Fear and Loathing in MiddleWare
We were close to javascript when we beat php. I remember saying something like: Something is spinning in my head. Maybe you better lead the project.

Suddenly, there was a terrible boom around us ... And the whole WEB was teeming with these articles about LAMP ...
It seemed that they were written for any needs. They grew and absorbed tasks for which previously used perl, bash and even C. There is no sense in talking about these articles, I thought. Everybody knows it.
')
We had a fifth IE, some Netscape, Opera, and a whole sea of disparate cgi modules on perl. Not that it was a necessary technology stack. But if you started collecting crap, it becomes difficult to stop. The only thing that caused me fear was a student using PHP . There is nothing more helpless, irresponsible and spoiled than that. I knew that sooner or later we will move on to this rubbish.
In the beginning
Once JS between browsers differed as a horse from a traffic jam, and XMLHttpRequest was possible only through ActiveX. There was no way out. That the dynamic web has been cut down. IE 6 seemed to be a revolution. But if you wanted cross-platform - your path ran through the volumetric MiddleWare. A large number of articles on php, tools and related new libraries did their job.
Damn php, you begin to behave like a country drunk from old Irish novels, a complete loss of basic motor functions, blurred vision, a wooden tongue, a brain in horror. An interesting condition when you see everything, but can not control anything. You come to the task, clearly knowing where the data is, where the logic is and where the presentation is. But on the spot everything goes wrong. You are confused by an evil noodles code, and you think: what's the matter, what's going on? ...
Gradually, the titanic plates between browsers began to converge. Everywhere XMLHttpRequest appeared and dreams of a dynamic WEB with a clear division across fronts became a reality.
Of course, I fell victim to the craze. An ordinary street slacker, who studied everything that fell under the arm. Ideas about a common language for web development were in the air. Wait, you see these changes in a new guise, man.
- Let's see Node.js.
- What? Not!
- You can not stop here. This is a fat middle.
- Sit down.
What kind of nonsense they rod, I do not know how much you need to write in JavaScript to find similarities between Front, Middle and BackEnd? This is the wrong option. Too fat for the chosen target.
But, I left such thoughts. It has been realized that a nail can be hammered with a screwdriver, but if you sometimes reach the hammer, the process will seriously accelerate.
I felt a monstrous protest against the whole situation.
There are also DBMS, such as PostgreSQL, which allow incredibly to operate with data through embedded functions. Business logic inside the base! Real BackEnd. Do not like the business logic in the database and it does not belong there? And such direct data streams like?

Let's try to figure out the thorny movement of data on the "direct" flows of the smoker.
The first thing we encounter is a constant data distillation in the middle, for any reason. In addition, this data may not be completely final and only be required for the calculation of subsequent requests. For data processing cycles are used. Procedural loops are not optimized for multithreading.
The multiplicity of requests in one session to the DBMS leads to the inevitable apotheosis of the demise of speed - multipass through the database tables.

To eliminate these factors, the logic has to be transferred closer to the data, i.e. in the DBMS!
And this is the most optimal way to bring the speed to new values!
Over time, browsers have learned the full dynamic generation of the interface. Achivka clear separation of data fronts and presentation. There was a full-fledged opportunity to drive mainly data from server to client. There was only one question: What to do with the middle layer? How to minimize it exclusively to the transport function with elements of simple routing of requests for server-side collections.
These naive developers believed that one could gain spiritual peace and understanding by studying one of the strongholds of the old Middle, and the result was the generation of a thick layer, who did not understand the main mistake of the IT industry as old as the world. Overlooking the belief that Someone or Something may have a fatal flaw .
By that time, nginx began to work, and there were no questions left with what to prepare the proposed idea. It was no longer an idea. Now it was a programmer contest with laziness. The idea itself, to try to somehow describe the architecture in the traditional way, through apache, seemed absurd.
In 2010, the ngx_postgres module arrived on github. Setting requests in the configuration file and issuing in JSON / CSV / SOMETHING.
Simple SQL code was enough for configuration. Complicated it was possible to wrap in a function that was then called from the config.
But this module could not load the http request body into the DBMS. That imposes serious restrictions on the data sent to the server. The URL is clearly only suitable for filtering the request.
The serialization of the output data was carried out by means of the module itself. That, from the height of my couch, seemed to be a meaningless translation of RAM - PostgreSQL was able to serialize.
There was a thought to correct, rewrite. I began to dig in the code of this module.
After a sleepless night of searching for many, ngx_postgres would suffice. We needed something stronger.
Madam, sir, baby, or whatever ... there is an option, here, hold ngx_pgcopy .

After the experiment, experiments and analysis of analyzes, the idea arose to rewrite everything practical from scratch. To speed up the loading, COPY queries were selected, which translate the data into the database an order of magnitude faster than the inserts and contain their own parser. Unfortunately, due to the paucity of describing this type of query, it is difficult to say how the DBMS will conduct with particularly massive calls to this method.
The world is mad in any direction and at any time, you come across it constantly. But there was an amazing, universal sense of the correctness of all that we did.
Together with COPY-requests, we automatically received serialization in CSV in both directions, which eliminated the need for data conversion concerns.
