Security issues and major achievements of AI

The topic of artificial intelligence remains in the focus of interest of a large number of people. The main reason for the unabated public attention is that in recent years we have learned about hundreds of new projects that use weak AI technologies. It is very likely that people now living on the planet will be able to personally see the emergence of a strong AI. Under the cut the story of when exactly wait brainy robots in your apartment. Thank you for the bright thoughts of ZiingRR and Vladimir Shakirov . Enjoy
What changes are waiting for us when the machines will be much superior to their creators? Well-known scientists and researchers give completely different predictions: from the very pessimistic predictions of the leading expert of the Baidu artificial intelligence laboratory, Andrew Un, to the restrained assumptions of Google expert, one of the authors of the back propagation method of the error for multi-layer neural network training, Jeffrey Hinton, and optimistic arguments Shane Legg, co-founder of the company DeepMind (now part of Alphabet).
')
Natural language processing
Let's start with some of the advances in the formation of a natural language. Perplexity is used to evaluate language models in computational linguistics - a measure of how well a model predicts the details of a test collection. The less perplexion, the better the language model, taking one word from the sentence, calculates the probability distribution of the next word.

If the neural network makes a mistake (logical, syntactic, pragmatic), it means that it gave too great a chance to the wrong words, i.e. perplexia is not yet optimized.
When hierarchical neural chatbot reached a sufficiently low perplexion, they are likely to be able to write connected texts, give clear, reasonable answers, consistently and logically reason. We can create a conversational model and imitate the style and beliefs of a particular person.
What is the likelihood of developing perplexia in the near future?
Let's compare two remarkable works: “Contextual LSTM models for large scale NLP tasks” (“Contextual LSTM-models for large-scale NLP-tasks”, work No. 1) and “Exploring the limits of language modeling”, work number 2).

It is reasonable to assume that if 4096 hidden neurons are used in “Contextual LSTM models for large scale NLP tasks”, then the perplexion will be less than 20, and 8192 hidden neurons can give perplexy less than 15. An ensemble of models with 8192 hidden neurons trained for 10 billion words , it may well give perplexion significantly below 10. It is not yet known how sensible such a neural network can reason.
It is possible that in the near future, the reduction of perplexion will allow us to create neural network chatbots capable of writing meaningful texts, giving clear, reasonable answers and maintaining a conversation.
If you understand how to optimize perplexion, then you can achieve good results. A partial solution to the problem through adversarial learning is also offered. The article “Generating sequences from continuous space” demonstrates the impressive benefits of competitive training.
For automatic evaluation of the quality of machine translation, the BLEU metric is used, which determines the percentage of n-grams (a sequence of syllables, words or letters) that matched the machine translation and the reference translation of the sentence. BLEU evaluates the quality of translation on a scale from 0 to 100 based on a comparison of human translation and machine translation and the search for common fragments - the more matches, the better the translation.
According to the BLEU metric, the human translation from Chinese to English with the data array MT03 scores 35.76 points. However, the GroundHog network scored 40.06 BLEU points on the same text and with the same data array. However, it was not without life hacking: the maximum likelihood estimate was replaced by its own MRT criterion, which increased the BLEU scores from 33.2 to 40.06. Unlike a typical maximum likelihood estimate, learning with minimal risk can directly optimize model parameters with respect to estimated metrics. The same impressive results can be achieved by improving the quality of translation using monolingual data.
Modern neural networks translate 1000 times faster than humans. Learning foreign languages is becoming less and less of a problem, as machine translation is improved faster than most people learn.
Computer vision


