LSTM — Long Short-Term Memory Networks
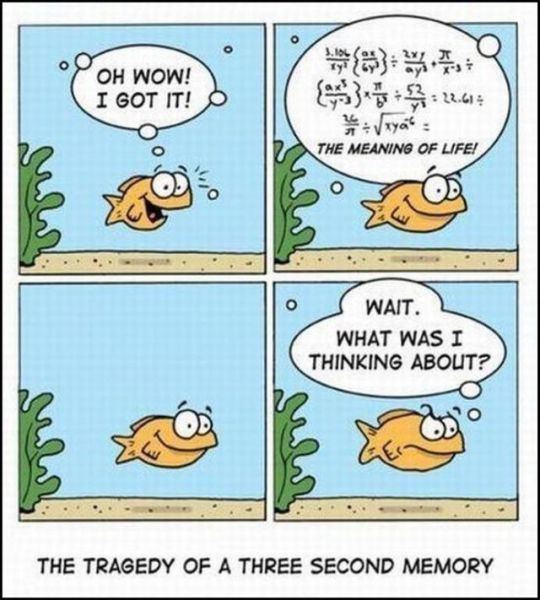
Recurrent Neural Networks
People don't start thinking from scratch every second. Reading this post, you understand each word based on the understanding of the previous word. We do not throw everything out of our heads and do not start thinking from scratch. Our thoughts are consistent.
Traditional neural networks do not have this property, and this is their main drawback. Imagine, for example, that we want to classify events occurring in a film. It is not clear how a traditional neural network could use reasonings about previous events of the film to get information about subsequent ones.
Recurrent neural networks (RNN) help solve this problem. These are networks that contain feedback and allow you to store information.

Recurrent neural networks contain feedbacks.
')
In the diagram above, a fragment of the neural network accepts input value and returns the value . The presence of feedback allows you to transfer information from one network step to another.
Feedbacks give recurrent neural networks some mystery. However, if you think about it, they are not so different from ordinary neural networks. A recurrent network can be considered as several copies of the same network, each of which transmits the information of the subsequent copy. Here is what happens if we expand the feedback:
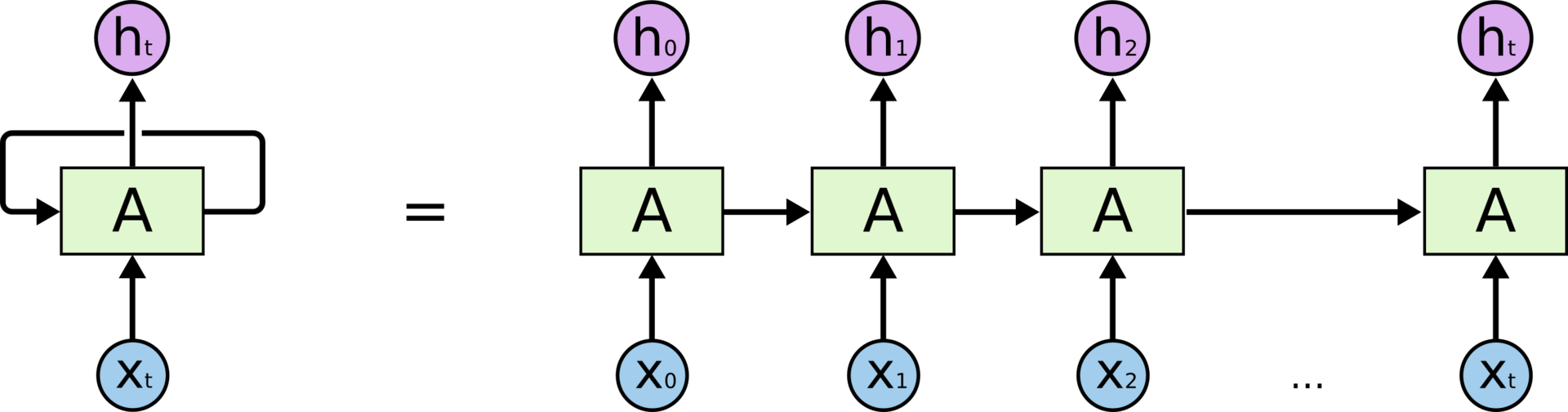
Recurrent neural network in scan
The fact that RNN resemble a chain suggests that they are closely related to sequences and lists. RNN is the most natural architecture of neural networks for working with data of this type.
And of course, they are used for such tasks. Over the past few years, RNN has been incredibly successfully applied to a variety of tasks: speech recognition, language modeling, translation, image recognition ... The list goes on. About what can be achieved with the help of RNN, tells the excellent blog post by Andrei Karpatoy (Andrej Karpathy) The Unreasonable Effectiveness of Recurrent Neural Networks .
A significant role in these successes belongs to LSTM - an unusual modification of the recurrent neural network, which in many cases significantly exceeds the standard version. Almost all of the impressive RNN results were achieved with LSTM. Our article is devoted to them.
The problem of long-term dependencies
One of the attractive ideas of RNN is that they are potentially able to associate previous information with the current task, for example, knowledge of the previous frame of the video can help in understanding the current frame. If the RNN had this ability, they would be extremely useful. But do RNNs really give us that opportunity? It depends on certain circumstances.
Sometimes for the current task we need only recent information. Consider, for example, a language model trying to predict the next word based on previous ones. If we want to predict the last word in the sentence “clouds float across the sky ”, we do not need a broader context; in this case, it is pretty obvious that the last word is “heaven”. In this case, when the distance between the actual information and the place where it was needed is small, the RNN can learn how to use information from the past.
