ArrayBuffer and SharedArrayBuffer in JavaScript, part 3: race streams and Atomics
→ ArrayBuffer and SharedArrayBuffer in JavaScript, Part 1: Short Memory Management Course
→ ArrayBuffer and SharedArrayBuffer in JavaScript, Part 2: Introduction to New Language Objects
→ ArrayBuffer and SharedArrayBuffer in JavaScript, part 3: race streams and Atomics

Last time , considering SharedArrayBuffer, we said that working with this object can lead to a race condition of threads. This complicates development, so we expect that this tool will be used by library creators with experience in multi-threaded programming. They will be able to use the new low-level APIs to create high-level tools that regular programmers will work with, without touching either the SharedArrayBuffer or Atomics.
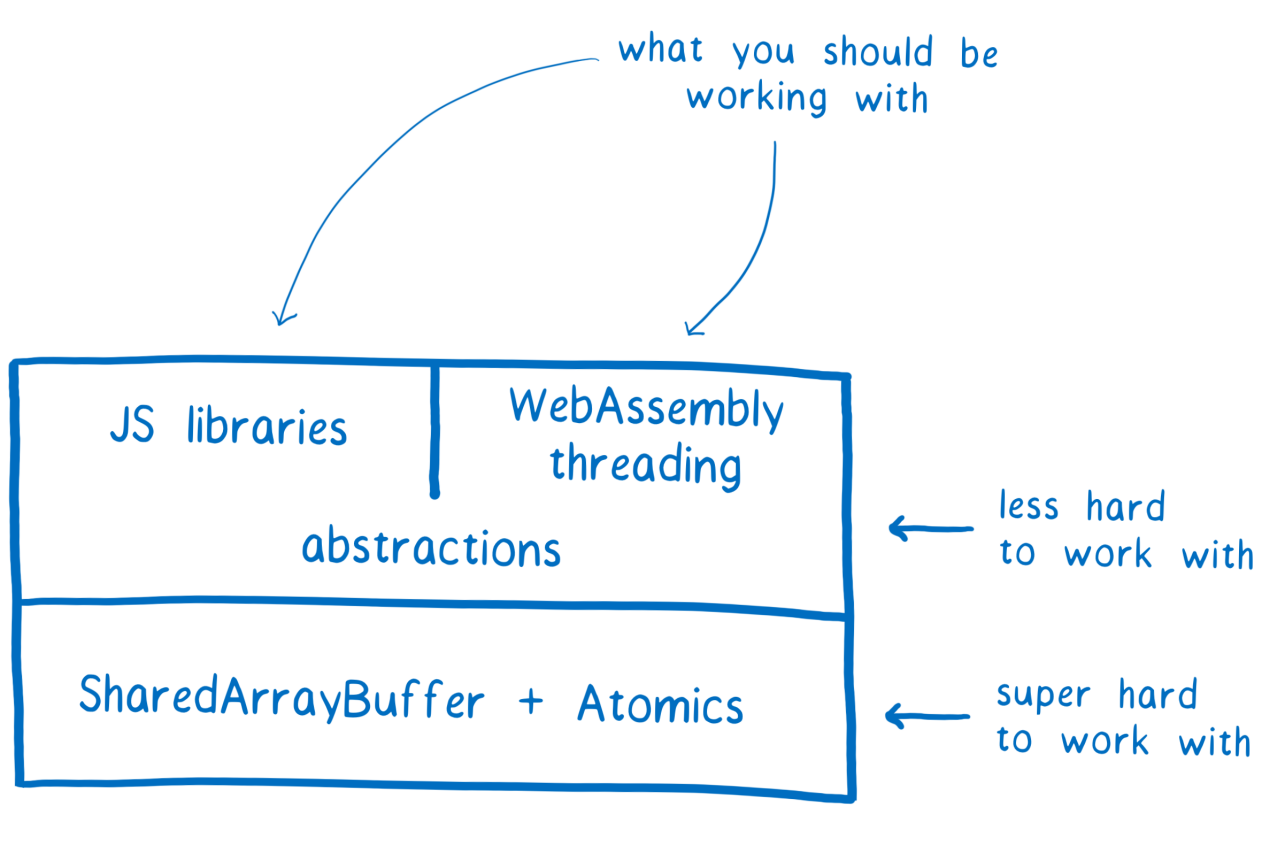
SharedArrayBuffer and Atomics as the basis for multithreading implementation in JS libraries and WebAssembly
If you do not belong to the developers of libraries, then, most likely, you should not work directly with Atomics and SharedArrayBuffer. However, we believe you will be interested to know how it all works. Therefore, in this article we will talk about the state of race races that can occur with multi-threaded programming, and how the use of the Atomics object will help the libraries based on new JS tools to avoid these states.
')
Let's start with a more detailed discussion of what race is.
Race Race: a classic example
A race race condition may occur in a situation where there is a variable that two threads have access to. Suppose the first thread, based on the value of the
fileExists variable, loads a certain file, and the second checks whether the file exists and, if so, sets this variable to true . We do not go into the details, the code for checking the presence of the file is omitted.Initially, the variable that processes use to exchange data is set to
false .
The first thread, on the left, loads the file, if the fileExists variable is set to true, the second thread, after checking the existence of the file, sets this variable to true
If the code in the second thread is executed first, sets the variable to true, the first thread will load the file.

First, the second thread sets the variable to true, then the second thread loads the file.
However, if the code in the first thread is executed first, it will display an error message containing information that the file does not exist.

If at first, when the variable is still set to false, the code in the first thread is executed, an error message is displayed
In fact, the problem is not that the file could not be found. In our very simplified case, the real cause of the error message is the racetrack state.
Many JS developers face a race condition of this kind, even in single-threaded code. And, in fact, you do not need to know anything about multithreading in order to see why such errors occur.
However, there are some types of race streams that are not possible in single-threaded code, but can occur when developing multi-threaded programs whose streams use shared memory.
Different types of racing streams and Atomics
Let's talk about the different types of race streams that can be encountered in multi-threaded code, and how Atomics can help prevent them. It should be noted that here we are not trying to consider absolutely all possible states of racing, but this review will help you understand why certain methods are provided for in the Atomics API.
Before we begin, I would like to remind again, turning to ordinary developers, that it is not expected that they will directly use the capabilities of Atomics. Multithreaded development is characterized by increased complexity, we believe that new creators of libraries will mostly use the new JavaScript tools.

Multithreaded programming carries many dangers
Now proceed to the story of the states of racing.
Race streams when processing a single operation
Suppose there are two threads that increment the same variable. At first glance it may seem that there is nothing dangerous here, that the result of several similar operations will be the same, regardless of which thread will increase the variable first.
