How do neural networks help us with technical support
Despite the general hyip around machine learning and neural networks, undoubtedly, now they really should pay special attention. Why? Here are the key reasons:
But to manage it is still difficult: a lot of mathematics, higher and merciless. And either you are from Fizmat, or sit and solve 2-3 thousand puzzles within two to three years to understand what is at stake. Understand on the way to an interview in the train, having looked through the book "Programming in PHP / JavaScript for 3 days" - it does not work, well, no way, and no one can write off (even for a box of vodka).

You will not be allowed to "write off" the model of the neural network, even for a box of vodka. Often, it is on your data that the publicly available model works suddenly poorly and you have to understand the terver and matane
')
But, wooo, having mastered the basics, you can build different predictive models that implement interesting and powerful algorithms. And here the tongue starts to wrap up and fall out of the mouth, catching the left eye ...
Even in such a seemingly intuitive and applied to the level of "AK-47" area as the processing of relational data, a large and very well-known company IBM in its time was tortured and, in fact, "squeezed out" the old Codd , the famous creator of for bazok, for walking on all four sides. What happened? Codd argued that the SQL distributed by IBM is evil, it is not strict and not complete and does not correspond to a rigorous and beautiful theory :-) Nevertheless, we still use SQL until now and ... nothing, alive.
Much the same thing is happening now with machine learning. On the one hand on a weekly or even more often, go inspires scientific publications on the subject of sudden victory GiroDrakonov (with physiological balls - gyros) on GiperKashalotami in Turing-spaces in the constellation of the Little Prince, massively appear free prototypes on github and distributions of neural frameworks who understand the meaning of the question by 5% better than previous prototypes - but, in fact, continuing not to understand the essence of the devil . At the same time, by means of the strongest group violence against the neural network and the very idea of training with reinforcements in spaces of enormous dimension, she suddenly begins to play Atari in two-dimensional games and, probably, everyone has already known about the victory of neural networks over Go champions . On the other hand, the business is beginning to realize that the region is still very raw, is in a phase of rapid growth and there are still very few applied, effectively solving the problems of people in cases - although they certainly exist and are simply amazing. Unfortunately, there are much more academic toys: neurons age their faces, generate porn (do not google, lose the potency for a day) and create a buggy layout on the design of web pages .

Or maybe take and invite this girl created by the neural network for a date? Awesome experience, will be remembered for a lifetime.
But real, tremendous success in some areas, such as, for example, pattern recognition, has been achieved at the cost of learning huge convolutional networks of hundreds of layers - that only industry giants can afford: Google, Microsoft ... Similarly, with machine translation: you need large, very large data volumes and large computational power.
A similar situation with recurrent neural networks . Despite their “unprecedented power” and ability to predict chains of events, generate texts similar to the writer's delusions under the influence of hard drugs and other tricks - they learn very, very slowly and you need disproportionate computing resources again.
Language neural models are now more interesting than ever, but many require significant corpus of texts and, again, computational resources, which is especially difficult for the Russian language. And although the matter has moved from the dead point and it is already possible to find embeddings and not only for Russian , it is effective to use them as part of complex language models in production without dragging 1000 kilograms of pyatons and the herd of grunting elephants - it’s not clear how.

Do you think that deploying Hadoop without the help of understanding system administrators is easy? Go better and grunt with this flock :)
Greater, really great , hope is served by generative adversarial networks ( GAN ) that appeared a couple of years ago. Despite their tremendous possibilities: restoring the lost part of the image, increasing the resolution, changing the age of the face, creating the interior, applying bioinformatics and in general, penetrating the essence of the data and generating them according to a certain condition (for example: I want to see many young girls with beautiful priests ): rather, this is the lot of serious research scientists.
Therefore, to rely on the fact that you will be engaged in deeplearning “on the knee” and something from this useful will work out and quickly - not worth it (emphasis on the letter “o”). You need to know a lot and work in the "sweat of your face."
