Multicore DSP TMS320C6678. Operational kernels: processor computing resources
We continue to consider the device multi-core DSP TMS320C6678. This article is devoted to the device operating processor cores. The core architecture is described briefly with an emphasis on comparing the C66x platform with the earlier well-known C6000 models.
The operating core of the signal processor is the main element that directly implements computational actions aimed at performing signal processing in accordance with the algorithm dictated by the program embedded in the processor. Multi-core processors of the TMS320C66xx family contain a set of operating cores, which is a prerequisite for a corresponding increase in the computing performance of the device compared to single-core processors. Further, one typical DSP core of the TMS320C66xx processor will be considered.
TMS320C66x processors are a development of the platform of C6000 signal processors from Texas Instruments. The fundamentals of building architecture are the same, however, their capabilities and, in part, the interpretation of their functioning, have undergone some modifications.
The core of the TMS320C66xx processor is built according to the architecture with a very long command word (Very Long Instruction Word - VLIW - "Wi-EI-Double-U"). Each core includes 8 parallel computing units (2 multipliers and 6 ALUs) and a register file of 64 32-bit registers. Compared with the latest models of processors in the TMS320C6000 line, the TMS320C66xx processors have the following features.
')
Thus, the main focus, in terms of processor computing resources, in the C66x architecture is placed on multi-core and on expanding the possibilities of vector arithmetic. Due to this, computational performance is increased by more than 30 times (if we compare the TMS320C6455 processor with a clock frequency of 1.2 GHz and the performance of 9600 MMACS and the TMS320C6678 processor with a frequency of 1.25 GHz and 320 GMACS). The main computational capabilities of TMS320C66x processors in comparison with the processors of the previous family with floating point TMS320C674x are summarized in table 1.1. Note that the performance expressed in the number of multiply operations with accumulation per second does not fully reflect the computational power of the processor. Vector arithmetic imposes a number of restrictions on operands. One multiplier that realizes 16 multiplications per cycle is not the same as 16 multipliers that perform the same 16 multiplications per cycle. Not all tasks can be well supported by vector arithmetic. In such cases, processor resources may be idle and the architecture gains will not be felt.
The core architecture of the TMS320C66x processor is shown in Figure 1.3. As with any digital signal processor, the TMS320C66xx DSP core includes a set of computation blocks, a register file, an automatic program, program and data memory.
TMS320C66x processors contain a double set of computing blocks — one on the A side (Data Path A); the other is on the B side (Data Path B). The set of computational blocks is classical and includes the multiplier .M, ALU .L, the shifter .S and the data address generator .D. In modern DSPs, the functions of each of these blocks are significantly expanded and can partially overlap, however, to simplify the understanding, it is convenient to use classical terminology. All blocks work in parallel, extracting operands from the register file registers (A / B Register File) and returning the result of the corresponding operation to one of the registers.
The data before being stored in the register file is stored in the internal or external data memory (L1D, L2 Cache / SRAM, MSM SRAM, DDR3 SRAM). The results of processing and intermediate data sets are also recorded in the memory. The memory subsystem of the TMS320C66x processor will be discussed separately in the appropriate section.
Data is processed in accordance with the program loaded on the processor. During operation, the program is located in the program memory (L1P, L2 Cache / SRAM, MSM SRAM, DDR3 SRAM). The automaton is responsible for reading the program from the memory (Instruction Fetch), its decoding (Decode) and distribution of the corresponding actuators (Dispatch).
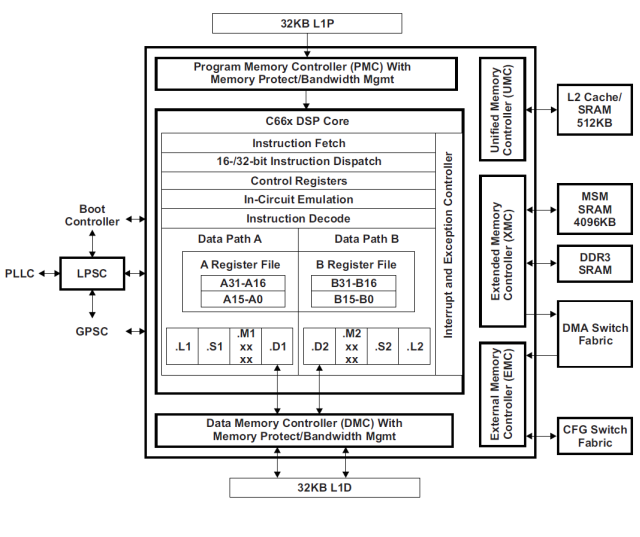
Figure 2 - C66x processor core architecture
Additional hardware modules in the processor core are the Control Registers set, the In-Circuit Emulation logic, the Interrupt and Exception Controller, the memory manager that includes the memory protection module (Program / Data Memory Controller), and a number of other components.