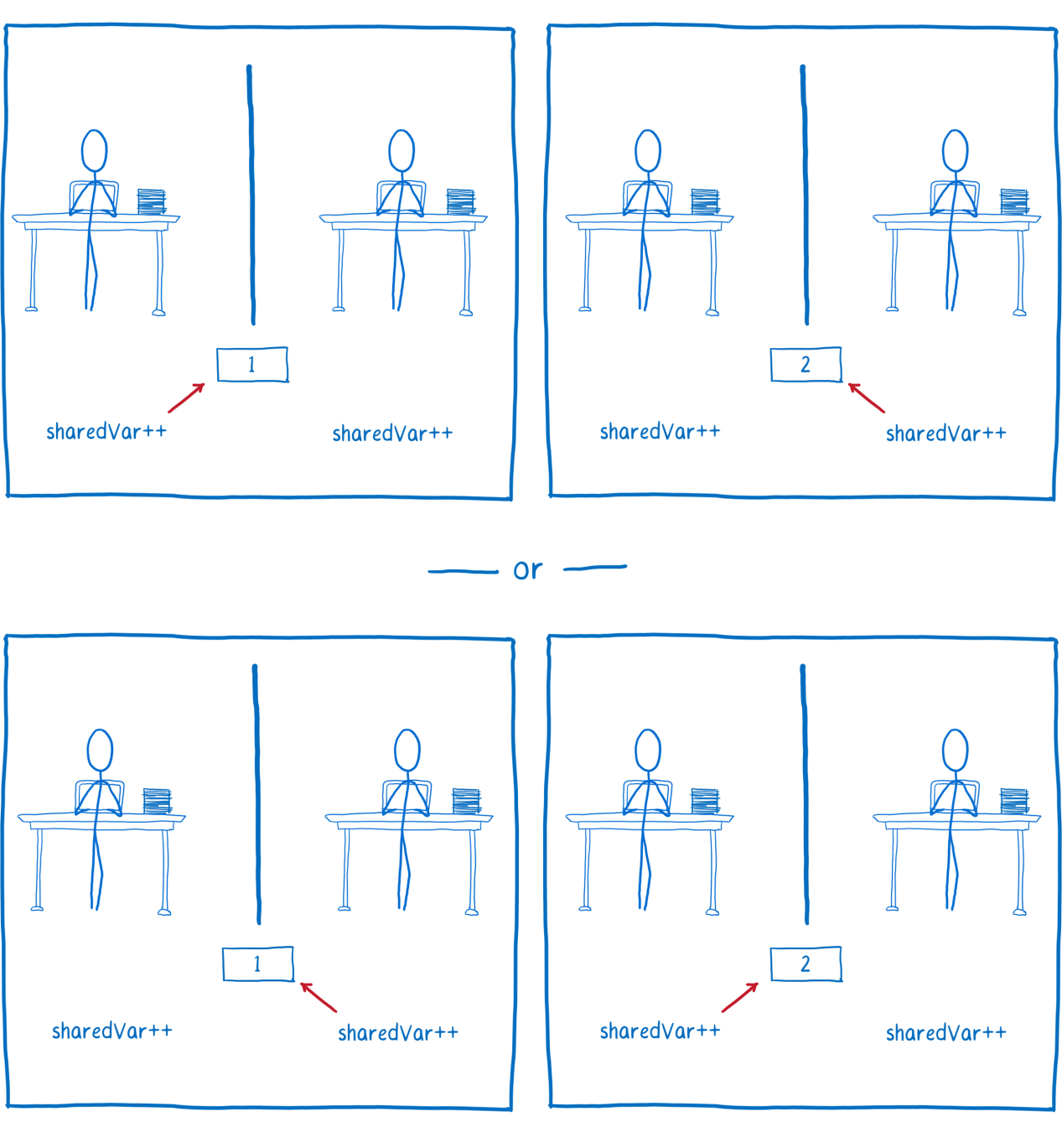
Two threads increment the variable
Although, in the JS program, incrementing looks like a single operation, if you look at the compiled code, it turns out that we have several operations in front of us. The processor, to increment a variable, must perform three operations.
The point here is that the computer has different types of memory. In this case, we are talking about the usual RAM, which stores data for a relatively long time, and the processor registers, which are used for short-term data storage.
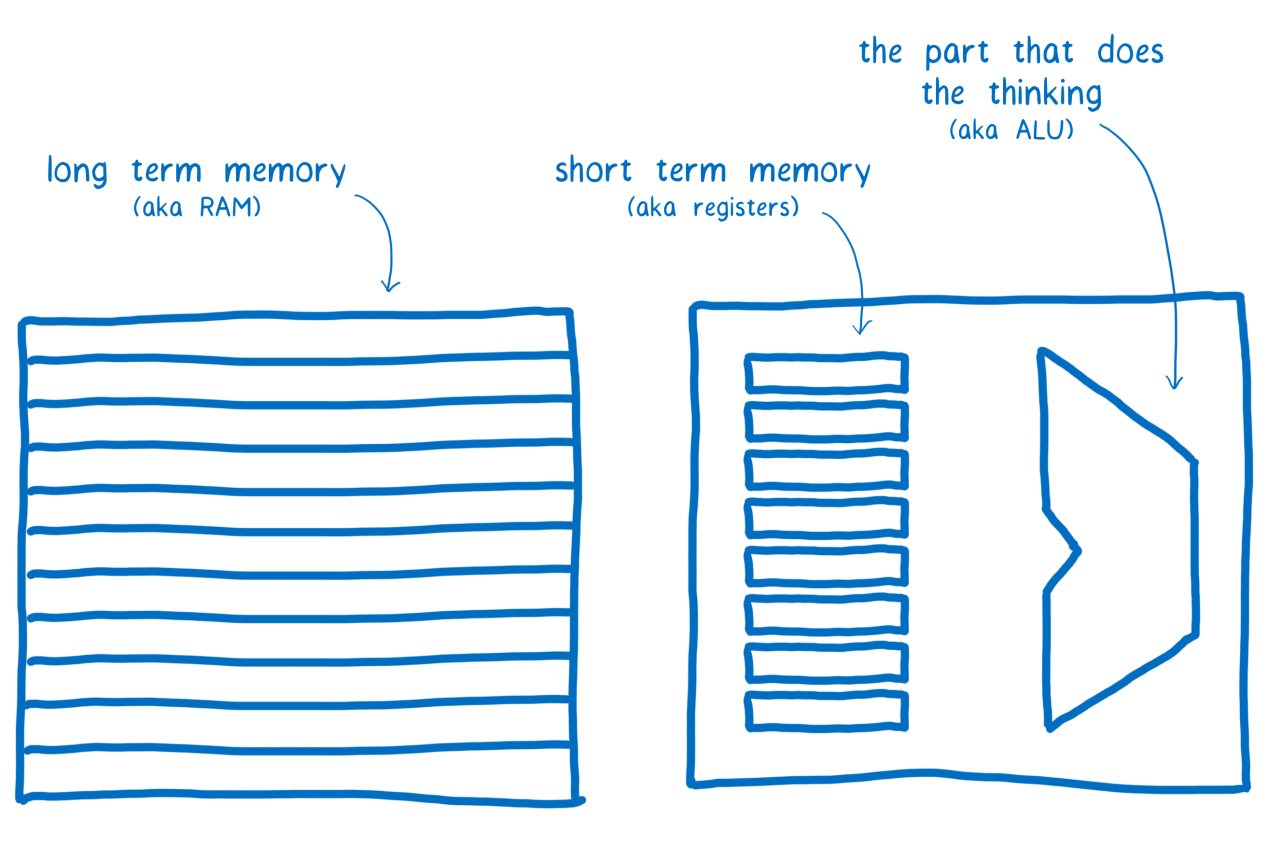
RAM, processor registers and arithmetic logic unit
Our two threads have shared RAM, but not processor registers. Each thread, to perform certain actions with data, you must first transfer them from RAM to registers. Then - to perform calculations, and after that - to return the data back into RAM.
