Improving data quality with Oracle Enterprise Data Quality
In most Siebel implementation projects, one way or another, one has to face data quality problems. In this part of the Oracle offers an interesting solution - Enterprise Data Quality with the ability to integrate into Siebel (which actually attracted us). In this article, I will briefly describe the product itself, its architecture, and show you how to create a simple process for improving data quality.
EDQ is a product that allows you to control the quality of information. The basis for the analysis of EDQ can serve as different data sources, such as:
EDQ allows you to analyze data, find inaccuracies, spaces and errors. You can make adjustments, transform and transform information to improve its quality. You can integrate data quality control rules in ETL tools, thereby preventing inconsistent information. The great advantage when using EDQ is an intuitive interface, as well as the ease of changing and expanding the rules of validation and transformation. An important EDQ tool is Dashboards, which allow business users to track trends in data quality. For example, as in the screenshot below:
')

EDQ is a Java web application that uses the Java Servlet Engine, a Java Web Start graphical user interface, and a database for storing data.
EDQ provides a number of client applications that allow you to manage the system:
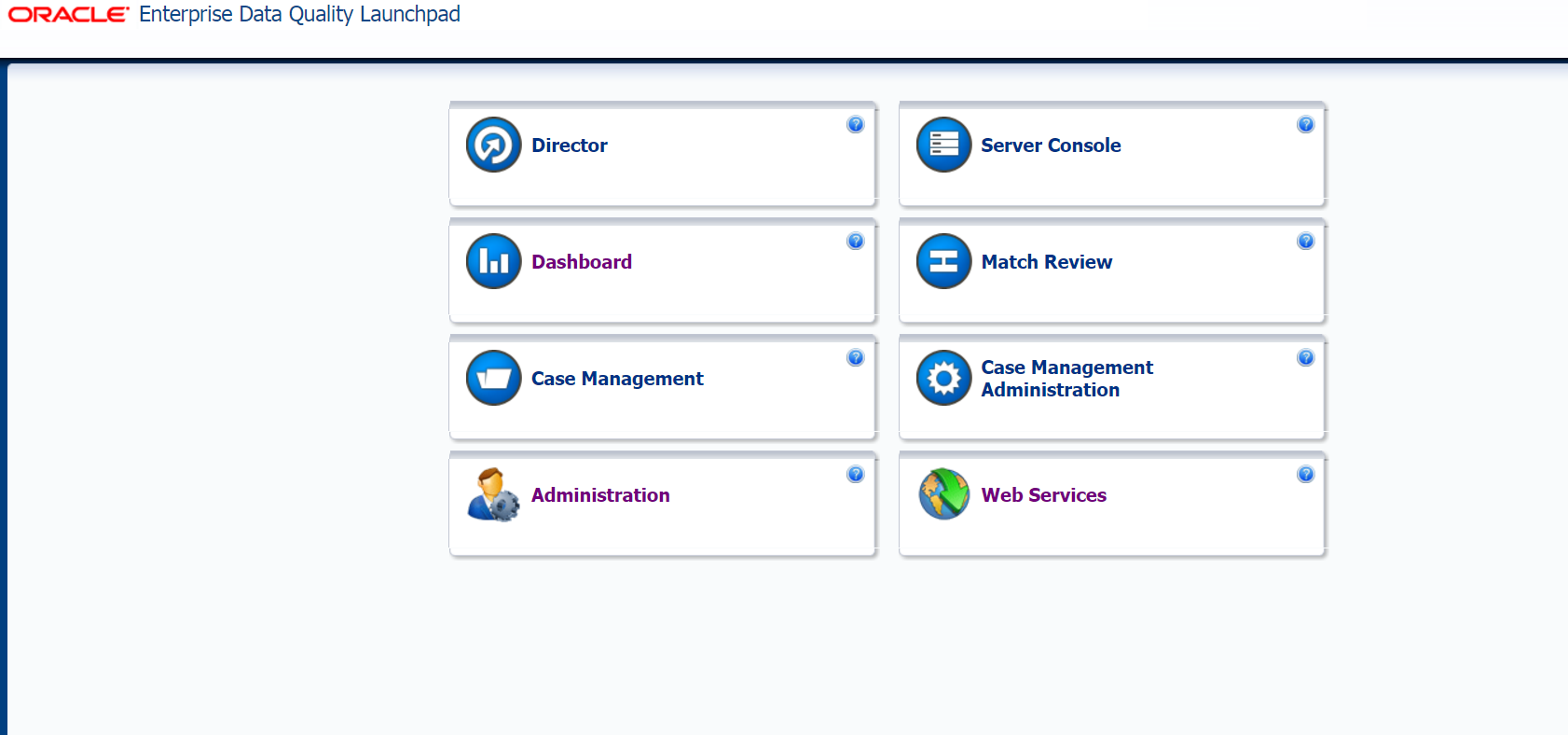
When you visit the Enterprise Data Quality Launchpad page, you can see application data, for example, Director, who is responsible for designing and processing information. When you click on the button, we are asked to save the file:

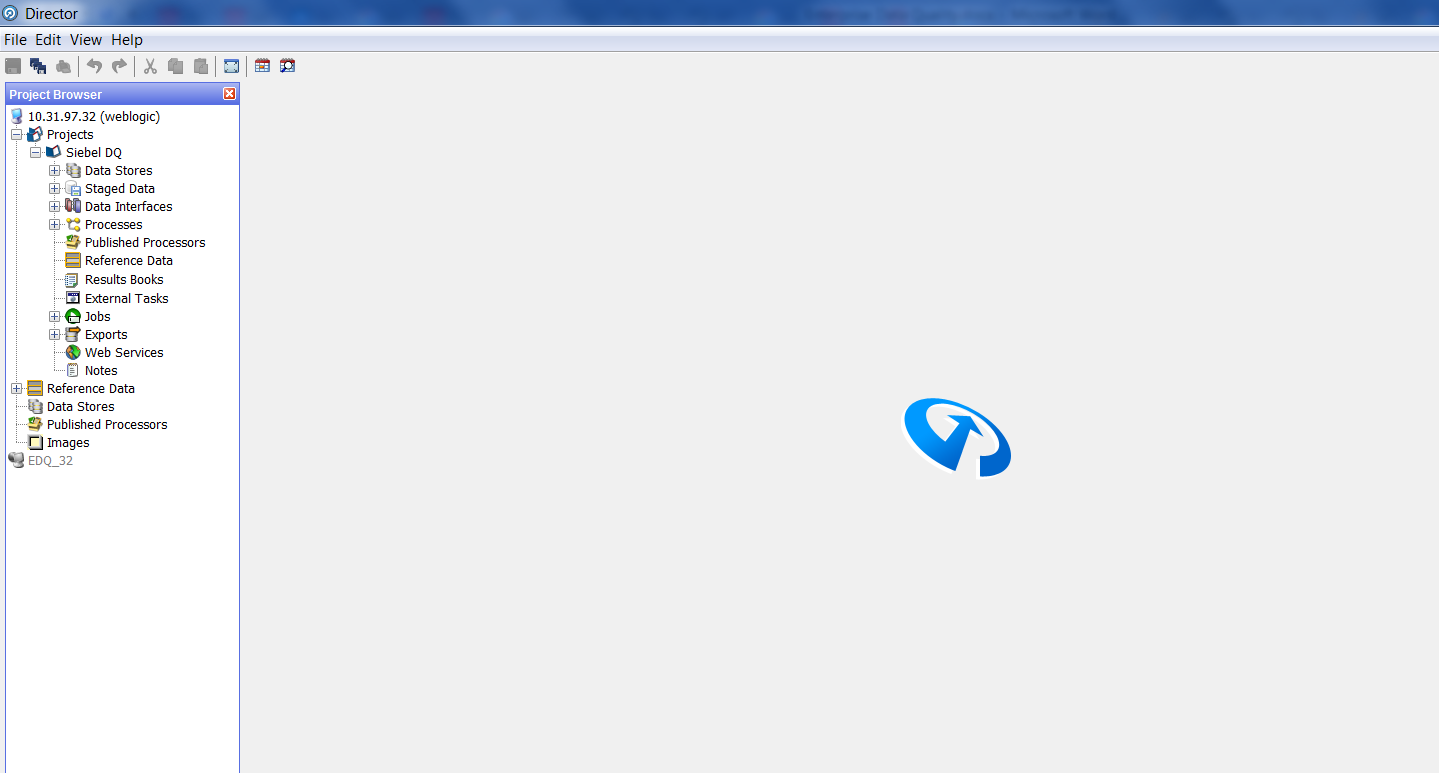
Having opened it, we get to the main design interface:
Data nibbles, processed information and the necessary metadata are stored on the EDQ server. Client machines only store user preferences. EDQ uses a repository that is stored in two database schemas — in the configuration database and in the result schema.