Let's start with a primitive, sending and receiving the entire table in CSV by URL:
CSV part import.export.nginx.conf

Currently PostgreSQL cannot in JSON and XML via COPY STDIN. I hope that the day of humility with the tabs in the code-style of the elephant will come, and I, or one thread, will find time and fasten this functionality to COPY methods. Moreover, in the DBMS processing of these formats is already present.
But! Method of application here and now is still there! We configure nginx to client_body_in_file_only on with subsequent use of the $ request_body_file variable in the request and passing it to the pg_read_binary_file function ...
Of course, this will have to be wrapped in the COPY method, since Will work only with my moped, due to the full body_rejecta of ngx_postgres. I have not yet met other mopeds, and ngx_pgcopy has not yet matured for additional functionality.
Consider how it looks for json / xml in import.export.nginx.conf
Yes, client_body_temp_path will have to be put in the base directory, and the user will be given ALTER SUPERUSER. Otherwise, Postgres will send our desires beyond the horizon.
The export presented in the GET methods uses the built-in functions included in the standard Postgres delivery. All COPYs are output to STDOUT, in case we want to notify the client about the results of these actions. Import to a fixed table (simple_data) looks a bit more bulky than export, therefore it is in the user-defined DBMS procedure.
Part of 1.import.export.sql for importing into a fixed table
The import function with a flexible table selection for JSON is not much different from the one above. But such flexibility for XML generates a more monstrous division.
In the examples given, the name table_name in the imported file does not affect the target destination table specified in nginx. The use of the xml hierarchy of the document table_name / rows / cols is due exclusively to symmetry with the built-in table_to_xml function.
The data sets themselves ...
We have drifted away here, so let's return to the sources of pure COPY ...
Okay. This is probably the only way. Just let's make sure I understood everything correctly. Do you want to send data between the server and the client without processing filling it into a table?

I think I caught fear.
Nonsense. We came to find MidleWare dream.
And now, when we are right in her whirlwind, do you want to leave?
You have to understand, man, we found the main nerve.
Yes, it's almost like that! This is a rejection of CRUD.
Of course, many will be indignant as some type in a couple of sentences crosses out the results of the work of the California minds, styling a short little article for the dialogues of a drug-addicted film. However, all is not lost. There is an option to transfer the data modifier along with the data itself. That still leads away from the usual RESTful architecture.
In addition, sometimes, and when and more often, theoretical studies are broken on the rocks of reality. Such rocks are still the same unfortunate multipass. In fact, if you allow a change in a number of positions of a user document, then it is likely that these changes will include several types of methods. As a result, to send a single document to the database, you will need to conduct several separate http requests. And each http request will generate its own modification of the database and its passage through the tables. Therefore, a qualitative breakthrough requires fundamental changes to abandon the classical understanding of CRUD methods. Progress requires sacrifice.
Here I had suspicions that a more interesting solution could be found. You just need to experiment and think a bit ...
By the time I asked this question,
No one who could answer him was not there yet.
Yes, yes, I'm starting again ...
We send data to the middle layer, which sends it to the database without processing.
The DBMS parses them and puts them in a table that performs the role of a log / log. Registration of all input data.
The key point, here it is! Journaling / logging data flow out of the box! And then it's up to triggers. In them, on the basis of the business logic, we decide: to update, add or do something else. Screwing the data modifier is optional, but can be a nice bonus.
This leads us to the adequacy of using HTTP methods GET and PUT. Let's try to model how to apply it. To begin with we will be defined with a difference between magazines and a broad gull. We distinguish the key difference through the priority between the value of the route of change and the final value. The first criterion belongs to the logs, the second - to the logs.
Despite the priority of the final goal in the logs, the route is still necessary. Which leads us to the separation of such tables into two parts: the result and the journal itself.
