Optimize AWS Costs in SaaS Business
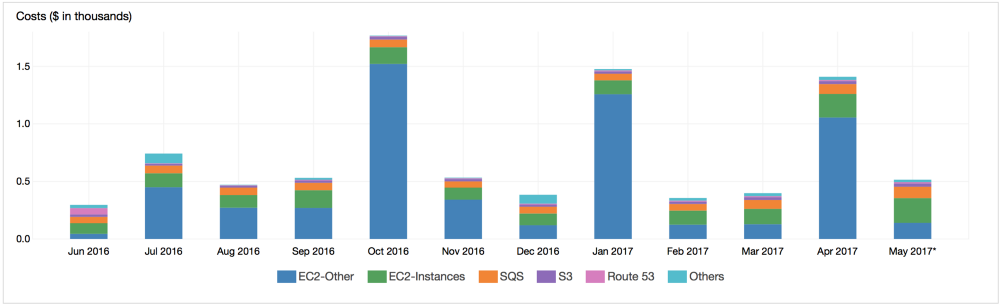
Cronitor costs on AWS over the past 12 months
In the first 30 days after the transfer of Cronitor to AWS in January 2015, we collected payments for $ 535 and paid $ 64.47 for hosting, data transfer and domain name. Since then, we have increased the consumption of services, upgraded instances, added services. Despite AWS’s reputation as an expensive pistol to shoot itself in the leg, our accounts remained at the level of 12.5% of revenue. See for yourself.
Bruises and bumps from cheap aws
It soon became clear that our idea has some perspective. We realized that we need to raise the bar from a side project to a full-fledged small business. The goal was not high availability, but only increased availability compared to the previous configuration on a single 2 GB Linode. We really only wanted to restart the database without losing the incoming telemetry. Nothing special. The initial installation was pretty simple:
- ELB
- SQS
- A couple of t2.small instances with a web application and data collection, both on us-west-2
- One m3.medium instance where MySQL and our daemon worked, which detected crashes and sent alerts
We finished the migration in two hours with almost no downtime and were truly pleased with ourselves. Beer poured. We went congratulatory tweets.
')
Joy was short-lived.
Problem 1: ELB failure
Our users send telemetry pings when they have jobs, processes and demons. With NTP today, the average server has very accurate hours, and we see traffic spikes at the beginning of every second, minute, hour, and day — up to 100 times our base traffic.
Immediately after the migration, users started complaining about periodic timeouts, so we decided to double-check the server configuration and the history of ELB logs. With traffic jumps, so far less than 100 requests per second, we abandoned the idea that the problem was in ELB, and began to look for errors in our own configuration. In the end, we launched a test for continuous ping service. It started a few moments before 00:00 UTC and ended a few moments after midnight - and saw unsuccessful requests that do not fall into the ELB logs at all. Separate instances were available, and a request queue was not created. It became clear that the connections were broken at the level of the load balancer, probably because our traffic jumps were too large and too short to warm up to a greater load. Due to the high cost of the AWS technical support plan, we could not ask them to manually increase the size of our ELB, so we decided instead to launch cyclical queries using DNS to eliminate the need for a load balancer altogether.
Lesson learned:
- Cloud solutions such as the flexible load balancer are generally designed for normal, average use. Think about how you differ from the average.
Problem 2: Familiarity with the CPU Credit Balance
The line of T2 instances with burst support is economically viable if the load occasionally increases, as the official website says. But here I would like it to be written there: if you run your instance on a constant load of 25% of the CPU, then the balance of CPU credits starts to run low, and when it ends, you basically have the computing power of Rasperry Pi. You will not receive any warnings about this, and your CPU% will not reflect the reduced power. For the first time, having exhausted the balance of credits, we decided that the compounds break for some other reason.
Lessons learned:
- If something is offered very cheaply, there is a good reason for this, you need to understand it.
- T2 instances should only be used in the autoscale group.
- Just in case, create a CloudWatch notification that will warn you if the credit balance falls below 100
Problem 3: what is written in small print
Last year, at the re: Invent conference, Amazon updated its Reserved Instance offer, probably in response to more favorable conditions from Google Cloud. The press release said that the reserved instances will become cheaper and can be transferred between zones. This is great!
When it was time to close our last T2 instances in October, we rolled out the new M3 with these cheaper and more flexible 12-month reservations. After the appearance of several large clients in April, we decided to raise the level of instances again, now to M4.large. It was six months from the October reservation, so I decided to sell them, as I always did before. And then I learned the bitter truth that the price for these cheaper and more flexible reservations was that ... you cannot resell them.
Lessons learned:
- If something is offered very cheaply, there is a good reason for this, you need to understand it.
- Always read the terms of the offer twice. AWS billing is incredibly difficult.
A look at AWS real prices
Today, our infrastructure remains fairly simple:
- Cluster M4.large is collecting incoming telemetry
- Cluster M3.medium serves a web application and API
- Worker M4.large with our monitoring daemon and alert system
- M4.xlarge for MySQL and Redis
We continue to use a number of managed services, including SQS, S3, Route53, Lambda, and SNS.
Elastic compute
We use partial advance bookings for all our services.
You may notice that from our monthly bills, 2/3 is spent on secured IOPS (I / O operations per second), as we do for instances. Unlike guaranteed IOPS in most cloud metrics, which are merely entries in the terms of the contract, this is a real service that has a cost price. They will also make up a significant portion of your EC2 budget for any host where disk performance is important. If you do not pay for IOPS, your tasks will queue up and wait for resources to be released.