Throwing away the bulky theory and thoroughly sobering up, you can see that there remains a small handful of theoretically useful in e-commerce and CRM algorithms with which you can and should start to work and solve current business problems:

They say that there are “blondes” in the head (this is a collective image, girls don't get offended, there are men like “blondes”), there is no brain, and the two ears are directly connected with a thin thread. If the thread is cut - the ears fall off and fall to the floor
Business managers, meanwhile, have nothing left to do, how to throw mathematics textbooks at developers from morning to night with the words: “well, find the application of these algorithms, for-fan not to offer!” And hire experts who understand scientific publications and capable of, at least in python, writing adequate code.
We were repelled by the fact that, on the one hand, we already have a bigdata that is sufficient to train the neural network (tens of thousands of examples), and on the other, there is a business task to constantly and daily classify the incoming customer calls with questions and suggestions a specific list of topics (dozens) for subsequent routing to responsible employees.
We considered classical and well-known algorithms for, sorry for the tautology, text classifications: Bayesian classifier , logistic regression , support vector machine , but we chose neural networks and here's why:
As a result, we came to such a fairly simple, but, as it turned out, very effective architecture in practice:
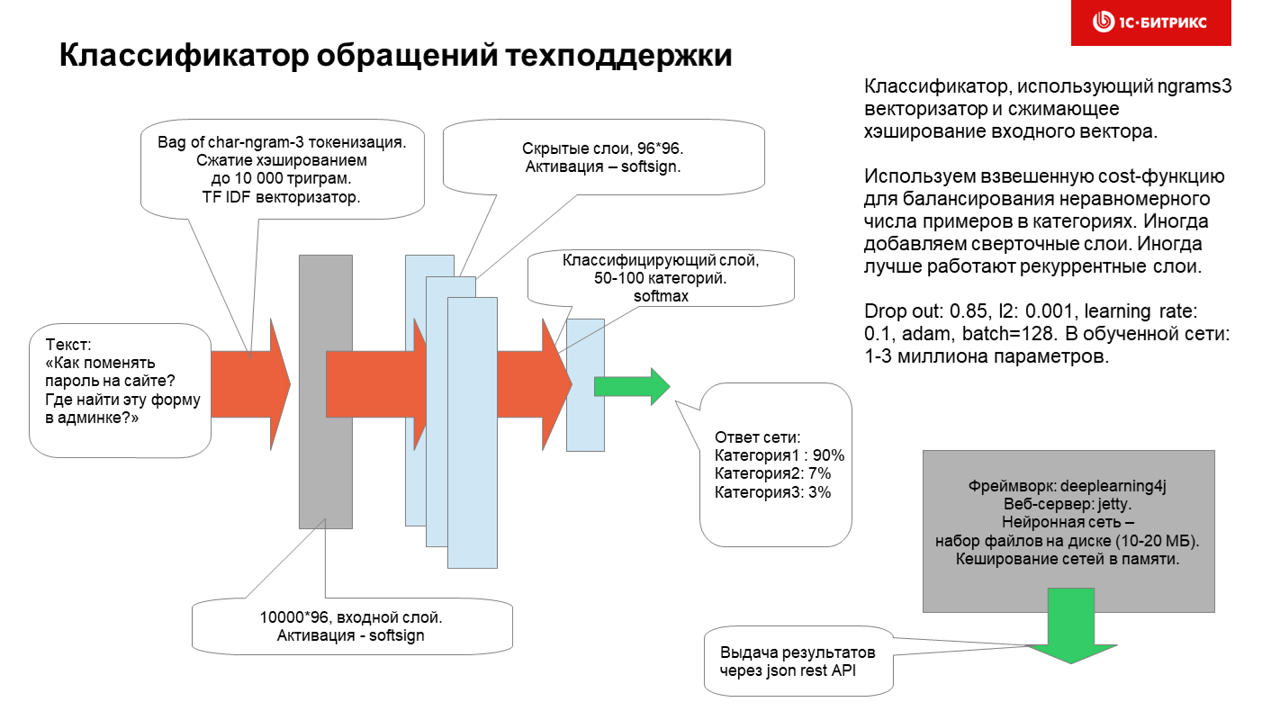
He studies a neural network for an hour and a half (without a GPU, and it is much faster on it) and uses ~ 100k datasets for categories to learn.
