How data science helps the development of medicine. Lecture in Yandex
The gradual informatization of medicine is associated with the collection of very different data. They are mined in completely different ways and almost always have a unique structure. Where, how and why should they be collected? In his report, Mikhail Tomcat, head of development of the Yandex.Health service, Pyson, talks about the main ways of developing modern medicine and the technological problems that it faces.
Under the cut - transcript of the report and slides.
My name is Mikhail Paison, I am developing Yandex. Health, in fact I am in charge of it. In my report, I will tell you about the spacecraft that plow open spaces. But not the Bolshoi Theater, because the Bolshoi Theater is quite far away, but these close spaces, which are somewhere nearby and will soon become a reality. This will be a report on tops, very shallow. I will try to maximize the number of areas where big data can be used, machine learning.
')
Why am I here? We are engaged in Yandex.Health, while we are very close to the user, that is, we are solving some very practical tasks: writing to a doctor, storing reception results, etc. Therefore, what I’m going to talk about is the most practical things that I would probably like to use it now, and introduce it into industry, and not just leave it in scientific research.
Let's start with the section on what big data we can have in medicine, on which we can build some conditional machine learning or artificial intelligence.
The first largest block of data that has accumulated in the industry is unstructured data.
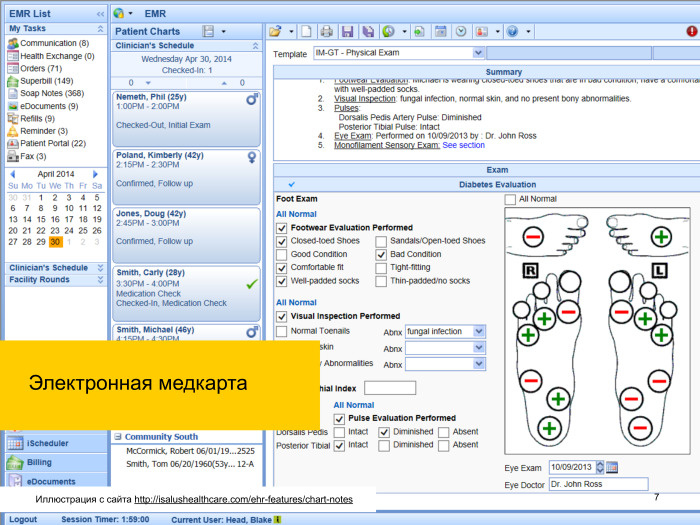
What it is? For example, electronic medical card. Now actively developing in many areas, used in many clinics. There are already projects, somewhere in the USA this has already become mandatory for a very long time. In Russia, it seems to be implemented more with constant success than with variable ones. However, there is such data. All this is stored, preserved, somewhere there is a base, in America it is centralized, we, I hope, will soon be centralized too.
This is unstructured data. These are data in which there is no clear division into fields, a clear selection of some terms or keywords. That is, there is some kind of array, you need to mine the necessary information from it.
The following is a telemedicine recording. Also a good example when the patient and the doctor communicate remotely. The patient says something, the doctor answers something. That is all - audio, video - can be recognized, and this is also unstructured data as an example of what might come in handy.
Photos and scans of documents. Here, too, there are some problems, especially if we remember how wonderful our doctors are ... The patient cannot exactly recognize what they wrote. It always surprises me how a pharmacist in a pharmacy, when you give him a prescription, can understand what is written there. However, this is also a big piece for analysis, that is, we can also analyze this data, we can also find a structure there and get some insights from there.
There are also forums, blogs. Blogs are different, forums are different too. Some are a little worse, some are better, but this is also a source of data that we can take and which we can work on.

There is such a thing - IBM Watson. Who heard about Watson? Wow! Great. It seems, about Watson heard almost everything. Now this is not some kind of technology, but rather a set of technologies, plus the platform on which it works. More recently, they bought a British image processing company. They now have their own Deep Learning there, etc. But in general, they started by taking an electronic archive of medical cards, plus forms, specialized blogs, fully indexed them, threw natural language processing on them, and made correct search algorithms based on them matching Then they began to use for diagnosis. They began with the processing of unstructured information, that is, information from medical cards.