Please do not ask what “alarm-month” means
SQS
We intensively use SQS to queue incoming telemetry pings and results from the system state checking service. A few months after the migration, we did one optimization - max-batching readings. You pay for the number of requests, not for the number of messages, so this reduces costs and significantly speeds up the processing of messages.
During the migration, we were worried that SQS was the only point of failure for our data collection pipeline. To avoid the risk, we ran little daemons on each host for buffering and retry writing SQS in the event of a crash. Buffering of messages took only once in 2.5 years, so 1) it was 100% worth launching; 2) SQS proved incredible reliability in the us-west-2 region.

Lambda
Our Healthchecks service is built in part on Lambda workers in the regions listed below. It should be noted that Lambda has a generous free level (Free Tier), which is applied to each region separately. At this time, the free level is advertised as "indefinite . "

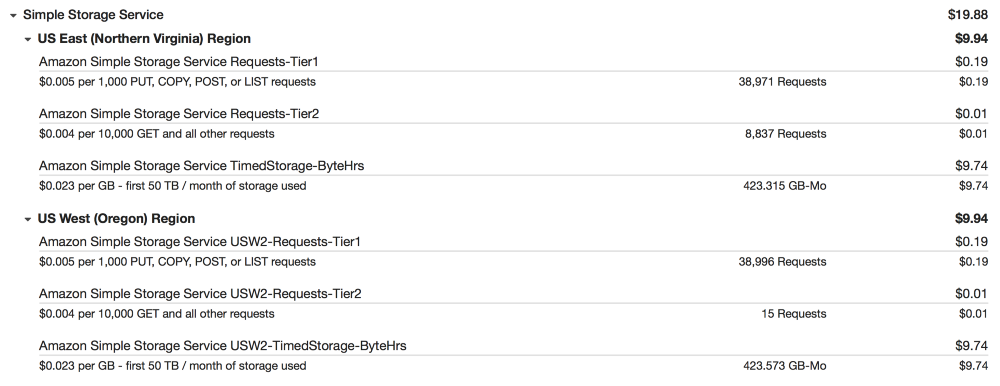
S3
We make backup copies of database snapshots and logs on S3 with replication in us-east-1 for recovery in the event of a disaster.
The professional advice for AWS is that EBS backups and snapshots are vital in the event of a recovery after a disaster, but the really serious disruptions in the region are usually not limited to a single service. If you are unable to start the instance, then most likely you will not be able to copy your files to another region. So do it in advance!
In conclusion
Having worked with large corporate and investment projects on AWS, I can personally vouch that you can run a big deal here. They created a fabulous set of tools and brilliant objects that are all grabbed together - and they charge you for everything you touch . This is dangerous, you need to be restrained and limit your appetites, but you will be rewarded with the opportunity to grow a small business into something more when any resources are available to you on request as soon as you need it. Sometimes it's good to stop for a second and think about how great it is - and then get back to work.
Source: https://habr.com/ru/post/331566/
All Articles