Administrator's sin or data recovery from knocking HDD Western Digital WD5000AAKX
In one small software company, data storage was organized as follows: a server in which ordinary SATA drives are organized using linux (mdamd) in several RAID 1 arrays, each of which was a storage for one of the development directions. This option at the lowest cost is relatively reliable if properly looked after. But the system administrator decided that there is no need to regularly check the status of the arrays, and did other things. In June 2017, having received complaints about the inability to read data from users of one of the arrays, I found out that the array itself is long gone and that the recording stopped on one of the drives in August 2015, and the second one with the actual data hangs the OS when trying to mount. A backup copy of the server was last made in November 2016.

rice one
Realizing the consequences of negligence in everyday work, the administrator tried to admit his guilt only in the irregularity of copying outside the server and hide the oversight behind arrays, citing the simultaneous failure of two drives.
')
Considering the prevailing circumstances, one of the managers of the company rather unflatteringly spoke about the work of the system administrator and instructed the latter to restore the data as soon as possible in a very emotional way.
From that moment on, a chain of events began that did not in the best way affect the integrity of user data.
On June 12, in the morning, immediately after opening, a person appears on the threshold of our company's office who says that he urgently needs to get the WD5000AAKX-221CA1 drive free diagnostics service, which suspends the system and does not allow copying files. The drive without traces of the autopsy.
We carry out standard diagnostic measures: visual inspection, checking power circuits on a printed circuit board, resistance of motor windings. Having found nothing seditious, we connect to the PC3000 port and power up. Heard the normal sound of the promotion of the shaft, passing the calibration test. By register, the drive shows readiness for data exchange. At the request of the passport we get from the hard disk the correct answer with all the data. Check the readability of the firmware modules and evaluate their checksums. When analyzing the relo-list, we find that it is not empty, which indicates that the drive's firmware has detected some problems on the surface. Looking through the attributes of SMART , we note that 197 attribute (the current number of unstable sectors) is very far from zero, which confirms the presence of problems. We modify the settings in the RAM of the drive: disable reassignment and adding defects to the relo-list, clear the relo-list itself, prohibit updating SMART logs. After this modification, the drive will not perform offline scanning procedures or update SMART logs. At this stage, we make an assessment of the quality of reading of each of the heads in areas of different recording density. The test confirms the suitability of the original BMG for reading data. We read 0 sector.

rice 2
We discover that it contains entries for three sections.
At offset 0x00000800 (2048) sectors is the first section of Linux RAID (0xFD), partition size 0x00064000 (409 600) sectors.
At offset 0x00064800 (411 648) sectors is the second section of Linux RAID (0xFD), partition size 0x39DC8000 (970 752 000) sectors.
At offset 0x39E2C800 (971 163 648) sectors is located the third section of linux swap (0x82), section size 0x00400000 (4 194 304) sectors.
An analysis of the contents of the superblocks of the first two sections shows that they consisted of RAID 1 arrays and each section contains one Ext4 section. After trying to read the file system metadata on a large section, we find that there are difficulties in reading.
This completes the initial diagnostic measures, and their results are communicated to the client, a price niche for services ranging from 250 to 350 Belarusian rubles is also reported, and the deadline is about 2-3 business days (only during the daytime, since the drive requires constant monitoring). If it is necessary to carry out work outside office hours to reduce the time, then it is possible, but this will directly affect the cost. Work plan: modification of drive microcode, localization of defective zones, reading stable zones, analyzing file system metadata on a copy, subtracting missing metadata from problem zones, reanalyzing and building chains of necessary files for reading from problem zones, if necessary, analyzing regular expressions in areas not occupied by files, and possible reconstruction of the damaged file system.
A potential client expressed his displeasure at the expected cost of services and the timing of work, as well as too quick diagnosis, arguing that in less than 15 minutes it is impossible to draw such conclusions. In addition, he noted that the data belong to the company, and the restoration work at his expense, so he will try it himself for now. With these words, the client left the office.
On June 14, at the beginning of the working day, this client came to us again and reported that he tried to copy the image from the drive repeatedly using dd. At first, the hard drive periodically hung up, but after turning it off and on again, it was seen again in the system and allowed to continue copying, but now the drive disappeared from the system, and turning off and on no longer helps, and then another buzz comes from the hramblock.