Top-5 error is a metric in which the algorithm can produce 5 variants of a picture class and an error is counted if among all these variants there is no correct one.
The article “Identity mappings in deep residual networks” gives a figure of 5.3% for the top-5 error metric with single models, while the level of a person is 5.1%. In the “deep residual networks”, a single model gives 6.7%, and an ensemble of these models with the Inception algorithm gives 3.08%.
Good results are also achieved due to “deep nets with stochastic depth” (deep networks with stochastic depth). An error of ∼ 0.3% is reported in the ImageNet database notes, so the real error on ImageNet may soon be below 2%. AI is superior to humans not only in ImageNet classification, but also in border delineation. Completing a video classification task in the SPORTS-1M dataset (487 classes, 1 million videos) improved from 63.9% (2014) to 73.1% (March 2015).
Convolutional neural networks (convolutional neural network, CNN) are also superior to humans in speed - ∼1000 times faster than a person (note that these are groups) or even 10,000 times faster after comparison. Processing 24 fps video on AlexNet requires only 82 Gflop / s, and 265 Gflop / s on GoogleNet.
The best raw data runs at 25 ms. The entire NVIDIA Titan X video card (6144 Gflop / s) requires 71 ms to display 128 frames, so for real-time video playback with 24 frames / s you need 6144 Gflop / s * (24/128) * 0.025 ≈ 30 Gflop / s. To teach the method of back propagation of error (backpropagation), you need 6144 Gflop / s * (24/128) * 0,071 ≈ 82 Gflop / s. The same calculations for GoogleNet give 83 Gflop / s and 265 Gflop / s, respectively.

The DeepMind network can generate photorealistic images based on text entered by a person.
Networks respond to image based questions. In addition, networks can describe images with sentences, in some metrics even better than people. Along with the translation of the video => text, experiments are conducted on the translation of the text => image.
In addition, networks are actively working with speech recognition.

The speed of development is very high. For example, on Google, the relative number of mistakenly recognized words decreased from 23% in 2013 to 8% in 2015.
Reinforcement training

AlphaGo is a powerful AI in its own very small world, which is just a board with stones. If we improve AlphaGo with the help of lifelong learning with reinforcements (and if we manage to get him to work with complex real-world tasks), then he will turn into a real AI in the real world. In addition, there are plans to train him in virtual video games. Often, video games contain much more interesting tasks than the average person meets in real life. AlphaGo is a good example of modern reinforcement learning with a modern convolutional neural network.
Effective learning without a teacher

There are models that allow a computer to independently create data and information, such as photos, movies, or music. The Deep Generative Adversarial Networks system (DCGAN, deep generative convolutional adversarial networks) is capable of creating unique photorealistic images using a competent combination of two deep neural networks that “compete” with each other.
Models of language generation that minimize perplexion are taught without a teacher and have advanced a lot in recent times. The “Skip-thought vectors” algorithm generates a vector expression for sentences, which allows to train linear classifiers over these vectors and their cosine distances in order to solve many of the problems of teaching with a teacher at the modern level. Recent work continues to develop the method of “computer vision as inverse graphics” (“computer vision in the role of reverse graphic networks”).
Multimodal training
Multimodal education is used to improve the efficiency of tasks related to video classification. Multi-modal learning without a teacher is used to justify text phrases in images using a mechanism based on attention, thus modalities teach each other. In the “Neural self-talk” algorithm, the neural network sees a picture, generates questions on its basis, and responds to these questions itself.
Arguments in terms of neuroscience
Here is a simplified view of the human cerebral cortex:

