.
Taking into account all the introductory, decided to restart the service in two stages. First, we implement the functionality of the old reports on the batch architecture, try to avoid the degradation of the functionality to the maximum and add some new features that are critical for internal customers. At the same time, we are actively looking for solutions that will allow to calculate data and display it in the interface in near real time.
New architecture or "this is a turn!"
As time went on, the restart date was approaching, Druid and Kudu slowly acquired documentation, Vertica was not going to get cheaper. We practically decided to make a monster from the combination of Druid and batch calculation, when EXTREMELY Yandex was laid out in the opensource clickhouse.
Naturally, we paid attention to a new opportunity - at first glance it perfectly solved our task. Having carefully studied the documentation, talked with acquaintances from Yandex and conducted load tests, we came to the conclusion that we will consider Clickhouse as the main option for the second stage of updating the Top-100.
As a result, we got the following architecture:
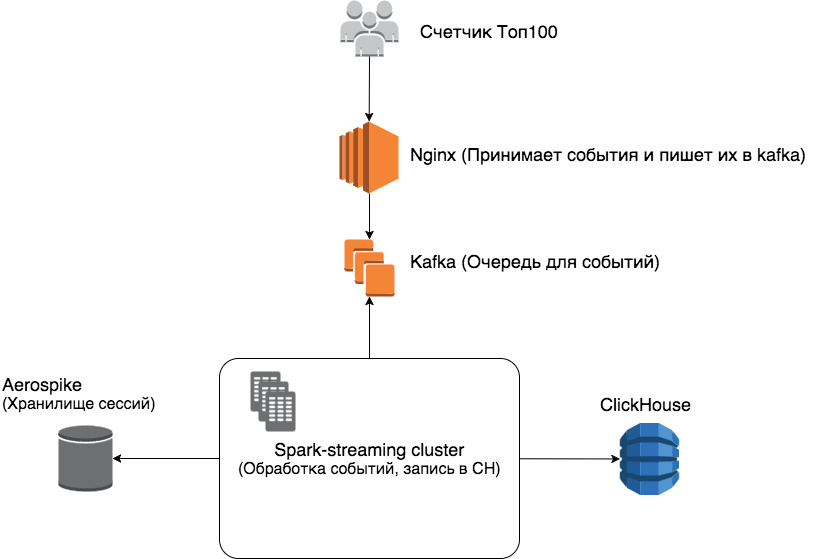
In order.
Nginx - accepts events from visitors to web pages transmitted by the counter, writes them into the event queue.
Kafka is a very fast queue of events, with replication, which can work with several clients at once.
Spark-streaming - performs stream data processing, python-implementation.
Aerospike - Aerospike was chosen as the storage of the sessions because there is a lot of data (on average, the mark is kept at 250-300GB of stored sessions), while Aerospike has a fairly good ratio of the cost of iron to the volume of stored data.
Why Aerospike, because Spark has a checkpoint (built-in storage option for object states)? The fact is that the documentation for checkpoints in Spark is quite raw and uninformative. For example, it is not completely clear how to monitor the expiration of a session’s lifetime, as well as the amount of memory used and the disk for storing checkpoints. Aerospike can automatically delete expired sessions from the box and is relatively easy to monitor and scale.
ClickHouse is a column database and a report building mechanism in one.
A little more about the Spark + Aerospike + Clickhouse combination so that it doesn’t work out like in the old picture.

