Classifying Text with Java Neural Network
“Our Lena is going on maternity leave,” the boss said, “so we need to look for a replacement for the time of her absence. We will distribute part of the tasks, but what about the task of redirecting user requests?
Lena is our technical support officer. One of her responsibilities is the distribution of requests received by e-mail among specialists. It analyzes the circulation and determines a number of characteristics. For example, "Type of treatment": a system error, the user just needs a consultation, the user wants some new functionality. Defines the "Functional module of the system": the accounting module, the module certification of equipment, etc. Putting all these characteristics, she redirects the appeal to the appropriate specialist.
- Let me write a program that will do this automatically! - I replied.
')
At this fascinating novel we end and turn to the technical part.
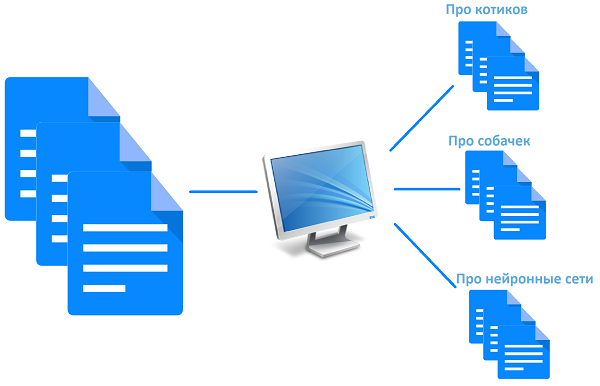
Having formalized the task and started developing for our specific needs, I realized that it would be better to develop a universal tool right away that would not be rigidly tied to any specific characteristics and the number of these characteristics. As a result, a tool was born that can classify text according to arbitrary characteristics.
I did not begin to look for ready-made solutions, because there was time and interest to make on my own, immersing in parallel the study of neural networks.
I decided to develop in Java.
I used SQLite and H2 as a DBMS. Also useful Hibernate .
From here I took a ready implementation of the neural network (Encog Machine Learning Framework). I decided to use the neural network as a classifier, and not, for example, the naive Bayes classifier , because, firstly, theoretically, the neural network should be more precise. Secondly, I just wanted to play around with neural networks.
To read the Excel data file, some Apache POI libraries were needed for training.
Well, for tests, I traditionally used JUnit 4 + Mockito .
I will not describe the theory in detail on neural networks, as there is plenty of it ( there is a good introduction material here). In short and in a simple way: the network has an input layer, hidden layers and an output layer. The number of neurons in each layer is determined by the developer in advance and, after learning the network, cannot be changed: if at least one neuron is added / subtracted, then the network must be retrained. For each neuron of the input layer, a normalized number (usually from 0 to 1) is fed. Depending on the set of these numbers on the input layer, after certain calculations, on each output neuron, we also get a number from 0 to 1.
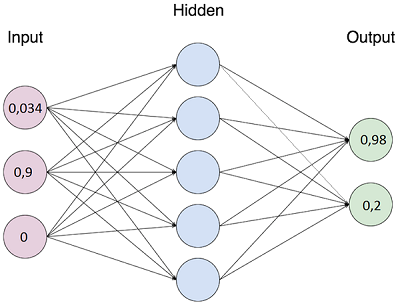
The essence of network training is that the network adjusts its link weights involved in the calculations, so that when a set of numbers on the input layer is known in advance, a set of numbers on the output layer will be known in advance. Adjusting the weights is an iterative process and occurs until the network reaches the specified accuracy on the training set or until it reaches a certain number of iterations. After training, it is assumed that the network will produce a close to the reference set of numbers on the output layer, if the input set file numbers, similar to the one that was in the training set.
The first task was to figure out how to convert the text to a form that can be transmitted to the input of a neural network. But first it was necessary to determine the size of the input layer of the network, since it must be specified in advance. Obviously, the input layer must be of such a size that any text can be “fit” into this layer. The first thing that comes to mind is that the size of the input layer should be equal to the size of the dictionary containing the words / phrases of which the texts consist.
There are many ways to build a dictionary. You can, for example, stupidly take all the words of the Russian language and this will be our dictionary. But this approach is not suitable, because the size of the input layer will be so huge that there will not be enough resources for a simple workstation to create a neural network. For example, imagine that our dictionary consists of 100,000 words, then we have 100,000 neurons in the input layer; for example, 80,000 in a hidden layer (the method for determining the dimension of a hidden layer is described below) and 25 in the output layer. Then, just to store the link weights, you will need ~ 60 GB of RAM: ((100,000 * 80,000) + (80,000 * 25)) * 64 bits (type double in JAVA). Secondly, such an approach is not suitable, because the texts can use specific terminology, which is absent in dictionaries.