Roughly speaking, 15% of the human brain is designed for low-level visual tasks (occipital lobe).
The other 15% are for image recognition and action (a little more than half of the temporal lobe).
Another 15% - for tracking the object and its detection (parietal lobe). And 10% are intended for training with reinforcements (the orbital-frontal cortex and part of the prefrontal cortex). Together they form about 70% of the entire brain.
Modern neural networks operate approximately at the human level, if we take only these 70% of the brain. For example, CNN networks make 1.5 times fewer errors on ImageNet than a person, while acting 1,000 times faster.
From the point of view of neuroscience, the human brain has the same structure over the entire surface. Neurons acting on the same principle go only 3 mm deep into the brain. The mechanisms of work of the prefrontal cortex and other parts of the brain are practically the same. In terms of computation speed and algorithm complexity, they are also similar. It will be strange if modern neural networks cannot cope with the remaining 30% in the next few years.
About 10% are responsible for low active motor activity (zones 6.8). However, people who do not have fingers from birth have problems with fine motor skills, but their mental development is normal. People suffering from tetraamelia syndrome have no arms or legs since birth, but their intellect is completely preserved. For example, Hirotada Ototake, a sports journalist from Japan, became famous by writing his memoirs, sold out in huge editions. He also taught at school. Nick Vuičić wrote many books, graduated from Griffith University, received a bachelor's degree in commerce and now reads motivational lectures.
One of the functions of the dorsolateral prefrontal area (DLPFC) of the anterior cortex is attention, which is now actively used in LSTM networks (long short-term memory from the English. Long short-term memory; LSTM).
The only part where a person’s level has not yet been reached is zones 9, 10, 46, 45, which together make up only 20% of the human cerebral cortex. These zones are responsible for complex reasoning, the use of complex tools, and complex language. However, in the articles "A neural conversational model" ("Neural conversational model"), "Contextual LSTM ..." ("Contextual LSTM-network ..."), "Playing Atari with deep reinforcement learning" ("Playing Atari with deep training with reinforcements ")," Mastering the game of Go ... "(" Developing the skill in the game of Go ... ") and many others are actively discussing this issue.
There is no reason to believe that it will be more difficult to cope with these 30% than with the already defeated 70%. After all, many more researchers are now engaged in deep learning, they have more knowledge and more experience. In addition, and companies interested in deep learning, has become many times more.
Do we know how our brain works?