It is worth mentioning the famous Google DeepMind Health. Like all normal living doctors, Watson and DeepMind have a hobby. Watson plays his American game Jeopardy and wins everybody, that is, he was once the champion of America in his game. And DeepMind is keen on go, and AlphaGo is the very DeepMind that is now used in medicine. This is with regard to unstructured data.
There are a lot of unstructured data, they need to be mined, they can be mined. It is clear how. People already do this in industry. The same Watson is already in full use, they offer it as a system in support of decision-making, and even quite successfully offer it.
Data from wearable devices is also a big piece of data that is not actively being processed now, but it seems that everything is about to begin.
What are wearable devices? For a start, we are talking about some professional devices. A good example is Holter monitoring. What are professional devices? These are devices that cost a lot of money, thousands of dollars, and which the clinic buys. A person comes, puts on this device, wears some time, and then they receive data from this device.
What is Holter monitoring, I think, many people know. This is a piece that is worn for a day and which monitors the state of the heart. He then brings the big-big data that a person collected in a day, to a doctor and somehow marks: "At this time I was doing one thing, at the time I was doing another." Then, according to the obtained markup, he is now analyzing in a semi-automatic mode, and the doctor, in turn, draws some conclusions.
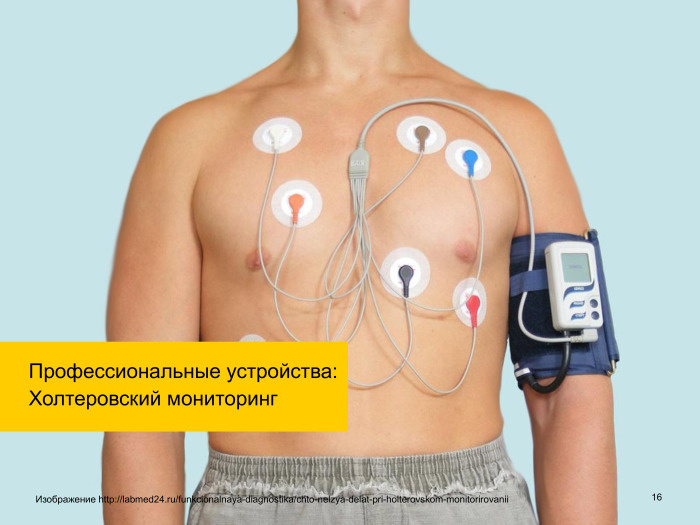
Everyone, probably, who came across this, got used to something like this kind of Holter monitoring, but in fact it’s already about that.
That is, it is a thing that is sewn. See how much science is already progressing. This is a thing that constantly sends data to any docking station via Wi-Fi or Bluetooth, which can be sent to the doctor’s console in real time, etc. That is, it is already used today. And a lot of data, they are large by definition. If the ECG for the whole day is taken from a person, then there is a very serious amount of data, it requires processing, and various conclusions can be made.
The next step is consumer electronics. What it is? Smartphones, Mi Band, bracelets. Who right now on the hand of any Mi Band, a bracelet is wearing, a pedometer? In principle, there are already enough, 10 percent of the hall.
The same Mi Band, which is now actively advertised - a thing with which you can also take a lot of different data. In fact, the pulse plus the number of steps and so on. It is difficult to make a diagnosis from this data when they are in themselves. But when they fall into the repository, where data from other sources — the same medical card — were lying before, the process begins to make sense. It is also possible to build some algorithms above the specified data.
