Our experience with Kubernetes in small projects (review and video report)

On June 6, at the RootConf 2017 conference, which was held as part of the Russian Internet Technologies Festival (RIT ++ 2017), a report titled “Our Experience with Kubernetes in Small Projects” was presented in the section “Continuous Deployment and Deploy”. It described the device, the principles of operation and the main features of Kubernetes, as well as our practice of using this system in small projects.
By tradition, we are pleased to present a video with the report (about an hour, much more informative than the article) and the main squeeze in text form.
')
Prehistory
Modern infrastructure (for web applications) has come a long way of evolving from a backend from a DBMS on one server to a significant increase in services used, their separation across virtual machines / servers, switching to cloud solutions with load balancing and horizontal scalability ... and to microservices.
With the operation of modern, microservice , infrastructure, there are a number of difficulties caused by the architecture itself and the number of its components. We distinguish the following from them:
- collecting logs;
- metrics collection;
- supervision (check the status of services and restart them in case of problems);
- service discovery (automatic discovery of services);
- Automation of updating configurations of infrastructure components (when adding / deleting new service entities);
- scaling;
- CI / CD (Continuous Integration and Continuous Delivery);
- vendor lock-in (this is about dependence on the chosen “solution provider”: the cloud provider, bare metal ...).
As it is easy to guess from the title of the report, the Kubernetes system appeared as an answer to these needs.
Kubernetes Basics
The Kubernetes architecture as a whole looks like a master (maybe not one) and many nodes (up to 5000), each of which has:
- Docker,
- kubelet (run by docker),
- kube-proxy (manages iptables).
On master are:
- API server
- etcd database
- scheduler (decides on which node to run the container on)
- controller-manager (responsible for fault tolerance).
In addition to all this, there is a kubectl management utility and configurations described in YAML (declarative DSL) format.

In terms of use, Kubernetes offers a cloud that combines all these master and nodes and allows you to run the "building blocks" of the infrastructure. These primitives, including, include:
- container - image + command launched in it;
- under (Pod; literally translated as “pod”) - a set of containers (maybe one) with a common network, one IP-address and other common characteristics (common data stores, labels); note: it is the platforms (rather than individual containers) that allow you to run Kubernetes;
- Label and selector (Label, Selector) - a set of arbitrary key-values assigned to the subs and other Kubernetes primitives;
- ReplicaSet - a set of pods, the number of which is automatically maintained (when the number of pods in the configuration changes, when any pods / nodes fall), which makes scaling very simple;
- Deploy - ReplicaSet + history of old versions ReplicaSet + update process between versions (used to solve problems of continuous integration - deployment);
- Service ( DNS) name + virtual IP + selector + load balancer (for scattering requests by subkey matching the selector);
- task (Job) - under and the logic of the success of performing the flow (used for migrations);
- cron-task (CronJob) - Job and schedule in crontab format;
- volume (Volume) - connection of data storage (to store, ReplicaSet or Deployment) with indication of size, access type (ReadWrite Once, ReadOnly Many, ReadWrite Many), storage type (19 methods of implementation are supported: iron, software, cloud);
- StatefulSet - a lot of pods like ReplicaSet, but with tightly defined names / hosts, so that these pods can always communicate with each other over them (for ReplicaSet, names are randomly generated each time) and have separate volumes (not one at all, as in the case of ReplicaSet) ;
- Ingress is a service that is accessible to users from outside and scatters all requests for services according to the rules (depending on the host name and / or URLs).
Examples of the description of the presentation and ReplicaSet in YAML format:
apiVersion: v1 kind: Pod metadata: name: manual-bash spec: containers: - name: bash image: ubuntu:16.04 command: bash args: [-c, "while true; do sleep 1; date; done"] apiVersion: extensions/v1beta1 kind: ReplicaSet metadata: name: backend spec: replicas: 3 selector: matchLabels: tier: backend template: metadata: labels: tier: backend spec: containers: - name: fpm image: myregistry.local/backend:0.15.7 command: php-fpm These primitives respond to all of the above calls with a few exceptions: automating configuration updates does not solve the problem of building Docker images, ordering new servers and installing nodes on them, while in CI / CD there is still a need for preparatory work (installing CI, describing assembly rules Docker images, rolling out YAML configurations in Kubernetes).