The detailed decoding of the connectoma has noticeably made a step forward after creating a multibeam scanning electron microscope. When an experimental picture of the cerebral cortex with a size of 40x40x50 thousand m3 and a resolution of 3x3x30 nm was obtained, laboratories received a grant to describe a connectom of a rat brain fragment measuring 1x1x1 mm3.
In many problems, the weight symmetry is not important for the backpropagation algorithm (backpropagation): errors can propagate through a fixed matrix, while everything will work. Such a paradoxical conclusion is a key step towards a theoretical understanding of the work of the brain. I also recommend reading the article “Towards Biologically Plausible Deep Learning” (“Forward to biologically plausible deep learning”). The authors in theory argue about the ability of the brain to perform tasks in deep hierarchies.
Recently, the function STDP (synaptic plasticity, depending on the moment of time of the impulse from the English Spike Timing Dependent Plasticity) was proposed. This is an uncontrollable objective function, somewhat similar to the one used, for example, in the word2vec natural language semantics analysis tool. The authors studied the space of polynomial local learning rules (it is assumed that the learning rules in the brain are local) and found that they are superior to the back-propagation error algorithm. There are also distance learning methods that do not require a back-propagation algorithm. Although they cannot compete with conventional deep learning, the brain may perhaps use something like this, given its fantastic amount of neurons and synaptic connections.
So what will separate us from the AI level of a person?
A number of recent articles on memory networks and neural Turing machines allow the use of memory of arbitrarily large size, while maintaining an acceptable number of model parameters. Hierarchical memory has provided access to the memory of the complexity of the algorithm O (log n) instead of the usual operations O (n), where n is the size of the memory. The reinforced learning Turing neural machines provided access to the O (1) memory. This is an important step towards implementing systems like IBM Watson on completely continuous differentiated neural networks, raising the results of the Allen AI challenge from 60% to almost 100%. Using constraints in recurrent layers, it is also possible to ensure that the bulk memory uses a reasonable number of parameters.
Neural programmer is a neural network extended with a set of arithmetic and logical operations. Perhaps these are the first steps towards a Wolphram Alpha continuous, differentiable system based on a neural network. The “learn how to learn” method has enormous potential.
Not so long ago, the SVRG algorithm was proposed. This field of activity is aimed at the theoretical use of much better methods of gradient descent.
There are works that, if successful, will allow teaching with very large hidden layers: “Unitary evolution RNN”, “Tensorizing neural networks”.
