Features of the organization of the IT infrastructure for video surveillance

The market of video surveillance systems (now they began to use the trendy term Video Surveillance) is developing rapidly and is very technological. The steepness of modern video surveillance systems is determined not only by the power of video cameras and software functionality, but also by the IT infrastructure that will serve all this stuff.
Of course, we are not talking about small installations for a couple of dozen cameras, where you can get by with one computer, a simple server or a NVR, and, of course, only IP solutions are considered, analog video surveillance is a thing of the past.
')
When it comes to hundreds or even thousands of video cameras with a single server or out-of-the-box solution, you will not be able to do it, especially if you need additional functions related to video analytics (detection, tracking, recognition), integration with cash registers, integration into integrated security systems (ACS, OPS). ). In this case, the optimal solution is to use specialized video surveillance software - VMS (Video Management Software), which provides the ability to scale and support a large number of IP cameras, as well as all the necessary functions and capabilities for the project.
To deploy such software, you will need to create a dedicated IT infrastructure, including a whole server farm, processing a lot of video streams and implementing the necessary additional functionality. To record and store video archives in this
infrastructure can be used:
- local server media;
- Direct Attached Storage (DAS) - disk shelves that are connected to servers directly;
- and / or dedicated storage with file or block access.
Naturally, by servers we mean servers on which video surveillance software (VMS) is installed, we will conditionally call them video servers.
Processing a large number of video streams with high performance requires serious computational power. First of all, it concerns processor resources, in terms of RAM, video servers are usually not voracious, usually 8-16GB of RAM per server is enough, but of course there are exceptions.
Video server requirements for 100 streams
Let us try to estimate the requirements for computing resources and, most importantly, for the storage subsystem, which are presented in serious video surveillance projects. We will proceed from the fact that video servers receive, process and record video streams to the archive, as well as other necessary VMS functionality, without focusing on the video analytics, which greatly increases the requirements for computing resources. Displaying pictures from IP cameras for real-time monitoring and video playback from the archive should be performed from dedicated URM (Remote Workstations), which allows you to remove a significant part of the computational load from video servers (up to half). Surveillance CCTVs are quite powerful PC-level graphic stations with special client software for connecting to VMS and the ability to display a variety of pictures on large screens.
We take the stream from a single IP camera using ONVIF protocols (open standard for interaction between IP cameras and VMS), with Full-HD resolution (1920x1080), the basic H.264 codec and a frequency of 25 frames per second, under the condition of high activity in the frame . According to the online calculator ITV | AxxonSoft , one of the leaders of the VMS market, such a video stream generates 6.86 Mbps traffic.
The computational resources required to process 100 video streams with a margin can be provided with a 4-core Intel Xeon E3-1225 V3 processor. By current standards, the percentage is rather weak, it is enough to allocate 8-16GB for RAM. As a result, in terms of power, we can do with an inexpensive 1U server or even a good desktop PC. However, with the repository for the archive of video recordings, things are more complicated.
To store a video archive with a depth of 1 month (standard requirement) for 100 streams, provided there is a 24-hour recording, you will need a storage with a usable capacity of about 212TB, which can be confirmed by monstrously complicated calculations:
(6.86 Mbit / s * 3600s * 24h * 30d * 100 chambers) / (8 * 1024 * 1024) = 211.97 TB, because 1TB = 8 * 1024 * 1024 Mbit
Such storage capacity is achieved through the use of a large number of high-capacity disks (4-6-8-10 TB). They can be used independently, each by itself, then VMS will write data to them sequentially or distribute them to all disks at once, depending on the manufacturer. Cons of this approach:
- reliability - when a disk fails, part of the video archive is lost;
- performance - we rest against the performance of a single disk if the recording is not distributed among the disks at the level of video surveillance software.
Using RAIDs
The solution to the problem is to combine disks into RAID arrays (RAID groups). For local and directly connected to the server drives - using dedicated hardware RAID controllers.
RAID technology has several levels (implementation methods), the main ones are: 0, 1, 10, 5, 6, 50, 60. RAID-0 is striping, data is written in parallel to all disks in the array. RAID-1 and RAID-10 - mirroring, data recording is duplicated on pairs of disks. Levels 5, 6, 50, 60 - parity check, carry out the calculation of checksums, which are distributed over all disks at the same time utilize the equivalent capacity of one or two disks of the array (disk group).
RAID-0 is a classic of the genre, the type of array is beloved by individual mountain IT-specialists and individual video surveillance integrators. The maximum speed and no overhead for redundancy - it does not exist, the net volume is equal to raw. Accordingly, when flying out one disk, we lose all data in the array without the possibility of recovery. This RAID level is only suitable for test environments where data loss is acceptable and noncritical, in any application, RAID-0 is unacceptable, incl. and for video surveillance.