Were repeated standard diagnostic measures. At the trial start stage, we did not hear the sound of the shaft spin, but we heard cyclical humming sounds that these drives emit during unsuccessful attempts to start the engine. Taking into account that the seizure of the shaft in these drives happens very rarely and usually happens due to serious deformations of the hull, which are not on this drive, it was suggested that the heads stick outside the parking ramp .
The client was voiced by an additional set of measures required for data recovery, and the fact that now the deadlines and cost increase due to the aggravation of the situation, to which he retorted, sticking the heads is not a great problem and that youtube saw a lot of videos, which shows how to act in such situations, and this is a matter of a few minutes. To listen to the information, than such “methods” are dangerous, the client refused and left the office.
On June 15, in the middle of the working day, the client reappears (he is a system administrator), but not one, but accompanied by his direct manager. Immediately the claim was voiced that after our diagnostics the drive became much worse, that it is now knocking and not detected in the BIOS. At this moment, we stop the monologue of the system administrator and say that we are ready to accept a written claim and give it an answer within the statutory period, but before proceeding to dialogue in a similar vein, let's conduct a visual inspection of the drive with you and also compare whether its appearance from what it was, as well as, if necessary, we will review the video of yesterday and determine if there was anything in our actions that could seriously aggravate the situation. The system administrator wanted to begin to contradict, but his manager intervened in the dialogue, who told the system administrator to put the hard drive on the rack.
Immediately we find that the label on the drive cover was partially peeled off, we also show that the tightening torque of the cover screws is different, which clearly shows that the cover was removed from the drive. And we provide a video of yesterday, where on the rack you can see that the sticker on the lid of the drive is intact at the time when it was taken by the system administrator, and his reasoning about videos on youtube is clearly audible.
Under the pressure of facts, the system administrator stopped blaming us and confessed that he had disassembled the drive and tried to remove the heads, but the drive did not work, but tapped. In an attempt to disclaim the responsibility, he informed the management that the autopsy was made by our company, and that it was after this that the drive began to knock. After that, the system administrator and his manager left the office to talk.
Only one manager returned to the office, who asked for the third time to take diagnostic measures taking into account the additional complications revealed, and also to diagnose the second disk from the array.
According to the results of the analysis of the second drive, it was established that small defect formation takes place (because of them the drive was excluded from the array), and according to the metadata of the file system, there are no user data after August 2015. Thus, the fact that the disc failure was not simultaneous was revealed.
Under the conditions of a laminar box, the drive was opened. Damage to BMG were visible visually and did not even require removal for examination under a microscope. But the photograph was taken.

rice 3
In this BMG, both pendants were deformed in a similar way. Such deformations are usually the result of inept pulling heads from the surface onto the parking ramp. Attempts to start this drive led to additional scratches on the surface of the plates. Fortunately, there were few start-up attempts, and the final data killing did not take place, but the nature of the scratches is such that a degeneration into gaps is possible.
Thus, instead of the ordinary task of reading out a drive with defects, due to the special diligence of the system administrator, we have a task where it is necessary to perform a BMG transplant and the prospects are very vague, since there are radial scratches at the beginning of the disk. The service area of this drive is located at the very beginning of the plate, i.e. in the area with scratches.

rice four
Let us note how the edge of the plate is mutilated with dangling sliders (the damage zone is approximately 0.1-0.3 mm, due to the increase, a piece of the circle degenerates almost straight). The good thing is that in this place, when an operating BMG goes off the ramp, the sliders are still quite high, so these strongest damages to the plate are not dangerous.
This information is communicated to the customer, we also inform that the cost has increased significantly due to the necessity of transplantation of BMG from a similar donor (Tahoe LT), additional work on transplantation, and there is also a high probability that one donor will hardly be enough to read the problem areas. since degradation processes will progress. The customer agrees without hesitation.
Starting to work, we make the selection of several sets of BMG from donor drives, taking into account the proximity of adaptive parameters, in order to obtain the most stable reading. Dust-freezing the patient's germoblock and performing BMG shuffling procedures from the donor's drive with the help of a specialized tool.

rice five
Having collected the drive, we carry out trial start. You can hear the sound of the shaft spin, passing the calibration test. There are no suspicious sounds, for this reason we do not interrupt the initialization procedure and we expect about 40 seconds before the appearance of readiness for data exchange.