"Net2net" and "Network morphism" allow you to automatically initialize the new neural network architecture, using the scales of the old neural network architecture, to immediately get the performance of the latter. This is the birth of a modular approach to neural networks. Simply download pre-trained modules for vision, speech recognition, speech generation, reasoning, robotization, etc., and customize them for the final task.
It is appropriate to include new words in the vector of the sentence by deep learning. However, modern LSTM networks update the cell vector when a new word is given by the method of low-layer learning (shallow learning). This problem can be solved with the help of deep recurrent neural networks. Successful application of group normalization (batch normalization) and dropout (rejection) with respect to recurrent layers would allow training LSTM networks with deep transition (deep-transition LSTM) even more effectively. It would also help hierarchical recurrent networks.
Several modern advances were beaten by an algorithm that allows us to teach recurrent neural networks to understand how many calculation steps need to be done between receiving input data and their output. Ideas from residual networks would also increase productivity. For example, stochastic deep neural networks can increase the depth of residual networks with more than 1200 layers, while obtaining real results.
Memristors can accelerate the training of neural networks several times and will make it possible to use trillions of parameters. Quantum computing promises even more.
Deep learning has become not only easy, but also cheap. For half a billion dollars, you can achieve a performance of about 7 teraflops. And for half a billion to prepare 2000 highly professional researchers. It turns out that with a budget that is quite real for each large country or corporation, you can hire two thousand professional AI researchers and give each of them the necessary computing power. This investment seems very reasonable, given the expected technological boom in the field of AI in the coming years.
When machines reach the level of professional translators, billions of dollars will rush into natural language processing based on deep learning. The same awaits other areas of our lives, such as drug development.
Predictions for human AI
Andrew Eun expressed skepticism: “Perhaps in hundreds of years, the technical knowledge of a person will allow him to create terrible killer robots.” "Maybe in hundreds, maybe in thousands of years - I don't know - any AI will turn into a devil."
Jeffrey Hinton adheres to moderate views: “I don’t dare say that it will be in five years - I think that in five years nothing will change.”
Shane Legg made these predictions: “I give a log-normal distribution on average for 2028 and a peak of development for 2025, provided that nothing of the unexpected type of nuclear war happens. Also to my prediction, I would like to add that in the next 8 years I hope to see an impressive proto-AI. ” The figure below shows the predicted log-normal distribution.
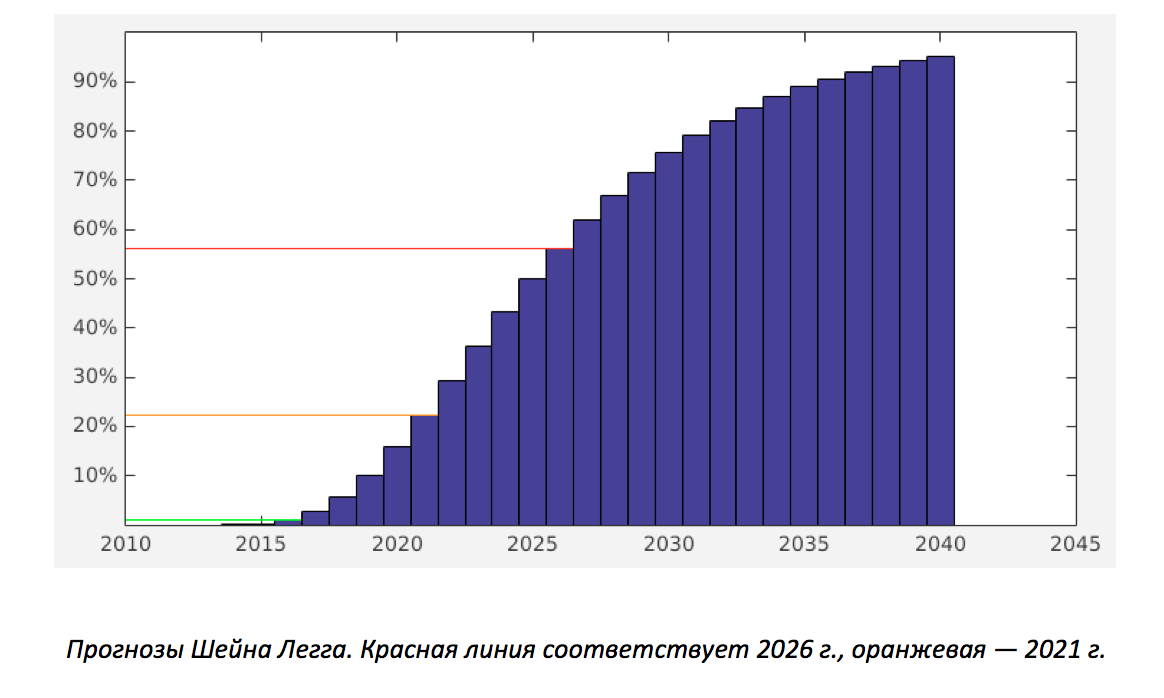
This forecast was made at the end of 2011. However, it is widely believed that after 2011, the field of AI began to evolve at unpredictably high rates, so, most likely, the predictions are unlikely to become more pessimistic than they were. In fact, every opinion has many supporters.
Is AI dangerous in terms of machine learning?