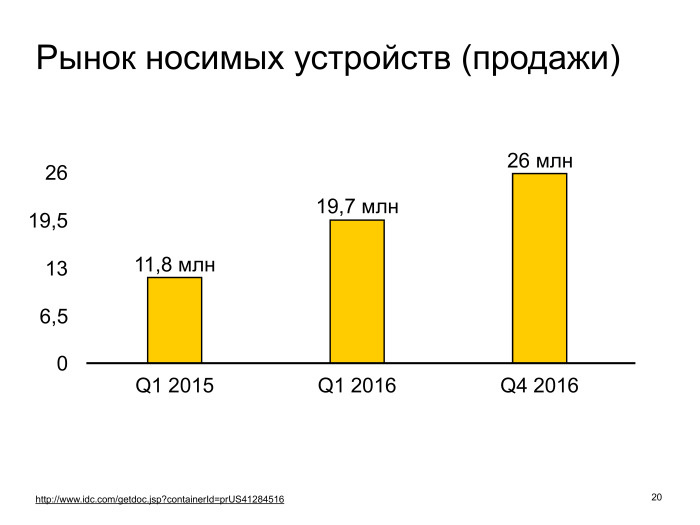
To the question about the market of wearable devices. According to statistics, from a good analytical website, listed below, we see a growth of more than twice from the beginning of 2015 and conditionally until the end of 2016 - because they have not yet had data for 2017. This is quite a lot. It seems that sooner or later approximately everyone will have such wearable electronics, the same smartphone that measures steps.

There is also such an intermediate option - specialized devices that a person can afford to buy, that is, it is not necessary to take them from a medical institution. However, they are more or less advanced. For example, an electronic stethoscope. He did not do auscultation himself, but he receives the data and can, for example, send it to a doctor. Or - this is big data, we are about science and about spacecraft - why not do it automatically, why not listen to the sound of the heart, the sound of breathing, and on the basis of sound signal processing, why not draw some conclusions?
There are big problems with wearable electronics. This is more about the protection of personal data, which Dmitry will talk about after me. But in general, when we say that we will have a lot of data about all users, we need to think about where they will be stored, where to go. Because, in principle, even now there are cases when Apple stores people’s routes somewhere, how they move during the day and where. And this is not very pleasant to those for whom Apple is watching.
Farther. Here is my favorite piece, because it's about rocket science. If until now everything has been more or less clear and approximate, then this is really a very steep area where there is a sea of interesting.
Genetic information is also used in very many areas, and it is not just about sequencing itself. Pieces of the genome are already little by little decoded, or there is already an apparatus that decodes a large piece, but with a loss of accuracy. But the question here is not only about the decoding of the genome itself - although this is a huge storehouse for knowledge and data. In fact, it is possible to decipher the genomes of our smaller brothers, who live in every hidden corner of the body and on the basis of which you can also get a lot of information about us.
For example, the diagnosis of genetic diseases is already actively and remarkably working. This is industry, reality. In this area you can now come. Probably heard an epic story about Angelina Jolie, how did she do a mastectomy for herself, because she had a very high risk of breast cancer? We can say that this thing has already saved her life, it is quite possible. Or at least greatly improved the quality.
The second is the search for pathogens.
Pro microbiota sequencing today will be a separate report . I really want to listen to him.
Search for pathogens. We look at the DNA that has been cut from small pieces, and we see that there is something wrong. There, some bad DNA was mixed up with some kind of malware, and we see what kind of malware it is, and we can already prescribe a treatment.
In fact, I urge to follow this link . We had a whole seminar, Data & Science, in the framework of the same course. Wonderful speakers, there are four hours, but you will not regret it, especially since you can double the speed on YouTube.
Probably the most common, the very first thing that catches your eye and what comes to mind is images. It is clear that exactly the images are striking. Here, too, a lot of things can be found.
For example, x-ray images. On them it is possible to automatically process and detect many violations, some diseases, etc.
The same MRI, automatic processing, CT. Let's say there is such an OCT - about the same as ultrasound, only on optical waves. I may not be speaking very precisely from a medical point of view, but just to have an understanding.
And images from electron microscopes are also a huge piece of data that can also be analyzed. We are talking about image processing, automatic analysis, pattern recognition, etc.
Here are some examples. There are two of them, both about the same, but nonetheless. To begin with, Google recently released an article, there Jeff Dean, about how they learned to localize tumor cells. Clearly, there is breast cancer, there are metastases in the adjacent lymph nodes, and they need to be found.