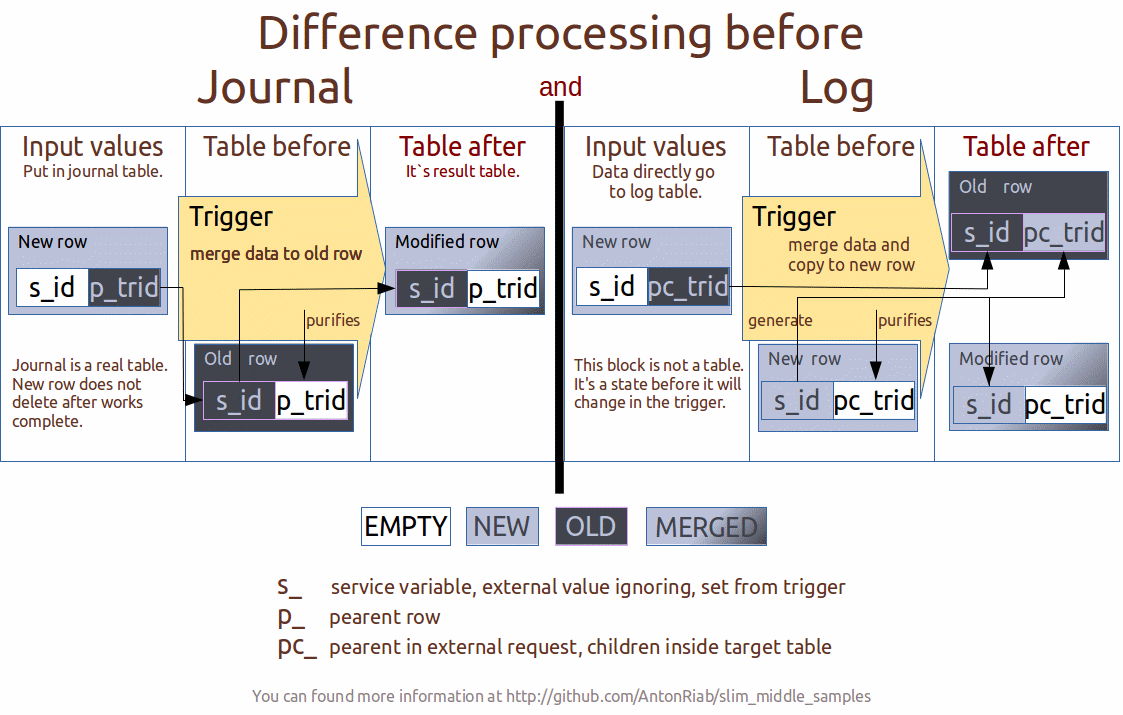
What is it possible to pull? Logs: the route of the car, the movement of material values, etc. Logs: stock balance, last comment, and other recent instantaneous data states.
Code from 2.jrl.log.sql:
The given examples do not know how to clean the cells, because for this you need to fasten utility values. And they are highly dependent on the method of import. In some cases, it can be any type with completely arbitrary content. In others, only the type of the target column with a probable sign to exit the range.
Triggers are called in the order of text sorting by name. I recommend using trg_N_ prefixes. From trg_0 to trg_4 to be considered as service ones, serving only the integrity of the common logic and incoming filtering. And from 5 to 9 use for applied calculations. Nine triggers will be enough for everyone !
It is also worth saying that they need to be installed on BEFORE INSERT. As in the case of AFTER, the NEW service variable will be put in the table before it is modified by the trigger. In principle, if integrity is not critical to some extent, such a solution can be a good accelerator for user requests passing through the log. This will not affect the values of the resulting table.
Also, with AFTER, we will not be able to return an error if the user does not have permission to change. But the correct FrondEnd and should not carry out operations prohibited by the server. Accordingly, such behavior is more likely characteristic of hacking, which will be peacefully recorded in the journal.

Routing URLs using standard nginx tools. In the same way we filter the request from injections. After doubling the problem, the code similar to the result of asymmetric encryption is pushed into the directive map nginx.conf to get a digestible and secure SQL query. Which, further, we filter the data.
There are some difficulties. They are caused by the lack of regularization in nginx for multiple replacements like sed s / bad / good / g . As a result, we ...
We fall right into the thick of this fucking terrarium. And after all, someone has the mind to write these damn expressions! A little more and they will tear the brain to shreds.
up to 4 equivalency filters by URL
Horrowshow part of filters.nginx.conf
With Cyrillic filtering in the URL, via the nginx config, all is not smooth either - we need native conversion from one variable from base64 to another, with human-readable text. At the moment, there is no such directive. Which is quite strange, because in the source code for nginx, transcoding functions are present.
As a thread, I will definitely gather my thoughts and liquidate this omission, as well as the problem with sed, if the nginx inc team does not solve this.
It would be possible to give the url a string with arguments in the DBMS, for the internal generation of a dynamic query in a direct function call or a call through the table log trigger. But since such data is already logged in nginx-access.log, these initiatives are redundant. And given the fact that such actions can increase the load on the base scheduler, they are also harmful.
Sm
- Modules for nginx have been successfully written for a long time. Why fanfare?
Most of the existing analogues are highly specialized solutions. The article presents a reasonable compromise of speed and flexibility!
- Work through the disk (client_body_in_file_only) - slowly!
Yes, RAM Drive will come with you and its prophet is the file system cache.
- What about user rights?
Login with plain http is forwarded to postgres. There you solve with built-in tools. In general, a full BackEnd.
- What about encryption?
Module ssl through nginx config. At the current stage, it may not take off due to the ngx_pgcopy code dampness.
Connecting nginx with postgres, when paging servers, paranoids can be thrown through ssh.
- Fuck JS symbols in the reflection of the points at the beginning? Where is javascript?
JS goes to FrontEnd. And this is a completely different movie.
- Is there life on the client with JS disabled?
As you may have noticed earlier, in the examples, Postgres may be in xml. Those. getting output HTML is no problem. Both with the use of spaghetti code, and through the xsl scheme.
It's horrible. However, everything will be fine. You do everything right.
- How to resize images, pack archivists and read the path of leptons on the GPU?

And so that is easier.
Maybe I'd better chat with this guy, I thought.
Do not come to FastCGI!
They are just waiting for this from us.
Lure us into this box
Let go to the basement. There.
We say ngix client_body_in_file_only on , take in the armful $ request_body_file and plperlu, with access to the command line. And adapt that thread from:
- It looks like a CGI. And CGI is not safe!
