Tuning a Linux network stack for the lazy
The Linux network stack works fine on desktops by default. On servers with a load slightly above average, you already have to figure out how to properly configure everything. At my current job, this has to be done almost on an industrial scale, so without automation there is no need to explain to each colleague what was arranged for a long time and force people to read ≈300 pages of English text mixed with C code ... You can and should, but the results will not be in an hour or a day. Therefore, I tried to distribute a set of utilities for tuning the network stack and a guide to using them, which does not go into specific details of certain tasks, which remains compact enough so that it can be read in less than an hour and take at least some favor
What needs to be achieved?
The main task in tuning the network stack (no matter what role the server performs - a router, a traffic analyzer, a web server that accepts large amounts of traffic) is to evenly distribute the processing load between the processor cores. Preferably, taking into account that the CPU and the network card belong to the same NUMA node, and without creating unnecessary packet swapping between the cores.
Before the main task, the primary task is performed - selection of the hardware, of course, taking into account what tasks lie on the server, where and how much traffic comes from and how, etc.
Recommendations for the selection of iron
- A dual-processor server will not be useful if traffic arrives on only one network card.
- Separate NUMA nodes will not be useful if traffic arrives at the ports of a single network card.
- It makes no sense to buy a server with a number of cores greater than the total number of queues of network cards.
- In the case of network cards with a single queue to distribute the load between the cores, you can use the RPS, but the loss when copying packets into memory does not eliminate it.
- Hyper-Threading is useless and turns off in the BIOS (especially in Skylake and Kaby Lake with problems)
- Choose a processor with a core frequency of at least 2.5GHz and a large amount of L3 and other caches.
- Use DDR4 memory.
- Choose network cards that support RX-buffers up to 2048 or more.
Thus, if a 2+ source of traffic volume is given more than 2 Gbit / s, then you should think about the server with the number of processors and NUMA nodes, as well as the number of network cards (not ports) equal to the number of these sources.
"Lord, I do not want to understand this!"
And do not. I already figured out and, in order not to waste time trying to explain this to my colleagues, I wrote a set of utilities - netutils-linux . Written in Python, tested on versions 2.6, 2.7, 3.4, 3.6.