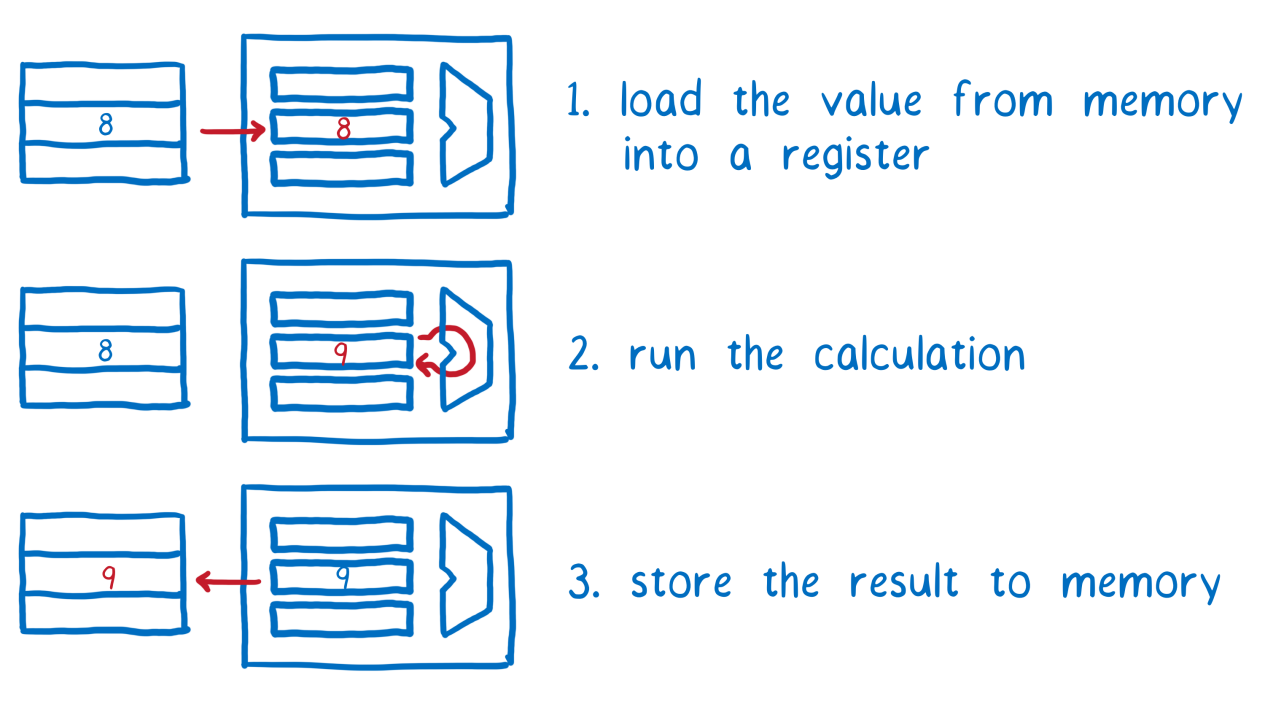
Perform actions with data stored in RAM. The first step is to load data from memory into the register. The second is the execution of calculations. The third is to save the result of calculations in RAM
If all the necessary low-level operations are first performed by the first thread and then by the second, we will get the expected result.
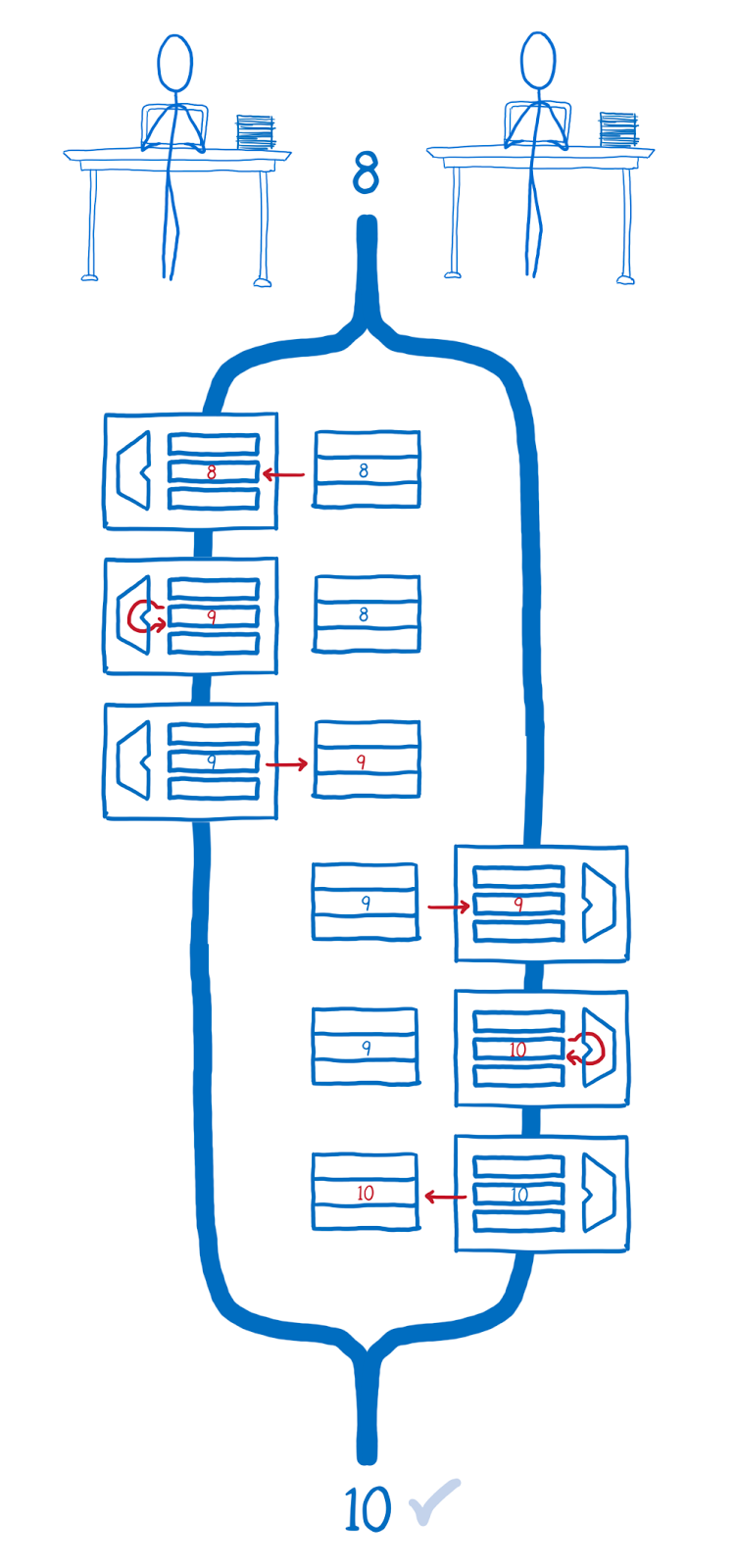
First, all operations on incrementing the variable are performed by the first thread, then - the second
But what if the operations in which the registers are involved are executed in such a way that one of them starts before the other ends? This will lead to a violation of the synchronization of the state of the registers and RAM. For example, it may happen that one of the streams does not take into account the results of the calculations of the other and overwrites with its data what it has written into memory.
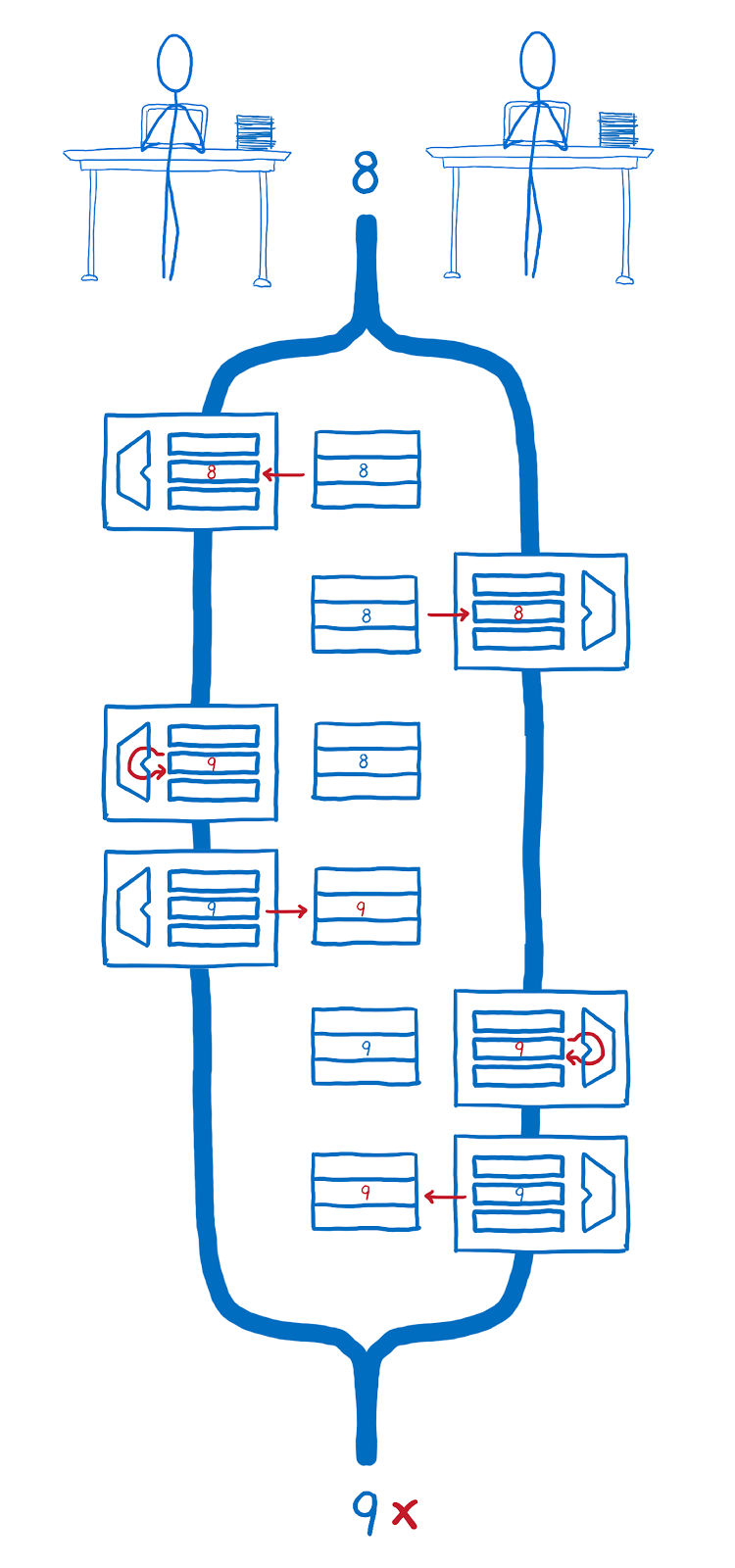
Race streams and register operations
Such situations can be avoided by implementing the so-called “atomic operations”. The point here is that what looks like a single operation to a programmer and a few to a computer looks like a single operation to a computer.