Next, we consider in more detail the computational blocks and registers of the operating core. In this case, we will focus only on the differences between the C66x core and the cores of the previous processor models.
In the C66x processors, the principle of packed instructions is applied - the most frequently used commands are 16-bit in length with a base command word length of 32 bits. This saves program memory. The software of the processor is capable of extracting from memory, decode and distribute up to 15 commands simultaneously.
Register files of sides A and B contain 32 32-bit registers each. It is possible to work with 8-, 16-, 32-, 64- and 128-bit data (for fixed-point format), as well as 40-bit data. In this case, registers are grouped in pairs or fours.
Exchange buses between the register file and computing units are extended to 64 bits. The .L and .S blocks can simultaneously be supplied with two 64-bit operands and a 64-bit result is obtained. Two 128-bit operands are supplied to the multiplier, which are formed as two by 64-bit input words. The result is 128-bit.
Only 64-bit words can be transmitted through the intersection channels of sides A and B.
The possibilities for loading operands from memory into registers have not changed - four 32-bit words in one clock cycle. Memory recording capabilities have been extended to four 32-bit words per clock compared to TMS320C67x processors.
Commands are always selected from the memory of 8 words each, forming a sampling packet. However, such a package can actually include up to 14 commands due to the presence of 16-bit commands packed in one word.
If a packet contains only regular 32-bit commands, then in them every 0th bit of a command indicates in parallel that the command is executed with the next one or the next command is executed one clock later. That is, the presence of a parallelism bit allows you to specify which of the commands are executed in parallel. As a result, execution packages are formed, which can contain from 1st to 8-bit and 32-bit commands.
If the sample package includes packed commands, then such a package is accompanied by a header that occupies 2 high-order words. The header indicates what is contained in the package, which of the commands are 16-bit, and which of the commands are executed in parallel.
Addressing is done in the same way as earlier processor models. It is interesting, however, to note that for cyclical addressing the possibility of looping is not implemented for aligned addresses.
The work of the pipeline when processing commands as a whole does not differ from the approach that is common for the C6000 platform to organizing program execution. The conveyor includes 4 stages of command selection, 2 stages of decoding and from 1 to 10 stages of command execution. Different commands execute a different number of cycles. Commands that are executed in one execution stage are called single-ended. Single-point commands include most fixed-point operations. Floating-point commands, even basic multiplication and addition, are 4-stroke commands. Memory reference commands, transition commands and many others are not single-ended. The difference in the execution times of different commands determines the existence of various restrictions on the sharing of commands and processor resources. All this makes the processor programming process, especially at a low level, a rather difficult task. However, this concept, as already mentioned, underlies the entire C6000 platform.
Work with interruptions is organized in the same way as other models of C6000 processors. Interrupt types: restart, nonmaskable interrupt, masked interrupts and exceptions. The special register contains the address of the interrupt vector table. The table contains a set of codes for each of the interrupts. If the interrupt handling is simple, all relevant code can be written directly to the table itself. If the code does not fit, it is necessary to organize the transition to the interrupt handling procedure.
Usually, when responding to an interrupt, other masked interrupts are disabled. However, artificially it is possible to organize nested interrupt handling due to special code fragments described in the documentation.
All articles of the cycle:
The operating core of the signal processor is the main element that directly implements computational actions aimed at performing signal processing in accordance with the algorithm dictated by the program embedded in the processor. Multi-core processors of the TMS320C66xx family contain a set of operating cores, which is a prerequisite for a corresponding increase in the computing performance of the device compared to single-core processors. Further, one typical DSP core of the TMS320C66xx processor will be considered.