The configuration scheme stores information about the EDQ settings, and the results scheme contains information snapshots (intermediate processing results and final results of the processes).
Examples of problems solved with EDQ:
On the basis of connections to different data sources, so-called “Staged Data” is created - information snapshots for further analysis.
EDQ has many processors with which you can transform the original snapshot of information.
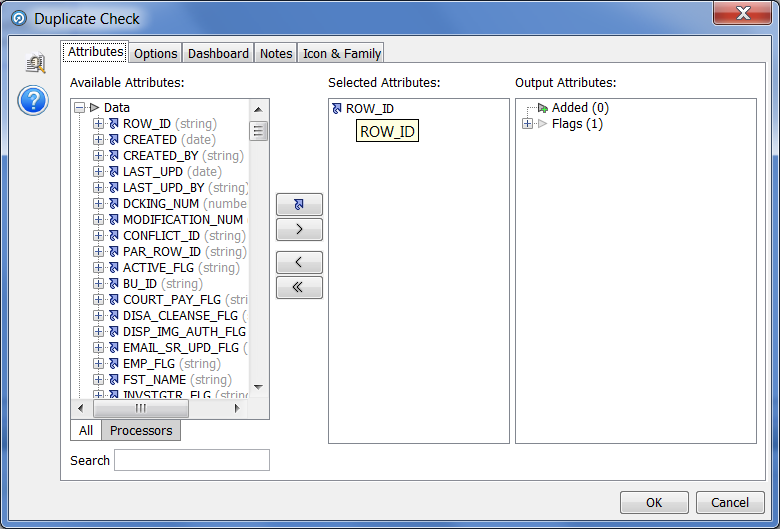
A common problem when using information is the presence of duplicates. As mentioned above, EDQ allows you to solve it. To eliminate duplicates, you can use the “Duplicate Check” processor, in its settings you need to select the field by which the information will be grouped:
This processor allows you to select for further analysis the data cleared of duplicates:
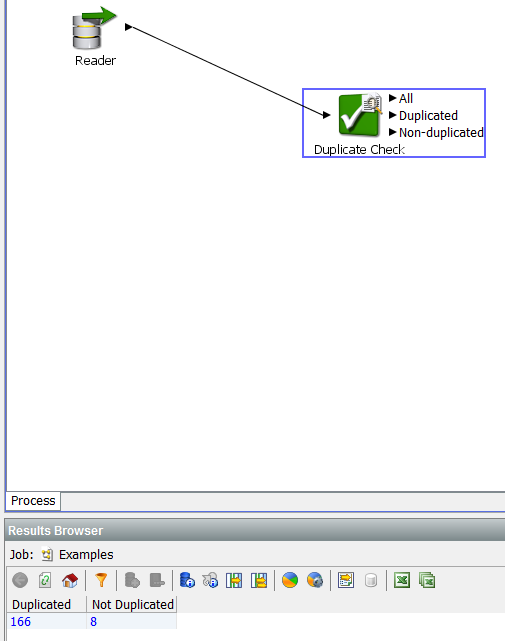
You can use the Group and Merge processor to merge duplicate lines. For example, consider its functionality.
Having placed the processor in the workspace and connecting it with the processor selecting the initial information, it is necessary to enter the settings of the “Group and Merge”.