Atomic operations allow you to turn certain actions, which can include many processor instructions, into something like a single indivisible instruction. This atomic "instruction" preserves the integrity even if the execution of the commands of which it is composed is suspended, and, after a while, resumes. Atomic operations are sometimes compared with atoms.
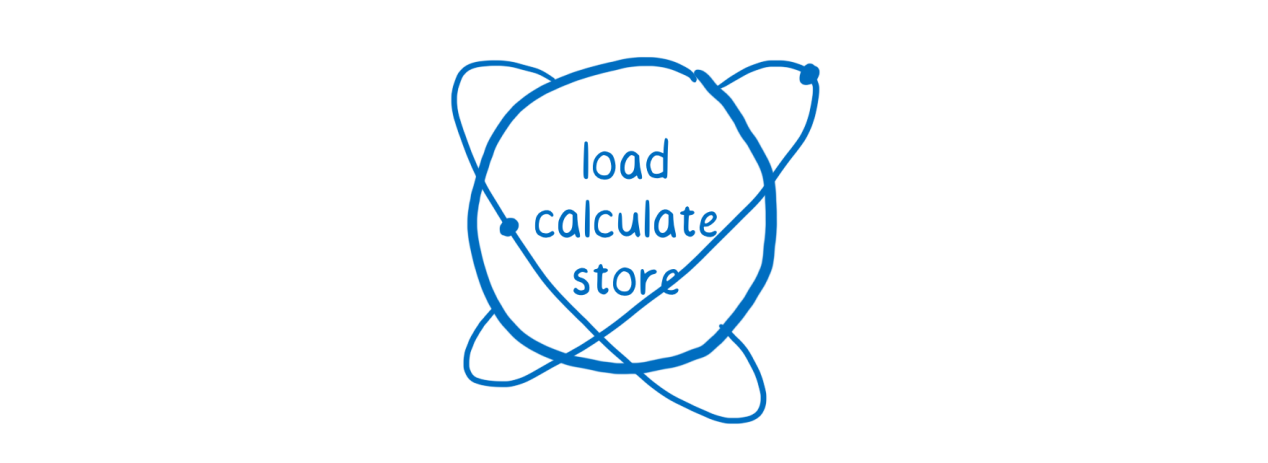
A set of instructions that form an atomic operation
Using atomic operations, the code for incrementing a variable will look different. Instead of the usual
sharedVar++ this would be something like Atomics.add(sabView, index, 1) . The first argument to the add method is the data structure for accessing the SharedArrayBuffer ( Int8Array , for example). The second is the index by which sharedVar is in the array. The third argument is a number to add to the sharedVar .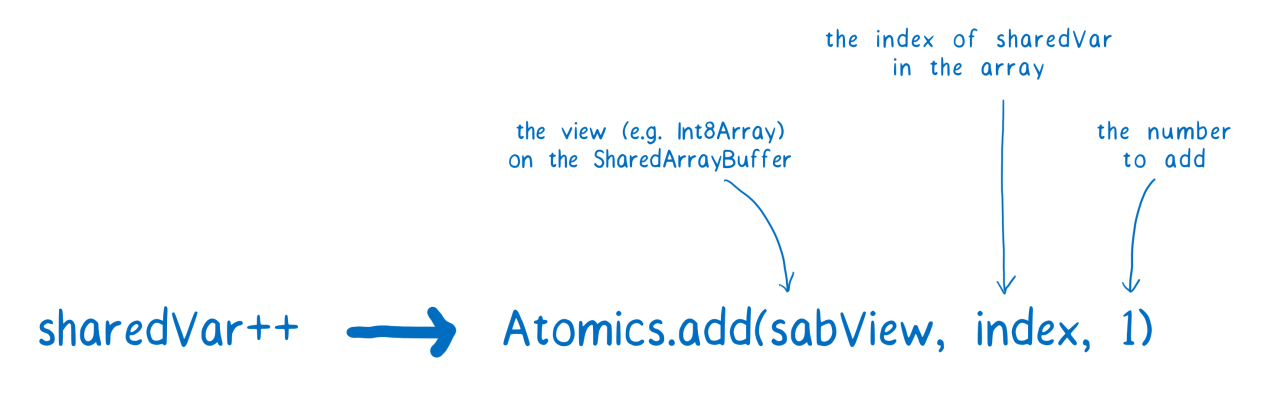
Atomic operation, which allows to increase the variable by 1
Now, when we use the
Atomics.add method, processor actions related to incrementing a variable by a command from one thread are not mixed with operations initiated from another thread. Instead, first all the necessary actions, within the framework of one atomic operation, are performed by the first thread, after which the operations of the second stream are performed, again, enclosed in an atomic operation.
First, the instructions needed to increment the variable are executed by the first thread, then the second
Here are Atomics methods that help to avoid racing conditions when performing individual operations.
You may notice that this list is rather limited. In it, for example, there are no methods for performing division or multiplication. However, developers of auxiliary libraries can independently implement atomic methods for performing various operations.
To implement such things, you can use the Atomics.compareExchange method. Using this method, you can read a certain value from the SharedArrayBuffer, perform some actions with it and write back only if it was not changed by another thread while performing actions with it. If, when attempting to write, it turned out that the value in the SharedArrayBuffer has changed, the recording is not performed, you can instead take the new value and try the same operation again.
Race status when performing multiple operations
Atomic operations, which we talked about above, make it possible to avoid the state of racing when performing single commands. However, sometimes it is necessary to change several values in the object (using several operations) and to be sure that no one else will try to change these values at the same time. In general, this means that, during each session of updating the state of an object, the object must be blocked and inaccessible to other threads.
The Atomics object does not provide tools that allow you to directly implement such functionality, but it provides tools that library developers can use to create mechanisms to perform such operations. This is about creating high-level locking tools.