Security depends more on your literacy than on the technology used. Yes. After screwing in environment variables, this is compatible with CGI. Moreover, it can be used for a smooth transition from CGI with minimal restructuring of scripts. Accordingly, the method is suitable for evacuating most PHP solutions.
You can also dream up about distributed computing (thanks to clustering PostgreSQL) and the freedom to choose approaches to asynchrony. But to do this, I certainly will not.
→ ngx_pgcopy
→ PostgreSQL COPY request
→ slim_middle_samples ( examples from article + build demo)
The module is still in development, so stability problems are possible. In view of the keep alive connection that I had not yet realized towards the backend, this creature, for the time being, is still valid for the role of a supersonic fighter. Module README to you in reading.
Ps. In fact, CRUD is implemented without any problems through stored procedures, or the log for a method is not applicable to logs. I also forgot to add the DELETE method to the module.
The article used frames and quotes from the movie “Fear and Loathing in Las Vegas” 1998. The materials are used exclusively for non-commercial purposes and as part of the promotion of cultural, educational and scientific development of society.
Suddenly, there was a terrible boom around us ... And the whole WEB was teeming with these articles about LAMP ...
It seemed that they were written for any needs. They grew and absorbed tasks for which previously used perl, bash and even C. There is no sense in talking about these articles, I thought. Everybody knows it.
')
We had a fifth IE, some Netscape, Opera, and a whole sea of disparate cgi modules on perl. Not that it was a necessary technology stack. But if you started collecting crap, it becomes difficult to stop. The only thing that caused me fear was a student using PHP . There is nothing more helpless, irresponsible and spoiled than that. I knew that sooner or later we will move on to this rubbish.
In the beginning it was not
Once JS between browsers differed as a horse from a traffic jam, and XMLHttpRequest was possible only through ActiveX. There was no way out. That the dynamic web has been cut down. IE 6 seemed to be a revolution. But if you wanted cross-platform - your path ran through the volumetric MiddleWare. A large number of articles on php, tools and related new libraries did their job.
Damn php, you begin to behave like a country drunk from old Irish novels, a complete loss of basic motor functions, blurred vision, a wooden tongue, a brain in horror. An interesting condition when you see everything, but can not control anything. You come to the task, clearly knowing where the data is, where the logic is and where the presentation is. But on the spot everything goes wrong. You are confused by an evil noodles code, and you think: what's the matter, what's going on? ...
Gradually, the titanic plates between browsers began to converge. Everywhere XMLHttpRequest appeared and dreams of a dynamic WEB with a clear division across fronts became a reality.
Of course, I fell victim to the craze. An ordinary street slacker, who studied everything that fell under the arm. Ideas about a common language for web development were in the air. Wait, you see these changes in a new guise, man.
- Let's see Node.js.
- What? Not!
- You can not stop here. This is a fat middle.
- Sit down.
What kind of nonsense they rod, I do not know how much you need to write in JavaScript to find similarities between Front, Middle and BackEnd? This is the wrong option. Too fat for the chosen target.
But, I left such thoughts. It has been realized that a nail can be hammered with a screwdriver, but if you sometimes reach the hammer, the process will seriously accelerate.
I felt a monstrous protest against the whole situation.
There are also DBMS, such as PostgreSQL, which allow incredibly to operate with data through embedded functions. Business logic inside the base! Real BackEnd. Do not like the business logic in the database and it does not belong there? And such direct data streams like?
Let's try to figure out the thorny movement of data on the "direct" flows of the smoker.
The first thing we encounter is a constant data distillation in the middle, for any reason. In addition, this data may not be completely final and only be required for the calculation of subsequent requests. For data processing cycles are used. Procedural loops are not optimized for multithreading.
The multiplicity of requests in one session to the DBMS leads to the inevitable apotheosis of the demise of speed - multipass through the database tables.
To eliminate these factors, the logic has to be transferred closer to the data, i.e. in the DBMS!
And this is the most optimal way to bring the speed to new values!
Becoming an idea
Over time, browsers have learned the full dynamic generation of the interface. Achivka clear separation of data fronts and presentation. There was a full-fledged opportunity to drive mainly data from server to client. There was only one question: What to do with the middle layer? How to minimize it exclusively to the transport function with elements of simple routing of requests for server-side collections.
These naive developers believed that one could gain spiritual peace and understanding by studying one of the strongholds of the old Middle, and the result was the generation of a thick layer, who did not understand the main mistake of the IT industry as old as the world. Overlooking the belief that Someone or Something may have a fatal flaw .
By that time, nginx began to work, and there were no questions left with what to prepare the proposed idea. It was no longer an idea. Now it was a programmer contest with laziness. The idea itself, to try to somehow describe the architecture in the traditional way, through apache, seemed absurd.
In 2010, the ngx_postgres module arrived on github. Setting requests in the configuration file and issuing in JSON / CSV / SOMETHING.
Simple SQL code was enough for configuration. Complicated it was possible to wrap in a function that was then called from the config.
But this module could not load the http request body into the DBMS. That imposes serious restrictions on the data sent to the server. The URL is clearly only suitable for filtering the request.