Our experience: architecture and CI / CD
By small projects we mean small (up to 50 knots, up to 1500 pods) and medium ones (up to 500 knots, up to 15000 pods). We make the smallest projects on bare metal with three hypervisors, which look like this:
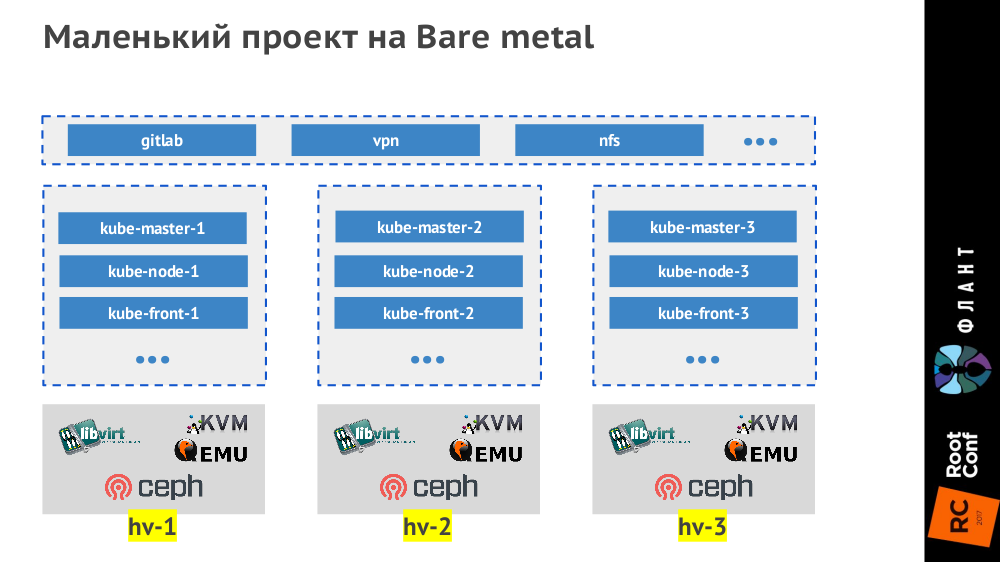
The Ingress controller is
kube-front-X on three virtual machines ( kube-front-X ):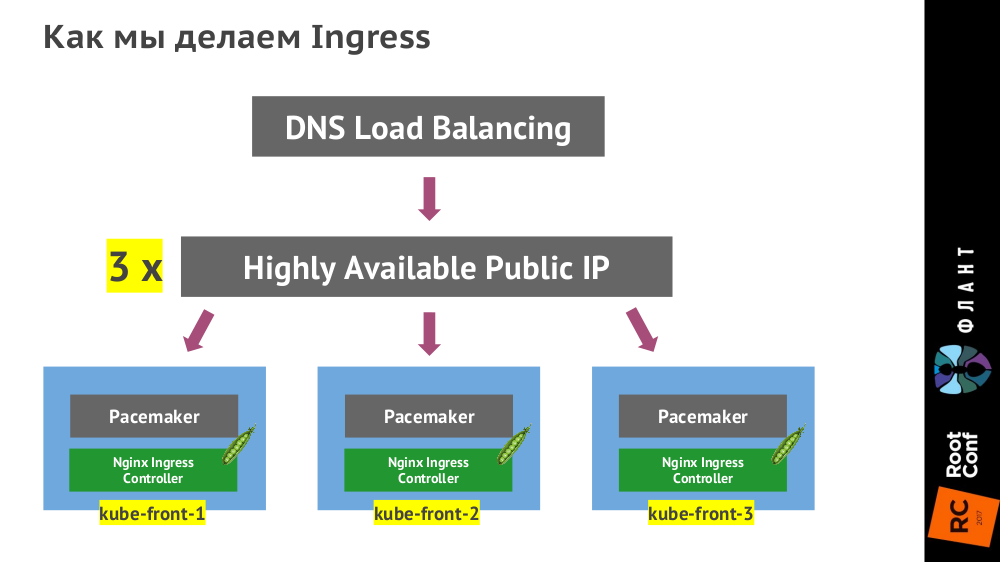
(Instead of the Pacemaker specified in the diagram, there may be VRRP, ucarp or another technology - it depends on the specific data center.)