This processor has three subprocessors:
Inputs - allows you to select the fields to be converted from the initial data set. Drag the required columns using the buttons:
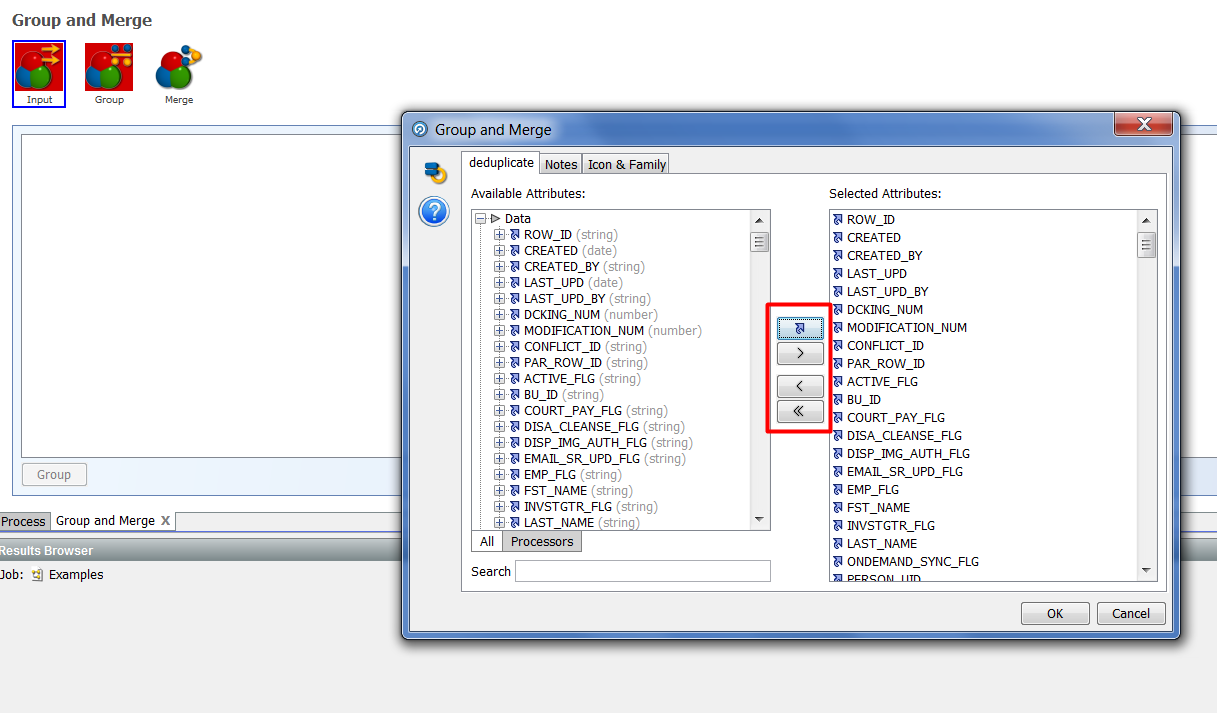
Based on the selected attributes, we will select the field or fields on the basis of which the grouping will be made.
Group - in this processor, you must select the fields on the basis of which the source data will be grouped:
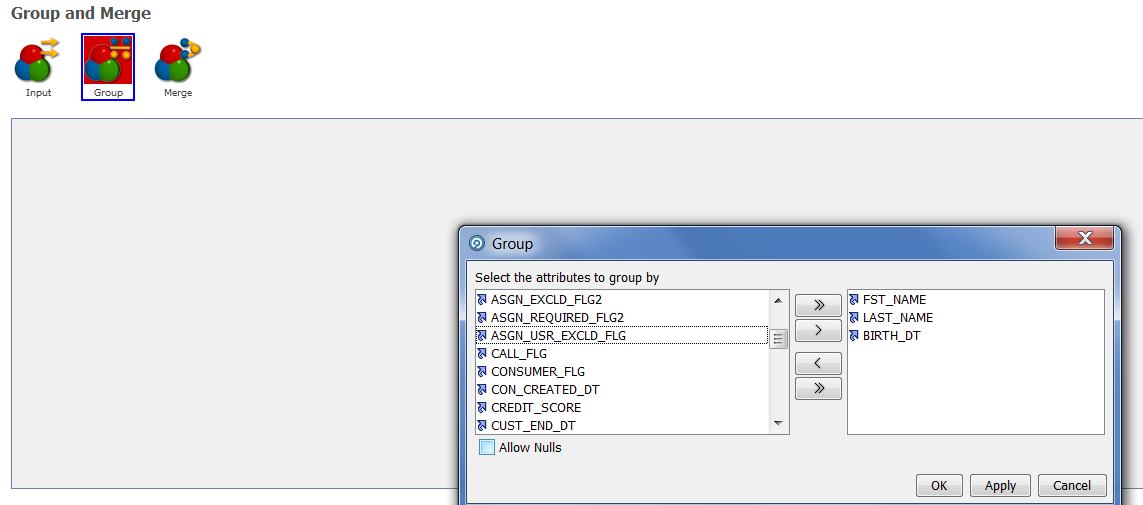
And the last subprocessor is Merge, which allows you to configure the rules for merging each attribute:
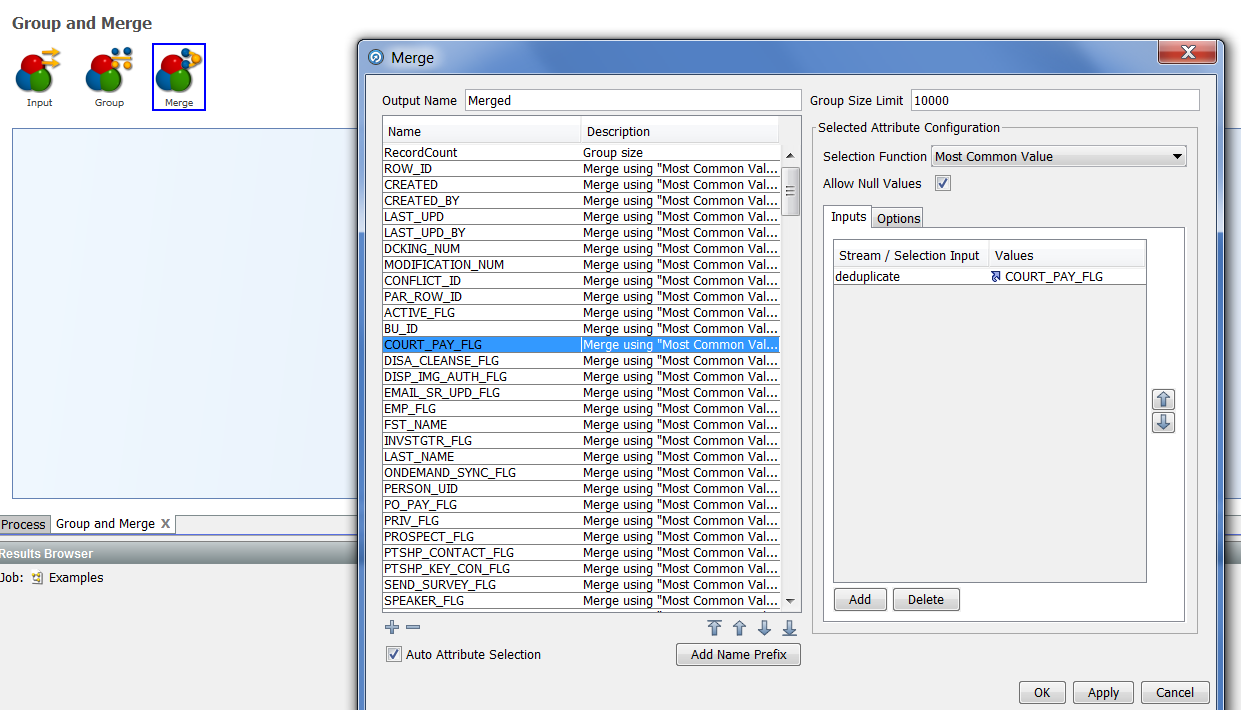
By default, the value of the rule is set to “Most Common Value”, but this value can be replaced if necessary by the ones from the list:

After setting up and running the processor, we see the result of its work:

In the original set there was a different amount of data:

These conversions are performed at the level of data nugget in EDQ and do not affect the data in the database. In order to display the resulting cleared information in the database, you need to take a few more steps. Based on the information received from the Group and Merge processor, you need to create a new information snapshot, which we will later load into the database. Select the processor "Writer":