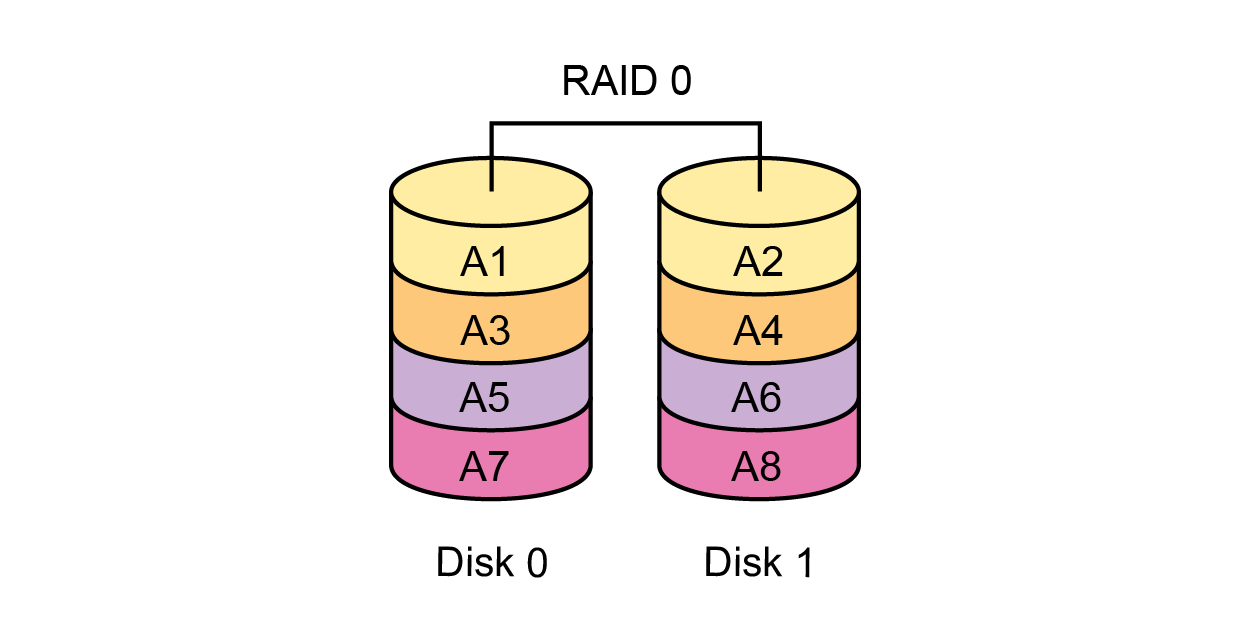
RAID-1 is not suitable because it is designed for only 2 disks.
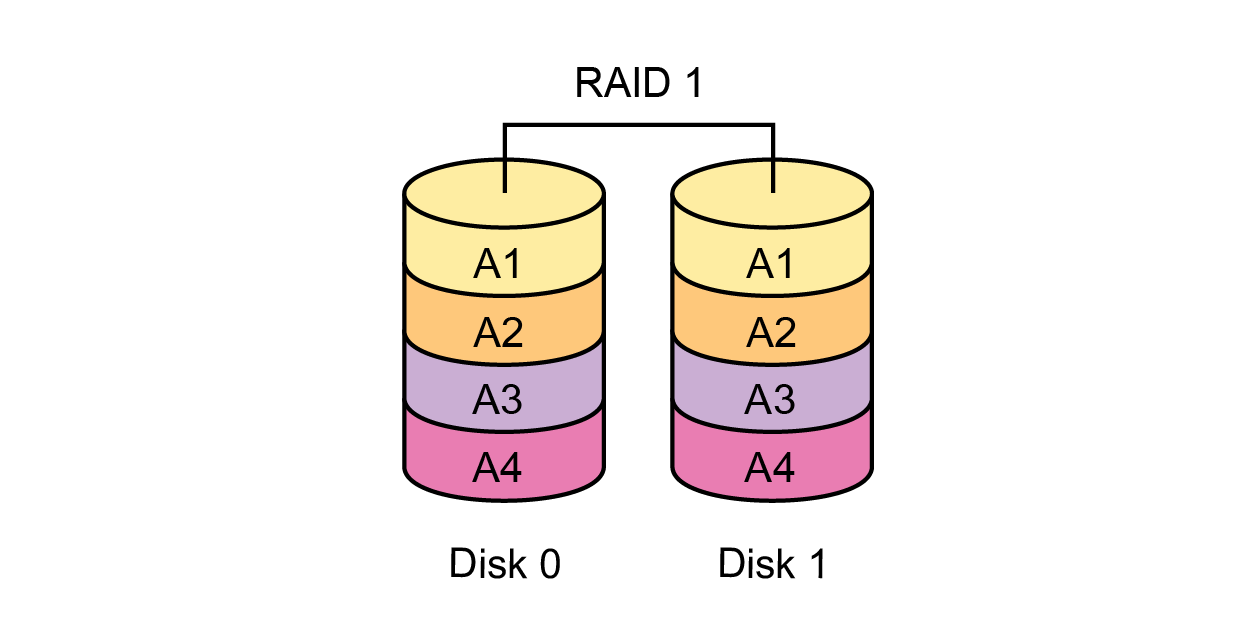
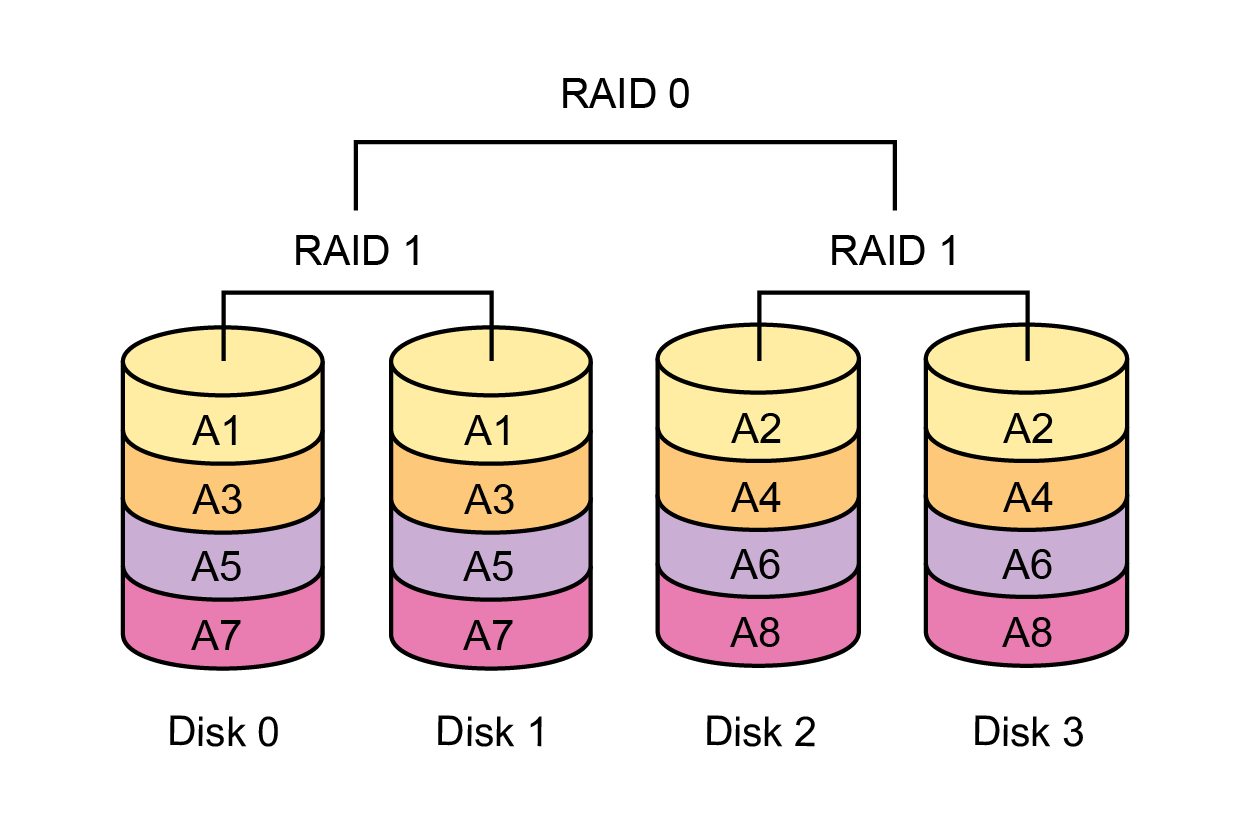
RAID-10 (RAID-0 from a variety of mirrored RAID-1 pairs) is not appropriate, since the overhead is too high, only half of the total raw capacity will be useful. On successive operations will be inferior in writing speed levels 5, 6, 50, 60.
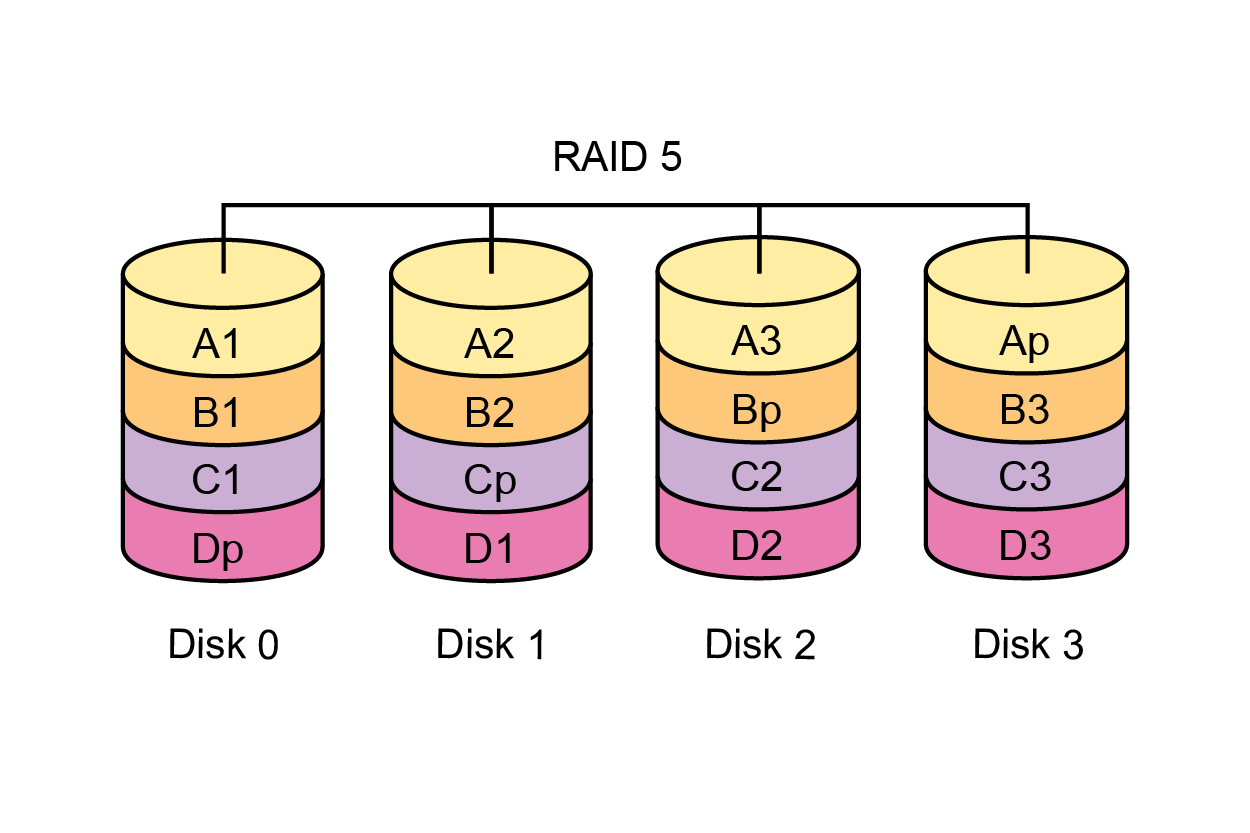
RAID-5 and RAID-50 (RAID-0 from several identical RAID-5 groups) - have slightly less overhead than RAID-6 and RAID-60 (one disk for redundancy in a disk group instead of two) and work faster, but allow you to survive the failure of only one disk. In the case of rebuilding such arrays, the load on them increases many times and the probability of the release of another disk increases dramatically, this is especially