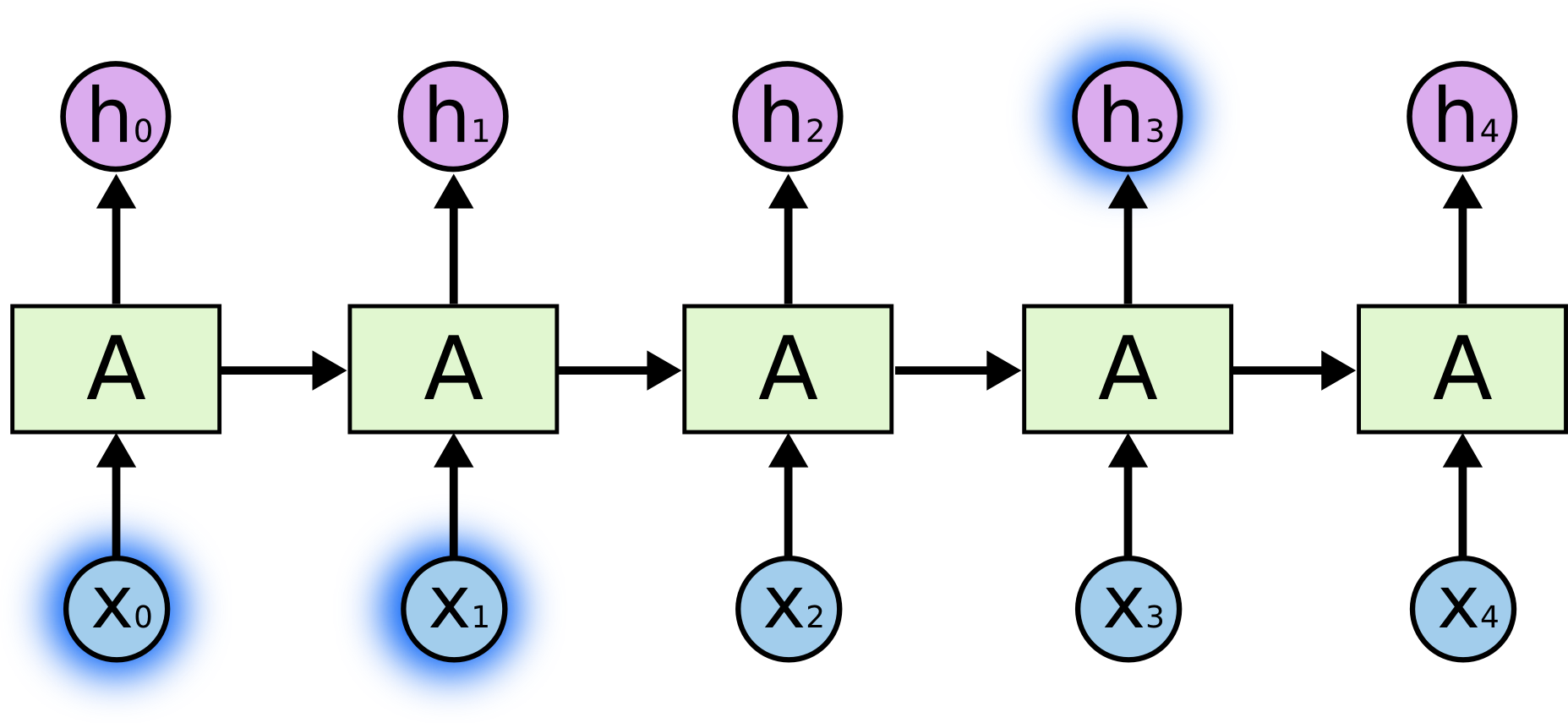
But there are times when we need more context. Suppose we want to predict the last word in the text “I grew up in France ... I speak fluent French .” The immediate context suggests that the last word will be the naming of a language, but in order to establish which particular language we need the context of France from a more distant past. Thus, the gap between the actual information and the point of its application can become very large.
Unfortunately, as this distance grows, RNNs lose their ability to bind information.