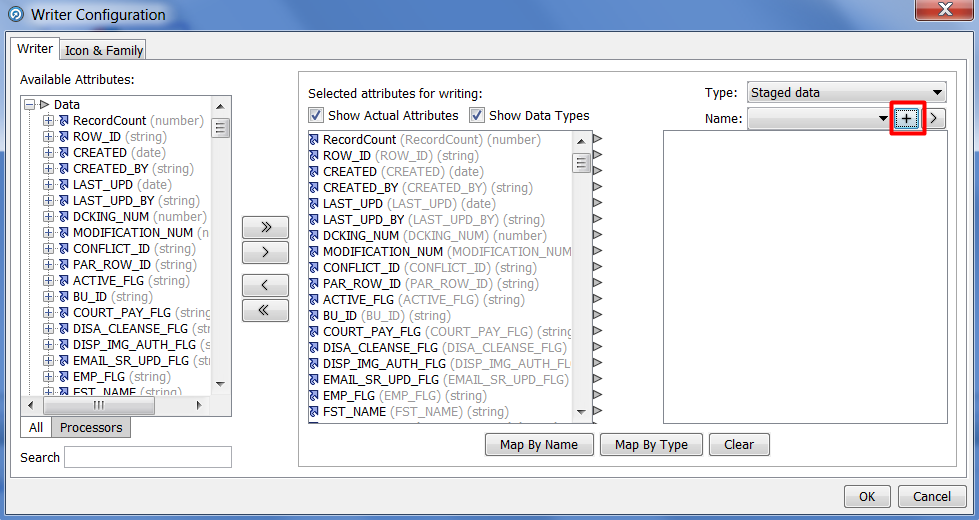
And press the New Staged Data button. Further, it is proposed to create a new image based on the information received after deduplication. The final screen should look like this:

You can also use existing snapshots that will be overwritten after the process starts.
After recording the deduplicated information, you need to create a new export, which will write our changes to the database:

In the interface above, it is proposed to select a prepared data cast and a table into which it is planned to be loaded. By default, this process will delete existing data and insert new ones, but it can be customized. For this you need to create a new job.
Drag the created process to the workspace:
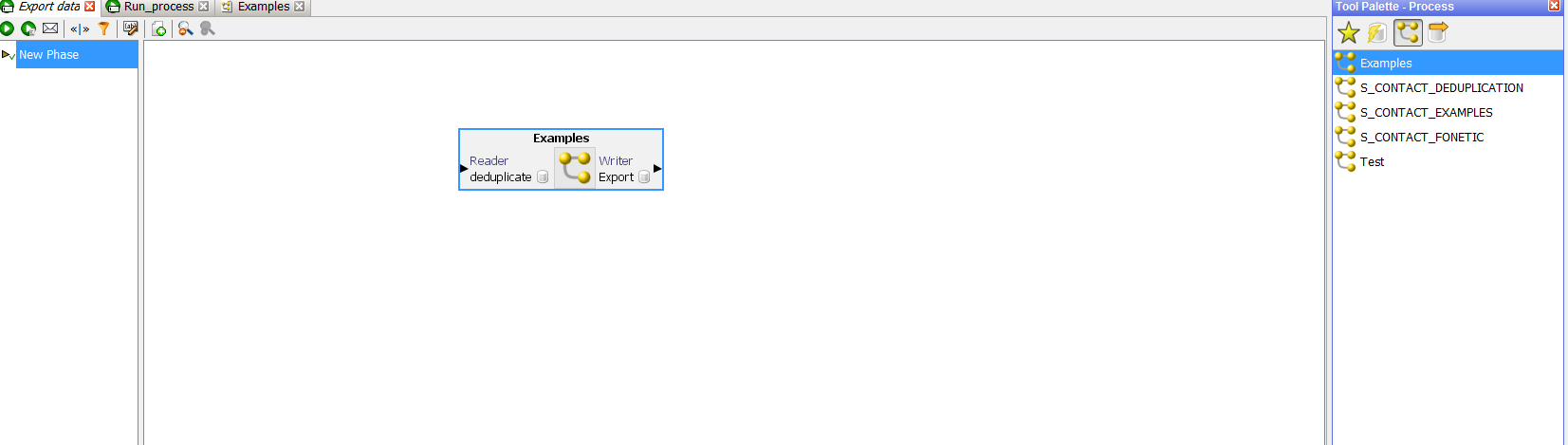
And the data export created:
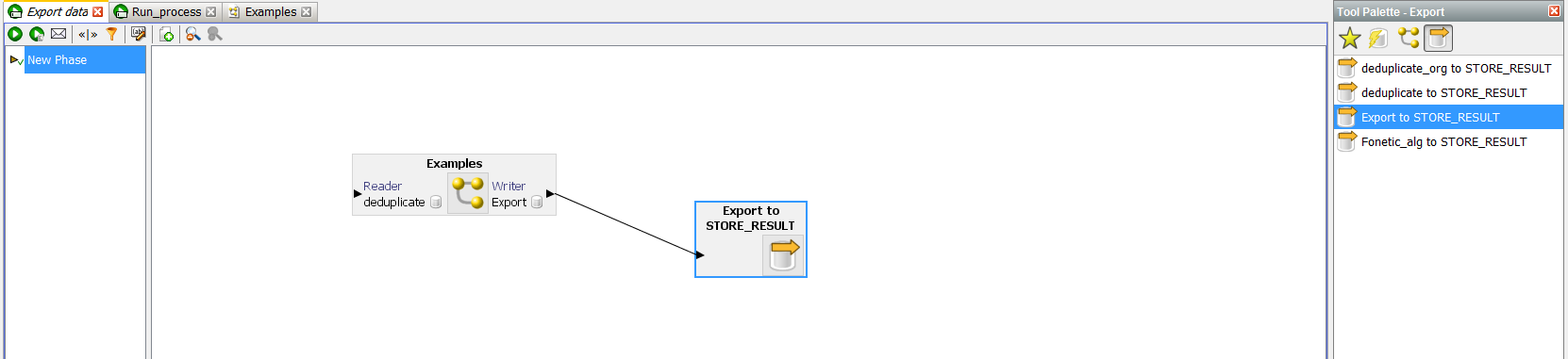
Then you can configure the export. Double-click the menu:
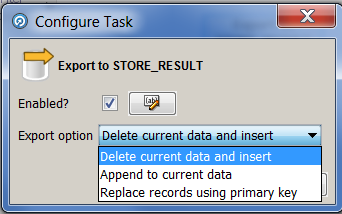
Having selected the necessary value, we launch the task to work and check the result in the database.
EDQ provides the user with a wide range of tools, but there are, as they say, some nuances. For example, such can be attributed to the absence of pre-configured templates for processing information. Indeed, most of the problems