This suggests the conclusion that the dictionary should be built only from those words / phrases that our analyzed texts consist of. It is important to understand that in this case there must be a sufficiently large amount of training data to build the dictionary.
One of the ways of “pulling out” words / phrases (even more precisely, fragments) from the text is called building an N-gram . The most popular are unigrams and bigrams. There are also character N-grams - this is when the text is divided not into separate words, but into segments of characters of a certain length. It is difficult to say in advance which of the N-grams will be more effective in a specific task, so you need to experiment.
I decided to move from simple to complex and first developed the Unigram class.
As a result, after processing ~ 10,000 texts, I received a dictionary of ~ 32,000 elements. Having analyzed the resulting dictionary diagonally, I realized that there is a lot of superfluous in it, which we should get rid of. To do this, do the following:
All this is implemented in the classes FilteredUnigram and VocabularyBuilder.
Example of compiling a dictionary:
To build Bigrams, I also wrote a class right away, so that after the experiments, to stop the choice on the variant that gives the best result in terms of the dictionary size and classification accuracy.
I have decided to stop at this for now, but further processing of words for compiling a dictionary is also possible. For example, you can define synonyms and bring them to a single form, you can analyze the similarity of words, you can even invent something of your own, etc. But, as a rule, this does not give a significant increase in the accuracy of the classification.
Okay, go ahead. The size of the input layer of the neural network, which will be equal to the number of elements in the dictionary, we calculated.
The size of the output layer for our task will be equal to the number of possible values for the characteristic. For example, we have 3 possible values for the "Type of address" characteristic: system error, user assistance, new functionality. Then the number of neurons in the output layer will be three. When training the network, for each value of the characteristic it is necessary to determine in advance the reference unique set of numbers that we expect to receive on the output layer: 1 0 0 for the first value, 0 1 0 for the second, 0 0 1 for the third ...
As for the number and dimension of hidden layers, then there is no specific recommendation. The sources say that the optimal size for each specific task can be calculated only experimentally, but for a narrowing network it is recommended to start with one hidden layer, the size of which varies between the size of the input layer and the output layer. To begin with, I created one hidden layer of 2/3 in size from the input layer, and then I experimented with the number of hidden layers and their sizes. Here you can read a little theory and recommendations on this issue. It also describes how much data there should be for training.
So, we have created a network. Now we need to decide on how we will convert the text into figures suitable for “feeding” the neural network. To do this, we need to convert the text into a text vector . First you need to assign each word in the dictionary a unique word vector , the size of which should be equal to the size of the dictionary. After learning the network to change the vector for words can not. Here’s how it looks for a 4-word dictionary:
The procedure of converting text into a vector of text implies the addition of vectors of words used in the text: the text “how do you say hello?” Will be converted into a vector “1 1 0 1”. We can already feed this vector to the input of the neural network: each individual number for each individual neuron of the input layer (the number of neurons is just equal to the size of the text vector).
Here and here you can additionally read about the preparation of the text for analysis.
Having experimented with different dictionary formation algorithms and with different number and dimension of hidden layers, I stopped at this option: use FilteredUnigram with cutting off rarely used words to form a dictionary; we make 2 hidden layers with the dimension 1/6 of the dictionary size - the first layer and 1/4 of the size of the first layer - the second layer.
After training on ~ 20,000 texts (and this is very small for a network of this size) and on the network run of 2,000 reference texts, we have:
This is accuracy for one feature. If accuracy is needed for several characteristics, the calculation formulas are as follows:
Example:
Assume that the accuracy of determining one characteristic is 65%, the second characteristic is 73%. Then the accuracy of determining both at once is equal to 0.65 * 0.73 = 0.4745 = 47.45% , and the accuracy of determining at least one characteristic is 1- (1-0.65) * (1-0.73) = 0 , 9055 = 90.55% .
It is quite a good result for a tool that does not require preliminary manual processing of incoming data.
There is one “but”: the accuracy strongly depends on the similarity of texts that should be assigned to different categories: the less similar the texts from the “System Errors” category are to the texts from the “Need Help” category, the more accurate the classification will be. Therefore, with the same network and dictionary settings in different tasks and on different texts there can be significant differences in accuracy.