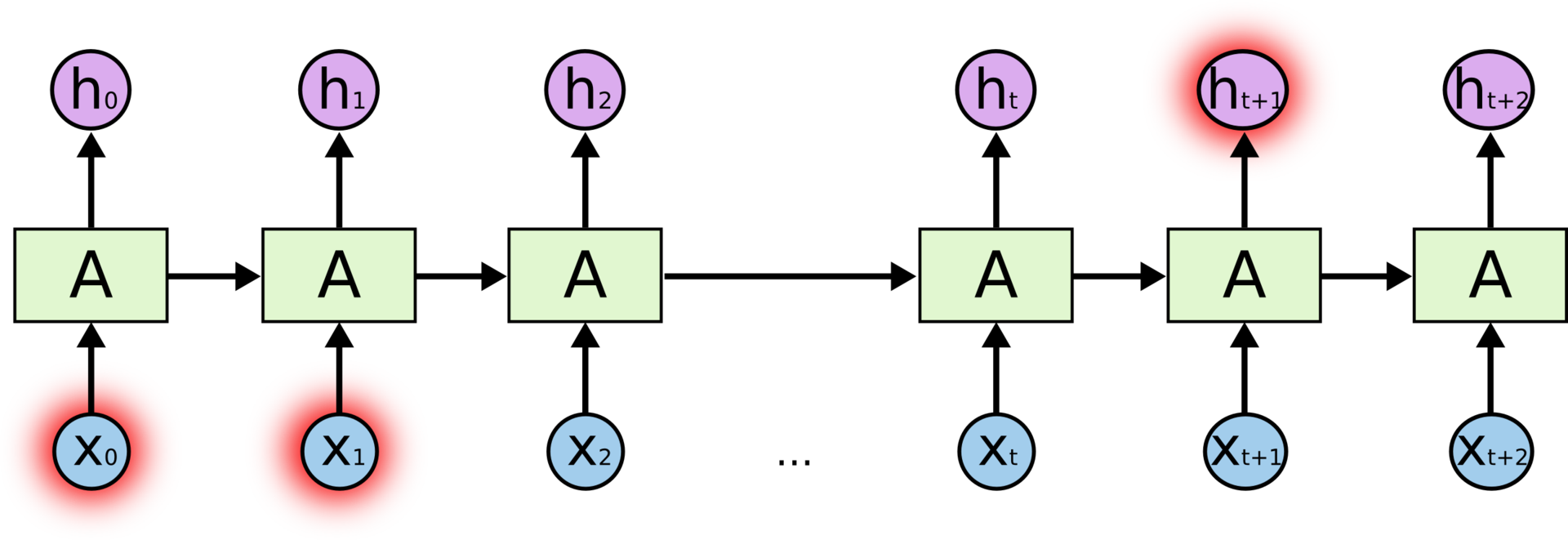
In theory, RNN should not have problems with handling long-term dependencies. A person can carefully select network parameters for solving artificial tasks of this type. Unfortunately, in practice it is impossible to teach RNN to these parameters. This problem was investigated in detail by Sepp Hochreiter ( Sepp Hochreiter, 1991 ) and Yoshua Bengio et al. (1994) ; they have found compelling reasons why this can be difficult.
Fortunately, LSTM does not know such problems!
LSTM networks
Long short-term memory (LSTM) is a special kind of recurrent neural network architecture capable of learning long-term dependencies. They were introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997 , and then refined and popularized in the works of many other researchers. They perfectly solve a number of diverse tasks and are now widely used.
LSTMs are specifically designed to avoid the problem of long-term dependency. Memorizing information for long periods of time is their usual behavior, and not something that they are struggling to learn.
Any recurrent neural network has the form of a chain of repeating modules of a neural network. In a typical RNN, the structure of one such module is very simple, for example, it can be a single layer with an activation function tanh (hyperbolic tangent).
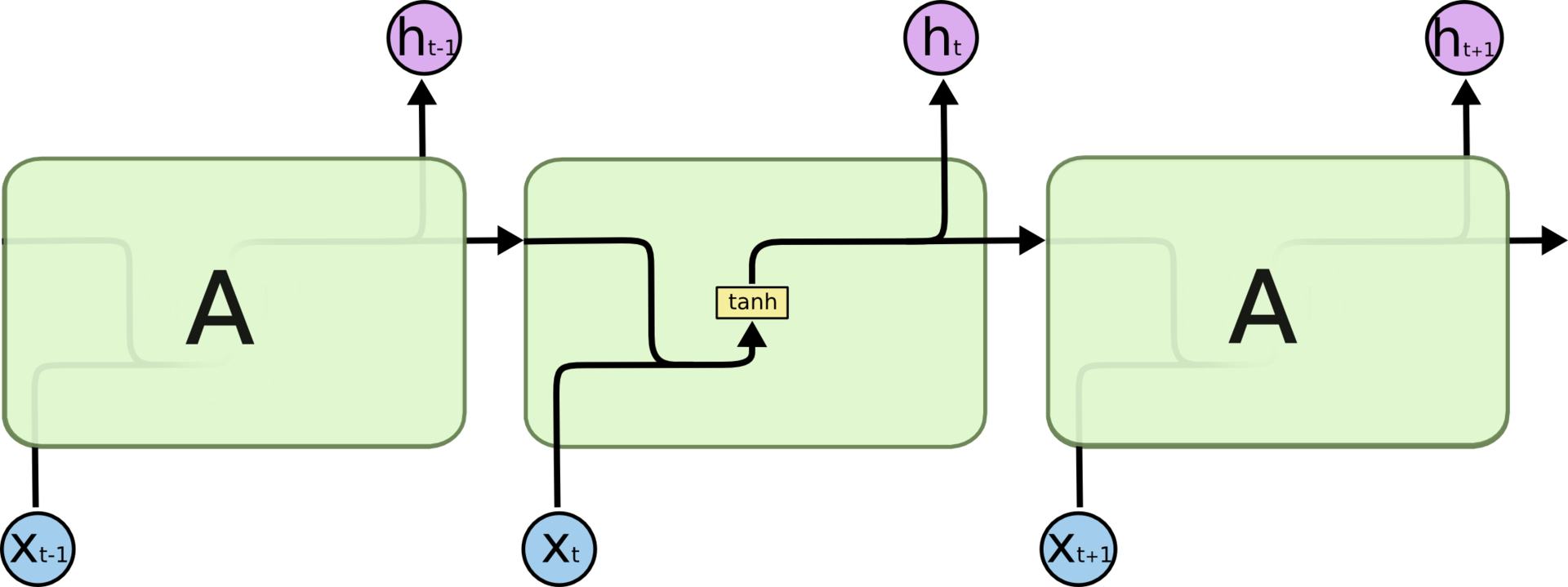
The repeating module in a standard RNN consists of a single layer.