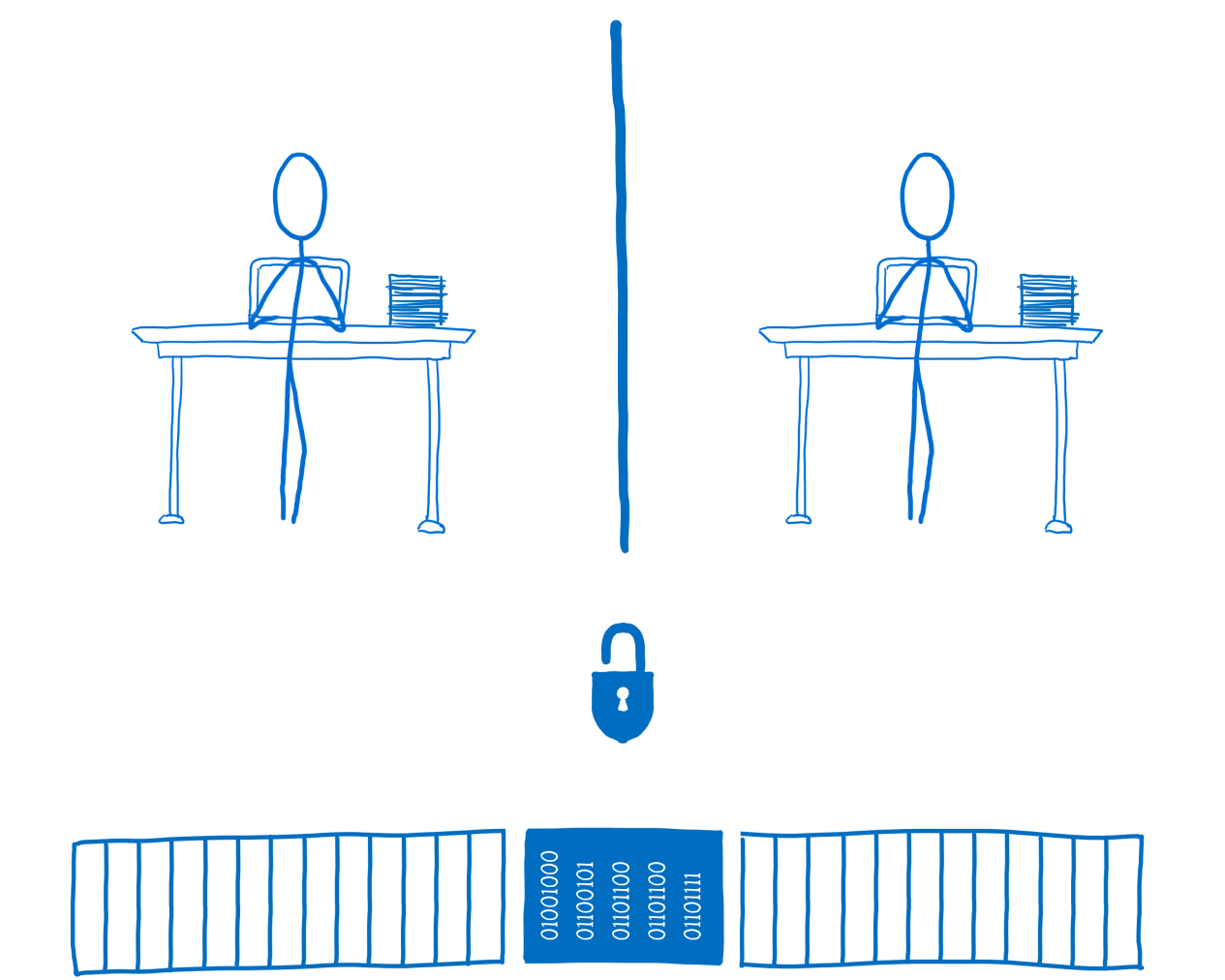
Two threads, shared memory and lock
If the code wants to use shared data, it must acquire the lock. In the picture above, none of the threads blocked the common memory area; this is represented as an open lock. Once captured, a stream can use a lock to protect data from other threads. Only he can access this data or change it while the lock is active.
In order to create a blocking mechanism, library authors can use the methods Atomics.wait , and Atomics.wake , as well as the methods Atomics.compareExchange and Atomics.store . Here you can look at the basic implementation of such a mechanism.
With this approach, shown in the following figure, stream # 2 will lock the data lock and set the value of
locked to true . This means that stream # 1 cannot access data until stream # 2 unlocks them.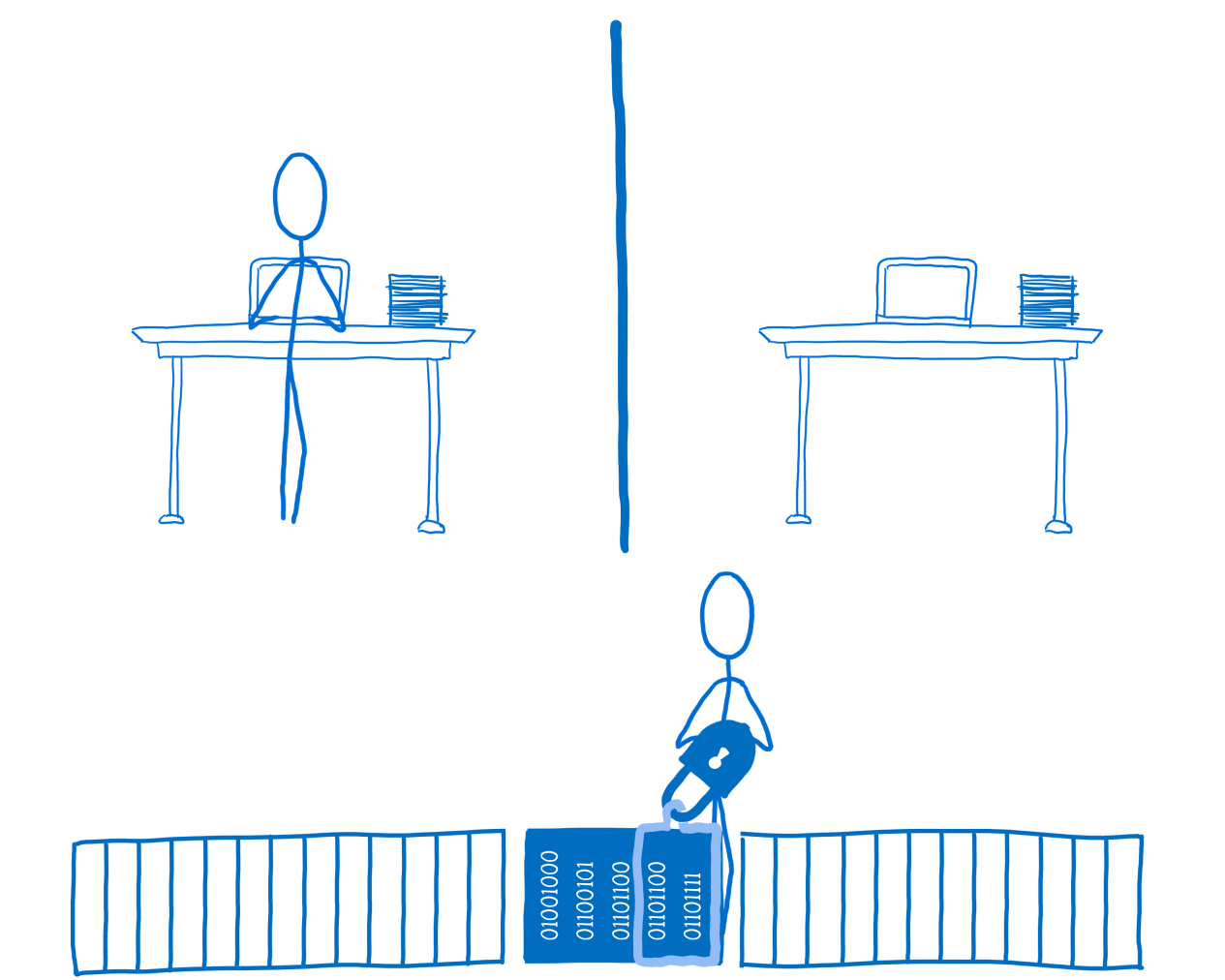
Stream # 2 blocks data
If stream 1 needs access to the data, it will try to lock the lock. But since the lock is already in use, it cannot do this. Therefore, the thread will have to wait until the data is unlocked.