The categories are distributed very unevenly, but experiments with assigning weights to teaching examples with poorly represented categories (tens to hundreds of examples for a heading) did not particularly improve the work of the neural network.
Let me remind you that at the entrance of the network, citizens are addressed on a heap of languages, which may contain:
It turned out that the neural network works better if the data are not pre-processed and char3 ngrams of them are made as they are. In this case, typo-resistance works fine, and you can enter a small piece of the file path or a code fragment or one or two words of the text in any language and the heading is quite adequately defined.
Here's how it works from the inside:
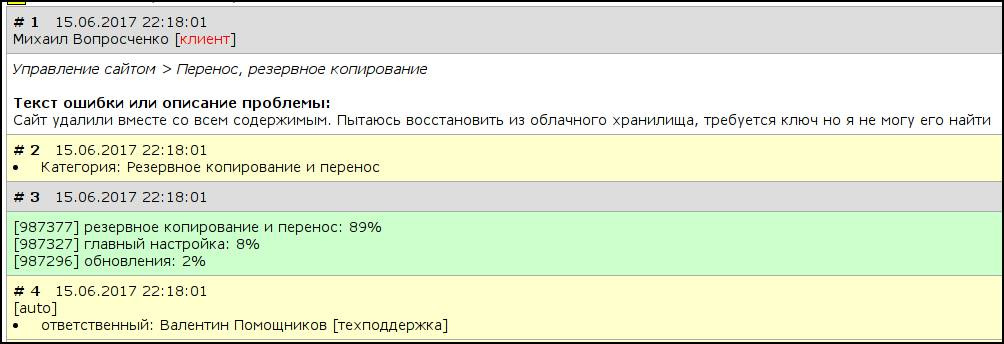
If during the classification the neural network is not sure or makes a mistake - it is insured by the person and the appeal is reassigned manually. While the accuracy of the classification is 85% and it certainly can and should be increased - but even the current decision has reduced quite a lot of man hours, it helps to increase the quality of customer service and is an example that neural networks are not any kind of porn generation toys - they can work alongside people and be very helpful.

In his head, this astrodroid is not a very powerful neural network - but, nevertheless, sometimes making mistakes, it brings a lot of benefit over 6 parts (or already 7) of the movie saga
Now we are experimenting on Keras with other text classifier architectures:
- based on recurrent network
- based on the convolution network
- based on bag-of-words
A multilayer classifier works best with one-hot vector of symbols (from a small dictionary of shell symbols), then several layers of 1D convolution with global-max / average pooling pass and the output is a regular feed-forward layer with softmax. It was not possible to train such a classifier in the end-to-end way, and even batch normalization did not help (it was necessary to look at the girls less and listen to the teacher) - but we managed to train her thoroughly by consistently learning layer by layer. Apparently, when we figure out how to use tensors on Keras / python / Tensorflow in production instead of tensors on java, we will definitely roll out this architecture for battle and will even more please our managers and clients.