The serialization of the output data was carried out by means of the module itself. That, from the height of my couch, seemed to be a meaningless translation of RAM - PostgreSQL was able to serialize.
There was a thought to correct, rewrite. I began to dig in the code of this module.
After a sleepless night of searching for many, ngx_postgres would suffice. We needed something stronger.
Madam, sir, baby, or whatever ... there is an option, here, hold ngx_pgcopy .
NGX_PGCOPY
After the experiment, experiments and analysis of analyzes, the idea arose to rewrite everything practical from scratch. To speed up the loading, COPY queries were selected, which translate the data into the database an order of magnitude faster than the inserts and contain their own parser. Unfortunately, due to the paucity of describing this type of query, it is difficult to say how the DBMS will conduct with particularly massive calls to this method.
The world is mad in any direction and at any time, you come across it constantly. But there was an amazing, universal sense of the correctness of all that we did.
Together with COPY-requests, we automatically received serialization in CSV in both directions, which eliminated the need for data conversion concerns.
Let's start with a primitive, sending and receiving the entire table in CSV by URL:
http://some.server/csv/some_tableCSV part import.export.nginx.conf
pgcopy_server db_pub "host=127.0.0.1 dbname=testdb user=testuser password=123"; location ~/csv/(?<table>[0-9A-Za-z_]+) { pgcopy_query PUT db_pub "COPY $table FROM STDIN WITH DELIMITER as ';' null as '';"; pgcopy_query GET db_pub "COPY $table TO STDOUT WITH DELIMITER ';';"; } Currently PostgreSQL cannot in JSON and XML via COPY STDIN. I hope that the day of humility with the tabs in the code-style of the elephant will come, and I, or one thread, will find time and fasten this functionality to COPY methods. Moreover, in the DBMS processing of these formats is already present.
But! Method of application here and now is still there! We configure nginx to client_body_in_file_only on with subsequent use of the $ request_body_file variable in the request and passing it to the pg_read_binary_file function ...
Of course, this will have to be wrapped in the COPY method, since Will work only with my moped, due to the full body_rejecta of ngx_postgres. I have not yet met other mopeds, and ngx_pgcopy has not yet matured for additional functionality.
Consider how it looks for json / xml in import.export.nginx.conf
client_body_in_file_only on; client_body_temp_path /var/lib/postgresql/9.6/main/import; location ~/json/(?<table>[0-9A-Za-z_]+) { pgcopy_query PUT db_pub "COPY (SELECT * FROM import_json_to_simple_data('$request_body_file')) TO STDOUT;"; pgcopy_query GET db_pub "COPY (SELECT '['||array_to_string(array_agg(row_to_json(simple_data)), ',')||']' FROM simple_data) TO STDOUT;"; } location ~/xml/(?<table>[0-9A-Za-z_]+) { pgcopy_query PUT db_pub "COPY (SELECT import_xml_to_simple_data('$request_body_file') TO STDOUT;"; pgcopy_query GET db_pub "COPY (SELECT table_to_xml('$table', false, false, '')) TO STDOUT;"; } Yes, client_body_temp_path will have to be put in the base directory, and the user will be given ALTER SUPERUSER. Otherwise, Postgres will send our desires beyond the horizon.
The export presented in the GET methods uses the built-in functions included in the standard Postgres delivery. All COPYs are output to STDOUT, in case we want to notify the client about the results of these actions. Import to a fixed table (simple_data) looks a bit more bulky than export, therefore it is in the user-defined DBMS procedure.
Part of 1.import.export.sql for importing into a fixed table
CREATE OR REPLACE FUNCTION import_json_to_simple_data(filename TEXT) RETURNS void AS $$ BEGIN INSERT INTO simple_data SELECT * FROM json_populate_recordset(null::simple_data, convert_from(pg_read_binary_file(filename), 'UTF-8')::json); END; $$ LANGUAGE plpgsql; CREATE OR REPLACE FUNCTION import_xml_to_simple_data(filename TEXT) RETURNS void AS $$ BEGIN INSERT INTO simple_data SELECT (xpath('//s_id/text()', myTempTable.myXmlColumn))[1]::text::integer AS s_id, (xpath('//data0/text()', myTempTable.myXmlColumn))[1]::text AS data0 FROM unnest(xpath('/*/*', XMLPARSE(DOCUMENT convert_from(pg_read_binary_file(filename), 'UTF-8')))) AS myTempTable(myXmlColumn); END; $$ LANGUAGE plpgsql; The import function with a flexible table selection for JSON is not much different from the one above. But such flexibility for XML generates a more monstrous division.
Part of 1.import.export.sql for importing into an arbitrary table.