How the Continuous Delivery Chain Looks:
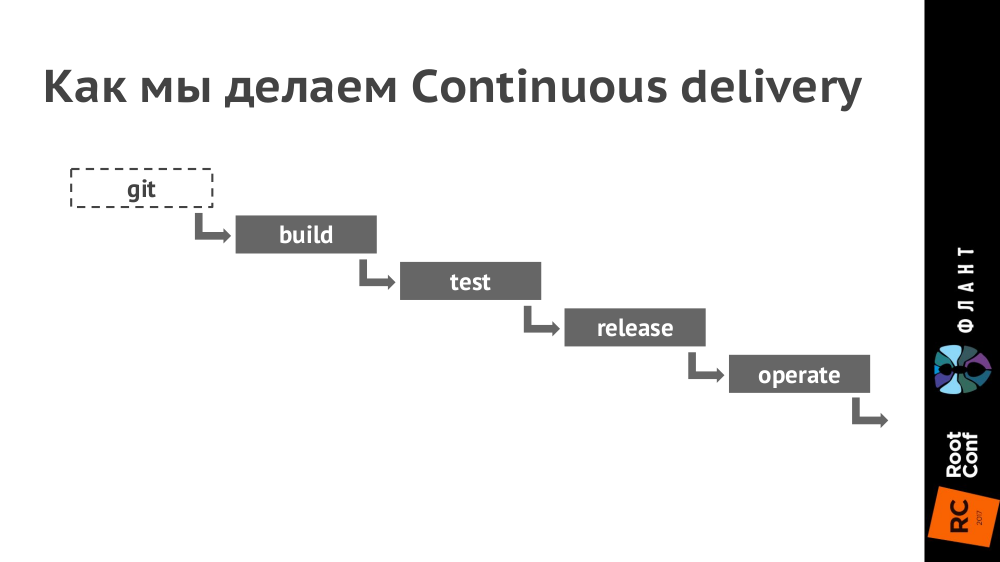
Explanations:
- For continuous integration we use GitLab (in the coming weeks we will publish an article with details on the practice of its use). Updated (July 11, 2017) : its first part is published as “ GitLab CI for continuous integration and delivery in production. Part 1: our pipeline .
- In Kubernetes we set up environments for each circuit (production, staging, testing, etc. - their number depends on the specific project). In this case, different contours can be serviced by different clusters of Kubernetes (on different hardware and in different clouds), and in GitLab it is configured to be deployed to them.
- In Git we put the Dockerfile (or rather, we use dapp for this) and the .kube directory with the YAML configurations.
- With a commit ( build stage), we create an image of the Docker, which is sent to the Docker Registry.
- Next ( test stage) we take this Docker image and run tests on it.
- With the release (release stage) of the YAML configuration from the .kube directory, we give it to the kubectl utility, which sends them to Kubernetes, after which the Docker images are downloaded and run in the infrastructure deployed in the configuration from YAML. (We used to use Helm for this, but now we finish our dapp tool.)
- Thus, Kubernetes is fully responsible for the last stage ( operate ).

In the case of small projects, the infrastructure looks like a container cloud (its implementation is secondary — it depends on hardware and needs) with configured storage (Ceph, AWS, GCE ...) and the Ingress controller, and (in addition to this cloud) additional virtual machines may be available to start services that we do not put inside Kubernetes:

Conclusion
From our point of view, Kubernetes has matured in order to use it in projects of any size. Moreover, this system provides an excellent opportunity from the very beginning to make a project very simple, reliable, with fault tolerance and horizontal scaling. The main underwater stone is the human factor: for a small team it is difficult to find a specialist who will solve all the necessary tasks (requires extensive technological knowledge), or he will be too expensive (and soon he will become bored).
Video and slides
Video from the performance (about an hour) published on YouTube .
Presentation of the report:
Continuation
Having received the first feedback on this report, we decided to prepare a special cycle of introductory articles on Kubernetes , focused on developers and telling in more detail about the structure of this system. Let's start in the coming weeks - stay tuned to our blog!
PS
Read also in our blog about CI / CD and not only:
- " Infrastructure with Kubernetes as an affordable service ";
- “ We assemble Docker images for CI / CD quickly and conveniently along with dapp ” (Dmitry Stolyarov; November 8, 2016 on HighLoad ++) ;
- “ Practices of Continuous Delivery with Docker ” (Dmitry Stolyarov; May 31, 2016 at RootConf) .
Source: https://habr.com/ru/post/331188/
All Articles