important for video surveillance, where large volumes of disks are used, which, respectively, are rebuilt longer. If, before the rebuild is completed, another disk will fly out, then the khan will be lost to the data on the whole array. Therefore, it is undesirable to use RAID-5 and RAID-50 for video surveillance.

For video surveillance, levels 6 and 60 (RAID-0 from several identical RAID-6 groups) are optimal because they provide maximum reliability and allow you to survive the simultaneous failure of any two disks.
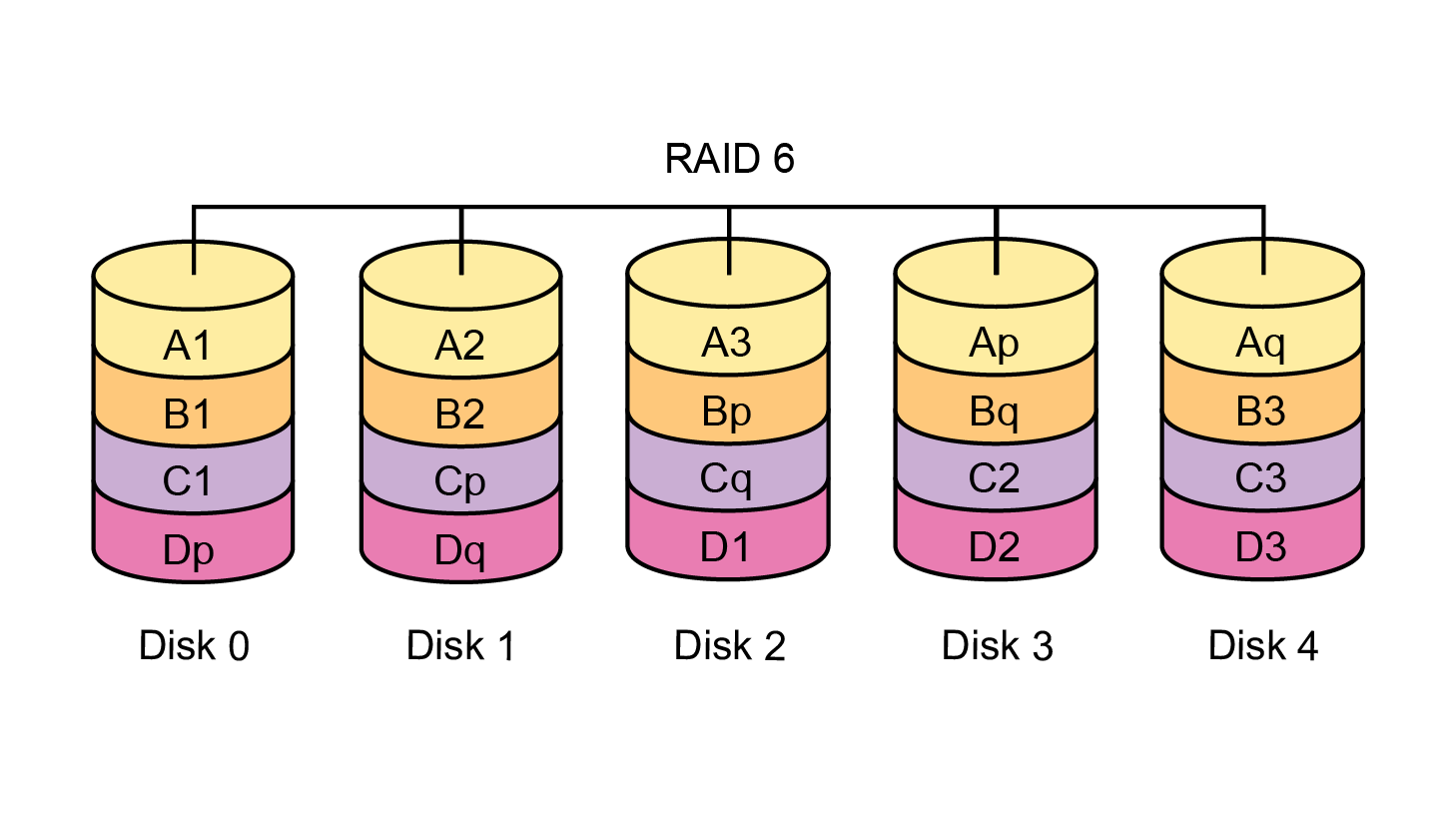
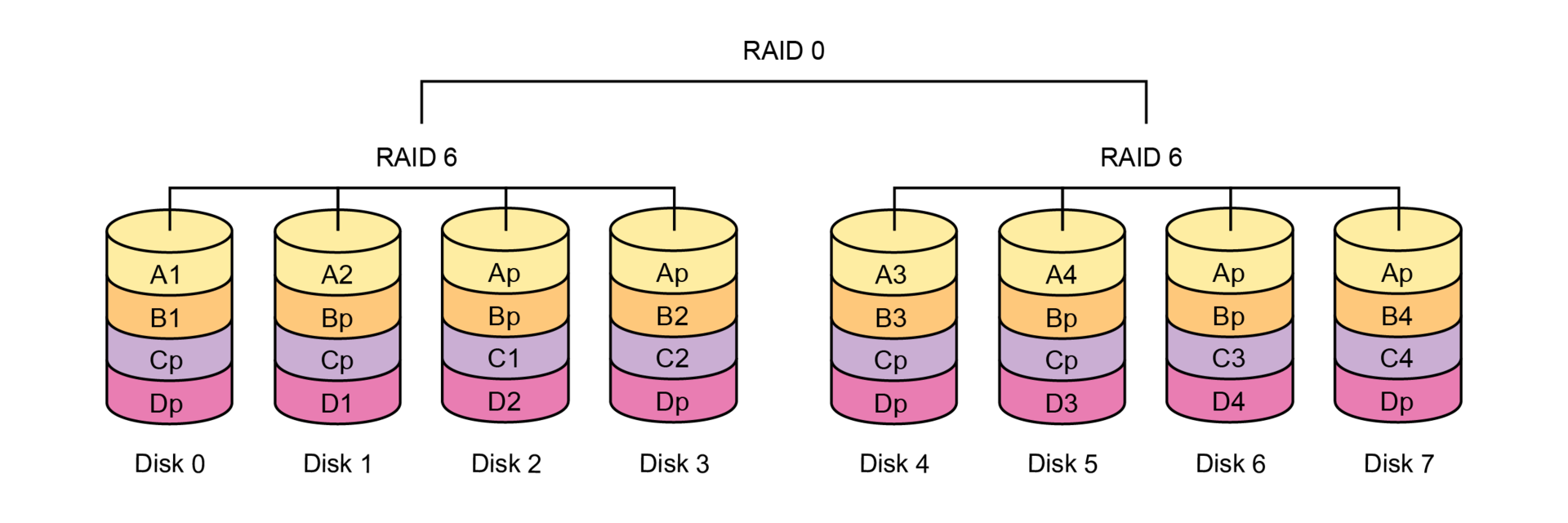
In general, for many years the use of RAID-6 and RAID-60 has been the best practice for any tasks in the IT industry due to their fault tolerance, although of course you have to use RAID-10 on random access.