The LSTM structure also resembles a chain, but the modules look different. Instead of a single layer of the neural network, they contain as many as four, and these layers interact in a special way.
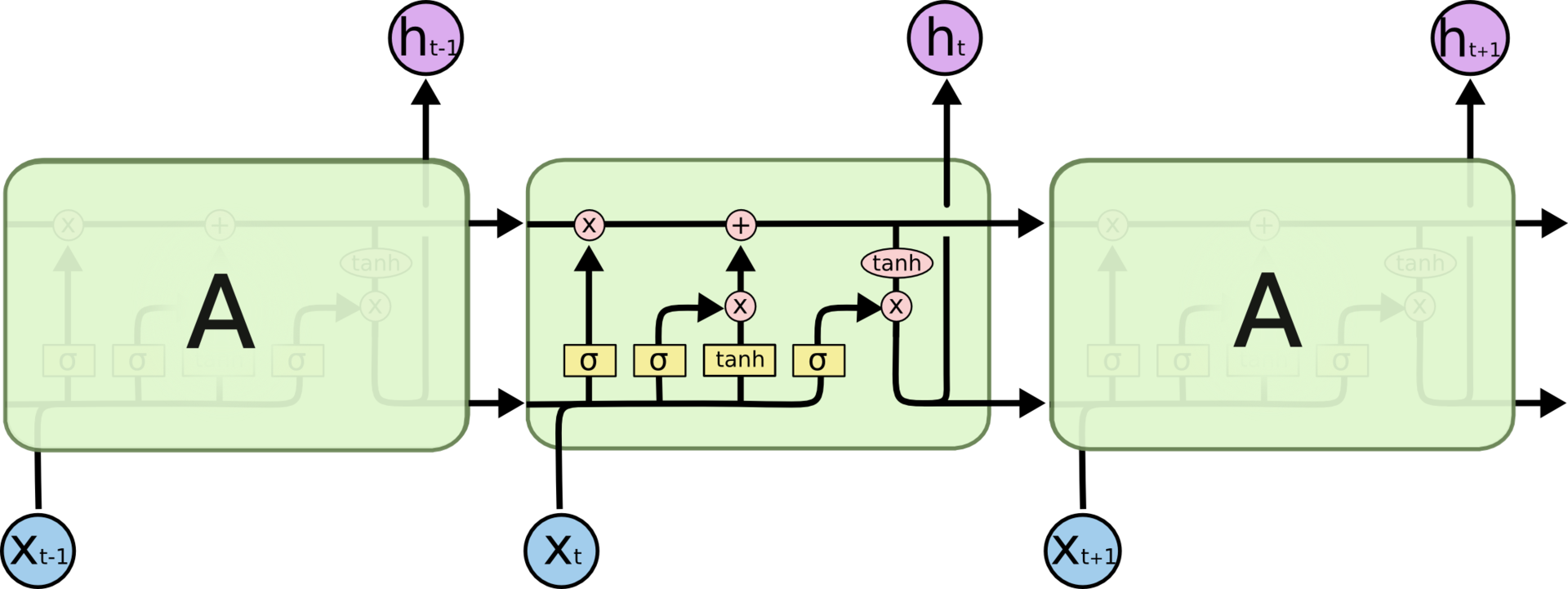
The repetitive model in the LSTM network consists of four interacting layers.
We will not be puzzled by the details yet. Consider each step of the LSTM scheme later. While we get acquainted with the special symbols that we use.

Neural network layer; pointwise operation; vector transfer; Union; copying.
In the diagram above, each line carries a whole vector from the output of one node to the input of another. Pink circles indicate pointwise operations, such as vector addition, and the yellow rectangles are the trained layers of the neural network. Merging lines mean merging, and branching arrows indicate that the data is copied and copies go to different components of the network.
LSTM main idea
The key component of LSTM is the cell state — a horizontal line that runs along the top of the circuit.
The state of the cell resembles a conveyor belt. It passes directly through the whole chain, participating only in a few linear transformations. Information can easily flow through it without changing.
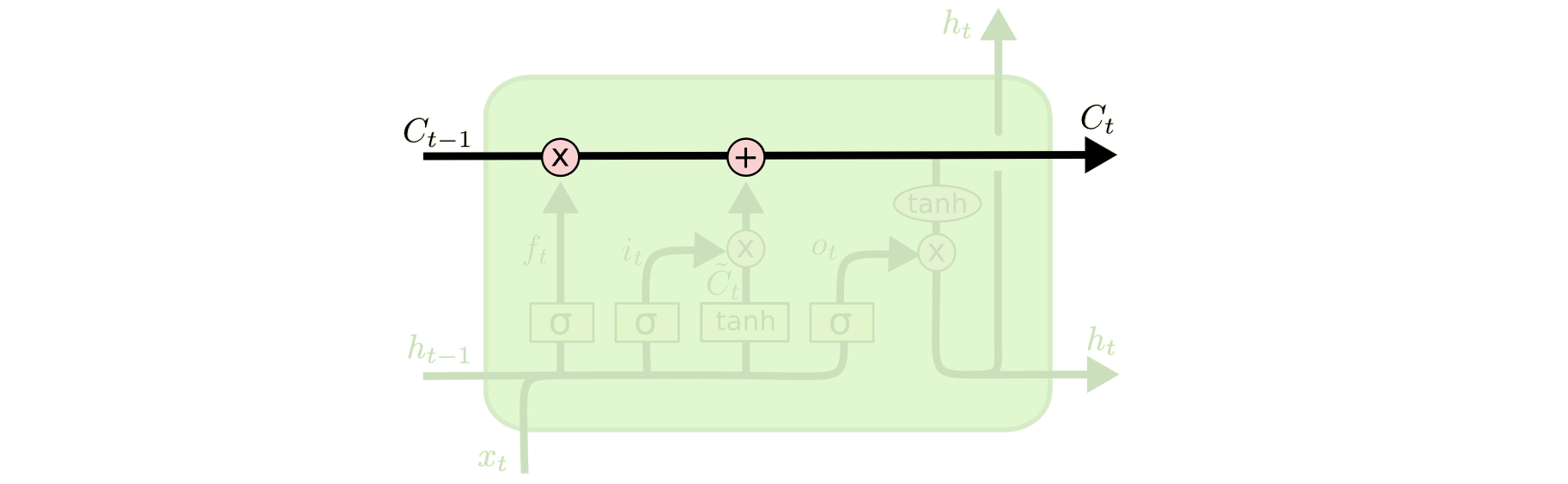
However, LSTM can remove information from the cell state; this process is governed by structures called filters (gates).