associated with data quality are typical of many projects. It is worth saying that some ready-made processes can still be found and integrated into your project. Actually, this is what we plan to do - to prepare a package of processes that can be used on different projects.
To use the phonetic algorithms presented in EDQ, only the Latin script is suitable, but you can always use transliteration and pre-configure your data for these algorithms.
Another, so to say, not quite convenient feature that we noticed is the not quite transparent process of uploading the results of processing to the base. If you use the database table as a source, it would be easier when getting the result immediately to be able to replace the original information with the cleared one.
As mentioned at the beginning, most of the projects that use data warehouses somehow suffer from the quality of the information stored in them. EDQ can help solve problems not only of deduplication, which we have spoken about here, but also of many others. A big plus of this product is the availability of ready-to-use various processors. A dashboard with a simple interface will help business users to actively participate in data quality control.
In the following articles we will try to consider using the example of the process of standardization of addresses according to FIAS and the creation of information panels, as well as integration with Oracle Siebel. Watch for updates.
Anton Akinshin, developer of Jet Infosystems business systems implementation center. Please contact us with questions in the comments.
Briefly about the product
EDQ is a product that allows you to control the quality of information. The basis for the analysis of EDQ can serve as different data sources, such as:
- databases (Oracle, Postgres, DB2, MySql, etc.),
- text files
- Xml files
- MS Office files
- system files and stuff.
EDQ allows you to analyze data, find inaccuracies, spaces and errors. You can make adjustments, transform and transform information to improve its quality. You can integrate data quality control rules in ETL tools, thereby preventing inconsistent information. The great advantage when using EDQ is an intuitive interface, as well as the ease of changing and expanding the rules of validation and transformation. An important EDQ tool is Dashboards, which allow business users to track trends in data quality. For example, as in the screenshot below:
')
EDQ is a Java web application that uses the Java Servlet Engine, a Java Web Start graphical user interface, and a database for storing data.