CREATE OR REPLACE FUNCTION import_vt_json(filename TEXT, target_table TEXT) RETURNS void AS $$ BEGIN EXECUTE format( 'INSERT INTO %I SELECT * FROM json_populate_recordset(null::%I, convert_from(pg_read_binary_file(%L), ''UTF-8'')::json)', target_table, target_table, filename); END; $$ LANGUAGE plpgsql; CREATE OR REPLACE FUNCTION import_vt_xml(filename TEXT, target_table TEXT) RETURNS void AS $$ DECLARE columns_name TEXT; BEGIN columns_name := ( WITH xml_file AS ( SELECT * FROM unnest(xpath( '/*/*', XMLPARSE(DOCUMENT convert_from(pg_read_binary_file(filename), 'UTF-8')))) --read tags from file ), columns_name AS ( SELECT DISTINCT ( xpath('name()', unnest(xpath('//*/*', myTempTable.myXmlColumn))))[1]::text AS cn FROM xml_file AS myTempTable(myXmlColumn) --get target table cols name and type ), target_table_cols AS ( -- SELECT a.attname, t.typname, a.attnum, cn.cn FROM pg_attribute a LEFT JOIN pg_class c ON c.oid = a.attrelid LEFT JOIN pg_type t ON t.oid = a.atttypid LEFT JOIN columns_name AS cn ON cn.cn=a.attname WHERE a.attnum > 0 AND c.relname = target_table --'log_data' ORDER BY a.attnum --prepare cols to output from xpath ), xpath_type_str AS ( SELECT CASE WHEN ttca.cn IS NULL THEN 'NULL AS '||ttca.attname ELSE '((xpath(''/*/'||attname||'/text()'', myTempTable.myXmlColumn))[1]::text)::' ||typname||' AS '||attname END AS xsc FROM target_table_cols AS ttca ) SELECT array_to_string(array_agg(xsc), ',') FROM xpath_type_str ); EXECUTE format('INSERT INTO %s SELECT %s FROM unnest(xpath( ''/*/*'', XMLPARSE(DOCUMENT convert_from(pg_read_binary_file(%L), ''UTF-8'')))) AS myTempTable(myXmlColumn)', target_table, columns_name, filename); END; $$ LANGUAGE plpgsql; In the examples given, the name table_name in the imported file does not affect the target destination table specified in nginx. The use of the xml hierarchy of the document table_name / rows / cols is due exclusively to symmetry with the built-in table_to_xml function.
The data sets themselves ...
simple_data_table.sql
CREATE TABLE simple_data ( s_id SERIAL, data0 TEXT ); data.csv
0;zero
1;one
data.json
[ {"s_id": 5, "data0": "five"}, {"s_id": 6, "data0": "six"} ] data.xml
<simple_data xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <row> <s_id>3</s_id> <data0>three</data0> </row> <row> <s_id>4</s_id> <data0>four</data0> </row> </simple_data> We have drifted away here, so let's return to the sources of pure COPY ...
Okay. This is probably the only way. Just let's make sure I understood everything correctly. Do you want to send data between the server and the client without processing filling it into a table?
I think I caught fear.
Nonsense. We came to find MidleWare dream.
And now, when we are right in her whirlwind, do you want to leave?
You have to understand, man, we found the main nerve.
Yes, it's almost like that! This is a rejection of CRUD.
Of course, many will be indignant as some type in a couple of sentences crosses out the results of the work of the California minds, styling a short little article for the dialogues of a drug-addicted film. However, all is not lost. There is an option to transfer the data modifier along with the data itself. That still leads away from the usual RESTful architecture.
In addition, sometimes, and when and more often, theoretical studies are broken on the rocks of reality. Such rocks are still the same unfortunate multipass. In fact, if you allow a change in a number of positions of a user document, then it is likely that these changes will include several types of methods. As a result, to send a single document to the database, you will need to conduct several separate http requests. And each http request will generate its own modification of the database and its passage through the tables. Therefore, a qualitative breakthrough requires fundamental changes to abandon the classical understanding of CRUD methods. Progress requires sacrifice.
Here I had suspicions that a more interesting solution could be found. You just need to experiment and think a bit ...
Point of entry
By the time I asked this question,
No one who could answer him was not there yet.
Yes, yes, I'm starting again ...
We send data to the middle layer, which sends it to the database without processing.
The DBMS parses them and puts them in a table that performs the role of a log / log. Registration of all input data.
The key point, here it is! Journaling / logging data flow out of the box! And then it's up to triggers. In them, on the basis of the business logic, we decide: to update, add or do something else. Screwing the data modifier is optional, but can be a nice bonus.
This leads us to the adequacy of using HTTP methods GET and PUT. Let's try to model how to apply it. To begin with we will be defined with a difference between magazines and a broad gull. We distinguish the key difference through the priority between the value of the route of change and the final value. The first criterion belongs to the logs, the second - to the logs.
Despite the priority of the final goal in the logs, the route is still necessary. Which leads us to the separation of such tables into two parts: the result and the journal itself.
What is it possible to pull? Logs: the route of the car, the movement of material values, etc. Logs: stock balance, last comment, and other recent instantaneous data states.