As already said, I decided to write a universal program that is not tied to the number of characteristics by which the text should be classified. I will not describe in detail all the details of the development here, I will describe only the algorithm of the program, and the link to the sources will be at the end of the article.
The general algorithm of the program:
In the plans:
Sources can be useful as an example of using some design patterns. There is no sense in putting it into a separate article, but I don’t want to be silent about them, since I share my experience, so let it be in this article.
Full source code: https://github.com/RusZ/TextClassifier
Constructive suggestions and criticism are welcome.
PS: Do not worry about Lena - this is a fictional character.
Lena is our technical support officer. One of her responsibilities is the distribution of requests received by e-mail among specialists. It analyzes the circulation and determines a number of characteristics. For example, "Type of treatment": a system error, the user just needs a consultation, the user wants some new functionality. Defines the "Functional module of the system": the accounting module, the module certification of equipment, etc. Putting all these characteristics, she redirects the appeal to the appropriate specialist.
- Let me write a program that will do this automatically! - I replied.
')
At this fascinating novel we end and turn to the technical part.
We formalize the problem
- text of arbitrary length and content arrives at the input;
- the text is written by man, so it may contain typos, errors, abbreviations and generally be obscure
- This text needs to be somehow analyzed and classified according to several unrelated characteristics. In our case, it was necessary to determine the essence of the appeal: an error message, a request for new functionality or consultation is needed, and also to define a functional module: salary calculation, accounting, warehouse management, etc .;
- only one value can be assigned for each characteristic;
- the set of possible values for each characteristic is known in advance;
- There are several thousand already classified complaints.
Having formalized the task and started developing for our specific needs, I realized that it would be better to develop a universal tool right away that would not be rigidly tied to any specific characteristics and the number of these characteristics. As a result, a tool was born that can classify text according to arbitrary characteristics.
I did not begin to look for ready-made solutions, because there was time and interest to make on my own, immersing in parallel the study of neural networks.
Selection of tools
I decided to develop in Java.
I used SQLite and H2 as a DBMS. Also useful Hibernate .
From here I took a ready implementation of the neural network (Encog Machine Learning Framework). I decided to use the neural network as a classifier, and not, for example, the naive Bayes classifier , because, firstly, theoretically, the neural network should be more precise. Secondly, I just wanted to play around with neural networks.
To read the Excel data file, some Apache POI libraries were needed for training.
Well, for tests, I traditionally used JUnit 4 + Mockito .
A little bit of theory
I will not describe the theory in detail on neural networks, as there is plenty of it ( there is a good introduction material here). In short and in a simple way: the network has an input layer, hidden layers and an output layer. The number of neurons in each layer is determined by the developer in advance and, after learning the network, cannot be changed: if at least one neuron is added / subtracted, then the network must be retrained. For each neuron of the input layer, a normalized number (usually from 0 to 1) is fed. Depending on the set of these numbers on the input layer, after certain calculations, on each output neuron, we also get a number from 0 to 1.
The essence of network training is that the network adjusts its link weights involved in the calculations, so that when a set of numbers on the input layer is known in advance, a set of numbers on the output layer will be known in advance. Adjusting the weights is an iterative process and occurs until the network reaches the specified accuracy on the training set or until it reaches a certain number of iterations. After training, it is assumed that the network will produce a close to the reference set of numbers on the output layer, if the input set file numbers, similar to the one that was in the training set.
Go to practice
The first task was to figure out how to convert the text to a form that can be transmitted to the input of a neural network. But first it was necessary to determine the size of the input layer of the network, since it must be specified in advance. Obviously, the input layer must be of such a size that any text can be “fit” into this layer. The first thing that comes to mind is that the size of the input layer should be equal to the size of the dictionary containing the words / phrases of which the texts consist.
There are many ways to build a dictionary. You can, for example, stupidly take all the words of the Russian language and this will be our dictionary. But this approach is not suitable, because the size of the input layer will be so huge that there will not be enough resources for a simple workstation to create a neural network. For example, imagine that our dictionary consists of 100,000 words, then we have 100,000 neurons in the input layer; for example, 80,000 in a hidden layer (the method for determining the dimension of a hidden layer is described below) and 25 in the output layer. Then, just to store the link weights, you will need ~ 60 GB of RAM: ((100,000 * 80,000) + (80,000 * 25)) * 64 bits (type double in JAVA). Secondly, such an approach is not suitable, because the texts can use specific terminology, which is absent in dictionaries.