For video surveillance, these RAID levels are especially relevant because they show excellent performance on sequential access, which is typical for a video stream. In this situation, RAID-6 or RAID-60 is preferable to RAID-10 because:
- sequential write speeds are higher — there are more usable spindles in RAID-6/60 than in RAID-10;
- less overhead - just two disks under redundancy for the entire disk group in RAID-6/60, instead of half the disks in RAID-10;
- fault tolerance is higher - RAID-6/60 allows you to work out the simultaneous failure of any two disks, RAID-10 ensures data integrity in case of failure of only one disk.
It should be noted an important disadvantage of RAID-6 and RAID-60 compared to RAID-10 - a significant performance drawdown in a degraded state, when one and especially two drives crashes, with RAID 5 and 50 the situation is the same. RAID-10 checksums do not consider that virtually eliminates performance drops. However, given that half of the capacity in RAID-10 goes under the mirror, for video surveillance, in which very large volumes are needed, it is not rational to use it. If you use high-performance hardware RAID controllers or storage systems, properly plan the array and the system as a whole, degradation of the RAID-6/60 array will not cause a disaster, and the capacity of the disks will be used efficiently.
Planning video server storage for 100 threads
We return from the theoretical excursion to the RAID-technology and remember that we need an array of 212TB. To organize the storage of such a volume, subject to the use of RAID-6 or RAID-60, we need 26-30 HDDs of 10TB:
- 1 RAID-6 group of 26 disks: 24 disks - usable volume, 2 disks - checksums;
- 2 separate RAID-6 disk groups with 14 disks or similar RAID-60;
- 3 separate RAID-6 disk groups with 10 disks or similar RAID-60.
