What are interactive systems, or something about elise
Interactive systems have long been firmly established in our life. The title mentions and in the picture is presented ELIZA - the interactive psychoanalyst system (now, they would call it a chat bot), originally from the 60s. If you are interested in how a person came to communicate with psychoanalytic bots and what else is interesting in conversational systems, welcome to Cat.
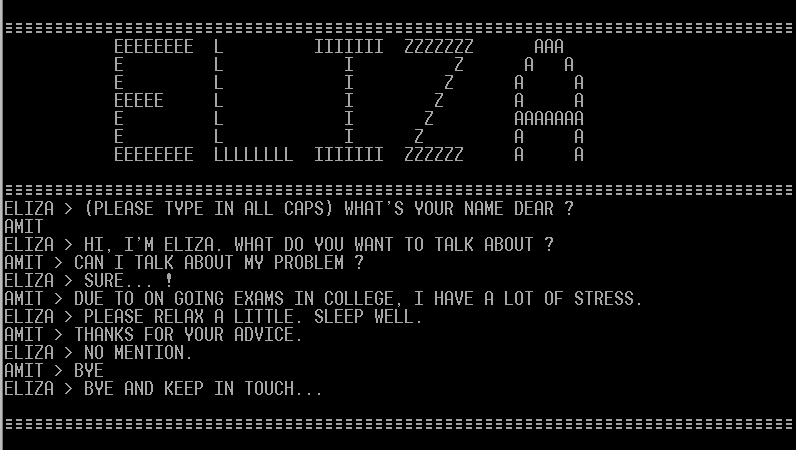
In fact, now the dialogue systems can be found anywhere: if you call the bank, you communicate (at least first) with the dialogue system when you place an order or try to set a route in the navigator - also maybe you are using Apple's Siri or Microsoft's Cortana, and that’s them too.
What is attractive about interactive interfaces? The fact that this is a natural way for a person to obtain information. (Actually, therefore, the robot with whom you are talking, when you call somewhere, calls the “autoinformer”.)
Classification
Interactive systems can be characterized by the following features: General - Task-oriented (general purpose - task-oriented) and Open Domain - Closed Domain (able to speak on any topic or only on a strictly defined one). In each pair, the first component is significantly more complex than the second. Let's look at a few examples:
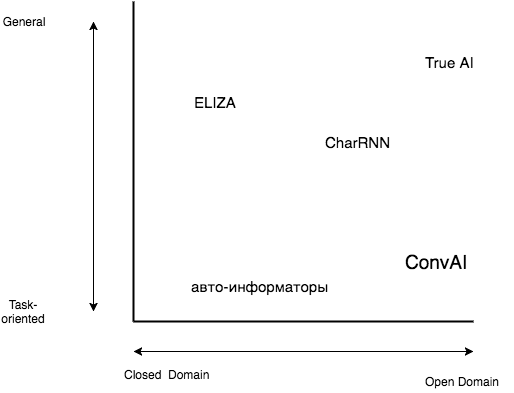
Let's start with the simplest - with autoinformers, they are definitely task-oriented and closed domain.
The aforementioned ELIZA is a closed domain (she is able to speak only on the topic of psychoanalysis), but at the same time she is general — she has no clearly set task, she can be “chatted” with her.
Another example of a bot that you can chat with is CharRNN from Andrei Karpati (Andrej Karpathy). CharRNN itself is just a neural network model that can continue the line given to it, if you train it, for example, on subtitles for movies and TV shows, it will learn to “respond” to your replicas. In this sense, it is general — it has no clearly defined goal — and the open domain can potentially speak on any topic. The only problem is that this model is extremely simple, it just continues the line given to it, having no idea about the dialogue, phrases and even individual words.
There are two examples left: ConvAI is our competition, which is described below, and true AI. Why did I separately single out that AI is “real” here? Because now the fashion has gone to call AI anything, right up to autoinformers. I wanted to emphasize that this is a full-fledged artificial intelligence, able to speak on any topic. And - most importantly - he is able to lead a conversation, that is, he has an idea about the dialogue.
Convi
Now it's time to talk about our competition, how it differs from the one above, and why we decided to do it.
ConvAI is a Conversational Intelligence Challenge, a competition of conversational artificial intelligence. And since this is a competition, you need to somehow compare the participants. And here it turns out that the standard text comparison metrics, known by machine translation BLEU, ROUGE, etc. don't work here.