Filters allow you to skip information based on certain conditions. They consist of a layer of a sigmoidal neural network and a pointwise multiplication operation.
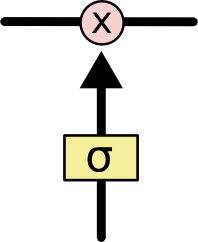
The sigmoidal layer returns numbers from zero to one, which indicate how much of each block of information should be passed further along the network. Zero in this case means “do not skip anything”, unit - “skip all”.
There are three such filters in LSTM to protect and monitor cell health.
LSTM Walkthrough
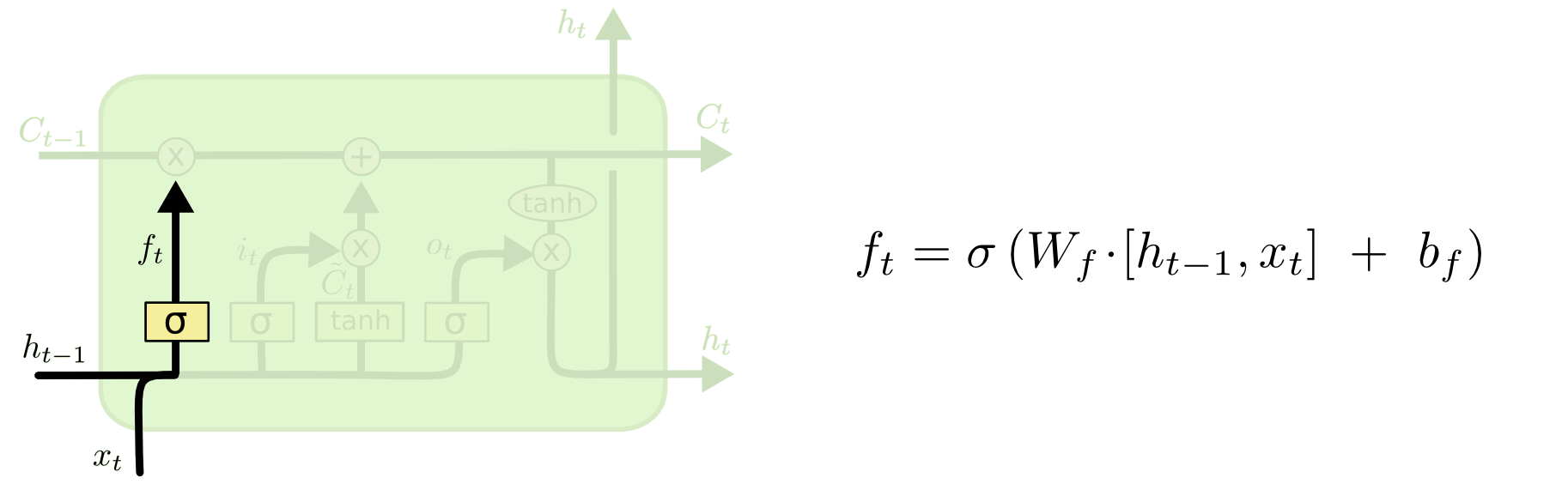
The first step in LSTM is to determine what information to throw out of the cell state. This decision is made by a sigmoidal layer called the “forget gate layer”. He looks at and and returns a number from 0 to 1 for each number from the state of the cell . 1 means “fully preserve” and 0 means “completely discard”.
Let us return to our example - a language model that predicts the next word based on all the previous ones. In this case, the state of the cell must preserve the noun in order to then use pronouns of the corresponding gender. When we see a new noun, we can forget the genus of the old.