This suggests the conclusion that the dictionary should be built only from those words / phrases that our analyzed texts consist of. It is important to understand that in this case there must be a sufficiently large amount of training data to build the dictionary.
One of the ways of “pulling out” words / phrases (even more precisely, fragments) from the text is called building an N-gram . The most popular are unigrams and bigrams. There are also character N-grams - this is when the text is divided not into separate words, but into segments of characters of a certain length. It is difficult to say in advance which of the N-grams will be more effective in a specific task, so you need to experiment.
| Text | Unigram | Bigram | 3-character N-grams |
|---|---|---|---|
| This text should be broken apart. | ["This", "text", "must", "be", "broken", "on", "parts"] | ["This text", "the text should", "should be", "be broken", "broken into", "into parts"] | [“This”, “t”, “ex”, “t d”, “Volzh”, “en”, “life”, “l p”, “az”, “it”, “on”, “hour "," Ty "] |
I decided to move from simple to complex and first developed the Unigram class.
Unigram class
class Unigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { if (text == null) { text = ""; } // get all words and digits String[] words = text.toLowerCase().split("[ \\pP\n\t\r$+<>№=]"); Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } } As a result, after processing ~ 10,000 texts, I received a dictionary of ~ 32,000 elements. Having analyzed the resulting dictionary diagonally, I realized that there is a lot of superfluous in it, which we should get rid of. To do this, do the following:
- Removed all non-alphabetic characters (numbers, punctuation marks, arithmetic operations, etc.), since they, as a rule, do not carry any meaning.
- I drove the words through the procedure of stemming (I used Stemmer Porter for the Russian language). By the way, a useful side effect of this procedure is the “unisexation” of the texts, that is, “made” and “made” will be transformed into “made”.
- First, I wanted to identify and correct typos and grammatical errors. I read about the Oliver Algorithm ( similar_text function in PHP) and Levenshtein Distance . But the task was solved much easier, albeit with an error: I decided that if an element of the N-gram is found less than in 4 texts from the training set, then we do not include this element in the dictionary as useless in the future. In this way, I got rid of most typos, grammatical words, “coarse words” and just very rare words. But it should be understood that if in future texts typos and grammatical errors are often encountered, the classification accuracy of such texts will be lower and then you will still have to implement a mechanism for correcting typos and grammatical errors. Important : such a "trick" with throwing out rarely occurring words is permissible with a large amount of data for training and building a dictionary.
All this is implemented in the classes FilteredUnigram and VocabularyBuilder.
Class FilteredUnigram
public class FilteredUnigram implements NGramStrategy { @Override public Set<String> getNGram(String text) { // get all significant words String[] words = clean(text).split("[ \n\t\r$+<>№=]"); // remove endings of words for (int i = 0; i < words.length; i++) { words[i] = PorterStemmer.doStem(words[i]); } Set<String> uniqueValues = new LinkedHashSet<>(Arrays.asList(words)); uniqueValues.removeIf(s -> s.equals("")); return uniqueValues; } private String clean(String text) { // remove all digits and punctuation marks if (text != null) { return text.toLowerCase().replaceAll("[\\pP\\d]", " "); } else { return ""; } } } VocabularyBuilder class
class VocabularyBuilder { private final NGramStrategy nGramStrategy; VocabularyBuilder(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } List<VocabularyWord> getVocabulary(List<ClassifiableText> classifiableTexts) { if (classifiableTexts == null || classifiableTexts.size() == 0) { throw new IllegalArgumentException(); } Map<String, Integer> uniqueValues = new HashMap<>(); List<VocabularyWord> vocabulary = new ArrayList<>(); // count frequency of use each word (converted to n-gram) from all Classifiable Texts // for (ClassifiableText classifiableText : classifiableTexts) { for (String word : nGramStrategy.getNGram(classifiableText.getText())) { if (uniqueValues.containsKey(word)) { // increase counter uniqueValues.put(word, uniqueValues.get(word) + 1); } else { // add new word uniqueValues.put(word, 1); } } } // convert uniqueValues to Vocabulary, excluding infrequent // for (Map.Entry<String, Integer> entry : uniqueValues.entrySet()) { if (entry.getValue() > 3) { vocabulary.add(new VocabularyWord(entry.getKey())); } } return vocabulary; } } Example of compiling a dictionary:
| Text | Filtered unigram | Vocabulary |
|---|---|---|
| Need to find a sequence of 12 tasks. | necessary, consistent, tasks | necessary, knight, consistently, tasks, for, arbitrarily, add, transpose |
| Task for arbitrary | tasks for arbitrary | |
| Add arbitrary transposition | add, arbitrary, transpose |
To build Bigrams, I also wrote a class right away, so that after the experiments, to stop the choice on the variant that gives the best result in terms of the dictionary size and classification accuracy.