EDQ provides a number of client applications that allow you to manage the system:
When you visit the Enterprise Data Quality Launchpad page, you can see application data, for example, Director, who is responsible for designing and processing information. When you click on the button, we are asked to save the file:
Having opened it, we get to the main design interface:
Data nibbles, processed information and the necessary metadata are stored on the EDQ server. Client machines only store user preferences. EDQ uses a repository that is stored in two database schemas — in the configuration database and in the result schema.
The configuration scheme stores information about the EDQ settings, and the results scheme contains information snapshots (intermediate processing results and final results of the processes).
What tasks solves EDQ
Examples of problems solved with EDQ:
- deduplication and consolidation of information
- bringing information to a single type (writing the name of one country in different ways, etc.),
- identifying information entered in the wrong field
- address parsing
- splitting of fields in which information on several attributes is encoded.
On the basis of connections to different data sources, so-called “Staged Data” is created - information snapshots for further analysis.
EDQ has many processors with which you can transform the original snapshot of information.
A common problem when using information is the presence of duplicates. As mentioned above, EDQ allows you to solve it. To eliminate duplicates, you can use the “Duplicate Check” processor, in its settings you need to select the field by which the information will be grouped:
This processor allows you to select for further analysis the data cleared of duplicates:
Simple deduplication process
You can use the Group and Merge processor to merge duplicate lines. For example, consider its functionality.
Having placed the processor in the workspace and connecting it with the processor selecting the initial information, it is necessary to enter the settings of the “Group and Merge”.
This processor has three subprocessors:
- Inputs
- Group
- Merge
Inputs - allows you to select the fields to be converted from the initial data set. Drag the required columns using the buttons:
Based on the selected attributes, we will select the field or fields on the basis of which the grouping will be made.
Group - in this processor, you must select the fields on the basis of which the source data will be grouped:
And the last subprocessor is Merge, which allows you to configure the rules for merging each attribute:
By default, the value of the rule is set to “Most Common Value”, but this value can be replaced if necessary by the ones from the list:
After setting up and running the processor, we see the result of its work:
In the original set there was a different amount of data:
These conversions are performed at the level of data nugget in EDQ and do not affect the data in the database. In order to display the resulting cleared information in the database, you need to take a few more steps. Based on the information received from the Group and Merge processor, you need to create a new information snapshot, which we will later load into the database. Select the processor "Writer":
And press the New Staged Data button. Further, it is proposed to create a new image based on the information received after deduplication. The final screen should look like this:
You can also use existing snapshots that will be overwritten after the process starts.
After recording the deduplicated information, you need to create a new export, which will write our changes to the database:
In the interface above, it is proposed to select a prepared data cast and a table into which it is planned to be loaded. By default, this process will delete existing data and insert new ones, but it can be customized. For this you need to create a new job.
Drag the created process to the workspace:
And the data export created:
Then you can configure the export. Double-click the menu:
Having selected the necessary value, we launch the task to work and check the result in the database.
Conclusion
EDQ provides the user with a wide range of tools, but there are, as they say, some nuances. For example, such can be attributed to the absence of pre-configured templates for processing information. Indeed, most of the problems associated with data quality are typical of many projects. It is worth saying that some ready-made processes can still be found and integrated into your project. Actually, this is what we plan to do - to prepare a package of processes that can be used on different projects.
To use the phonetic algorithms presented in EDQ, only the Latin script is suitable, but you can always use transliteration and pre-configure your data for these algorithms.
Another, so to say, not quite convenient feature that we noticed is the not quite transparent process of uploading the results of processing to the base. If you use the database table as a source, it would be easier when getting the result immediately to be able to replace the original information with the cleared one.
As mentioned at the beginning, most of the projects that use data warehouses somehow suffer from the quality of the information stored in them. EDQ can help solve problems not only of deduplication, which we have spoken about here, but also of many others. A big plus of this product is the availability of ready-to-use various processors. A dashboard with a simple interface will help business users to actively participate in data quality control.
In the following articles we will try to consider using the example of the process of standardization of addresses according to FIAS and the creation of information panels, as well as integration with Oracle Siebel. Watch for updates.
Anton Akinshin, developer of Jet Infosystems business systems implementation center. Please contact us with questions in the comments.
Source: https://habr.com/ru/post/332024/
All Articles