TMS320C66x processors are a development of the platform of C6000 signal processors from Texas Instruments. The fundamentals of building architecture are the same, however, their capabilities and, in part, the interpretation of their functioning, have undergone some modifications.
The core of the TMS320C66xx processor is built according to the architecture with a very long command word (Very Long Instruction Word - VLIW - "Wi-EI-Double-U"). Each core includes 8 parallel computing units (2 multipliers and 6 ALUs) and a register file of 64 32-bit registers. Compared with the latest models of processors in the TMS320C6000 line, the TMS320C66xx processors have the following features.
')
- The number of multiplication operations with accumulation for both fixed and floating point is increased 4 times. Each core is able to execute 32 multiplications of 16x16 bits with a fixed point or 8 multiplications of 32x32 bits in floating-point format in one clock cycle.
- The efficiency of floating-point arithmetic is improved: support is provided for fast implementation of basic floating-point operations; floating-point calculations in SIMD mode (parallel actions on parts of data words); complex floating point multiplication; other functional extensions.
- The possibilities of vector arithmetic are expanded in both fixed and floating point formats. By vector arithmetic is meant the following concept. Operands at the input of arithmetic units are represented by 128-bit vectors consisting of 4-bit 32-bit; 8 16-bit or 16 8-bit data words. Arithmetic operations can be performed simultaneously on all operands in the composition of vectors (SIMD-mode). An example of vector multiplication using the QMPY32 command is shown in Figure 1.

Figure 1 - Example of vector multiplication - Additional special instruction sets for complex and matrix arithmetic have appeared. This functionality is similar to vector multiplication, however, instead of the SIMD mode, more complex schemes are used to implement, in particular, up to two complex multiplications of a vector of dimension (1x2) and a matrix of dimension (2x2) in one clock cycle. Additional operations are also supported, such as, for example, taking a complex-conjugate number.
Thus, the main focus, in terms of processor computing resources, in the C66x architecture is placed on multi-core and on expanding the possibilities of vector arithmetic. Due to this, computational performance is increased by more than 30 times (if we compare the TMS320C6455 processor with a clock frequency of 1.2 GHz and the performance of 9600 MMACS and the TMS320C6678 processor with a frequency of 1.25 GHz and 320 GMACS). The main computational capabilities of TMS320C66x processors in comparison with the processors of the previous family with floating point TMS320C674x are summarized in table 1.1. Note that the performance expressed in the number of multiply operations with accumulation per second does not fully reflect the computational power of the processor. Vector arithmetic imposes a number of restrictions on operands. One multiplier that realizes 16 multiplications per cycle is not the same as 16 multipliers that perform the same 16 multiplications per cycle. Not all tasks can be well supported by vector arithmetic. In such cases, processor resources may be idle and the architecture gains will not be felt.
| C674x | C66x | |
|---|---|---|
| The number of multiplications with accumulation per clock in the format of 16x16 bits with a fixed point | eight | 32 |
| The number of multiplications with accumulation per clock in the format of 32x32 bits with a fixed point | 2 | eight |
| The number of multiplications with accumulation per clock in the format of ordinary precision floating point | 2 | eight |
| The number of common operations in floating point format per clock | 6 | sixteen |
| Bandwidth read / write channels between the core and memory | 2x64 bits | 2x64 bits |
| Dimension of vector operands (SIMD processing capabilities) | 32 bits (2x16 bits, 4x8 bits) | 128 bits (4x32 bits, 4x16 bits, 4x8 bits) |
The core architecture of the TMS320C66x processor is shown in Figure 1.3. As with any digital signal processor, the TMS320C66xx DSP core includes a set of computation blocks, a register file, an automatic program, program and data memory.
TMS320C66x processors contain a double set of computing blocks — one on the A side (Data Path A); the other is on the B side (Data Path B). The set of computational blocks is classical and includes the multiplier .M, ALU .L, the shifter .S and the data address generator .D. In modern DSPs, the functions of each of these blocks are significantly expanded and can partially overlap, however, to simplify the understanding, it is convenient to use classical terminology. All blocks work in parallel, extracting operands from the register file registers (A / B Register File) and returning the result of the corresponding operation to one of the registers.