Such a number of disks can be placed only in a special 4U rack-mount server platform, or use an external disk shelf bundled with a 1U server on which stream processing will be performed. In any case, it will be necessary to use a good dedicated (not embedded in the motherboard) hardware RAID controller with support for RAID-6/60, which can pull out so many disks and ensure normal operation of the array in case of degradation - failure of 1-2 disks.
Video server requirements for 500 streams
Consider the system requirements for 500 IP cameras. In this case, we will need two Intel Xeon E5-2630 V3 processors (8 cores at 2.4 GHz), and better two Intel Xeon E5-2680 V3 (12 cores at 2.5 GHz). So, the server platform should be dual-processor and we can still do with one server.
The useful capacity of the video archive in this case exceeds 1PB, and if it is accurate, it is
1,059.84 TB, these are 117 disks of 10TB, for multiplicity and with a margin it is better to take 120 disks. The overhead of placing checksums in a RAID array will require another 10-20-30 such disks, for example, 5-10-15 RAID-6/60 disk groups for 26-14-10 disks. Such a number of disks will not be included in any standard server platform (maximum 24-36 HDD 3.5 "on 4U server), external disk shelves will be needed. In this case, one solution will be a 2-socket 1U server and two 4U disk shelves (90 + 60 HDD) connected in cascade. The correct RAID controller can pull out the number of disks we need, connect it to the first basket (disk shelf) with two Mini-SAS HD cables, and attach the second basket to the first with two such cables.
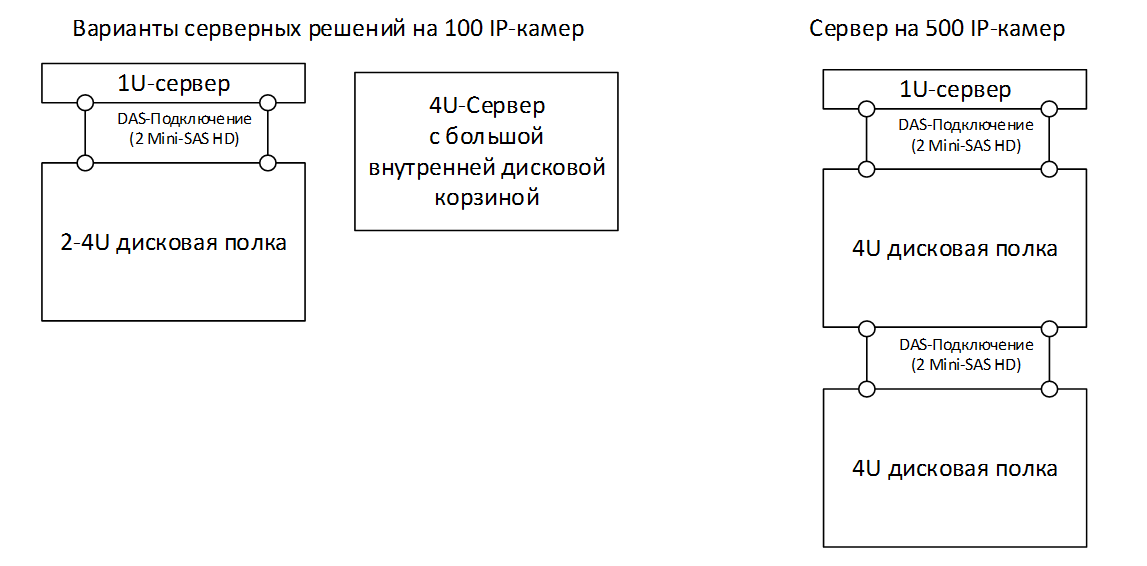
Load distribution and lyrical digression
We reviewed examples of designing IT infrastructure for video surveillance systems for 100 and 500 IP cameras that generate a serious load. Call such CCTV systems small and cheap can not be. A system with 100 cameras is at least an average project, and 500 is already a large one. Nevertheless, in both cases we could manage with one server, in the first case without disk shelves or with one, in the second two large baskets will suffice.
In terms of computing power and performance of the disk subsystem, the approach works, one server takes everything out. Values of 100 and 500 streams are fairly arbitrary, determined by the characteristics of the project, the complexity of the load and the selected VMS. In practice, the actual numbers will most likely be 50-100-200 flows per server. After all, if the task involves serious video analytics, or there is a constant multi-threaded viewing of data from the archive, we can rest against the performance of very steep processors and disk subsystems already on 50-100 streams. Accordingly, if there are hundreds or even thousands of cameras, it is necessary to deploy a farm (set) of video servers, each of which will take its own share of the streams: 50, 100 or 200, depending on the load and hardware configuration. Distributing the load across multiple identical video servers, each of which stores data on directly connected drives (DAS), is standard practice for video surveillance.
In simpler situations, when the system requires just a stable high-quality video recording without additional burden on analytics, and viewing from the archive is carried out by one camera (from time to time, but it can be done all the time) - 500 IP cameras per server are more realistic. If you put 18-core processors, several RAID controllers and a bunch of disk baskets, then it is theoretically possible to hang 1000+ threads on one server. In principle, large systems can be built from several servers for 500+ cameras, following the above concept of a set of DAS servers.