rice 6
We request the passport of the drive and get a dummy, which indicates that the drive could not load from the service area all the modules that are needed to start. We analyze the version of the code in the drive ROM and select the appropriate overlay from our database of firmware copied from the drives. After downloading it to the memory of the drive, it was possible to fully read and analyze the contents of the service area. According to the results of checking the integrity of the service area, 0x11 (main overlay) turned out to be unreadable, 0x31 - translator, 0x32 - relo-list, 0x33 - P-list, 0x34 - G-list, 0x43 - adaptive parameters, as well as modules responsible for SMART operation.
We produce sector reading of the most critical modules. P-list was read with a small number of defects, the location of which is far enough from the beginning of the module. A similar picture with the module of adaptive parameters. Translator modules, G-list, relo-list were 100% unreadable. Similar damage to the modules occurs when the drive is working with not completely working heads when trying to overwrite the module with the drive's firmware.
To restore the translator module, we write everything we need, received from the patient’s service area, into the donor drive, including the reconstructed 0x33 and 0x43. Having performed the translator recalculation taking into account the P-list, we get the original 0x31 module due to the work of the drive firmware itself. Information about hidden defects in the 0x34 module is irretrievably lost, so we will create a dummy module with no entries. We perform the same action with the 0x32 module.
We will check the possibility of recording on the patient, for this we prescribe unused tracks and try to count them. The recording test was successful, so we write down the restored modules of 0 copies to the patient, and also correct the information about the regions so that only the copy on the zero head is active. We also make changes to the settings module so that, if successfully started, the offline scanning procedures will not start and the SMART procedures will not work.
We restart the drive, and within 10 seconds we receive information about readiness for data exchange. At the request of the passport we get the correct answer. Attempting to read in the user zone gives us the partition table already familiar to us in the first diagnostics, which indicates that the drive was able to load everything from the surface and initialize the translation system.
We create the task of a sector copy to another drive in Data Extractor and perform the procedure for constructing a map of mini zones. We take into account that during the examination scratches were found at the beginning of the plate; we start the main reading in UDMA mode from the end zones.
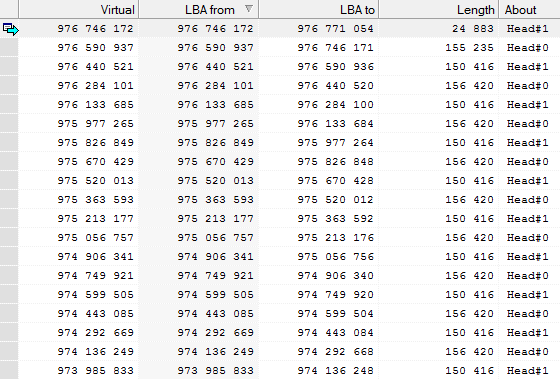
rice 7
There are problems with reading within the boundaries of the swap section, but we ignore them, since the section is of very low value. Within the boundaries of the main second section, the reading proceeds without complaints to the 57 89x xxx sectors, then the first instabilities begin to appear.
Let's change the reading from the UDMA mode to the PIO for better control of the reading process and read the file system meta data (Ext4) of the second section. Having completed this operation by 99.99%, we will proceed to reading mini zones with a short timeout and a jump of 10,000 sectors in case of instability. This measure allowed us to read more than 85% of the unread volume.
Next, we proceed to the analysis of the location of the files on the second section and build a queue of chains, according to the priority of the data in the Customer’s terms of reference. Considering that some of the files important for the Customer are present in the scratched part of the plate, we proceed to multipass reading in the area of the main defective zones.
When proofreading defective areas, degradation of both the sliders and the plate surfaces occurs, so it is important to exclude the most dangerous areas from reading in order to read the maximum of user data with a minimum of donor head sets.
In the course of work, the Customer was sent reports of damaged files after each degradation of donor BMH and the use of each additional donor was agreed. When using the third reading dynamics was hardly noticeable, for this reason it was decided to discontinue further attempts to obtain the remaining data from the defective areas. It was possible to get more than 95% of all files (and more than 99.5% according to the main technical task). This result satisfied the customer.