Code from 2.jrl.log.sql:
Tables
CREATE TABLE rst_data ( --Output/result table 1/2 s_id SERIAL, data0 TEXT, --Operating Data data1 TEXT, --Operating Data ); --Service variable with prefix s_, ingoring input value, it will be setting from trigers CREATE TABLE jrl_data ( --Input/journal table 2/2 s_id SERIAL, --Service variable, Current ID of record s_cusr TEXT, --Service variable, User name who created the record s_tmc TEXT, --Service variable, Time when the record was created p_trid INTEGER, --Service variable, Target ID/Parent in RST_(result) table, -- if exists for modification data0 TEXT, data1 TEXT, ); CREATE TABLE log_data ( --Input/output log table 1/1 s_id SERIAL, s_cusr TEXT, s_tmc TEXT, pc_trid INTEGER, --Service variable, Target ID(ParentIN/ChilrdenSAVE) -- in CURRENT table, if exists for modification data0 TEXT, data1 TEXT, ); Magazine Trigger
CREATE OR REPLACE FUNCTION trg_4_jrl() RETURNS trigger AS $$ DECLARE update_result INTEGER := NULL; target_tb TEXT :='rst_'||substring(TG_TABLE_NAME from 5); BEGIN --key::text,value::text DROP TABLE IF EXISTS not_null_values; CREATE TEMP TABLE not_null_values AS SELECT key,value from each(hstore(NEW)) AS tmp0 INNER JOIN information_schema.columns ON information_schema.columns.column_name=tmp0.key WHERE tmp0.key NOT LIKE 's_%' AND tmp0.key <> 'p_trid' AND tmp0.value IS NOT NULL AND information_schema.columns.table_schema = TG_TABLE_SCHEMA AND information_schema.columns.table_name = TG_TABLE_NAME; IF NEW.p_trid IS NOT NULL THEN EXECUTE (WITH keys AS ( SELECT ( string_agg((select key||'=$1.'||key from not_null_values), ',')) AS key) SELECT format('UPDATE %s SET %s WHERE %s.s_id=$1.p_trid', target_tb, keys.key, target_tb) FROM keys) USING NEW; END IF; GET DIAGNOSTICS update_result = ROW_COUNT; IF NEW.p_trid IS NULL OR update_result=0 THEN IF NEW.p_trid IS NOT NULL AND update_result=0 THEN NEW.p_trid=NULL; END IF; EXECUTE format('INSERT INTO %s (%s) VALUES (%s) RETURNING s_id', target_tb, (SELECT string_agg(key, ',') from not_null_values), (SELECT string_agg('$1.'||key, ',') from not_null_values)) USING NEW; END IF; RETURN NEW; END; $$ LANGUAGE plpgsql; Trigger for logs
CREATE OR REPLACE FUNCTION trg_4_log() RETURNS trigger AS $$ BEGIN IF NEW.pc_trid IS NOT NULL THEN EXECUTE ( WITH str_arg AS ( SELECT key AS key, CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN key ELSE NULL END AS ekey, CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN 't.'||key ELSE TG_TABLE_NAME||'.'||key END AS tkey, CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN '$1.'||key ELSE NULL END AS value, isc.ordinal_position FROM each(hstore(NEW)) AS tmp0 INNER JOIN information_schema.columns AS isc ON isc.column_name=tmp0.key WHERE isc.table_schema = TG_TABLE_SCHEMA AND isc.table_name = TG_TABLE_NAME ORDER BY isc.ordinal_position) SELECT format('WITH upd AS (UPDATE %s SET pc_trid=%L WHERE s_id=%L) SELECT %s FROM (VALUES(%s)) AS t(%s) LEFT JOIN %s ON t.pc_trid=%s.s_id', TG_TABLE_NAME, NEW.s_id, NEW.pc_trid, string_agg(tkey, ','), string_agg(value, ','), string_agg(ekey, ','), TG_TABLE_NAME, TG_TABLE_NAME) FROM str_arg ) INTO NEW USING NEW; NEW.pc_trid=NULL; END IF; RETURN NEW; END; $$ LANGUAGE plpgsql; The given examples do not know how to clean the cells, because for this you need to fasten utility values. And they are highly dependent on the method of import. In some cases, it can be any type with completely arbitrary content. In others, only the type of the target column with a probable sign to exit the range.
Triggers are called in the order of text sorting by name. I recommend using trg_N_ prefixes. From trg_0 to trg_4 to be considered as service ones, serving only the integrity of the common logic and incoming filtering. And from 5 to 9 use for applied calculations. Nine triggers will be enough for everyone !
It is also worth saying that they need to be installed on BEFORE INSERT. As in the case of AFTER, the NEW service variable will be put in the table before it is modified by the trigger. In principle, if integrity is not critical to some extent, such a solution can be a good accelerator for user requests passing through the log. This will not affect the values of the resulting table.
Also, with AFTER, we will not be able to return an error if the user does not have permission to change. But the correct FrondEnd and should not carry out operations prohibited by the server. Accordingly, such behavior is more likely characteristic of hacking, which will be peacefully recorded in the journal.
Filtering and routing
Routing URLs using standard nginx tools. In the same way we filter the request from injections. After doubling the problem, the code similar to the result of asymmetric encryption is pushed into the directive map nginx.conf to get a digestible and secure SQL query. Which, further, we filter the data.
There are some difficulties. They are caused by the lack of regularization in nginx for multiple replacements like sed s / bad / good / g . As a result, we ...
