Java place in the HFT world
In the article, the author tries to analyze why there are trading systems written in Java. How can Java compete in high performance with C and C ++? Then there are some small thoughts about the advantages and disadvantages of using Java as a programming language / platform for developing HFT systems.
A small disclaimer: the world of Java is broad, and in the article I will mean HotSpot, the implementation of Java, unless otherwise stated.
1. Introduction
I want to tell a lot about the place of Java in the world of HFT. To begin with, let's define what HFT (High Frequency Trading) is. This term has several definitions explaining its various aspects. In the context of this article, I will stick to the explanation given by Peter Lauri (Peter Lawrey), creator of the Java Performance User's Group: “HFT is a trade that is faster than a person’s reaction rate (faster than a human can see)”.
HFT trading platforms can analyze different markets simultaneously and are programmed to conduct transactions in the most appropriate market conditions. The progressive technology used makes it possible to process data incredibly quickly thousands of transactions per day, while extracting only a small profit from each transaction.
')
This definition covers the entire electronic automated trading with characteristic times of hundreds of milliseconds and less, up to microseconds. But if the speeds are reached in units of microseconds, then why do we need systems that are an order of magnitude slower? And how can they make money? The answer to this question consists of two parts:
- The faster the system should be, the simpler the model should be. Those. If our trading logic is implemented on FPGA, then you can forget about complex models. And vice versa, if we write code not on FPGA or plain assembler, then we should lay more complex models in the code.
- Network latency. It makes sense to optimize microseconds only when it can significantly reduce the total processing time, which includes network delays. It's one thing when network delays are tens and hundreds of microseconds (if you work with only one exchange), and completely different - 20ms on each side to London (and even further to New York!). In the second case, optimization of microseconds spent on data processing will not bring a noticeable reduction in the total response time of the system, which includes network latency.
Optimization of HFT systems in the first place pursues the reduction not of the total speed of information processing (throughput), but of the system response time to an external impact (latency). What does this mean in practice?
For optimization through throughput, the resulting performance over a long time interval (minutes / hours / days / ...) is important. Those. for such systems, it is normal to stop processing for some tangible period of time (milliseconds / second), for example, at the Garbage Collection in Java (hi, Enterprise Java!) if this does not entail a significant decrease in performance over a long time interval.
When optimizing latency, first of all, the fastest response to an external event is interesting. Such optimization leaves its mark on the means used. For example, if for optimizing through throughput, OS kernel level synchronization primitives are usually used (for example, mutexes), then to optimize for latency, you often have to use busy-spin, as this minimizes the response time to an event.
Having determined what HFT is, we will move on. Where is the place of Java in this "brave new world"? And how can Java be in speed with titans like C, C ++?
2. What is included in the concept of "performance"
As a first approximation, we divide all aspects of performance into 3 baskets:
- CPU performance per se, or the execution speed of the generated code,
- Memory performance,
- Network performance.
Consider each component in more detail.
2.1. CPU-performance
First , in the arsenal of Java there is the most important means for generating really fast code: the real profile of the application, that is, understanding which parts of the code are “hot” and which are not. This is critical for low-level code layout planning.
Consider the following small example:
int doSmth(int i) { if (i == 1) { goo(); } else { foo(); } return …; } When generating code from a static compiler (which works in compile-time), there is physically no way to determine (if you do not take into account PGO) which option is more frequent: i == 1 or not. Because of this, the compiler can only guess which generated code is faster: # 1, # 2, or # 3. At best, the static compiler will be guided by some kind of heuristics. And at worst, just the location in the source code.
Option 1
cmpl $1, %edi je .L7 call goo NEXT: ... ret .L7: call foo jmp NEXT Option # 2
cmpl $1, %edi jne .L9 call foo NEXT: ... ret .L9: call goo jmp NEXT Option # 3
cmpl $1, %edi je/jne .L3 call foo/goo jmp NEXT: .L3: call goo/foo NEXT: … ret In Java, due to the presence of a dynamic profile, the compiler always knows which option to prefer and generates code that maximizes performance for the actual load profile.
Secondly , in Java there are so-called speculative optimizations. Let me explain by example. Suppose we have the code:
void doSmth(IMyInterface impl) { impl.doSmth(); } Everything seems to be clear: a call to the virtual function doSmth should be generated. The only thing that static C / C ++ compilers can do in this situation is to try to de-virtualize the call. However, in practice, this optimization happens relatively rarely, since its implementation requires complete confidence in the correctness of this optimization.
