Apache Spark: from open source to industry
Alyona Lazareva, freelance editor, specifically for the Netology blog, wrote a review article about one of the popular tools of the Big Data specialist, the Apache Spark framework.
People often do not realize how Big Data affects their lives. But every person is a source of big data. Big Data specialists collect and analyze digital traces: likes, comments, watching videos on Youtube, GPS data from our smartphones, financial transactions, behavior on websites and much more. They are not interested in every person, they are interested in patterns.

Understanding these patterns helps to optimize advertising campaigns, predict the customer's need for a product or service, assess the mood of users.
')
According to surveys and studies, Big Data is most often implemented in the areas of marketing and IT, and only after that research, direct sales, logistics, finance, and so on, go.

Special tools have been developed for working with big data. The most popular today is Apache Spark.
Apache Spark is an open source framework for parallel processing and analysis of semi-structured in-memory data.
The main advantages of Spark are performance, user-friendly software interface with implicit parallelization and fault tolerance. Spark supports four languages: Scala, Java, Python, and R.
The framework consists of five components: the core and four libraries, each of which solves a specific task.
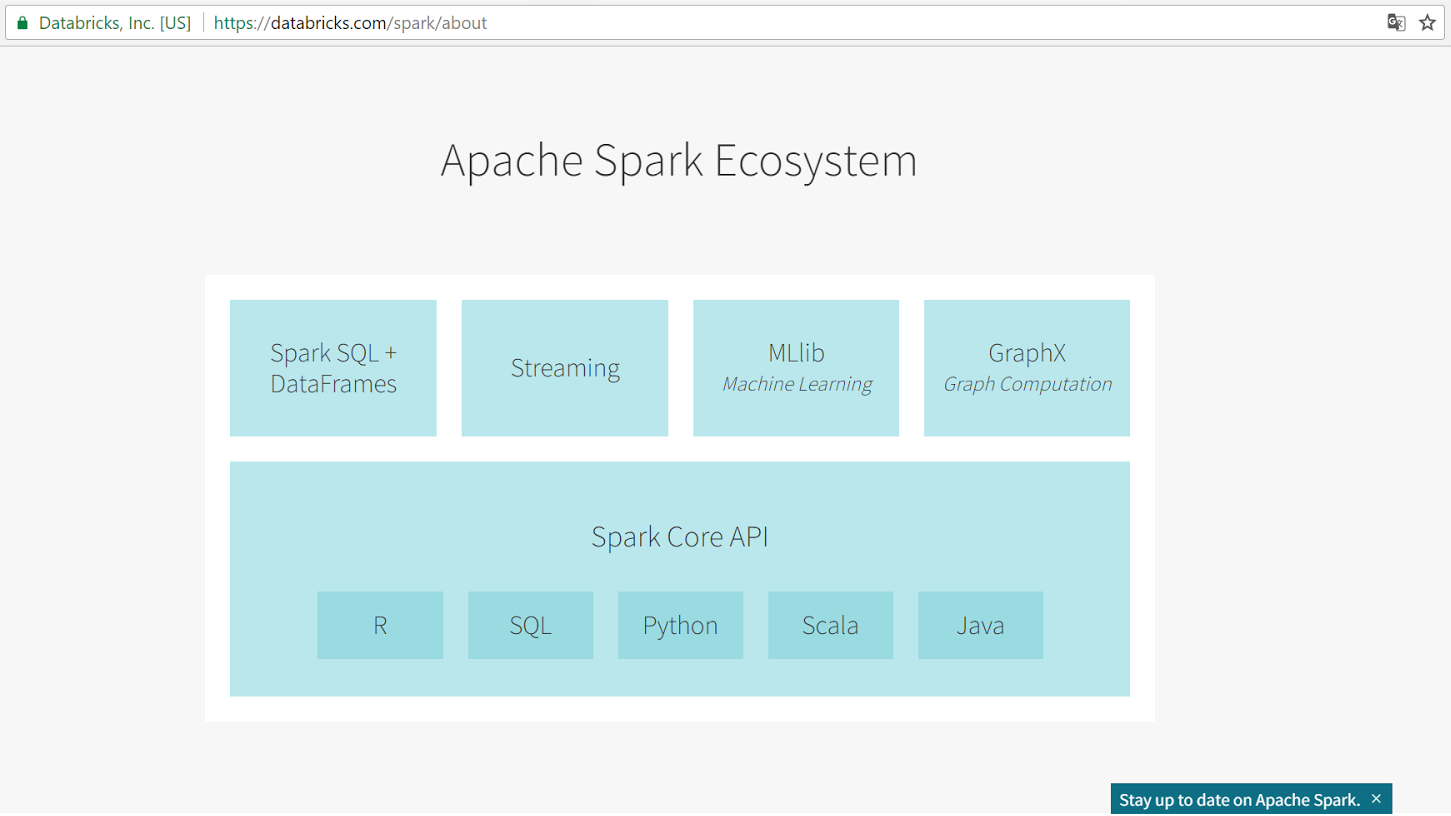
Spark Core is the foundation of the framework. It provides distributed scheduling, scheduling, and basic I / O functions.