We fall right into the thick of this fucking terrarium. And after all, someone has the mind to write these damn expressions! A little more and they will tear the brain to shreds.
up to 4 equivalency filters by URL
http://some.server/csv/table_name/*?col1=value&col2=value&col3=value&col4=valueHorrowshow part of filters.nginx.conf
# SQL map $args $fst0 { default ""; "~*(?<tmp00>[a-zA-Z0-9_]+=)(?<tmp01>[a-zA-Z0-9_+-.,:]+)(:?&(?<tmp10>[a-zA-Z0-9_]+=)(?<tmp11>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp20>[a-zA-Z0-9_]+=)(?<tmp21>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp30>[a-zA-Z0-9_]+=)(?<tmp31>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp40>[a-zA-Z0-9_]+=)(?<tmp41>[a-zA-Z0-9_+-.,:]+))?" "$tmp00'$tmp01' AND $tmp10'$tmp11' AND $tmp20'$tmp21' AND $tmp30'$tmp31' AND $tmp40'$tmp41'"; } # map $fst0 $fst1 { default ""; "~(?<tmp0>(:?[a-zA-Z0-9_]+='[a-zA-Z0-9_+-.,:]+'(?: AND )?)+)(:?( AND '')++)?" "$tmp0"; } map $fst1 $fst2 { default ""; "~(?<tmp0>[a-zA-Z0-9_+-=,.'' ]+)(?= AND *$)" "$tmp0"; } # , WHERE map $fst2 $fst3 { default ""; "~(?<tmp>.+)" "WHERE $tmp"; } server { location ~/csv/(?<table>result_[a-z0-9]*)/(?<columns>\*|[a-zA-Z0-9,_]+) { pgcopy_query GET db_pub "COPY (select $columns FROM $table $fst3) TO STDOUT WITH DELIMITER ';';"; } } With Cyrillic filtering in the URL, via the nginx config, all is not smooth either - we need native conversion from one variable from base64 to another, with human-readable text. At the moment, there is no such directive. Which is quite strange, because in the source code for nginx, transcoding functions are present.
As a thread, I will definitely gather my thoughts and liquidate this omission, as well as the problem with sed, if the nginx inc team does not solve this.
It would be possible to give the url a string with arguments in the DBMS, for the internal generation of a dynamic query in a direct function call or a call through the table log trigger. But since such data is already logged in nginx-access.log, these initiatives are redundant. And given the fact that such actions can increase the load on the base scheduler, they are also harmful.
Sm oke all FAQ
- Modules for nginx have been successfully written for a long time. Why fanfare?
Most of the existing analogues are highly specialized solutions. The article presents a reasonable compromise of speed and flexibility!
- Work through the disk (client_body_in_file_only) - slowly!
Yes, RAM Drive will come with you and its prophet is the file system cache.
- What about user rights?
Login with plain http is forwarded to postgres. There you solve with built-in tools. In general, a full BackEnd.
- What about encryption?
Module ssl through nginx config. At the current stage, it may not take off due to the ngx_pgcopy code dampness.
Connecting nginx with postgres, when paging servers, paranoids can be thrown through ssh.
- Fuck JS symbols in the reflection of the points at the beginning? Where is javascript?
JS goes to FrontEnd. And this is a completely different movie.
- Is there life on the client with JS disabled?
As you may have noticed earlier, in the examples, Postgres may be in xml. Those. getting output HTML is no problem. Both with the use of spaghetti code, and through the xsl scheme.
It's horrible. However, everything will be fine. You do everything right.
- How to resize images, pack archivists and read the path of leptons on the GPU?
And so that is easier.
Maybe I'd better chat with this guy, I thought.
Do not come to FastCGI!
They are just waiting for this from us.
Lure us into this box
Let go to the basement. There.
We say ngix client_body_in_file_only on , take in the armful $ request_body_file and plperlu, with access to the command line. And adapt that thread from:
CREATE OR REPLACE FUNCTION foo(filename TEXT) RETURNS TEXT AS $$ return `/bin/echo -n "hello world!"`; $$ LANGUAGE plperlu; - It looks like a CGI. And CGI is not safe!
Security depends more on your literacy than on the technology used. Yes. After screwing in environment variables, this is compatible with CGI. Moreover, it can be used for a smooth transition from CGI with minimal restructuring of scripts. Accordingly, the method is suitable for evacuating most PHP solutions.
You can also dream up about distributed computing (thanks to clustering PostgreSQL) and the freedom to choose approaches to asynchrony. But to do this, I certainly will not.
Links
→ ngx_pgcopy
→ PostgreSQL COPY request
→ slim_middle_samples ( examples from article + build demo)
WARRNING
The module is still in development, so stability problems are possible. In view of the keep alive connection that I had not yet realized towards the backend, this creature, for the time being, is still valid for the role of a supersonic fighter. Module README to you in reading.
Ps. In fact, CRUD is implemented without any problems through stored procedures, or the log for a method is not applicable to logs. I also forgot to add the DELETE method to the module.
The article used frames and quotes from the movie “Fear and Loathing in Las Vegas” 1998. The materials are used exclusively for non-commercial purposes and as part of the promotion of cultural, educational and scientific development of society.
Source: https://habr.com/ru/post/331056/
All Articles