In conclusion, summarize. There is a neglect of the system administrator to their duties. Also striking the misplaced emotional leadership, which harms the work process. After all, it was because of pressure from management that the system administrator tried to minimize his expenses and made a lot of rash actions that aggravated the state of the drive, which threatened the final destruction of user data that was valuable to the company many times more than the cost of data recovery services. I would like to draw the attention of the management team that in such situations it is an unaffordable luxury to fall for emotions. Much more reasonable solution would be to analyze the problem and assess your own capabilities to eliminate it and, if necessary, search for performers. And only after the solution of the main problem to understand the degree of guilt of the system administrator and to talk about any penalties for the damage caused by inaction. Also, the leadership should share the burden of guilt with their subordinates, since it was the lack of job descriptions or their complete absence created the conditions for the development of such a situation.
Next post: Save on matches or restore data from the grind HDD Seagate ST3000NC002-1DY166
Previous publication: Shallow immersion or data recovery from the hard drive after flooding the office
rice one
Realizing the consequences of negligence in everyday work, the administrator tried to admit his guilt only in the irregularity of copying outside the server and hide the oversight behind arrays, citing the simultaneous failure of two drives.
')
Considering the prevailing circumstances, one of the managers of the company rather unflatteringly spoke about the work of the system administrator and instructed the latter to restore the data as soon as possible in a very emotional way.
From that moment on, a chain of events began that did not in the best way affect the integrity of user data.
On June 12, in the morning, immediately after opening, a person appears on the threshold of our company's office who says that he urgently needs to get the WD5000AAKX-221CA1 drive free diagnostics service, which suspends the system and does not allow copying files. The drive without traces of the autopsy.
We carry out standard diagnostic measures: visual inspection, checking power circuits on a printed circuit board, resistance of motor windings. Having found nothing seditious, we connect to the PC3000 port and power up. Heard the normal sound of the promotion of the shaft, passing the calibration test. By register, the drive shows readiness for data exchange. At the request of the passport we get from the hard disk the correct answer with all the data. Check the readability of the firmware modules and evaluate their checksums. When analyzing the relo-list, we find that it is not empty, which indicates that the drive's firmware has detected some problems on the surface. Looking through the attributes of SMART , we note that 197 attribute (the current number of unstable sectors) is very far from zero, which confirms the presence of problems. We modify the settings in the RAM of the drive: disable reassignment and adding defects to the relo-list, clear the relo-list itself, prohibit updating SMART logs. After this modification, the drive will not perform offline scanning procedures or update SMART logs. At this stage, we make an assessment of the quality of reading of each of the heads in areas of different recording density. The test confirms the suitability of the original BMG for reading data. We read 0 sector.
rice 2
We discover that it contains entries for three sections.
At offset 0x00000800 (2048) sectors is the first section of Linux RAID (0xFD), partition size 0x00064000 (409 600) sectors.
At offset 0x00064800 (411 648) sectors is the second section of Linux RAID (0xFD), partition size 0x39DC8000 (970 752 000) sectors.
At offset 0x39E2C800 (971 163 648) sectors is located the third section of linux swap (0x82), section size 0x00400000 (4 194 304) sectors.
An analysis of the contents of the superblocks of the first two sections shows that they consisted of RAID 1 arrays and each section contains one Ext4 section. After trying to read the file system metadata on a large section, we find that there are difficulties in reading.
This completes the initial diagnostic measures, and their results are communicated to the client, a price niche for services ranging from 250 to 350 Belarusian rubles is also reported, and the deadline is about 2-3 business days (only during the daytime, since the drive requires constant monitoring). If it is necessary to carry out work outside office hours to reduce the time, then it is possible, but this will directly affect the cost. Work plan: modification of drive microcode, localization of defective zones, reading stable zones, analyzing file system metadata on a copy, subtracting missing metadata from problem zones, reanalyzing and building chains of necessary files for reading from problem zones, if necessary, analyzing regular expressions in areas not occupied by files, and possible reconstruction of the damaged file system.
A potential client expressed his displeasure at the expected cost of services and the timing of work, as well as too quick diagnosis, arguing that in less than 15 minutes it is impossible to draw such conclusions. In addition, he noted that the data belong to the company, and the restoration work at his expense, so he will try it himself for now. With these words, the client left the office.
On June 14, at the beginning of the working day, this client came to us again and reported that he tried to copy the image from the drive repeatedly using dd. At first, the hard drive periodically hung up, but after turning it off and on again, it was seen again in the system and allowed to continue copying, but now the drive disappeared from the system, and turning off and on no longer helps, and then another buzz comes from the hramblock.