Spark SQL is one of the four libraries of the framework for structured data processing. It uses a data structure called DataFrames and can act as a distributed SQL query mechanism. This allows you to perform Hadoop Hive queries up to 100 times faster.
Spark Streaming is an easy-to-use stream processing tool. Despite the name, Spark Streaming does not process data in real time, but does it in micro-batch mode. The creators of Spark claim that the performance suffers from this slightly, since the minimum processing time for each micro-batch is 0.5 seconds.
The library allows you to use batch-analysis application code for stream analytics, which facilitates the implementation of the λ-architecture.
Spark Streaming seamlessly integrates with a wide range of popular data sources: HDFS, Flume, Kafka, ZeroMQ, Kinesis, and Twitter.
MLlib is a high-speed distributed machine learning system. It is 9 times faster than its rival - Apache Mahout libraries when testing with benchmarks on the Alternate Least Squares (ALS) algorithm.
MLlib includes popular algorithms:
GraphX is a library for scalable graph data processing. GraphX is not suitable for graphs that are modified by a transactional method: for example, databases.
Spark works:
It also supports several distributed storage systems:
The first framework for working with Big Data was Apache Hadoop, implemented on the basis of MapReduce technology.
In 2009, a group of graduate students from the University of California at Berkeley developed an open source cluster management system - Mesos. In order to show all the capabilities of their product and how easy it is to manage the Mesos-based framework, the same group of graduate students began working on Spark.
As planned by the creators, Spark was supposed to become not just an alternative to Hadoop, but also surpass it.
The main difference between the two frameworks is the way data is accessed. Hadoop saves data to the hard disk at each step of the MapReduce algorithm, and Spark performs all operations in RAM. Thanks to this, Spark gains performance up to 100 times and allows data to be processed in the stream.
In 2010, the project was published under the BSD license, and in 2013 it was licensed under the Apache Software Foundation, which sponsors and develops promising projects. Mesos also caught the attention of Apache and came under its license, but did not become as popular as Spark.
According to a survey conducted by the Apache fund in 2016, more than 1,000 companies use Spark. It is used not only in marketing. Here are some of the tasks that companies do with Spark.
With the development of the need for collecting, analyzing and processing big data, new frameworks are emerging. Some large corporations develop their own product, taking into account internal tasks and needs. For example, this is how Beam from Google and Kinesis from Amazon appeared. If we talk about frameworks that are popular among a wide range of users, then besides the already mentioned Hadoop, you can call Apache Flink, Apache Storm and Apache Samza.
We compared four frameworks under the Apache license by key indicators:

Each framework has its strengths and weaknesses. So far, none of them is universal and can not replace the rest. Therefore, when working with big data, companies choose the framework that is best suited for solving a particular problem. Some companies simultaneously use multiple frameworks, such as TripAdvisor and Groupon.
Apache Spark is the most popular and fast-developing framework for working with Big Data . Good technical parameters and four additional libraries allow using Spark for solving a wide range of tasks.
Of the unobvious advantages of the framework - numerous Spark-community and a large amount of information about it in the public domain. Of the obvious drawbacks - the delay in data processing is greater than that of frameworks with a streaming model.
People often do not realize how Big Data affects their lives. But every person is a source of big data. Big Data specialists collect and analyze digital traces: likes, comments, watching videos on Youtube, GPS data from our smartphones, financial transactions, behavior on websites and much more. They are not interested in every person, they are interested in patterns.
Understanding these patterns helps to optimize advertising campaigns, predict the customer's need for a product or service, assess the mood of users.
')
According to surveys and studies, Big Data is most often implemented in the areas of marketing and IT, and only after that research, direct sales, logistics, finance, and so on, go.
Special tools have been developed for working with big data. The most popular today is Apache Spark.