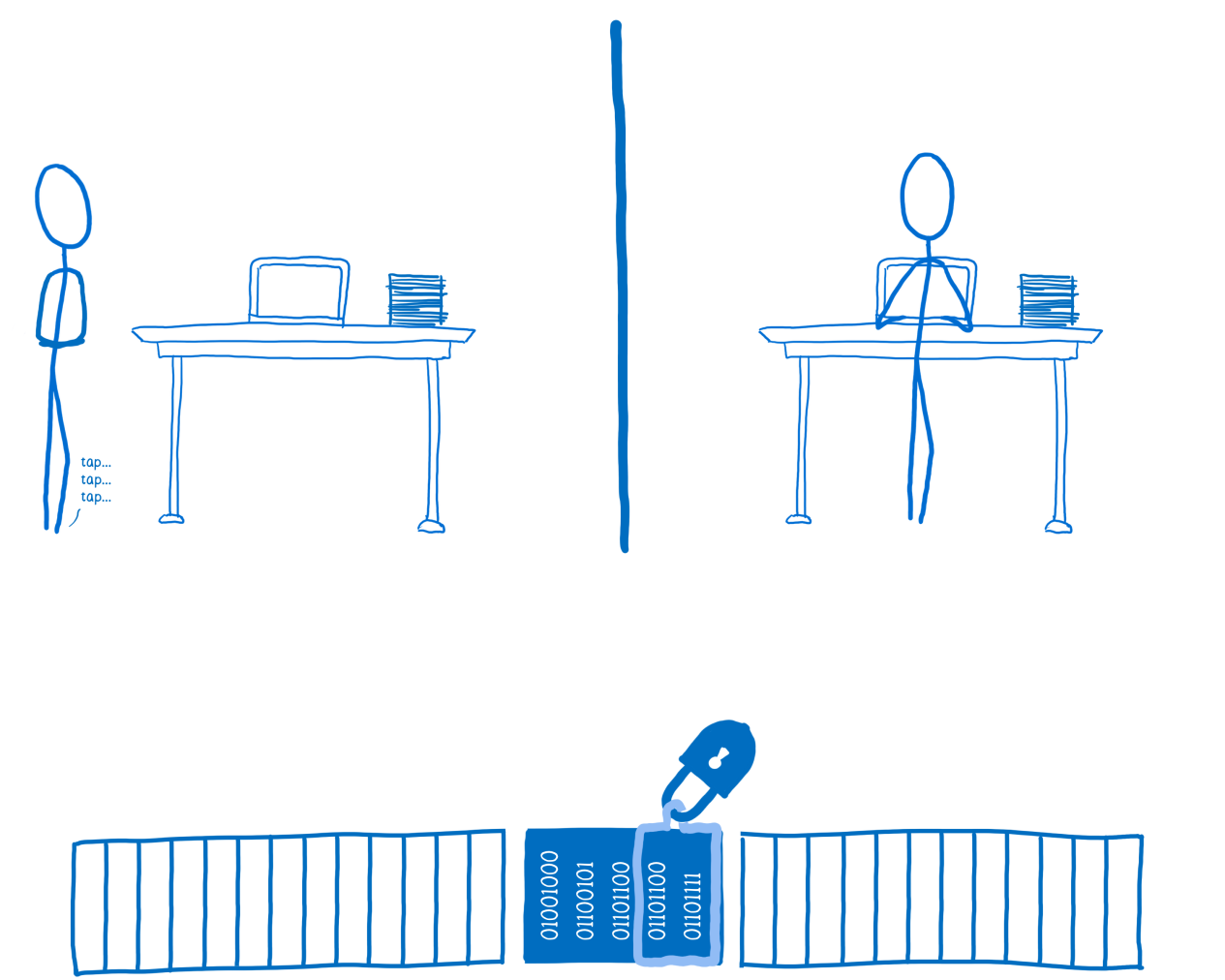
Stream # 1 is waiting for the lock to be released.
As soon as the flow number 2 is completed, it will remove the lock. After this, the locking mechanism will notify the pending threads that they can acquire the lock.
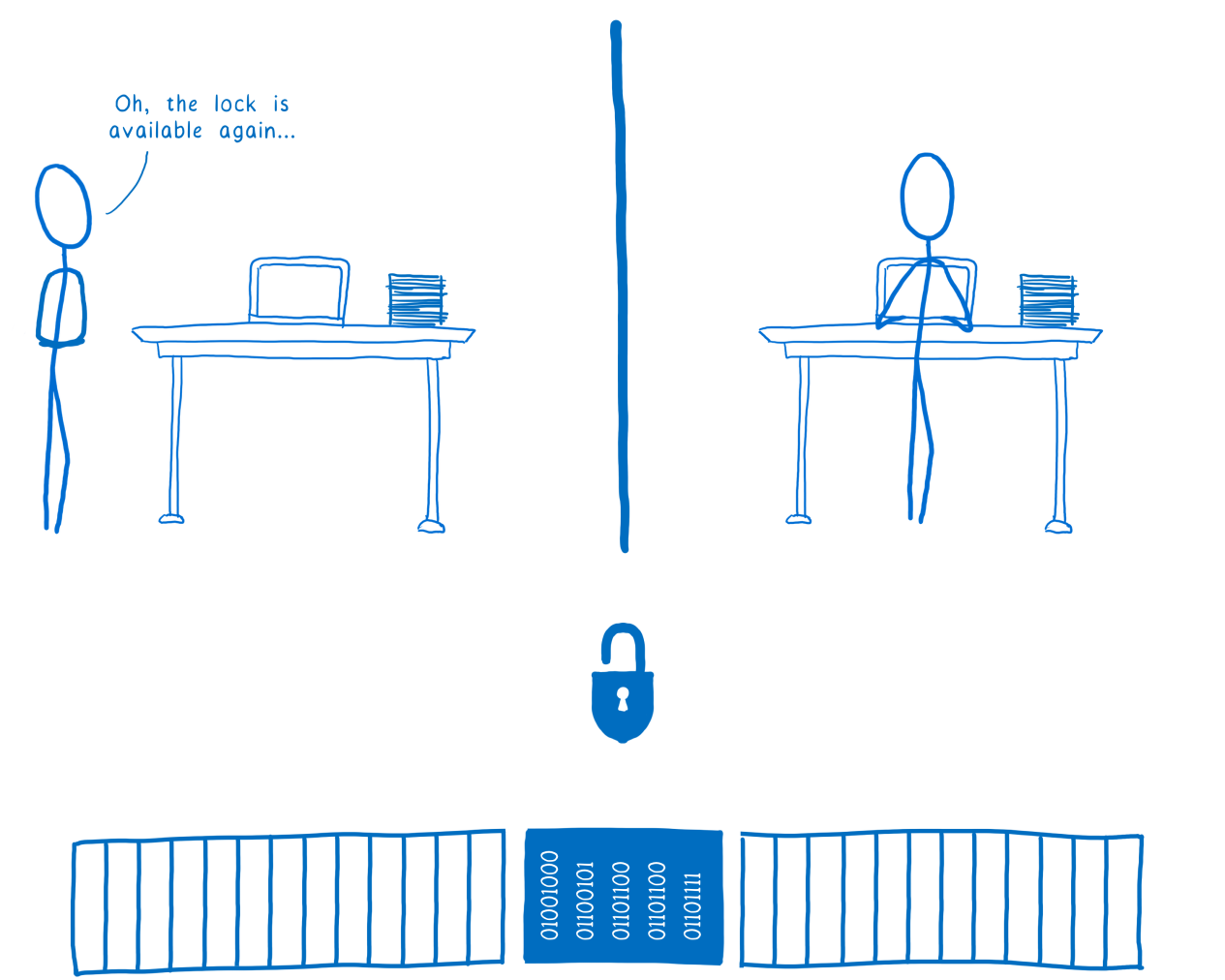
Stream # 1 received an alert that the lock was released
Now stream # 1 can lock and block data for its own use.