Were repeated standard diagnostic measures. At the trial start stage, we did not hear the sound of the shaft spin, but we heard cyclical humming sounds that these drives emit during unsuccessful attempts to start the engine. Taking into account that the seizure of the shaft in these drives happens very rarely and usually happens due to serious deformations of the hull, which are not on this drive, it was suggested that the heads stick outside the parking ramp .
The client was voiced by an additional set of measures required for data recovery, and the fact that now the deadlines and cost increase due to the aggravation of the situation, to which he retorted, sticking the heads is not a great problem and that youtube saw a lot of videos, which shows how to act in such situations, and this is a matter of a few minutes. To listen to the information, than such “methods” are dangerous, the client refused and left the office.
On June 15, in the middle of the working day, the client reappears (he is a system administrator), but not one, but accompanied by his direct manager. Immediately the claim was voiced that after our diagnostics the drive became much worse, that it is now knocking and not detected in the BIOS. At this moment, we stop the monologue of the system administrator and say that we are ready to accept a written claim and give it an answer within the statutory period, but before proceeding to dialogue in a similar vein, let's conduct a visual inspection of the drive with you and also compare whether its appearance from what it was, as well as, if necessary, we will review the video of yesterday and determine if there was anything in our actions that could seriously aggravate the situation. The system administrator wanted to begin to contradict, but his manager intervened in the dialogue, who told the system administrator to put the hard drive on the rack.
Immediately we find that the label on the drive cover was partially peeled off, we also show that the tightening torque of the cover screws is different, which clearly shows that the cover was removed from the drive. And we provide a video of yesterday, where on the rack you can see that the sticker on the lid of the drive is intact at the time when it was taken by the system administrator, and his reasoning about videos on youtube is clearly audible.
Under the pressure of facts, the system administrator stopped blaming us and confessed that he had disassembled the drive and tried to remove the heads, but the drive did not work, but tapped. In an attempt to disclaim the responsibility, he informed the management that the autopsy was made by our company, and that it was after this that the drive began to knock. After that, the system administrator and his manager left the office to talk.
Only one manager returned to the office, who asked for the third time to take diagnostic measures taking into account the additional complications revealed, and also to diagnose the second disk from the array.
According to the results of the analysis of the second drive, it was established that small defect formation takes place (because of them the drive was excluded from the array), and according to the metadata of the file system, there are no user data after August 2015. Thus, the fact that the disc failure was not simultaneous was revealed.
Under the conditions of a laminar box, the drive was opened. Damage to BMG were visible visually and did not even require removal for examination under a microscope. But the photograph was taken.
rice 3
In this BMG, both pendants were deformed in a similar way. Such deformations are usually the result of inept pulling heads from the surface onto the parking ramp. Attempts to start this drive led to additional scratches on the surface of the plates. Fortunately, there were few start-up attempts, and the final data killing did not take place, but the nature of the scratches is such that a degeneration into gaps is possible.
Thus, instead of the ordinary task of reading out a drive with defects, due to the special diligence of the system administrator, we have a task where it is necessary to perform a BMG transplant and the prospects are very vague, since there are radial scratches at the beginning of the disk. The service area of this drive is located at the very beginning of the plate, i.e. in the area with scratches.
rice four
Let us note how the edge of the plate is mutilated with dangling sliders (the damage zone is approximately 0.1-0.3 mm, due to the increase, a piece of the circle degenerates almost straight). The good thing is that in this place, when an operating BMG goes off the ramp, the sliders are still quite high, so these strongest damages to the plate are not dangerous.
This information is communicated to the customer, we also inform that the cost has increased significantly due to the necessity of transplantation of BMG from a similar donor (Tahoe LT), additional work on transplantation, and there is also a high probability that one donor will hardly be enough to read the problem areas. since degradation processes will progress. The customer agrees without hesitation.
Starting to work, we make the selection of several sets of BMG from donor drives, taking into account the proximity of adaptive parameters, in order to obtain the most stable reading. Dust-freezing the patient's germoblock and performing BMG shuffling procedures from the donor's drive with the help of a specialized tool.
rice five
Having collected the drive, we carry out trial start. You can hear the sound of the shaft spin, passing the calibration test. There are no suspicious sounds, for this reason we do not interrupt the initialization procedure and we expect about 40 seconds before the appearance of readiness for data exchange.
rice 6
We request the passport of the drive and get a dummy, which indicates that the drive could not load from the service area all the modules that are needed to start. We analyze the version of the code in the drive ROM and select the appropriate overlay from our database of firmware copied from the drives. After downloading it to the memory of the drive, it was possible to fully read and analyze the contents of the service area. According to the results of checking the integrity of the service area, 0x11 (main overlay) turned out to be unreadable, 0x31 - translator, 0x32 - relo-list, 0x33 - P-list, 0x34 - G-list, 0x43 - adaptive parameters, as well as modules responsible for SMART operation.