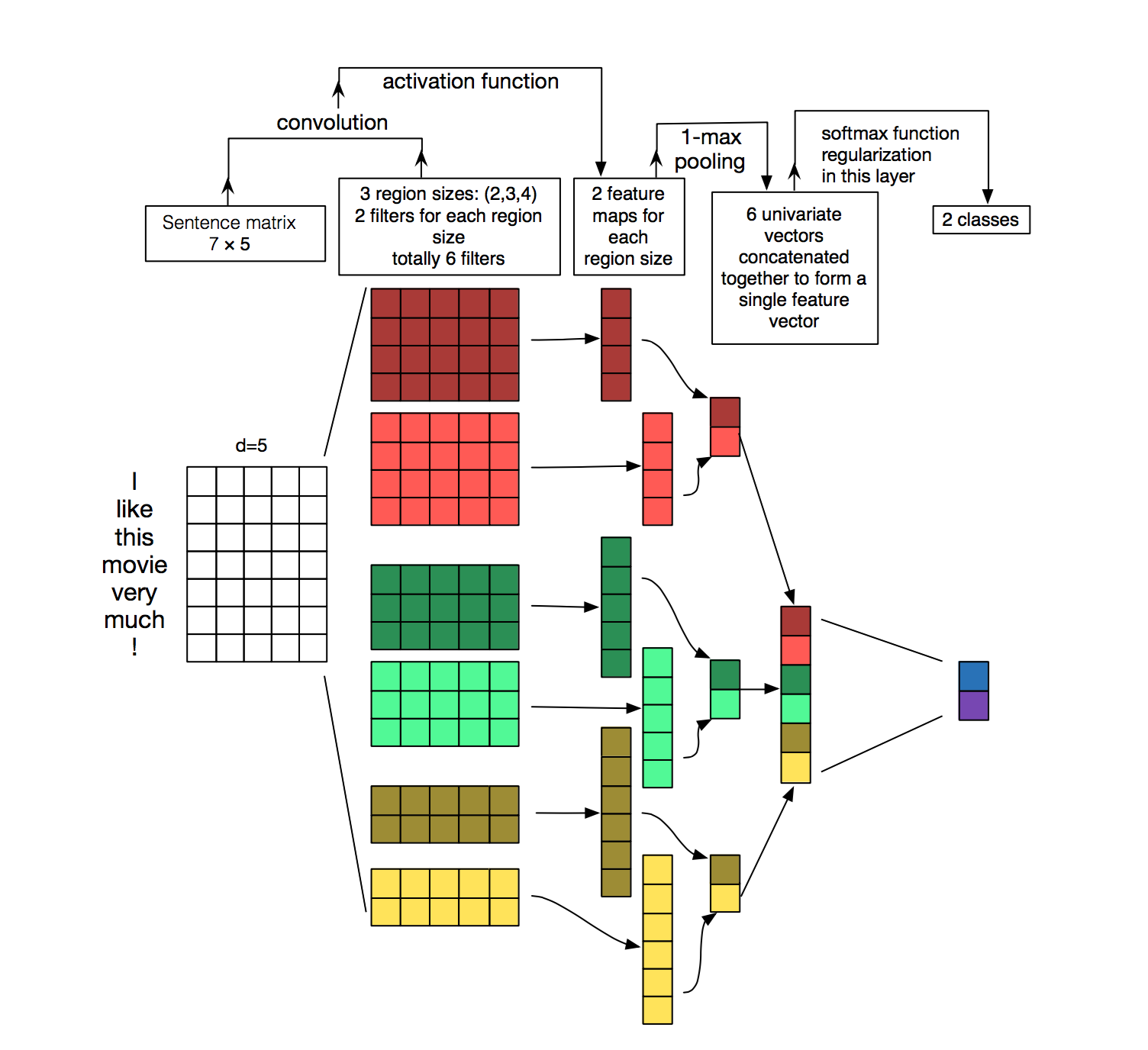
This is not how everyone understands the 1D convolution. We can say that kernels (convolutional kernels) are created that define 1-2-3-n character chains, “ala” multi-nrgams model. In our case, the 1D convolution with window 9 works best.
At the end of the post, dear friends, I wish you not to shuffle before ML and neurons, feel free to take them and use, build and train models and I am sure you will see how AI works effectively, how it helps to remove the routine from people and increase the quality of your services. Good luck to everyone and good and, most importantly, the rapid convergence of neural networks! Kissing you tenderly.
- Iron has become much faster and you can easily cheat on GPU models.
- There was a bunch of good free frameworks for neural networks
- Dazzled by the previous HYIP, the companies began to collect the big data - now there is something to train on!
- Neurons in some areas approached the person, and in some they already surpassed in solving a number of tasks (where they sell shovels, it is urgent to dig a bunker)
But to manage it is still difficult: a lot of mathematics, higher and merciless. And either you are from Fizmat, or sit and solve 2-3 thousand puzzles within two to three years to understand what is at stake. Understand on the way to an interview in the train, having looked through the book "Programming in PHP / JavaScript for 3 days" - it does not work, well, no way, and no one can write off (even for a box of vodka).