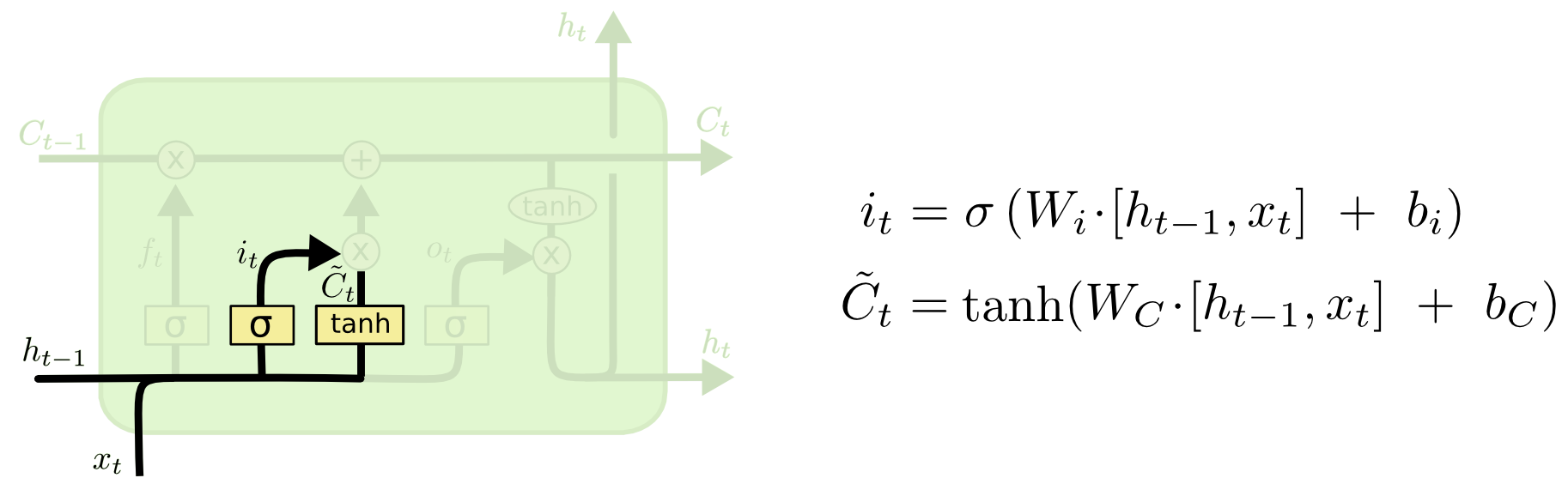
The next step is to decide which new information will be stored in the cell state. This stage consists of two parts. First, a sigmoid layer called “input layer gate” determines which values should be updated. Then the tanh layer builds a vector of new candidate values. that can be added to the cell state.
In our example with the language model in this step, we want to add the gender of the new noun, replacing the old one.
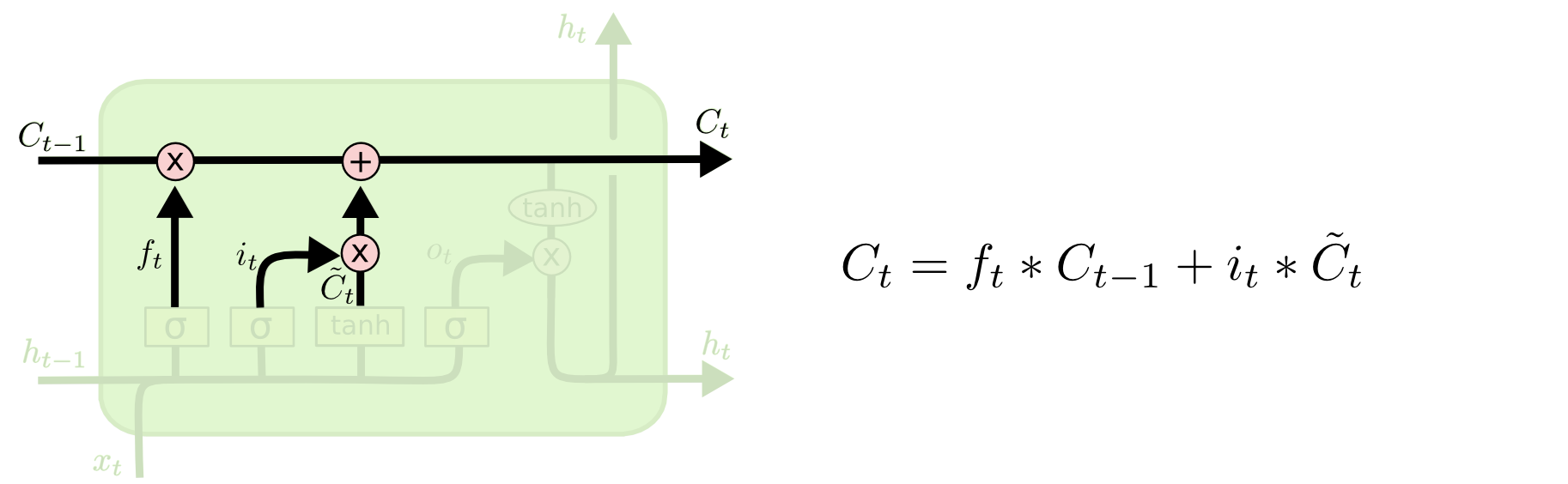
It is time to replace the old cell state. on a new state . What we need to do - we have already decided on the previous steps, it remains only to complete it.
We multiply the old state by , forgetting what we decided to forget. Then add . These are new candidate values multiplied by - how much we want to update each of the state values.
In the case of our language model, this is the moment when we throw out information about the gender of the old noun and add new information.