Class bigram
class Bigram implements NGramStrategy { private NGramStrategy nGramStrategy; Bigram(NGramStrategy nGramStrategy) { if (nGramStrategy == null) { throw new IllegalArgumentException(); } this.nGramStrategy = nGramStrategy; } @Override public Set<String> getNGram(String text) { List<String> unigram = new ArrayList<>(nGramStrategy.getNGram(text)); // concatenate words to bigrams // example: "How are you doing?" => {"how are", "are you", "you doing"} Set<String> uniqueValues = new LinkedHashSet<>(); for (int i = 0; i < unigram.size() - 1; i++) { uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1)); } return uniqueValues; } } I have decided to stop at this for now, but further processing of words for compiling a dictionary is also possible. For example, you can define synonyms and bring them to a single form, you can analyze the similarity of words, you can even invent something of your own, etc. But, as a rule, this does not give a significant increase in the accuracy of the classification.
Okay, go ahead. The size of the input layer of the neural network, which will be equal to the number of elements in the dictionary, we calculated.
The size of the output layer for our task will be equal to the number of possible values for the characteristic. For example, we have 3 possible values for the "Type of address" characteristic: system error, user assistance, new functionality. Then the number of neurons in the output layer will be three. When training the network, for each value of the characteristic it is necessary to determine in advance the reference unique set of numbers that we expect to receive on the output layer: 1 0 0 for the first value, 0 1 0 for the second, 0 0 1 for the third ...
As for the number and dimension of hidden layers, then there is no specific recommendation. The sources say that the optimal size for each specific task can be calculated only experimentally, but for a narrowing network it is recommended to start with one hidden layer, the size of which varies between the size of the input layer and the output layer. To begin with, I created one hidden layer of 2/3 in size from the input layer, and then I experimented with the number of hidden layers and their sizes. Here you can read a little theory and recommendations on this issue. It also describes how much data there should be for training.
So, we have created a network. Now we need to decide on how we will convert the text into figures suitable for “feeding” the neural network. To do this, we need to convert the text into a text vector . First you need to assign each word in the dictionary a unique word vector , the size of which should be equal to the size of the dictionary. After learning the network to change the vector for words can not. Here’s how it looks for a 4-word dictionary:
| Word in dictionary | Word vector |
|---|---|
| Hello | 1 0 0 0 |
| as | 0 1 0 0 |
| affairs | 0 0 1 0 |
| you | 0 0 0 1 |
The procedure of converting text into a vector of text implies the addition of vectors of words used in the text: the text “how do you say hello?” Will be converted into a vector “1 1 0 1”. We can already feed this vector to the input of the neural network: each individual number for each individual neuron of the input layer (the number of neurons is just equal to the size of the text vector).
Method that calculates the text vector
private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) { double[] vector = new double[inputLayerSize]; // convert text to nGram Set<String> uniqueValues = nGramStrategy.getNGram(classifiableText.getText()); // create vector // for (String word : uniqueValues) { VocabularyWord vw = findWordInVocabulary(word); if (vw != null) { // word found in vocabulary vector[vw.getId() - 1] = 1; } } return vector; } Here and here you can additionally read about the preparation of the text for analysis.
Classification accuracy
Having experimented with different dictionary formation algorithms and with different number and dimension of hidden layers, I stopped at this option: use FilteredUnigram with cutting off rarely used words to form a dictionary; we make 2 hidden layers with the dimension 1/6 of the dictionary size - the first layer and 1/4 of the size of the first layer - the second layer.
After training on ~ 20,000 texts (and this is very small for a network of this size) and on the network run of 2,000 reference texts, we have:
| N-gram | Accuracy | Dictionary size (without rarely used words) |
|---|---|---|
| Unigram | 58% | ~ 25 000 |
| Filtered unigram | 73% | ~ 1,200 |
| Bigram | 63% | ~ 8 000 |
| Filtered bigram | 69% | ~ 3,000 |
This is accuracy for one feature. If accuracy is needed for several characteristics, the calculation formulas are as follows:
- The probability of guessing all the characteristics at once is equal to the product of the probabilities of guessing each characteristic.