network top
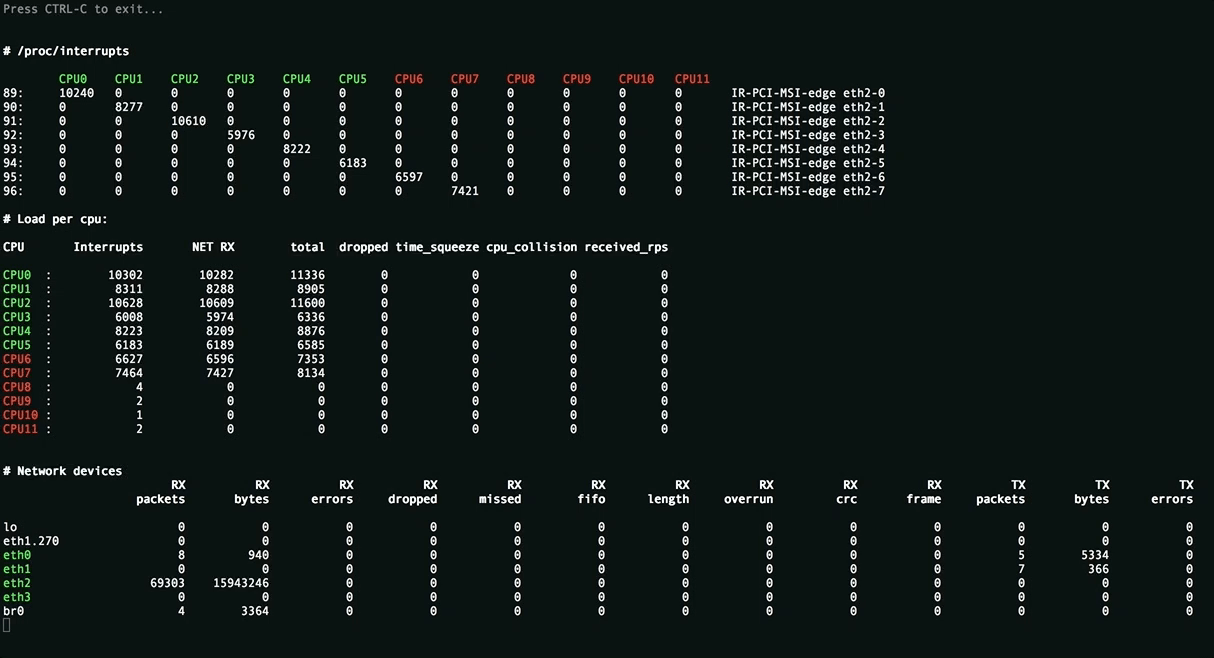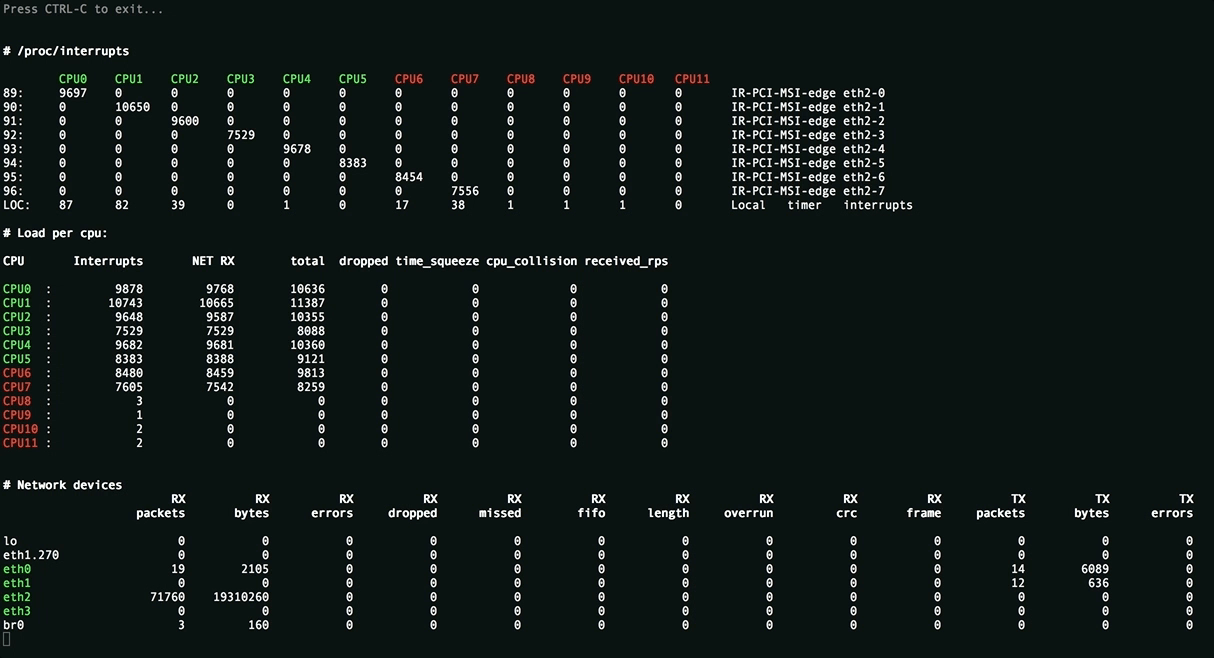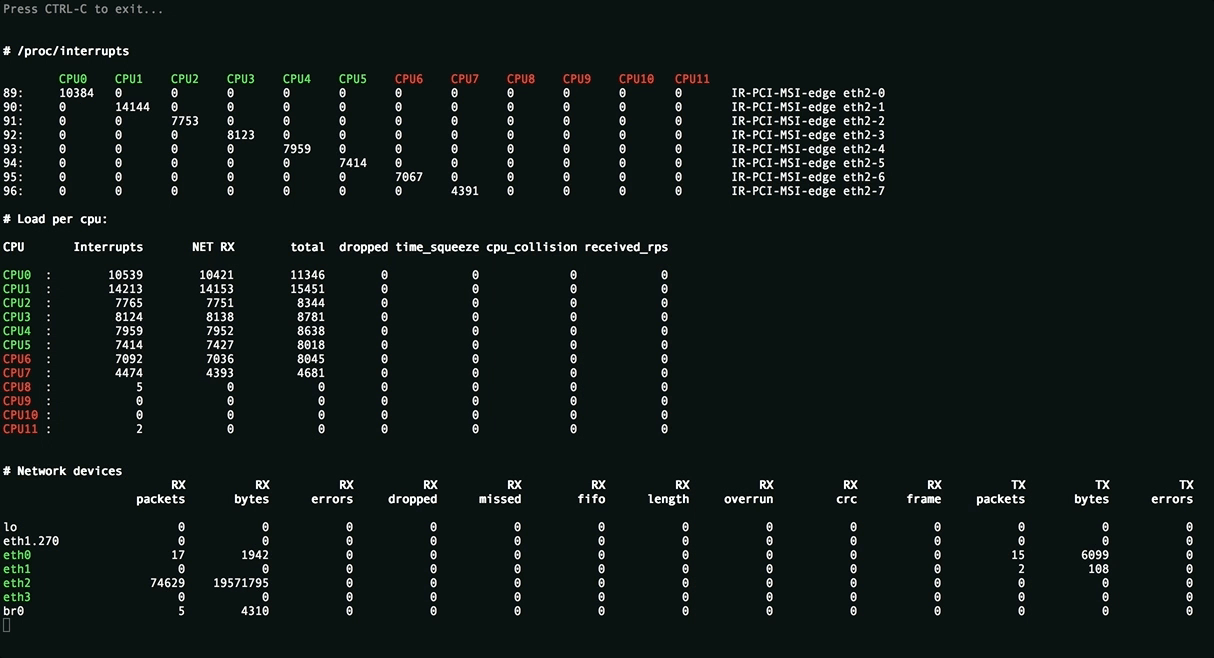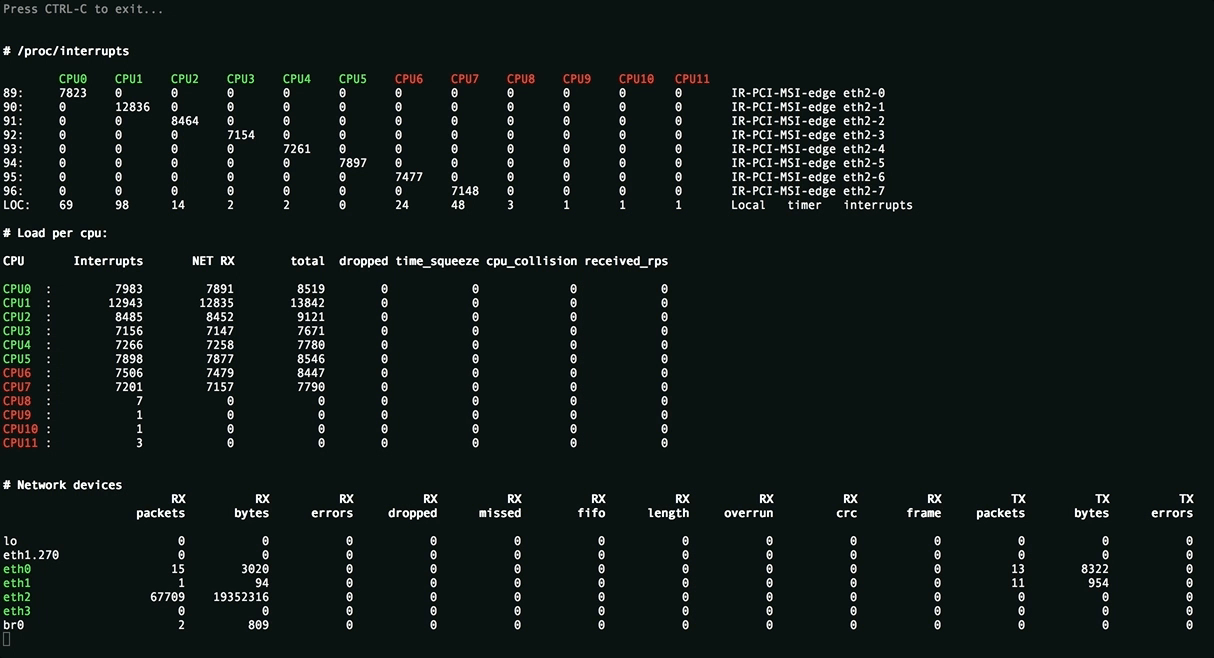
This utility is needed to assess the applied settings and displays the uniform distribution of the load (interrupts, softirqs, the number of packets per second per processor core) on server resources, all sorts of packet processing errors. Values above threshold are highlighted.
rss-ladder
# rss-ladder eth1 0 - distributing interrupts of eth1 (-TxRx) on socket 0:" - eth1: irq 67 eth1-TxRx-0 -> 0 - eth1: irq 68 eth1-TxRx-1 -> 1 - eth1: irq 69 eth1-TxRx-2 -> 2 - eth1: irq 70 eth1-TxRx-3 -> 3 - eth1: irq 71 eth1-TxRx-4 -> 8 - eth1: irq 72 eth1-TxRx-5 -> 9 - eth1: irq 73 eth1-TxRx-6 -> 10 - eth1: irq 74 eth1-TxRx-7 -> 11 This utility distributes the network card interrupts to the cores of the selected physical processor (zero by default).
autorps
# autorps eth0 Using mask 'fc0' for eth0-rx-0. This utility allows you to configure the distribution of packet processing between the cores of the selected physical processor (the default is zero). If you use RSS, most likely you will not need this utility. A typical use case is a multi-core processor and network cards with a single queue.