There is such a thing - gigapixel images. They have billions of pixels. If you roughly count, the order is. If it is printed out with a normal resolution, then the size of the canvas is approximately 30 by 30 meters. It is clear that when a doctor looks at this image, it’s quite difficult to understand what is happening there, to detect small foci, etc. But if you set up an algorithm on all of this, let's say the same neuron as Google’s did, - you can quite accurately detect the presence of, say, tumor cells. According to the results of research, they showed about 89% accuracy against 73% of a normal live, serious and good doctor. It seems that this is also a promotion.
The following is about the same. Here, it seems to me, is more interesting. The guys identified a different type of lung cancer. There is squamous cell carcinoma, and there is adenocarcinoma. They look a little different and, most importantly, are treated with different chemotherapy. Accordingly, in the image from a microscope, they can most likely distinguish the first from the second. And decision support systems - after all, all the decisions are made by a person - they can already say with a fair degree of confidence that this cancer is most likely here.
How does this example differ from the previous one? It seems they are very similar, the difference is in the details. In the previous gigapixel images, the neural network was simply wrapped up - maybe, it was trained on ImageNet, on dogs and seal dogs (it was a joke). Here they simply process the image, isolate these cells, and already on the images the cells measure, consider about 200 features. In this article, there is a straightforward Excel-table, where it is indicated what particular features they consider. And already on the basis of these features, they classify the tumor. It seems they are just doing SVM up there.
Next, another example about the image. It is clear that we can talk a lot about them. There is a huge number of applications not only for detecting types of oncology, etc. The field is not plowed.
Now I don’t even fantasize a bit, but I’ll do some summing up.
Where can I use big data right now?

In fact, for a doctor, this is basically a diagnosis of decision support systems. That is, we still now seem to be afraid to say that we are 100% diagnosed, that the patient has this thing, treat like this, we don’t need a doctor, we do it automatically. Now we are not ready, as algorithm developers, to make such decisions. But now, with a high degree of probability, algorithms can give the right solution, and diagnose it more accurately.
What is accurate medicine? This is a medicine that, when diagnosing, takes into account not only the current history of a person, but also a huge amount of information about him, in particular the genetic code and all the data that I first described. In this direction, too, everything will move, because the more we know about a person, the more we can understand what a person is sick and how to treat it.
The third point, the simplification of daily work, is an exceptionally mundane. For example, voice recognition seems to be very relevant now for doctors, because in certain cases - when the hands, for example, are occupied with manipulations - it is very inconvenient to write. Good voice recognition can help here, which, let's say, takes and translates everything that the doctor pronounces into the same electronic medical card.

Now about the patient. To begin with - the prediction of disease. What does it mean? This means that the patient comes, as now, donates a piece of saliva or a drop of blood, he is sequenced by DNA and potential problems are found. This is very cool, allows you to know in advance about what you can not find out. Once again I say: all the things related to DNA, sequencing, the processing algorithm of these sequences are also very interesting, there is very strong mathematics. I refer to the link that I gave a dozen slides back. Listen, look - very cool.
Further predictions. Next is the survey recommendation, at about the same level. If we understand that a person has an increased risk of a particular disease, then we can recommend an examination, for example. You can do an ultrasound of the breast or pass on some markers.
Recommendations for a healthy lifestyle. Exactly the same, when you have a box or a smartphone - which most likely - will say: “So, something is all bad, something you have been running for a long time and a lot. Give me some rest. ” Or: “Something in recent times, the pulse has behaved in a strange way. We need to eat carrots, ”- conditionally.
Health monitoring is more for the chronicles. I flipped through a slide with a patch that measures glucose levels. Now, for example, Apple does it with might and main. It seems that non-invasive methods for measuring glucose will be the next huge breakthrough. This is also very important, because a person stabs his finger many times a day, especially if it is a chronicle with diabetes. This is unpleasant, disgusting. If such a plaster is simply pasted somewhere on the arm - in my opinion, this will greatly increase the likelihood that it will not ignore these procedures.
I talked about the good, now a little about the bad.