The Java compiler running when the application is running has additional information:
- A full tree of currently loaded classes, on the basis of which it is possible to effectively conduct de-virtualization,
- Statistics about what implementation was called in this place.
Even if there are other implementations of the IMyInterface interface in the class hierarchy, the compiler will embed (inline) the implementation code, which will, on the one hand, get rid of a relatively expensive virtual call and perform additional optimizations on the other hand.
Third , the Java compiler optimizes the program for the specific hardware on which it was run.
Static compilers are forced to use only instructions of sufficiently ancient iron to ensure backward compatibility. As a result, all modern extensions available in x86 extensions remain overboard. Yes, you can compile under several instruction sets and, while running the program, do run-dispatching (for example, using ifunc's in LINUX), but who does this?
The Java compiler knows on which particular hardware it is running and can optimize the code for this particular system. For example, if the system supports AVX, then new instructions will be used, operating with new vector registers, which significantly speeds up the work of floating-point calculations.
2.2. Memory performance
Let us single out several aspects of the memory subsystem's performance: memory access pattern, speed of allocation and memory allocation (release). It is obvious that the issue of the speed of the memory subsystem is extremely extensive and cannot be fully exhausted by the 3 aspects considered.
2.2.1 Memory Access Pattern
In terms of the memory access pattern, the most interesting question is the difference in the physical location of objects in memory or the data layout. And here C and C ++ languages have a huge advantage - after all, we can clearly control the location of objects in memory, and the differences from Java. For example, consider the following code in C ++):
class A { int i; }; class B { long l; }; class C { A a; B b; }; C c; When compiling this code with the C / C ++ compiler, the fields of the subobject fields will be physically arranged in series, approximately as follows (we disregard the possible padding between the fields and the possible data-layout transformations produced by the compiler):
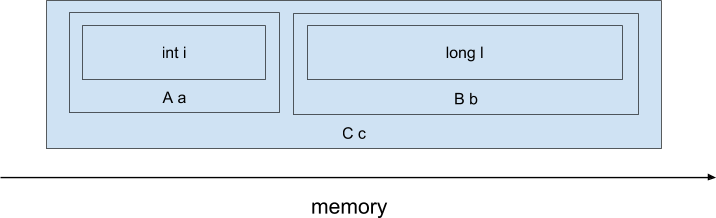
Those. an expression of the form 'return cai + cbl' will be compiled into such x86 assembler instructions:
mov (%rdi), %rax ; << cai add ANY_OFFSET(%rdi), %rax ; << cbl cai ret Such simple code was achieved due to the fact that the object is located linearly in memory and the compiler at the stage of compiling the displacement of the required fields from the beginning of the object. Moreover, when accessing the cai field, the processor will load the entire cache line with a length of 64 bytes, in which neighboring fields are likely to fall, for example, cbl. Thus, access to several fields will be relatively fast.
How will this object be located when using Java? Since the objects cannot be values (as opposed to primitive types), but always referential, during execution, the data will be located in memory in the form of a tree structure, rather than a sequential memory area:
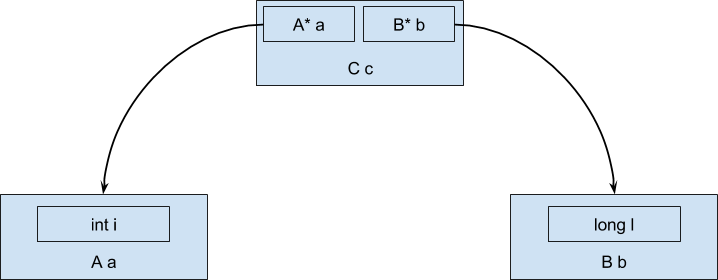
And then the expression 'cai + cbl' will compile at best into something similar to such x86 assembly code:
mov (%rdi), %rax ; << a mov 8(%rdi), %rdx ; << b mov (%rax), %rax ; << i a add (%rdx), %rax ; << l b We received an additional level of indirection when accessing data inside field objects, since the object of type C contains only references to field objects. An additional level of indirection significantly increases the amount of data load from memory.
2.2.2. Allocation rate
Java has a significant advantage over traditional languages with manual memory management (if you do not take the artificial case that all memory is allocated on the stack).
Usually, Java uses so-called TLABs (Thread local allocation buffer), that is, memory areas that are unique to each thread. Allocation looks like a decrease of the pointer indicating the beginning of free memory.