You will not be allowed to "write off" the model of the neural network, even for a box of vodka. Often, it is on your data that the publicly available model works suddenly poorly and you have to understand the terver and matane
')
But, wooo, having mastered the basics, you can build different predictive models that implement interesting and powerful algorithms. And here the tongue starts to wrap up and fall out of the mouth, catching the left eye ...
Beauty Theory and Practice
Even in such a seemingly intuitive and applied to the level of "AK-47" area as the processing of relational data, a large and very well-known company IBM in its time was tortured and, in fact, "squeezed out" the old Codd , the famous creator of for bazok, for walking on all four sides. What happened? Codd argued that the SQL distributed by IBM is evil, it is not strict and not complete and does not correspond to a rigorous and beautiful theory :-) Nevertheless, we still use SQL until now and ... nothing, alive.
Much the same thing is happening now with machine learning. On the one hand on a weekly or even more often, go inspires scientific publications on the subject of sudden victory GiroDrakonov (with physiological balls - gyros) on GiperKashalotami in Turing-spaces in the constellation of the Little Prince, massively appear free prototypes on github and distributions of neural frameworks who understand the meaning of the question by 5% better than previous prototypes - but, in fact, continuing not to understand the essence of the devil . At the same time, by means of the strongest group violence against the neural network and the very idea of training with reinforcements in spaces of enormous dimension, she suddenly begins to play Atari in two-dimensional games and, probably, everyone has already known about the victory of neural networks over Go champions . On the other hand, the business is beginning to realize that the region is still very raw, is in a phase of rapid growth and there are still very few applied, effectively solving the problems of people in cases - although they certainly exist and are simply amazing. Unfortunately, there are much more academic toys: neurons age their faces, generate porn (do not google, lose the potency for a day) and create a buggy layout on the design of web pages .
Or maybe take and invite this girl created by the neural network for a date? Awesome experience, will be remembered for a lifetime.
But real, tremendous success in some areas, such as, for example, pattern recognition, has been achieved at the cost of learning huge convolutional networks of hundreds of layers - that only industry giants can afford: Google, Microsoft ... Similarly, with machine translation: you need large, very large data volumes and large computational power.
A similar situation with recurrent neural networks . Despite their “unprecedented power” and ability to predict chains of events, generate texts similar to the writer's delusions under the influence of hard drugs and other tricks - they learn very, very slowly and you need disproportionate computing resources again.
Language neural models are now more interesting than ever, but many require significant corpus of texts and, again, computational resources, which is especially difficult for the Russian language. And although the matter has moved from the dead point and it is already possible to find embeddings and not only for Russian , it is effective to use them as part of complex language models in production without dragging 1000 kilograms of pyatons and the herd of grunting elephants - it’s not clear how.
Do you think that deploying Hadoop without the help of understanding system administrators is easy? Go better and grunt with this flock :)
Greater, really great , hope is served by generative adversarial networks ( GAN ) that appeared a couple of years ago. Despite their tremendous possibilities: restoring the lost part of the image, increasing the resolution, changing the age of the face, creating the interior, applying bioinformatics and in general, penetrating the essence of the data and generating them according to a certain condition (for example: I want to see many young girls with beautiful priests ): rather, this is the lot of serious research scientists.
Therefore, to rely on the fact that you will be engaged in deeplearning “on the knee” and something from this useful will work out and quickly - not worth it (emphasis on the letter “o”). You need to know a lot and work in the "sweat of your face."
Business Cases of ML Algorithms - the bottom line
Throwing away the bulky theory and thoroughly sobering up, you can see that there remains a small handful of theoretically useful in e-commerce and CRM algorithms with which you can and should start to work and solve current business problems:
- Classification of anything into several classes (spam / not spam, buy / not buy, quit / not leave)
- Personalization: what product / service will a person buy, having already bought others?
- Regression of anything in tsiferku: we determine the price of an apartment by its parameters, the price of the car, the potential income of the client according to its characteristics
- Clustering anything in multiple groups
- Business dataset enrichment or pre-training with GAN
- Transfer of one sequence to another: Next Best Offer, customer loyalty cycles, etc.