For a start, sample sizes. Returning to the fact that we still mean big data, I will say: everything is bad with the sample size. If you read a lot of modern research, it is 200-300 measurements. Not to say that this is big data. To educate some normal classifier on 200-300 dimensions is a dubious pleasure, yet more data is needed. And get big data, just take it and say: “I want to do big data in medicine. Give me the data, I will analyze them, ”also fails. Basically, all the studies that are referenced and about which it is said that they are at the forefront of science, are carried out through partnership with some large medical institution. Google partners with the Royal College in London, takes data from them constantly. The same IBM got access to a single medical card in America. It takes a lot of diplomatic efforts, especially in Russia.
What is in Russia? It seems that the most interesting thing we will have in the near future is an electronic medical card. It is currently being developed, implemented. As I have already said, it is being introduced with conditionally variable success. It seems more likely with success than without it. But there are some concerns about implementation. They say: "Let us all cover hundreds of thousands of clinics, medical assistant's points and other things with a single network and structure." That is, with it, as with any large state initiative, there are many problems in terms of the coincidence of data, formats, etc. Even technical problems are not technical — I’m not even talking about organizational ones. Plus, they postulate that there will be access to this data, but, returning to the previous slide, not at all and not immediately. , , . , . , , , .
— , . , , - , c . , , , .
. , Google , . ? , . , , «», — , . , … , 30-40 , . . — , .
. — .

. . . , — , : «, , », . , , . . , - - Kaggle. , , , . — , , — . , - , , : «, — ».
Farther. , . . , . , … , : , - XII , , , . , , , . . , . .
— , , , , , , . . - , , , - .
— . . . — , , , . . , . , , , , , , . . . - . . , — - . , .

— . - , , . , , . . , , , . , — , . , - , , .
— . , — , . . — . , — . -, , - . , .

— . , — , . , . !
Under the cut - transcript of the report and slides.
My name is Mikhail Paison, I am developing Yandex. Health, in fact I am in charge of it. In my report, I will tell you about the spacecraft that plow open spaces. But not the Bolshoi Theater, because the Bolshoi Theater is quite far away, but these close spaces, which are somewhere nearby and will soon become a reality. This will be a report on tops, very shallow. I will try to maximize the number of areas where big data can be used, machine learning.
')
Why am I here? We are engaged in Yandex.Health, while we are very close to the user, that is, we are solving some very practical tasks: writing to a doctor, storing reception results, etc. Therefore, what I’m going to talk about is the most practical things that I would probably like to use it now, and introduce it into industry, and not just leave it in scientific research.
Let's start with the section on what big data we can have in medicine, on which we can build some conditional machine learning or artificial intelligence.
The first largest block of data that has accumulated in the industry is unstructured data.
What it is? For example, electronic medical card. Now actively developing in many areas, used in many clinics. There are already projects, somewhere in the USA this has already become mandatory for a very long time. In Russia, it seems to be implemented more with constant success than with variable ones. However, there is such data. All this is stored, preserved, somewhere there is a base, in America it is centralized, we, I hope, will soon be centralized too.
This is unstructured data. These are data in which there is no clear division into fields, a clear selection of some terms or keywords. That is, there is some kind of array, you need to mine the necessary information from it.
The following is a telemedicine recording. Also a good example when the patient and the doctor communicate remotely. The patient says something, the doctor answers something. That is all - audio, video - can be recognized, and this is also unstructured data as an example of what might come in handy.
Photos and scans of documents. Here, too, there are some problems, especially if we remember how wonderful our doctors are ... The patient cannot exactly recognize what they wrote. It always surprises me how a pharmacist in a pharmacy, when you give him a prescription, can understand what is written there. However, this is also a big piece for analysis, that is, we can also analyze this data, we can also find a structure there and get some insights from there.
There are also forums, blogs. Blogs are different, forums are different too. Some are a little worse, some are better, but this is also a source of data that we can take and which we can work on.
There is such a thing - IBM Watson. Who heard about Watson? Wow! Great. It seems, about Watson heard almost everything. Now this is not some kind of technology, but rather a set of technologies, plus the platform on which it works. More recently, they bought a British image processing company. They now have their own Deep Learning there, etc. But in general, they started by taking an electronic archive of medical cards, plus forms, specialized blogs, fully indexed them, threw natural language processing on them, and made correct search algorithms based on them matching Then they began to use for diagnosis. They began with the processing of unstructured information, that is, information from medical cards.