- The probability of guessing at least one characteristic is equal to the difference between the unit and the product of the probabilities of incorrectly determining each characteristic.
Example:
Assume that the accuracy of determining one characteristic is 65%, the second characteristic is 73%. Then the accuracy of determining both at once is equal to 0.65 * 0.73 = 0.4745 = 47.45% , and the accuracy of determining at least one characteristic is 1- (1-0.65) * (1-0.73) = 0 , 9055 = 90.55% .
It is quite a good result for a tool that does not require preliminary manual processing of incoming data.
There is one “but”: the accuracy strongly depends on the similarity of texts that should be assigned to different categories: the less similar the texts from the “System Errors” category are to the texts from the “Need Help” category, the more accurate the classification will be. Therefore, with the same network and dictionary settings in different tasks and on different texts there can be significant differences in accuracy.
Final program
As already said, I decided to write a universal program that is not tied to the number of characteristics by which the text should be classified. I will not describe in detail all the details of the development here, I will describe only the algorithm of the program, and the link to the sources will be at the end of the article.
The general algorithm of the program:
- When you first start the program asks for the XLSX file with the training data. A file can consist of one or two sheets. On the first sheet, the data for training, on the second - the data for subsequent testing of the accuracy of the network. The sheet structure is the same. The first column should contain the analyzed text. Subsequent columns (there may be any number of them) should contain the values of the characteristics of the text. The first line should contain the names of these characteristics.
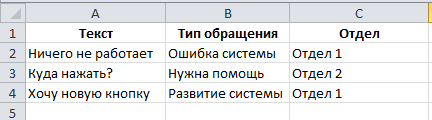
- Based on this file, a dictionary is built, a list of characteristics and unique values valid for each characteristic are determined. All this is stored in the repository.
- A separate neural network is created for each characteristic.
- All created neural networks are trained and stored.
- Upon subsequent launch, all saved trained neural networks are loaded. The program is ready for text analysis.
- The resulting text is processed independently by each neural network, and the total result is output as a value for each characteristic.
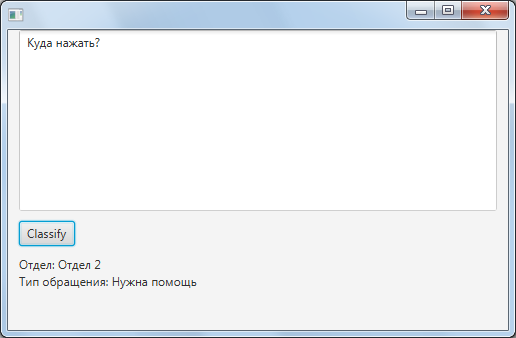
In the plans:
- Add other types of classifiers (for example, a convolutional neural network and a naive Bayes classifier );
- Try using a dictionary consisting of a combination of unigrams and bigrams.
- Add a mechanism for removing typos and grammatical errors.
- Add a dictionary of synonyms.
- Eliminate too frequent words, as they are usually informational noise.
- Add weights to individual significant words so that their influence in the analyzed text is greater.
- A little to alter the architecture, simplifying the API, so that you can bring the main functionality into a separate library.
Little about source
Sources can be useful as an example of using some design patterns. There is no sense in putting it into a separate article, but I don’t want to be silent about them, since I share my experience, so let it be in this article.
- Pattern "Strategy" . The NGramStrategy interface and the classes that implement it.
- Pattern "Observer" . The LogWindow and Classifier classes implement the Observer and Observable interfaces.
- Pattern "Decorator" . Bigram class.
- Pattern "Simple Factory". The NGramStrategy interface's getNGramStrategy () method.
- Pattern "Factory Method" . The getNgramStrategy () method of the NGramStrategyTest class.
- Pattern "Abstract Factory" . JDBCDAOFactory class.
- Pattern (anti-pattern?) "Loner" . EMFProvider class.
- Pattern "Template method" . The initializeIdeal () method of the NGramStrategyTest class. True, there is not quite a classic of its application.
- Pattern "DAO" . Interfaces CharacteristicDAO, ClassifiableTextDAO, etc.
Full source code: https://github.com/RusZ/TextClassifier
Constructive suggestions and criticism are welcome.
PS: Do not worry about Lena - this is a fictional character.
Source: https://habr.com/ru/post/332078/
All Articles