They say that there are “blondes” in the head (this is a collective image, girls don't get offended, there are men like “blondes”), there is no brain, and the two ears are directly connected with a thin thread. If the thread is cut - the ears fall off and fall to the floor
Business managers, meanwhile, have nothing left to do, how to throw mathematics textbooks at developers from morning to night with the words: “well, find the application of these algorithms, for-fan not to offer!” And hire experts who understand scientific publications and capable of, at least in python, writing adequate code.
How do we use neural networks in technical support and why?
We were repelled by the fact that, on the one hand, we already have a bigdata that is sufficient to train the neural network (tens of thousands of examples), and on the other, there is a business task to constantly and daily classify the incoming customer calls with questions and suggestions a specific list of topics (dozens) for subsequent routing to responsible employees.
The choice of algorithm, why neurons
We considered classical and well-known algorithms for, sorry for the tautology, text classifications: Bayesian classifier , logistic regression , support vector machine , but we chose neural networks and here's why:
- Due to the factorization of layers and nonlinearity, they are able to approximate much more complex patterns with fewer layers than flat-wide models.
- Neural networks, with a sufficient number of training examples, work better with new data “by design” ( generalization is better)
- Neural networks can work better than classical models and even better than models that pre-parse texts and isolate from them the semantic relations between words and sentences.
- If you use a regularization similar to the effect of alcohol in the human brain ( dropout ), then neural networks adequately converge and do not suffer much from retraining
As a result, we came to such a fairly simple, but, as it turned out, very effective architecture in practice:
He studies a neural network for an hour and a half (without a GPU, and it is much faster on it) and uses ~ 100k datasets for categories to learn.
The categories are distributed very unevenly, but experiments with assigning weights to teaching examples with poorly represented categories (tens to hundreds of examples for a heading) did not particularly improve the work of the neural network.
Let me remind you that at the entrance of the network, citizens are addressed on a heap of languages, which may contain:
- PHP code
- layout
- mat remat slang
- problem description, tasks, ideas
- links to files inside the product
It turned out that the neural network works better if the data are not pre-processed and char3 ngrams of them are made as they are. In this case, typo-resistance works fine, and you can enter a small piece of the file path or a code fragment or one or two words of the text in any language and the heading is quite adequately defined.
Here's how it works from the inside:
If during the classification the neural network is not sure or makes a mistake - it is insured by the person and the appeal is reassigned manually. While the accuracy of the classification is 85% and it certainly can and should be increased - but even the current decision has reduced quite a lot of man hours, it helps to increase the quality of customer service and is an example that neural networks are not any kind of porn generation toys - they can work alongside people and be very helpful.
In his head, this astrodroid is not a very powerful neural network - but, nevertheless, sometimes making mistakes, it brings a lot of benefit over 6 parts (or already 7) of the movie saga
Future plans
Now we are experimenting on Keras with other text classifier architectures:
- based on recurrent network
- based on the convolution network
- based on bag-of-words
A multilayer classifier works best with one-hot vector of symbols (from a small dictionary of shell symbols), then several layers of 1D convolution with global-max / average pooling pass and the output is a regular feed-forward layer with softmax. It was not possible to train such a classifier in the end-to-end way, and even batch normalization did not help (it was necessary to look at the girls less and listen to the teacher) - but we managed to train her thoroughly by consistently learning layer by layer. Apparently, when we figure out how to use tensors on Keras / python / Tensorflow in production instead of tensors on java, we will definitely roll out this architecture for battle and will even more please our managers and clients.
This is not how everyone understands the 1D convolution. We can say that kernels (convolutional kernels) are created that define 1-2-3-n character chains, “ala” multi-nrgams model. In our case, the 1D convolution with window 9 works best.
At the end of the post, dear friends, I wish you not to shuffle before ML and neurons, feel free to take them and use, build and train models and I am sure you will see how AI works effectively, how it helps to remove the routine from people and increase the quality of your services. Good luck to everyone and good and, most importantly, the rapid convergence of neural networks! Kissing you tenderly.
Source: https://habr.com/ru/post/331304/
All Articles