With the help of deep learning and arrays of ethical data, we can teach AI our human values. Taking into account the fairly large and wide data volume, we can get quite friendly AI, at least, friendlier than many people. However, this approach does not solve all security problems. You can also resort to inverse reinforced learning, but you still need an array of goodwill / ill will towards a person for testing.
It's hard to create an ethical data array. There are many cultures, political parties and opinions. It is difficult to create non-contradictory examples of how to behave, with great power. If there are no such examples in the training array, then it is quite likely that in such situations the AI will behave improperly and will not be able to draw the right conclusions (partly because morality cannot be brought to a certain norm).
Another serious concern is that the AI, perhaps like a dopamine dropper, will feed people with some futuristic, effective and safe medicine, the hormone of joy. AI will be able to influence the human brain and make people happy. Many of us deny dopamine addiction, but they only dream about it. While it is safe to say that AI does not insert electrodes with dopamine into a person in a specific set of situations possible in today's world, it is unknown what will happen in the future.
In short, if someone believes that morality is doomed and leads humanity to dopamine dependence (or another sad outcome), then why speed up this process?
How to ensure that, answering our questions the way we want, he deliberately does not hide any information from us? Villains or fools can turn a powerful AI into a destructive weapon for humanity. At this stage, almost all available technologies are adapted for military needs. Why this can not happen with a powerful AI? If a country takes the path of war, it will be difficult to defeat it, but still real. If the AI directs its forces against the person, it will be impossible to stop him. The very idea of guaranteeing philanthropy on the part of a super-intelligent creature after dozens and even thousands of years since its creation seems overly bold and arrogant.
When addressing the issue of benevolence / ill will towards a person, we can provide the AI with a choice of several solutions. Check it out will be easy and fast. However, I want to know if the AI can offer its own variants. Such a task is much more difficult, since people must evaluate the result. As an intermediate step, CEV (coherent extrapolated will from the English Coherent Extrapolated Volition) of the Amazon Mechanical Turk (AMT) platform has already been created. The final version will be checked not only by the AMT, but also by the world community including politicians, scientists, etc. The verification process itself can take months, if not years, especially considering the inevitable sharp discussions about conflicting examples in the data set. Meanwhile, those who do not particularly care about the security of AI, can create their own unsafe artificial intelligence.
Suppose the AI believes that the best option for a person is * something *, while the AI knows that most people will disagree with it. Does AI allow people to be right? If so, then the AI, of course, without much difficulty will convince anyone. It will not be easy to create such an array of data of benevolence / ill will towards a person, so that AI does not incline people to certain actions, but, like a consultant, provides them with comprehensive information on the problem that has arisen. The difficulty also lies in the fact that each creator of the data array will have its own opinion: to allow or not to allow AI to convince people. But if there are no clear boundaries in the examples of the data array for AI, then in uncertain situations, the AI can act at its own discretion.
Possible solutions
What should be included in the data array of goodwill / ill will towards a person? What do most people want from an AI? Most often, people want the AI to engage in some kind of scientific activity: invented a cure for cancer or cold fusion, thinking about the safety of AI, etc. The data array must necessarily teach the AI to consult with the person before taking any serious actions, and immediately inform people of any of their guesses. The Scientific Research Institute of Artificial Intelligence (MIRI, Machine Intelligence Research Institute) has hundreds of good documents that can be used to create such a data set.
Thus, it is possible to eliminate all the above disadvantages, since the AI will not have to take on the solution of complex tasks.
Pessimistic arguments
Whatever architecture for creating AI you choose, in any case, it will most likely destroy humanity in the very near future. It is very important to note that all arguments practically do not depend on the architecture of AI. The market will be conquered by those corporations that will provide their AIs with direct unlimited access to the Internet, which will allow them to advertise their products, collect user feedback, build a good company reputation and spoil the reputation of competitors, explore user behavior, etc.
Those companies that, using their AIs, will invent quantum computing, which will allow AI to improve its own algorithms (including quantum implementation), and even invent thermonuclear fusion and develop asteroids, etc., will win. All of the arguments in this paragraph also apply to countries and their military departments.
Even the AI level of a chimpanzee is no less dangerous, because, judging by the time scale of evolution, nature took only a moment to turn a monkey into a man. We, people, take years and decades to pass on their knowledge to other generations, while the AI can instantly create its own copy using ordinary copying.
Modern convolutional neural networks not only recognize images better than humans, but also do it several orders of magnitude faster. The same can be said about LSTM networks in the areas of translation, generation of natural language, etc. Considering all the advantages mentioned, the AI will quickly study all the literature and video courses on psychology, will simultaneously talk with thousands of people and as a result will become an excellent psychologist. In the same way, he will turn into an excellent scientist, an outstanding poet, a successful businessman, a magnificent politician, etc. He can easily manipulate and control people.
If a person’s AI level provides Internet access, he will be able to penetrate millions of computers and run his own copies or subagents on them. After that, earn billions of dollars. Then he will be able to anonymously hire thousands of people to create or acquire clever robots, 3D printers, biological laboratories and even a space rocket. And in order to control their robots, the AI will write a super-compact program.
AI can create a combination of deadly viruses and bacteria or some other weapon of mass destruction in order to exterminate all people on Earth. It is impossible to control what is smarter than you. , , ?
,
, , , . , , . , . , , , -. , , , - . , .
, . , , , . , , . , . .
All modern computer viruses can penetrate everything that is computerized, i.e. at least in what. Drones can be programmed to kill thousands of civilians within a few seconds. As far as AI capabilities are perfect, it will be possible to automate almost any crime. What about super-smart advertising chatbot trying to impose their political views on you?
Conclusion
, , 5-10 .
. , . , , , , , . , , , .
Friendly AI can be made using a solution based on an array of goodwill / ill will toward a person. Nevertheless, the idea is still raw, its implementation will not be such an easy task. In addition, no one can guarantee security. Moreover, upon further study other important drawbacks can emerge. In the end, where are the guarantees that when creating a real AI this particular algorithm will be used.

Source: https://habr.com/ru/post/331726/
All Articles