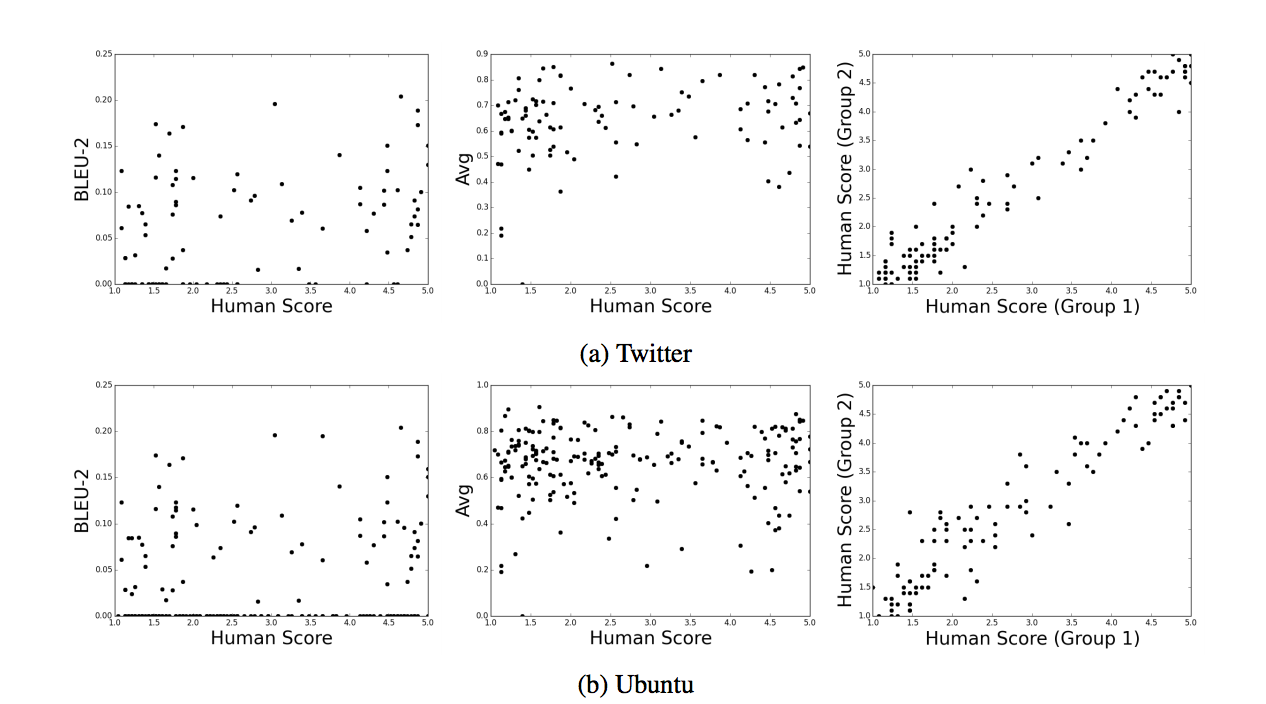
It turns out that the machine metrics that we know do not correlate with human judgments (while human assessments correlate well with each other — the upper right picture). Source [1].
From this it follows that comparing general-purpose systems with each other is not yet possible - we simply do not know how to do this. But then we can definitely compare task-oriented systems using the simplest Task Completion Rate (TCR) metric.

That is, we can compare them by the number of dialogues that have reached the goal. As a goal for our competition, we have chosen to discuss a small piece of text, for example, a short news article or a Wikipedia entry. The person, having communicated on the subject of the presented text with another person / bot, puts his assessment. In this case, we do not give the user information about the "naturalness" or "artificiality" of the interlocutor's intelligence. Based on the collected assessments, we will be able to rank the bots of our participants so as to build a chain from the simplest CharRNN to a human. (At least we hope so.)
![]()
It is worth mentioning that our challenge has passed a tough selection and was chosen as the NIPS Live Competition of this year. Also, the co-organizers of the competition are Yoshua Bengio, who needs no introduction, as well as Alexander Rudnicky and Alan W. Black of Carnegie-Mellon University.
All information about the competition, including the rules, the API of our server and more, can be found on his website convai.io .
Datasets
Separately it is necessary to say about the available datasets for research in the field of conversational intelligence. There are several public datasets for interactive systems [2]. First of all, it is worth highlighting the Dialog State Tracking Challenge , this year, by the way, it will be held for the sixth time. It is designed for systems that can conduct a dialogue, tracking its state (state), that is, it is perhaps the closest to the goal of our competition. But this dataset has an important feature - it is a closed domain, that is, it exclusively considers one specific topic. Open domain and task-oriented public dataset does not exist, and we expect that after our competition a new dataset consisting of conversations of volunteers and team members with bots will be formed, which will be shared for all researchers.
Conclusion
We hope that you have formed some idea of the dialogue systems. Moreover, if you want to try yourself in their creation, then we will be happy to see you as a participant or a volunteer (we need people who will talk to our members' bots). If you have no idea where to start, we have made a basic decision especially for you. It requires a bit of prerequisites to run - in fact, Docker alone. So - go ahead!
PS If you are interested in participating in the creation of artificial intelligence, not only during the competition, but also on an ongoing basis, we have open positions. Information can be found on the website ipavlov.ai .
Literature
- Chia-Wei Liu et al. How Do You Evaluate Your Dialogue System Metals for Dialogue Response Generation. arxiv: 1603.08023
- Iulian Vlad Serban et al. A Survey of Available Dialogue Systems. arxiv: 1512.05742
')
Source: https://habr.com/ru/post/330228/
All Articles