The data before being stored in the register file is stored in the internal or external data memory (L1D, L2 Cache / SRAM, MSM SRAM, DDR3 SRAM). The results of processing and intermediate data sets are also recorded in the memory. The memory subsystem of the TMS320C66x processor will be discussed separately in the appropriate section.
Data is processed in accordance with the program loaded on the processor. During operation, the program is located in the program memory (L1P, L2 Cache / SRAM, MSM SRAM, DDR3 SRAM). The automaton is responsible for reading the program from the memory (Instruction Fetch), its decoding (Decode) and distribution of the corresponding actuators (Dispatch).
Figure 2 - C66x processor core architecture
Additional hardware modules in the processor core are the Control Registers set, the In-Circuit Emulation logic, the Interrupt and Exception Controller, the memory manager that includes the memory protection module (Program / Data Memory Controller), and a number of other components.
Next, we consider in more detail the computational blocks and registers of the operating core. In this case, we will focus only on the differences between the C66x core and the cores of the previous processor models.
In the C66x processors, the principle of packed instructions is applied - the most frequently used commands are 16-bit in length with a base command word length of 32 bits. This saves program memory. The software of the processor is capable of extracting from memory, decode and distribute up to 15 commands simultaneously.
Register files of sides A and B contain 32 32-bit registers each. It is possible to work with 8-, 16-, 32-, 64- and 128-bit data (for fixed-point format), as well as 40-bit data. In this case, registers are grouped in pairs or fours.
Exchange buses between the register file and computing units are extended to 64 bits. The .L and .S blocks can simultaneously be supplied with two 64-bit operands and a 64-bit result is obtained. Two 128-bit operands are supplied to the multiplier, which are formed as two by 64-bit input words. The result is 128-bit.
Only 64-bit words can be transmitted through the intersection channels of sides A and B.
The possibilities for loading operands from memory into registers have not changed - four 32-bit words in one clock cycle. Memory recording capabilities have been extended to four 32-bit words per clock compared to TMS320C67x processors.
Commands are always selected from the memory of 8 words each, forming a sampling packet. However, such a package can actually include up to 14 commands due to the presence of 16-bit commands packed in one word.
If a packet contains only regular 32-bit commands, then in them every 0th bit of a command indicates in parallel that the command is executed with the next one or the next command is executed one clock later. That is, the presence of a parallelism bit allows you to specify which of the commands are executed in parallel. As a result, execution packages are formed, which can contain from 1st to 8-bit and 32-bit commands.
If the sample package includes packed commands, then such a package is accompanied by a header that occupies 2 high-order words. The header indicates what is contained in the package, which of the commands are 16-bit, and which of the commands are executed in parallel.
Addressing is done in the same way as earlier processor models. It is interesting, however, to note that for cyclical addressing the possibility of looping is not implemented for aligned addresses.
The work of the pipeline when processing commands as a whole does not differ from the approach that is common for the C6000 platform to organizing program execution. The conveyor includes 4 stages of command selection, 2 stages of decoding and from 1 to 10 stages of command execution. Different commands execute a different number of cycles. Commands that are executed in one execution stage are called single-ended. Single-point commands include most fixed-point operations. Floating-point commands, even basic multiplication and addition, are 4-stroke commands. Memory reference commands, transition commands and many others are not single-ended. The difference in the execution times of different commands determines the existence of various restrictions on the sharing of commands and processor resources. All this makes the processor programming process, especially at a low level, a rather difficult task. However, this concept, as already mentioned, underlies the entire C6000 platform.
Work with interruptions is organized in the same way as other models of C6000 processors. Interrupt types: restart, nonmaskable interrupt, masked interrupts and exceptions. The special register contains the address of the interrupt vector table. The table contains a set of codes for each of the interrupts. If the interrupt handling is simple, all relevant code can be written directly to the table itself. If the code does not fit, it is necessary to organize the transition to the interrupt handling procedure.
Usually, when responding to an interrupt, other masked interrupts are disabled. However, artificially it is possible to organize nested interrupt handling due to special code fragments described in the documentation.
All articles of the cycle:
- Processor architecture overview
- Operational kernels: processor computing resources
Source: https://habr.com/ru/post/331842/
All Articles