We produce sector reading of the most critical modules. P-list was read with a small number of defects, the location of which is far enough from the beginning of the module. A similar picture with the module of adaptive parameters. Translator modules, G-list, relo-list were 100% unreadable. Similar damage to the modules occurs when the drive is working with not completely working heads when trying to overwrite the module with the drive's firmware.
To restore the translator module, we write everything we need, received from the patient’s service area, into the donor drive, including the reconstructed 0x33 and 0x43. Having performed the translator recalculation taking into account the P-list, we get the original 0x31 module due to the work of the drive firmware itself. Information about hidden defects in the 0x34 module is irretrievably lost, so we will create a dummy module with no entries. We perform the same action with the 0x32 module.
We will check the possibility of recording on the patient, for this we prescribe unused tracks and try to count them. The recording test was successful, so we write down the restored modules of 0 copies to the patient, and also correct the information about the regions so that only the copy on the zero head is active. We also make changes to the settings module so that, if successfully started, the offline scanning procedures will not start and the SMART procedures will not work.
We restart the drive, and within 10 seconds we receive information about readiness for data exchange. At the request of the passport we get the correct answer. Attempting to read in the user zone gives us the partition table already familiar to us in the first diagnostics, which indicates that the drive was able to load everything from the surface and initialize the translation system.
We create the task of a sector copy to another drive in Data Extractor and perform the procedure for constructing a map of mini zones. We take into account that during the examination scratches were found at the beginning of the plate; we start the main reading in UDMA mode from the end zones.
rice 7
There are problems with reading within the boundaries of the swap section, but we ignore them, since the section is of very low value. Within the boundaries of the main second section, the reading proceeds without complaints to the 57 89x xxx sectors, then the first instabilities begin to appear.
Let's change the reading from the UDMA mode to the PIO for better control of the reading process and read the file system meta data (Ext4) of the second section. Having completed this operation by 99.99%, we will proceed to reading mini zones with a short timeout and a jump of 10,000 sectors in case of instability. This measure allowed us to read more than 85% of the unread volume.
Next, we proceed to the analysis of the location of the files on the second section and build a queue of chains, according to the priority of the data in the Customer’s terms of reference. Considering that some of the files important for the Customer are present in the scratched part of the plate, we proceed to multipass reading in the area of the main defective zones.
When proofreading defective areas, degradation of both the sliders and the plate surfaces occurs, so it is important to exclude the most dangerous areas from reading in order to read the maximum of user data with a minimum of donor head sets.
In the course of work, the Customer was sent reports of damaged files after each degradation of donor BMH and the use of each additional donor was agreed. When using the third reading dynamics was hardly noticeable, for this reason it was decided to discontinue further attempts to obtain the remaining data from the defective areas. It was possible to get more than 95% of all files (and more than 99.5% according to the main technical task). This result satisfied the customer.
In conclusion, summarize. There is a neglect of the system administrator to their duties. Also striking the misplaced emotional leadership, which harms the work process. After all, it was because of pressure from management that the system administrator tried to minimize his expenses and made a lot of rash actions that aggravated the state of the drive, which threatened the final destruction of user data that was valuable to the company many times more than the cost of data recovery services. I would like to draw the attention of the management team that in such situations it is an unaffordable luxury to fall for emotions. Much more reasonable solution would be to analyze the problem and assess your own capabilities to eliminate it and, if necessary, search for performers. And only after the solution of the main problem to understand the degree of guilt of the system administrator and to talk about any penalties for the damage caused by inaction. Also, the leadership should share the burden of guilt with their subordinates, since it was the lack of job descriptions or their complete absence created the conditions for the development of such a situation.
Next post: Save on matches or restore data from the grind HDD Seagate ST3000NC002-1DY166
Previous publication: Shallow immersion or data recovery from the hard drive after flooding the office
Source: https://habr.com/ru/post/331512/
All Articles