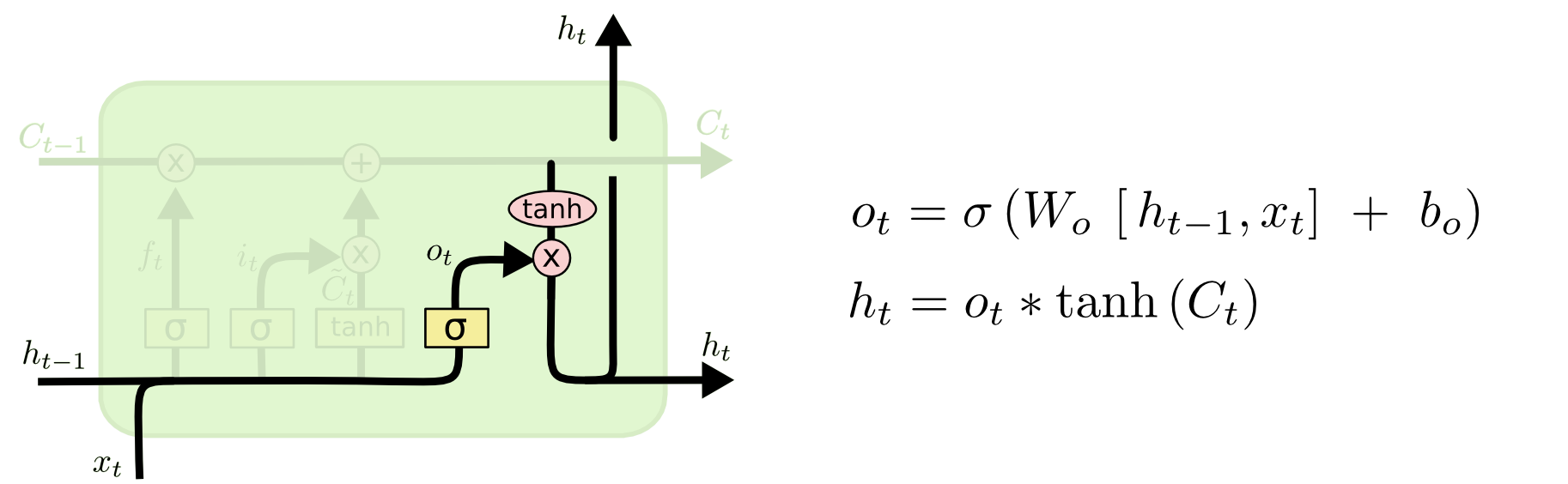
Finally, you need to decide what information we want to receive at the output. The output will be based on our cell status, and some filters will be applied to them. First, we apply a sigmoidal layer that decides what information from the state of the cell we will output. Then the state values of the cell pass through the tanh-layer to get the output values from the range from -1 to 1, and are multiplied with the output values of the sigmoidal layer, which allows you to display only the required information.
We may want our language model, finding a noun, to display information that is important for the verb following it. For example, she can deduce whether the noun is singular or plural in order to correctly determine the form of the subsequent verb.
LSTM variations
We have just reviewed the regular LSTM; but not all LSTM are the same. In general, it seems that each new work on LSTM uses its own version of LSTM. The differences between them are minor, but some of them are worth mentioning.
One of the popular variations of LSTM, proposed by Gers & Schmidhuber (2000) , is characterized by the addition of so-called “peephole connections”. With their help, filter layers can see the state of the cell.
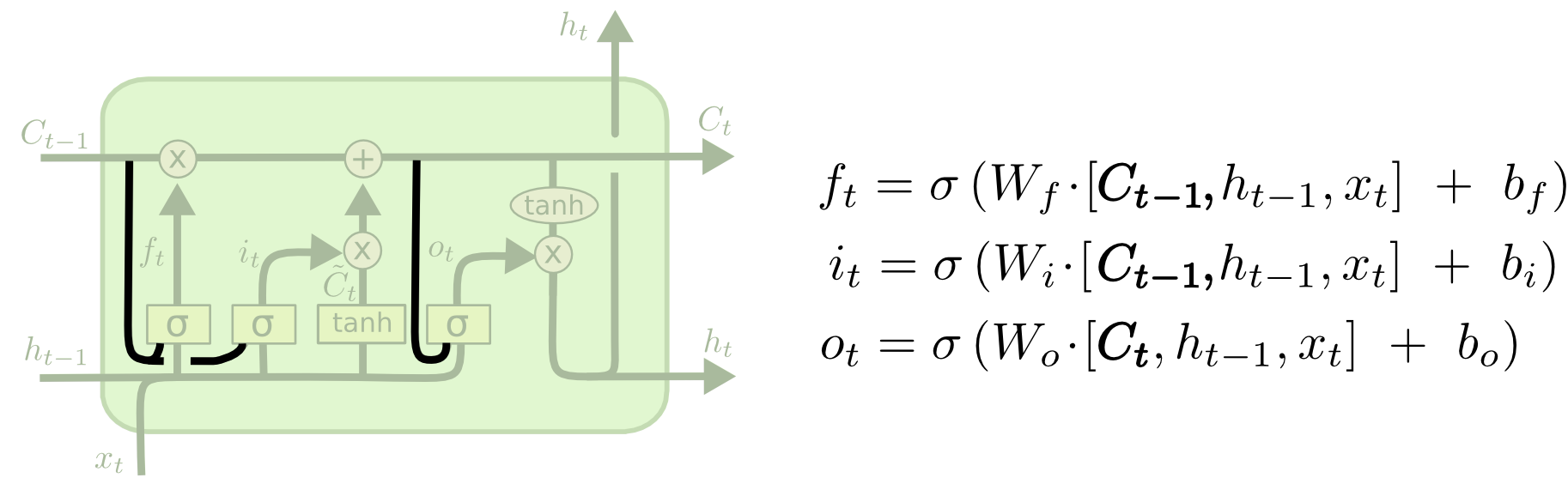
In the diagram above, each layer has “eyes”, but in many papers they are added only to certain layers.