server-info
# server-info rate cpu: BogoMIPS: 7 CPU MHz: 7 CPU(s): 1 Core(s) per socket: 1 L3 cache: 1 Socket(s): 10 Thread(s) per core: 10 Vendor ID: 10 disk: vda: size: 1 type: 1 memory: MemTotal: 1 SwapTotal: 10 net: eth1: buffers: cur: 5 max: 10 driver: 1 queues: 1 system: Hypervisor vendor: 1 Virtualization type: 1 This utility allows you to do two things:
server-info show: see what kind of hardware is installed on the server. In general, it looks like a bicycle that repeatslshw, but with an emphasis on the parameters of interest.server-info rate: find bottlenecks in server hardware. In general, it is similar to the Windows performance index, but again with an emphasis on the parameters we are interested in. Evaluation is made on a scale from 1 to 10.
Other utilities
rx-buffers-increaseautomatically increases the buffer of the selected network card to the optimal value.maximize-cpu-freqdisables the floating frequency of the processor. Power consumption will be increased, but this is not a laptop without a charger, but a server that handles gigabit traffic.
Lord, I want to understand this!
Read articles about:
These articles inspired me to write these tools.
Also a good article was written on the classmates blog 2 years ago.
Ordinary cases
But the manual for launching utilities in itself says little about how exactly they should be applied depending on the situation. We give some examples.
Example 1. As simple as possible.
Given:
- one processor with 4 cores
- one 1 Gbit / s network card (eth0) with 4 combined queues
- incoming traffic volume 600 Mbit / s, outgoing no.
- all queues hang on CPU0, a total of ≈55000 interrupts and 350000 packets per second on it, of which about 200 packets / sec are lost by the network card. The remaining 3 cores are idle
Decision:
- we distribute queues between kernels the
rss-ladder eth0command - increase her buffer command
rx-buffers-increase eth0
Example 2. A little harder.
Given:
- two processors with 8 cores
- two NUMA nodes
- Two dual-port 10 Gbit / s network cards (eth0, eth1, eth2, eth3), each port has 16 queues, all tied to node0, incoming traffic volume: 3 Gbit / s per each
- 1 x 1 Gbit / s network card, 4 queues, tied to node0, outgoing traffic volume: 100 Mbit / s.
Decision:
1 Drag one of the 10 Gbit / s network cards into another PCI slot tied to NUMA node1.
2 Reduce the number of combined queues for 10 Gb ports to the number of cores of one physical processor:
for dev in eth0 eth1 eth2 eth3; do ethtool -L $dev combined 8 done 3 Distribute the interrupts of the ports eth0, eth1 to the processor cores that fall into NUMA node0, and the ports eth2, eth3 to the processor cores that fall into the NUMA node1:
rss-ladder eth0 0 rss-ladder eth1 0 rss-ladder eth2 1 rss-ladder eth3 1 4 Increase eth0, eth1, eth2, eth3 RX-buffers:
for dev in eth0 eth1 eth2 eth3; do rx-buffers-increase $dev done Unusual cases
Not always everything goes perfectly:
- There are network cards that lose packets (missed) when using RSS to several cores in one NUMA node. The solution is strange, but working - 6 RX queues are tied to CPU0, the mask of 111110 processors is recorded in rps_cpus of each queue, the losses are gone.
- There were mellanox and intel (X710) network cards that continue to work when the interrupt counters stop growing. The traffic in tcpdump was there, the load created by the network cards hung on CPU0. Normal operation has been restored after turning the RPS on and off. Why - is unknown.
- Some SFP-modules for Intel 82599ES when updating the driver (build ixgbe from source with sourceforge) "disappear" from the list of network cards. In this case, this port is displayed in lspci, the second similar port works, and in dmesg, both ports have the same warning messages. The
unsupported_sfp=1,1flag helps when loading the ixgbe module. For good, however, it is worth buying supported sfp. - Some network card drivers adjust the number of queues only to equal powers of two (which is insulting on 6-core processors).
Update: after publication, the author realized that people use not only RHEL-based distributions for network tasks, but tests in debian on data sets collected in RHEL-based systems do not catch a lot of bugs. Many thanks to all who reported that something is not working in Ubuntu / Debian / Altlinux! All bugs fixed in release 2.0.10
Update2. in the comments they mentioned that RPS is still often useful to people and I underestimate it. In principle, this is the case; therefore, a significantly improved version of the autorps utility appeared in release 2.2.0 .
Update3: Release 2.5.0
')
Source: https://habr.com/ru/post/331720/
All Articles