From the point of view of IT infrastructure costs, its deployment and administration, this option is the best - the cheapest, easiest, minimum of IT competencies. No need to bother with the network and data storage system which we will discuss below. This approach is used by most integrators of video surveillance systems, otherwise they simply do not know how. At the same time in the installation, design and configuration of video surveillance directly (VMS, cameras, cables) they can be aces. And this is normal, it is impossible to know and be able to do everything, just in this case, when working in serious projects, the IT infrastructure must be left to the professionals. Even in the examples reviewed, choosing the right hardware, optimally setting up the disk subsystem, properly installing and configuring the server operating system, and integrating into the customer’s overall IT infrastructure, if necessary, is not at all simple, highly specialized knowledge is needed. Therefore, this task should be handled by the customer's IT specialists, a specialized organization partner, or the video surveillance integrator should have these competencies.
Reservation requirement
To get back to business, using the concept of DAS servers (one powerful server or server pool) to build large video surveillance systems, for all its charms, has very serious disadvantages in terms of resiliency and maintenance of the storage subsystem.
Any standard server, even from a premium manufacturer, even with duplication of power supplies and network interfaces can fail, because it has at least one single point of failure - the motherboard. Server disk controllers, as a rule, are also not duplicated, there are still processors, RAM and other elements that can fail.
If the video surveillance system is built on a single server, and it is not duplicated (reserved), then we put the eggs in one basket. If this video server giknet (fails), and this happens, the video will have nowhere to write until we fix it, while there is a risk of losing the video archive, partially or fully. This is especially dangerous for steroid monster eggs on 500+ cameras, since everything is tied to a single server, it is better to avoid this and distribute the load across several servers.
When the load is distributed across the DAS server farm, we are in a better situation. If one of the farm servers fails, we lose only a part of the cameras of the system it serves, and we risk only its video archive.
However, the loss of hundreds or several hundred cameras at the time of recovery of the video server in many cases is unacceptable. Therefore, it is necessary to provide for the backup of video servers. To do this, one or several dedicated backup servers must be added to the video server pool. In normal mode, when all the primary servers are alive, the backup servers are idle, but if one or more of the primary servers fail, the VMS automatically switches their streams to the backup servers. The computational capacity and configuration of the backup servers should ideally be identical to the main ones; their storage capacity should provide an acceptable archive depth for the recovery time of the main servers. Naturally, VMS should support redundancy or clustering functionality and the corresponding license should be purchased.
Storage Approach
An alternative approach, in our opinion more correct, reliable and technological - the separation of computing resources and storage resources. In this case, we make a fault-tolerant cluster of several 1-2U servers on which VMS is installed and video streams are processed, and the data is stored on one or several fault-tolerant two-controller external storage systems (DSS). You can scale these two sets of resources independently, increasing the number of cluster servers, performance, and disk storage resources.
Proper storage, unlike a server, does not have single points of failure. A storage system is a specialized software and hardware complex, the only tasks of which are reliable storage and ensuring the required data input / output speed, and fault tolerance is stored in it by default.
If the storage system is a single solution, then all its elements are duplicated or their redundancy is ensured. The main element of storage is the controller (storage processor), it processes the I / O, combines disks into RAID groups and creates logical partitions or volumes on them that are provided to the end devices (video servers - cluster nodes) that store data on the storage. Proper storage has two controllers. In normal mode, both controllers divide the load in half, if one of them is dead (failed), then the second will automatically take over the entire load without stopping, it will be transparent and transparent to the end nodes (video servers). RAID groups in which storage disks are combined make it possible to survive the failure of one or several disks. Network interfaces and power supplies are duplicated. This means that there is not a single point of failure in the storage system; only a passive printed circuit board is not duplicated in it, which theoretically cannot break. To disable such a storage system, you can only with an ax or a bucket of water, and in this case you can "get a ticket" and for complete happiness replicate data to the second such storage system. Yes, it’s expensive, but if the task is so critical, then you don’t feel any money, the main thing is that there is such a technical possibility.
The storage system can be distributed, in which case it is horizontally scaled by identical blocks of nodes filled with disks, while its capacity and performance linearly increase. The fault tolerance of such solutions is achieved through redundancy at the node level; accordingly, they ensure the failure not only of individual disks, but also of several nodes entirely. This may be true for very large infrastructures with thousands of cameras.
In any case, the basis of normal storage is specialized software and often heavily stripped down OS (operating system), while eliminating the performance of any other tasks other than storage. Due to this, maximum reliability and speed of access to data is achieved, unlike conventional servers with operating systems and general-purpose software.
Storage Networking
Video servers are connected to storage using file (NAS, for example, NFS or SMB) or block (SAN, for example, iSCSI, FC, iSER) access protocols and ideally require the creation of a dedicated storage network. To do this, each video server must be equipped with appropriate physical adapters, preferably selected and duplicated. The core of the storage network will be a pair of dedicated switches connecting multiple video servers to the storage system. Physical allocation of a storage network from other data transmission networks, the use of separate equipment for its organization with redundancy (switches and adapters) will guarantee its simplicity and transparency, security and isolation, specified throughput and fault tolerance.