Other modifications include combined forgetting filters and input filters. In this case, decisions about which information should be forgotten, and which to remember, are not taken separately, but jointly. We forget any information only when it is necessary to write something in its place. We add new information with the state of the cell only when we forget the old one.
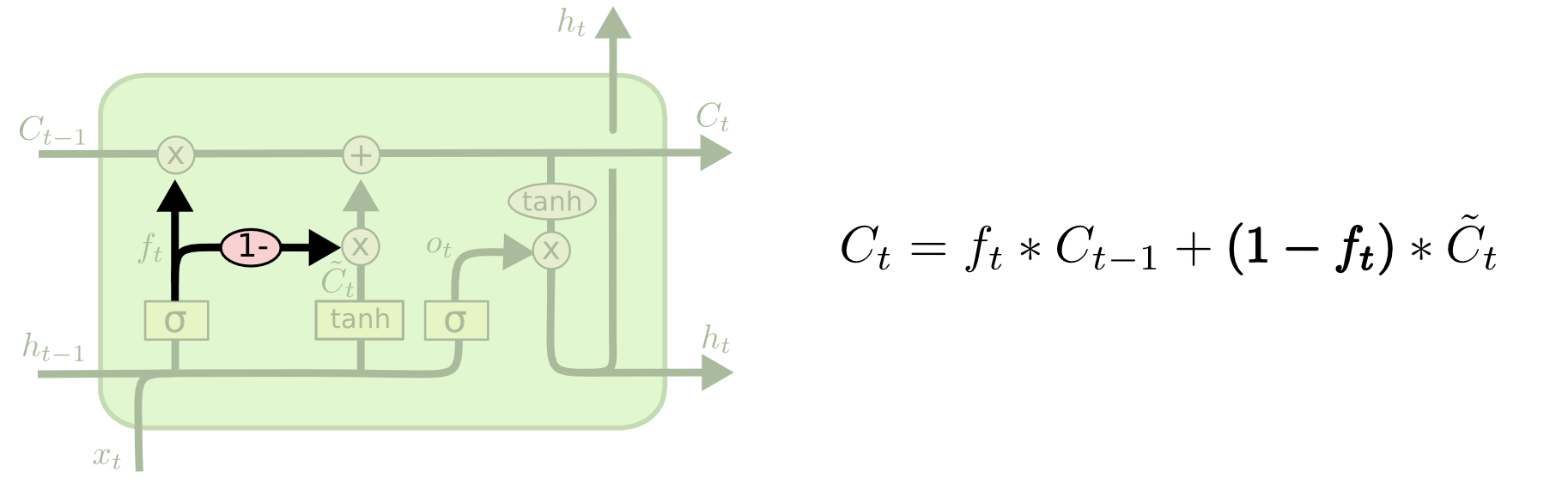
Managed recurrent neurons (Gated recurrent units, GRU), first described in Cho, et al (2012), differ slightly from the standard LSTM. In it, the “forgetting” and entry filters are combined into one “update gate” filter. In addition, the state of the cell is combined with the hidden state, there are other small changes. The resulting model is simpler than the standard LSTM, and its popularity is steadily increasing.

We looked at just a few of the most remarkable variations of LSTM. There are many other modifications, such as deep controlled recurrent neural networks (Depth Gated RNNs), presented in Yao, et al (2015) . There are other ways to solve the problem of long-term dependencies, for example, Jan Kutnik's Clockwork RNN (Koutnik, et al., 2014) .
What is the best option? What is the role of the differences between them? Klaus Greff (Klaus Greff) and colleagues give a good comparison of the most popular variations of LSTM and in their work come to the conclusion that they are all approximately the same. Rafal Jozefowicz, et al, in his 2015 work, tested more than ten thousand RNN architectures and found several solutions that work on certain tasks better than LSTM.
Conclusion
We have previously mentioned outstanding results that can be achieved using RNN. In essence, all these results were obtained on LSTM. On most tasks, they actually work better.
LSTMs written in the form of a system of equations look pretty frightening. We hope that the step by step analysis of LSTM in this article made them more accessible.
LSTM is a big step in the development of RNN. This raises a natural question: what will be the next big step? According to the general opinion of researchers, the next big step is “attention” (attention). The idea is this: each RNN step takes data from a larger repository of information. For example, if we use RNN to generate a caption for an image, then that RNN can view the image in parts and generate individual words based on each part. The work of Kelvin Xu (Xu, et al., 2015) , devoted to just such a task, can serve as a good starting point for those who want to study such a mechanism as “attention”. Researchers have already managed to achieve impressive results using this principle, and it seems there are still many discoveries ahead ...
Attention is not the only interesting area of research in RNN. For example, the Grid LSTM described in Kalchbrenner, et al. (2015) seem very promising. Studies on the use of RNN in generative models ( Gregor, et al. (2015) , Chung, et al. (2015) or Bayer & Osendorfer (2015) are also extremely interesting. The last few years are the heyday of recurrent neural networks, and the next years promise to bring even greater fruits.
Oh, and come to work with us? :)wunderfund.io is a young foundation that deals with high-frequency algorithmic trading . High-frequency trading is a continuous competition of the best programmers and mathematicians of the whole world. By joining us, you will become part of this fascinating fight.
We offer interesting and challenging data analysis and low latency tasks for enthusiastic researchers and programmers. Flexible schedule and no bureaucracy, decisions are quickly made and implemented.
Join our team: wunderfund.io
Source: https://habr.com/ru/post/331310/
All Articles