For example, a pointer to the beginning of the free memory in TLAB indicates 0x4000. To allocate, say, 16 bytes, you need to change the pointer value to 0x4010. Now you can use the newly allocated memory in the range 0x4000: 0x4010. Moreover, since access to TLAB is possible only from one thread (this is a thread-local buffer, as the name implies), there is no need for synchronization!
In languages with manual memory management, operator new / malloc / realloc / calloc functions are usually used to allocate memory. Most implementations contain resources that are shared between threads and are much more complex than the Java memory allocation method described. In some cases, memory shortages or heap fragmentation (memory allocation) operations can take a long time, which can affect latency.
2.2.3. Memory release speed
In Java, automatic memory management is used and the developer now does not have to manually release the previously allocated memory, as the Garbage collector does. The advantages of this approach include the simplification of writing code, because there is less reason for a headache.
However, this leads to not quite expected consequences. In practice, the developer has to manage various resources, not only memory: network connections, connections to the DBMS, open files.
And now, due to the lack of intelligible syntactic means of control over the life cycle of resources in the language, it is necessary to use rather cumbersome constructions such as try-finally or try-with-resources.
Compare:
Java:
{ try (Connection c = createConnection()) { ... } } or so:
{ Connection c = createConnection(); try { ... } finally { c.close(); } } With what you can write in C ++
{ Connection c = createConnection(); } // scope' But back to the release of memory. For all garbage collectors shipped with Java, there is a Stop-The-World pause. The only way to minimize its impact on the performance of the trading system (do not forget that we need optimization not by throughput, but by latency) is to reduce the frequency of any stops at the Garbage Collection.
At the moment, the most commonly used way to do this is to "reuse" objects. That is, when we no longer need an object (in C / C ++, we must call the delete operator), we write an object to a certain pool of objects. And when we need to create an object instead of the operator new, refer to this pool. And if there is a previously created object in the pool, then we take it out and use it as if it had just been created. Let's see how it will look at the source code level:
Automatic memory management:
{ Object obj = new Object(); ..... // , } And with reuse of objects:
{ Object obj = Storage.malloc(); // ... Storage.free(obj); // } The theme of reuse of objects, it seems to me, is not sufficiently covered and, of course, deserves a separate article.
2.3. Network performance
Here, Java positions are quite comparable with traditional C and C ++ languages. Moreover, the network stack (level 4 of the OSI model and below), located in the OS kernel, is physically the same when using any programming language. All network stack performance settings that are relevant for C / C ++ are also relevant for a Java application.
3. Development and debugging speed
Java allows you to develop logic much faster due to much faster code writing speed. Last but not least, this is a consequence of the rejection of manual memory management and the pointer-number dualism. Indeed, it is often quicker and easier to configure the Garbage Collection to a satisfactory level than to catch numerous dynamic memory management errors. Recall that errors when developing in C ++ often take a completely mystical turn: they are reproduced in a release assembly or only on Wednesdays (hint: in English, “Wednesday” is the longest day of the week in writing). Developing in Java in the overwhelming majority of cases goes without such an occult, and for every error you can get a normal stack trace (even with line numbers!). Using Java in HFT allows you to spend significantly less time on writing the correct code, which entails an increase in the system's adaptation speed to constant changes in the market.
4. Summary
In the HFT world, how successful a trading system depends on is the sum of two parameters: the speed of the trading system itself and the speed of its development and development. And if the speed of the trading system is a relatively simple and understandable criterion (at least it is clear how to measure), then the speed of development of the system is noticeably more difficult to assess. You can imagine the speed of development as the sum of countless factors, among which are the speed of writing code and debugging speed and speed of profiling and convenience of tools and entry threshold. Also, important factors are the speed of integration of ideas obtained from quantitative analysts (Quantitative Researchers), who, in turn, can reuse the code of the grocery trading system for data analysis. As it seems to me, Java is a reasonable compromise between all these factors. This language combines:
- good enough speed;
- relatively low entry threshold;
- simplicity of tools (Unfortunately, for C ++ there are no development environments comparable to IDEA);
- possibility of simple reuse of code by analysts;
- simplicity of work under large technically complex systems.
Summarizing the above, we can summarize the following: Java in the HFT has its essential niche. Using Java, not C ++, significantly speeds up the development of the system. In terms of performance, Java performance can be comparable to C ++ performance, and in addition, Java has a set of unique optimization capabilities that are not available for C / C ++.
Source: https://habr.com/ru/post/331608/
All Articles