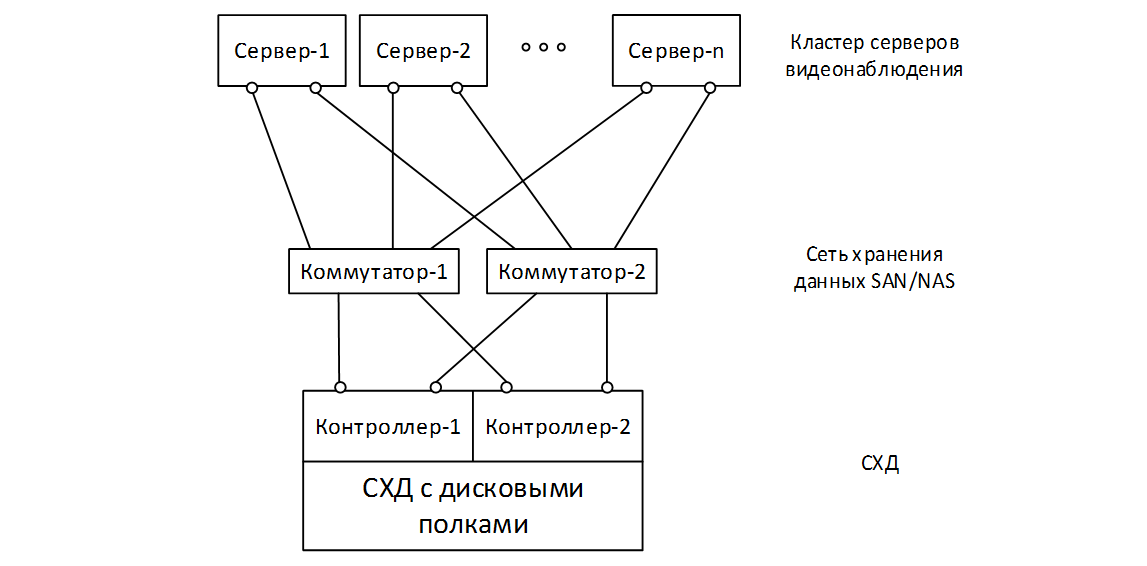
In the simplest case, a pair of high-performance 10GbE switches (Ethernet, 10Gbps / s) and a pair of dedicated 1-10GbE ports per video server is enough for organizing a storage network, and you can use file NFS or block iSCSI as a transport. Theoretically, in situations that require greater performance (very large projects), converged Ethernet or Infiniband (IB) adapters with RDMA support (SRP, iSER, RoCE) and appropriate switches may be needed, and the servers will most likely have enough 10 Gbit / s on the servers, and switches and storage systems will need at least 40 Gbit / s. The good old Fiber Chanel (FC, 16 Gbit / s) can also be useful if there is enough bandwidth.
Advantages of using storage systems for video surveillance
Obviously, the need for networking storage for storage solutions requires additional costs and increases the complexity of the project compared to traditional DAS solutions. However, this approach in addition to performance, reliability and fault tolerance has a number of other advantages:
- Avoiding the need to organize and maintain local or DAS disk arrays on servers. Virtually all data from video surveillance systems are stored centrally on the storage system, local drives on servers are only needed to create boot partitions with the OS and the installed VMS. For their organization, there will be enough of a pair of small budget carriers united in RAID-1 based on the controller built into the motherboard.
- For the organization of video servers, the best platform option will be a compact and efficient 1U server. There is no need to use bulky 2-4U server platforms or DAS shelves. At the same time, the need to install expensive hardware RAID controllers on each server goes away.
- Creation and maintenance of disk groups and volumes, monitoring and access control to them, in general, all operations related to data storage are now centralized on the storage system from a single console. Storage management tools greatly outperform any local disk controller in terms of flexibility, power, and convenience.
And finally, an indisputable argument in favor of the use of storage systems in serious projects for video surveillance. It works regardless of the number of VMS servers, even if the cluster includes only two video servers - the main and the backup one. Storage is a shared storage and is always accessible to all nodes of the video surveillance cluster. Therefore, if one of the primary nodes drops, the backup node will pick up all its video streams and continue writing them to the archive on the same volume, since it is located on the storage system. In fact, there will be a relocation of the VMS server entity from the failed main hardware to the backup with all the settings. It will be possible to work transparently with the video archive of this server for all its depth. Of course, this possibility should be maintained at the level of video surveillance software (VMS).
In the traditional DAS approach with local arrays, this cannot be done, since it is impossible to organize shared storage. When a server crashes, its local array becomes unavailable, the backup server will have to write an archive to its local storage, work with the archive will be available only as part of the data recorded after the crash, the archive from the main server will not be available for viewing. After the restoration of the primary server, questions will arise with the synchronization of the archives. This is a serious drawback.
Summary
In this article we have tried to understand the features of the organization of the IT infrastructure and the storage subsystem for video surveillance. We considered the advantages and disadvantages of approaches for using servers with local (DAS) storage and storage. We came to the conclusion that for large projects that do not allow downtime, failure and degradation of functionality, the use of storage systems for storing video archives is the best solution, despite some complexity.
The next article will discuss the criteria for choosing a storage system for video surveillance. For dessert - a description of a large project on video surveillance for 2000 cameras with the implementation of storage based on RAIDIX.
Source: https://habr.com/ru/post/331370/
All Articles