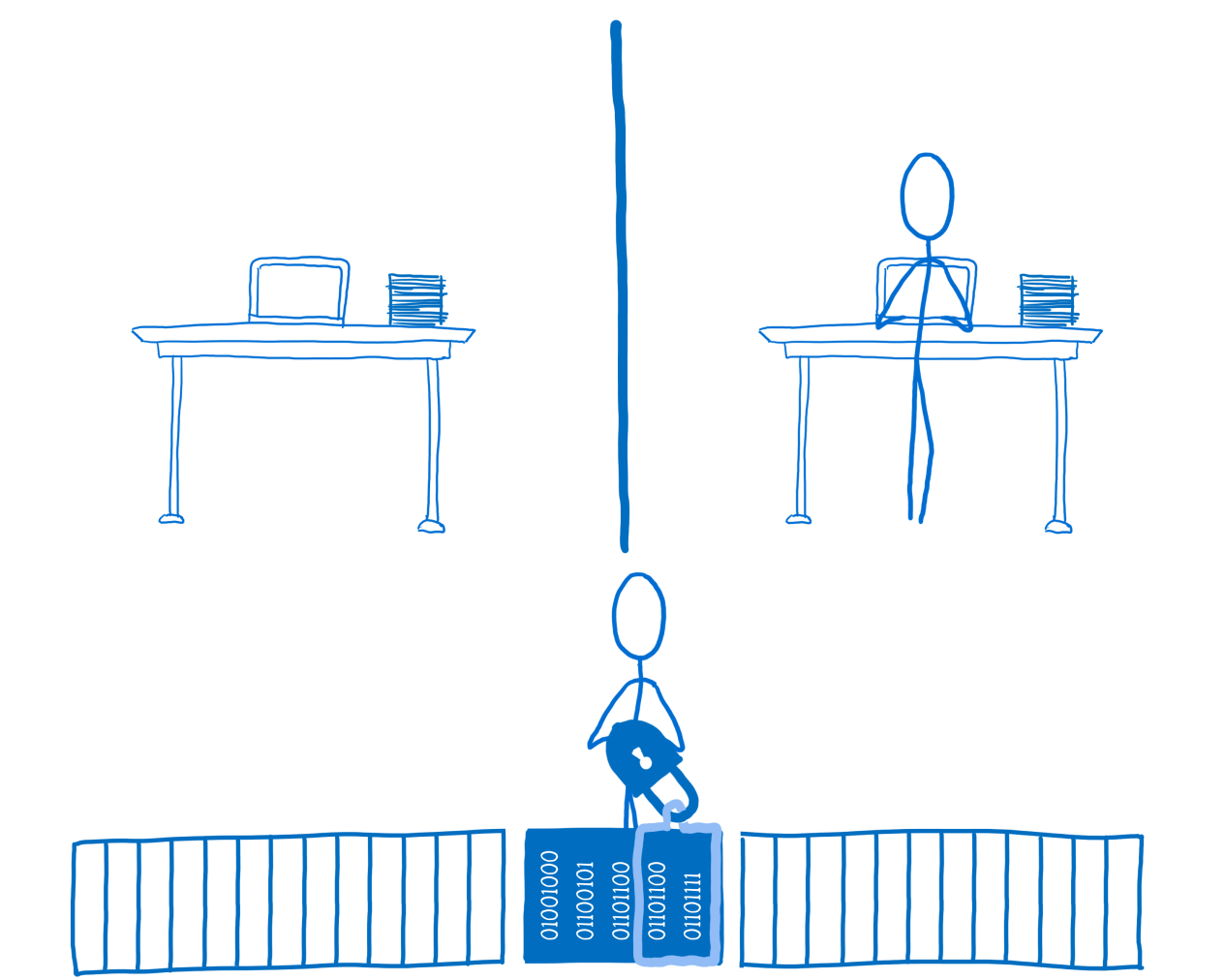
Stream # 1 locks data
A library that implements the locking mechanism could use various methods of the Atomics object, however, the most important ones are Atomics.wait and Atomics.wake .
Race condition caused by changing the order of operations
Here is the third synchronization problem in which the Atomics object can help. For some, it may be a complete surprise.
You may not know this, but there is a great chance that the commands of the program written by you will not be executed in the order in which they go in the code. Both compilers and processor change the order in which the code is executed in order to use computer resources more efficiently.
For example, suppose a certain function was written, the code of which calculates the total amount of a check. After completing the calculations, we set the appropriate flag.

A snippet of code that performs the calculation of the total amount and sets a flag signaling the end of the operation
In order to compile this, the system must decide which register to use for each variable. After that, the JS code can be translated into machine instructions.

A simplified example of converting JS code to machine instructions
So far, everything looks as expected.
For those who are not very well versed in how the computer works at the hardware level, how the pipelines are used, which are used to execute the code, it may not be entirely obvious that the machine will have to wait a little before executing the second line of our code.
Most computers break down the process of executing instructions into several steps. This allows for the constant loading of all the processor mechanisms, which makes it possible to effectively use the resources of the machine.
Here is a description of the steps that make up the instruction.
Stage # 1
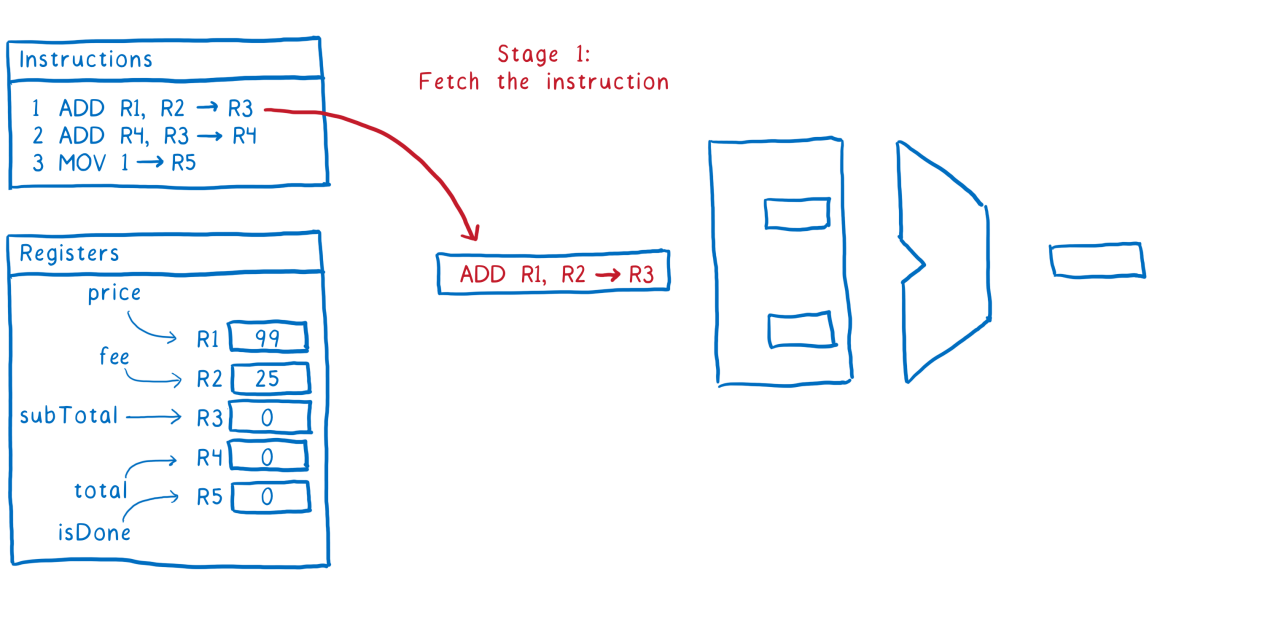
Sampling instructions from memory
Stage 2
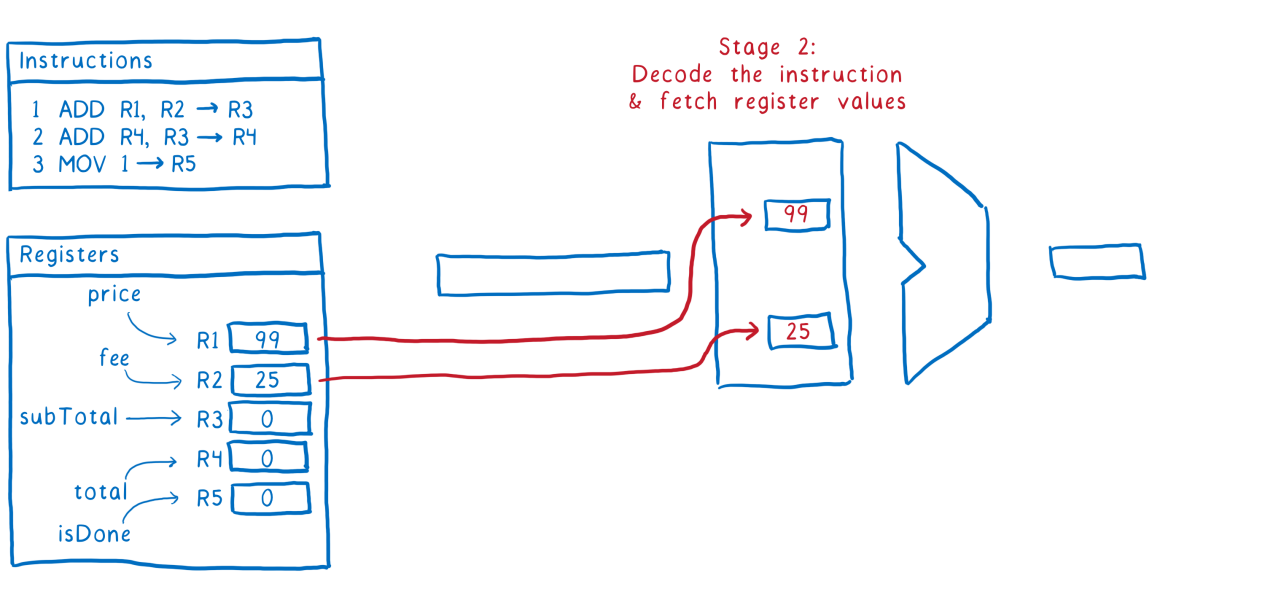
Decoding instructions, that is, finding out exactly what actions need to be performed to execute this instruction, and loading the necessary data from the registers
Stage 3
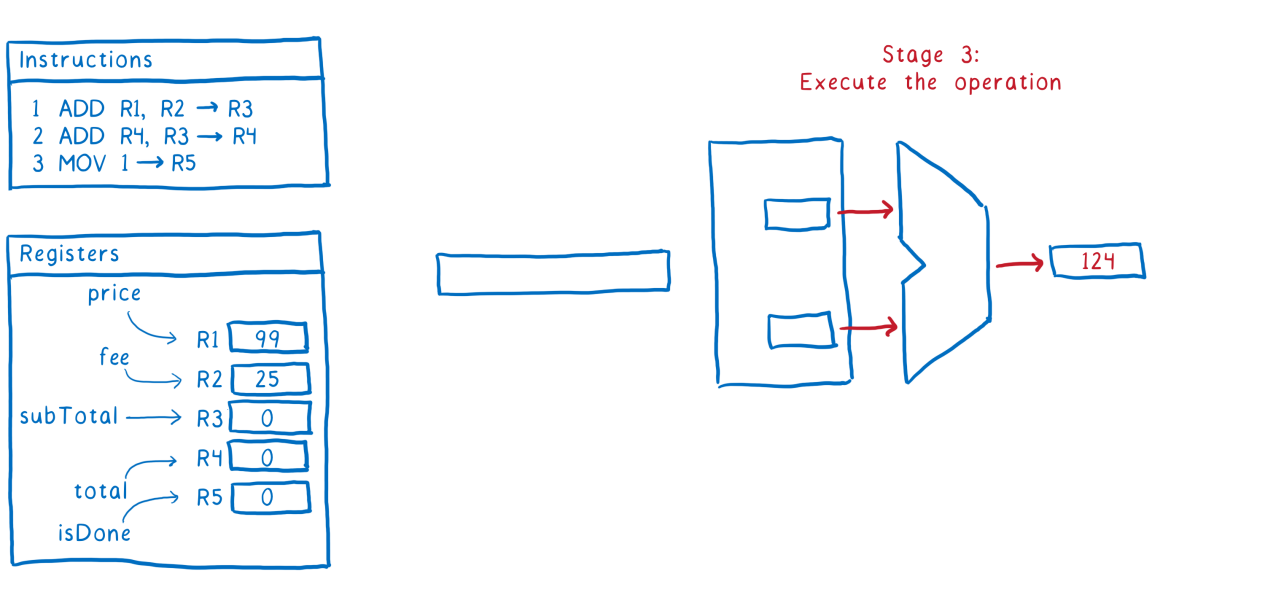
Execution of instructions
Stage 4

Write the results of the execution of instructions in the registers
Here, very simply, the path that the first instruction follows. Ideally, we would like the second instruction to follow immediately after the first one. That is, as soon as the first instruction proceeds to step # 2, step # 1 is performed for the second instruction, and so on.
The problem is that instruction number 2 depends on instruction number 1.

Instructions # 2 need to get the value of the variable subTotal from R3, but instruction # 1 has not yet written down the result of the calculations.
In this situation, you can pause processor processing of instructions until instruction # 1 updates the value of the
subTotal variable in the register. However, with this approach, performance will suffer.In order to use system resources efficiently, many compilers and processors change the order of operations. Namely, in our case, we search for instructions that do not use the variables
subTotal and total , and execute these instructions between instructions No. 1 and No. 2, which follow each other in the code.
Changing the order of instructions, instruction number 3 will be executed between instructions number 1 and number 2
This allows, ideally, not to interrupt the flow of instructions following the pipeline.