Events from visitors are read by Spark from Kafka, micro-batch includes 5 minutes of data. Data is grouped by project and unique visitors (cookies) within projects. For each visitor, it is checked whether there is an active session within the framework of this project and, if so, from this session, data are taken for splicing with new data. Sessions and session data are stored in Aerospike with some lifetime. After pasting the sessions, we need to save them in Clickhouse. In this, the CollapsingMergeTree engine is perfect for us: when new data comes to us, we make two entries in Clickhouse - the old one, if it exists, with the (-) sign and the new one (()).
With visitors figured out, now more about the session. For the first event encountered from the visitor, we generate the session_id, save this id and the time of the last event in the Aerospike. All further events within this session are assigned this id. If the time interval between the last session event from Aerospike and the new event is more than 30 minutes, we consider this event the beginning of a new session, and everything starts anew.
This architecture solves all the problems described at the beginning of the article, it scales quite easily and is tested.
To verify that this architecture will work in reality, to keep our intended workload and to respond quickly enough, we conducted three tests:
- Clickhouse load testing with sample data and suggested table schema;
- load testing of the Kafka-Aerospike-ClickHouse bundle;
- We checked a working prototype of the bundle under production load.
All tests ended successfully, we were delighted and started to implement.
Overcoming difficulties
During the implementation of the scheme invented, we naturally met a certain amount of rakes.
Spark
Sometimes not very informative logs, you have to dig into the Spark source code and traceback on Scala. There is no recovery from offset in Kafka from the box, I had to write my bike. In addition, we did not find the normal graceful shutdown mechanism for realtime computing, we also had to write our bicycle (some information about this problem).
Aerospike
While there were no problems, except for a test namespace you need a separate partition on your hard disk.
Clickhouse
Almost no automation of DDL for the cluster (for example, to make an alter table on a distributed table, you need to go to all the nodes and make on each alter table node). Many undocumented functions - you need to go into the code and figure it out or ask the developers of CH directly. Work with replicas and shards is poorly automated, and it is only divided by months.
It's alive, ALIVE!
What happened as a result. The scheme of the base.
CREATE TABLE IF NOT EXISTS page_views_shard( project_id Uint32, page_view_id String, session_id String, user_id String, ts_start Float64, ts_end Float64, ua String, page_url String, referer String, first_page_url String, first_page_referrer String, referer String, dt Date, sign Int8 ) ENGINE=CollapsingMergeTree( dt, sipHash64(user_id), (project_id, dt, sipHash64(user_id), sipHash64(session_id), page_view_id), 8192, sign ); The row in the database schema is a page view with all the parameters associated with it. (The scheme is intentionally simplified, there is not a large number of additional parameters).
We analyze in order:
• dt - date, mandatory requirement for MergeTree tables;
• sipHash64 (user_id) - to support sampling;
• (project_id, dt, sipHash64 (user_id), sipHash64 (session_id), page_view_id) - the primary key by which the data is sorted and by which values are collapsed with a different sign;
• 8192 - index granularity;
• sign - described above.
Examples of requests for one of the projects:
The number of page views and sessions per month, grouped by date.
SELECT SUM(sign) as page_views, uniqCombined(session_id) as sessions, dt FROM page_views WHERE project_id = 1 GROUP BY dt ORDER BY dt WHERE dt >= '2017-02-01' AND dt <= '2017-02-28' FORMAT JSON; 2-5 seconds on full data (127kk lines)
0.5 seconds on sample 0.1
0.1 seconds on sample 0.01

Count all page_views, visits grouped by url.
SELECT SUM(sign) as page_views, uniqCombined(session_id) as sessions, URLHierarchy(page)[1] FROM page_views GROUP BY URLHierarchy(page)[1] ORDER BY page_views DESC WHERE dt >= '2017-02-01' AND dt <= '2017-02-28' and project_id = 1 LIMIT 50 FORMAT JSON; 10 seconds on full data
3-5 seconds on sample 0.1
1.5 seconds on sample 0.01

Kafka
Does not even strain.
Spark
It works quite quickly, lags behind at peak loads, then it is gradually catching up the queue.
ClickHouse, Data Compression
1.5-2TB of data is compressed to 110-150 GB.
ClickHouse, Write Load
1-4 RPS batches with 10,000 entries.
ClickHouse, Reading Load
Currently highly dependent on the requested projects and report type, from 5 to 30 RPS.
Sampling should solve this problem depending on the size of the project and quota.
Results and impressions
Mmm-magic. We rolled out into production the first report working with ClickHouse - “Today is detailed . ” Wishes and constructive criticism are welcome.
To be continued. I would be glad if you write in the comments about what it would be interesting to read in the future: the subtleties of operation, benchmarks, typical problems and ways to solve them, your option.
Source: https://habr.com/ru/post/332202/
All Articles