What is Apache Spark
Apache Spark is an open source framework for parallel processing and analysis of semi-structured in-memory data.
The main advantages of Spark are performance, user-friendly software interface with implicit parallelization and fault tolerance. Spark supports four languages: Scala, Java, Python, and R.
The framework consists of five components: the core and four libraries, each of which solves a specific task.
Spark Core is the foundation of the framework. It provides distributed scheduling, scheduling, and basic I / O functions.
Spark SQL is one of the four libraries of the framework for structured data processing. It uses a data structure called DataFrames and can act as a distributed SQL query mechanism. This allows you to perform Hadoop Hive queries up to 100 times faster.
Spark Streaming is an easy-to-use stream processing tool. Despite the name, Spark Streaming does not process data in real time, but does it in micro-batch mode. The creators of Spark claim that the performance suffers from this slightly, since the minimum processing time for each micro-batch is 0.5 seconds.
The library allows you to use batch-analysis application code for stream analytics, which facilitates the implementation of the λ-architecture.
Spark Streaming seamlessly integrates with a wide range of popular data sources: HDFS, Flume, Kafka, ZeroMQ, Kinesis, and Twitter.
MLlib is a high-speed distributed machine learning system. It is 9 times faster than its rival - Apache Mahout libraries when testing with benchmarks on the Alternate Least Squares (ALS) algorithm.
MLlib includes popular algorithms:
- classification,
- regression,
- decision trees
- recommendation,
- clustering
- thematic modeling.
GraphX is a library for scalable graph data processing. GraphX is not suitable for graphs that are modified by a transactional method: for example, databases.
Spark works:
- among the Hadoop clusters on YARN,
- running Mesos,
- in the cloud on AWS or other cloud services,
- completely autonomous.
It also supports several distributed storage systems:
- HDFS
- OpenStack Swift,
- NoSQL-DBMS,
- Cassandra,
- Amazon S3,
- Kudu,
- MapR-FS.
How come
The first framework for working with Big Data was Apache Hadoop, implemented on the basis of MapReduce technology.
In 2009, a group of graduate students from the University of California at Berkeley developed an open source cluster management system - Mesos. In order to show all the capabilities of their product and how easy it is to manage the Mesos-based framework, the same group of graduate students began working on Spark.
As planned by the creators, Spark was supposed to become not just an alternative to Hadoop, but also surpass it.
The main difference between the two frameworks is the way data is accessed. Hadoop saves data to the hard disk at each step of the MapReduce algorithm, and Spark performs all operations in RAM. Thanks to this, Spark gains performance up to 100 times and allows data to be processed in the stream.
In 2010, the project was published under the BSD license, and in 2013 it was licensed under the Apache Software Foundation, which sponsors and develops promising projects. Mesos also caught the attention of Apache and came under its license, but did not become as popular as Spark.
How to use
According to a survey conducted by the Apache fund in 2016, more than 1,000 companies use Spark. It is used not only in marketing. Here are some of the tasks that companies do with Spark.
- Insurance companies are optimizing the claims recovery process.
- Search engines identify fake social media accounts and improve targeting.
- Banks predict the demand for certain banking services from their customers.
- Taxi services analyze time and geolocation to predict demand and prices.
- Twitter analyzes large volumes of tweets to determine the mood of users and attitudes towards a product or company.
- Airlines build models to predict flight delays.
- Scientists analyze weather disasters and predict their appearance in the future.
Alternatives
With the development of the need for collecting, analyzing and processing big data, new frameworks are emerging. Some large corporations develop their own product, taking into account internal tasks and needs. For example, this is how Beam from Google and Kinesis from Amazon appeared. If we talk about frameworks that are popular among a wide range of users, then besides the already mentioned Hadoop, you can call Apache Flink, Apache Storm and Apache Samza.
We compared four frameworks under the Apache license by key indicators:
Each framework has its strengths and weaknesses. So far, none of them is universal and can not replace the rest. Therefore, when working with big data, companies choose the framework that is best suited for solving a particular problem. Some companies simultaneously use multiple frameworks, such as TripAdvisor and Groupon.
Summarizing
Apache Spark is the most popular and fast-developing framework for working with Big Data . Good technical parameters and four additional libraries allow using Spark for solving a wide range of tasks.
Of the unobvious advantages of the framework - numerous Spark-community and a large amount of information about it in the public domain. Of the obvious drawbacks - the delay in data processing is greater than that of frameworks with a streaming model.
Source: https://habr.com/ru/post/331728/
All Articles