Since the third line of code does not depend on either the first or the second, the compiler or processor can decide that it is safe to change the order of instructions. When all this happens in single-threaded mode, inside a function, another code will not access these values until the entire function completes.
However, if there is another thread running in parallel, everything changes. It is not necessary for another thread to wait until the function terminates, in order to know the state of the variables. These changes may be noticed by another stream almost immediately after they occur. As a result, it appears that the
isDone flag, visible to another thread, will be set before the completion of the calculations. codeisDone as a flag indicating that the total calculation is completed, and the resulting value is ready for use in another thread, changing the order of operations will lead to a race condition of the threads.The Atomics object is trying to solve some of these oddities. In particular, the use of an atomic write operation resembles the installation of a fence between two code fragments. Separate atomic operations instructions do not mix with other operations. In particular, here are two operations that are often used to ensure that operations are performed in order:
If some variable is updated in the JS function code above the
Atomics.store , it will be guaranteed to be completed before Atomics.store stores the value of the variable in memory. Even if the order of execution of non-atomic instructions is changed with respect to each other, none of them will be moved below the Atomics.store call, located at the bottom of the code.Similarly, loading a variable after calling
Atomics.load guaranteed to be executed after Atomics.load its value. Again, even if the order of execution of non-atomic instructions is changed, none of them will be moved in such a way that it will be executed before Atomics.load , which is located in the code above it.
Updating the variable above Atomics.store is guaranteed to be completed before the completion of Atomics.store. The variable loading below Atomics.load is guaranteed to be executed after Atomics.load completes
Notice that the
while in this example implements a circular lock; this is a very inefficient construct. If something like this happens to be in the main application thread, the program may simply hang. In real code, almost certainly, cyclic locks should not be used.Results
Multi-threading programming with shared memory is not an easy task. There are many situations that can cause a race race condition. They, like dragons, await inexperienced developers in the most unexpected places.

Multi-threaded shared memory programming is full of hazards
We, in this series of three materials, constantly said that new language tools allow library developers to create simple, convenient and reliable tools designed for ordinary programmers. The SharedArrayBuffer and Atomics path in the JavaScript universe is just beginning; therefore, libraries based on them have not yet been created. However, now the JS-community has everything you need to develop such libraries.
Dear readers! If you are one of those highly-skilled programmers who know first-hand about multi-threading, based on which SharedArrayBuffer and Atomics are created, you are sure that many beginners will be interested to know which direction to take in order to become a developer of high-quality libraries implementing parallel computing . Share, please, experience.
Source: https://habr.com/ru/post/332194/
All Articles