It is worth mentioning the famous Google DeepMind Health. Like all normal living doctors, Watson and DeepMind have a hobby. Watson plays his American game Jeopardy and wins everybody, that is, he was once the champion of America in his game. And DeepMind is keen on go, and AlphaGo is the very DeepMind that is now used in medicine. This is with regard to unstructured data.
There are a lot of unstructured data, they need to be mined, they can be mined. It is clear how. People already do this in industry. The same Watson is already in full use, they offer it as a system in support of decision-making, and even quite successfully offer it.
Data from wearable devices is also a big piece of data that is not actively being processed now, but it seems that everything is about to begin.
What are wearable devices? For a start, we are talking about some professional devices. A good example is Holter monitoring. What are professional devices? These are devices that cost a lot of money, thousands of dollars, and which the clinic buys. A person comes, puts on this device, wears some time, and then they receive data from this device.
What is Holter monitoring, I think, many people know. This is a piece that is worn for a day and which monitors the state of the heart. He then brings the big-big data that a person collected in a day, to a doctor and somehow marks: "At this time I was doing one thing, at the time I was doing another." Then, according to the obtained markup, he is now analyzing in a semi-automatic mode, and the doctor, in turn, draws some conclusions.
Everyone, probably, who came across this, got used to something like this kind of Holter monitoring, but in fact it’s already about that.
That is, it is a thing that is sewn. See how much science is already progressing. This is a thing that constantly sends data to any docking station via Wi-Fi or Bluetooth, which can be sent to the doctor’s console in real time, etc. That is, it is already used today. And a lot of data, they are large by definition. If the ECG for the whole day is taken from a person, then there is a very serious amount of data, it requires processing, and various conclusions can be made.
The next step is consumer electronics. What it is? Smartphones, Mi Band, bracelets. Who right now on the hand of any Mi Band, a bracelet is wearing, a pedometer? In principle, there are already enough, 10 percent of the hall.
The same Mi Band, which is now actively advertised - a thing with which you can also take a lot of different data. In fact, the pulse plus the number of steps and so on. It is difficult to make a diagnosis from this data when they are in themselves. But when they fall into the repository, where data from other sources — the same medical card — were lying before, the process begins to make sense. It is also possible to build some algorithms above the specified data.
To the question about the market of wearable devices. According to statistics, from a good analytical website, listed below, we see a growth of more than twice from the beginning of 2015 and conditionally until the end of 2016 - because they have not yet had data for 2017. This is quite a lot. It seems that sooner or later approximately everyone will have such wearable electronics, the same smartphone that measures steps.
There is also such an intermediate option - specialized devices that a person can afford to buy, that is, it is not necessary to take them from a medical institution. However, they are more or less advanced. For example, an electronic stethoscope. He did not do auscultation himself, but he receives the data and can, for example, send it to a doctor. Or - this is big data, we are about science and about spacecraft - why not do it automatically, why not listen to the sound of the heart, the sound of breathing, and on the basis of sound signal processing, why not draw some conclusions?
There are big problems with wearable electronics. This is more about the protection of personal data, which Dmitry will talk about after me. But in general, when we say that we will have a lot of data about all users, we need to think about where they will be stored, where to go. Because, in principle, even now there are cases when Apple stores people’s routes somewhere, how they move during the day and where. And this is not very pleasant to those for whom Apple is watching.
Farther. Here is my favorite piece, because it's about rocket science. If until now everything has been more or less clear and approximate, then this is really a very steep area where there is a sea of interesting.
Genetic information is also used in very many areas, and it is not just about sequencing itself. Pieces of the genome are already little by little decoded, or there is already an apparatus that decodes a large piece, but with a loss of accuracy. But the question here is not only about the decoding of the genome itself - although this is a huge storehouse for knowledge and data. In fact, it is possible to decipher the genomes of our smaller brothers, who live in every hidden corner of the body and on the basis of which you can also get a lot of information about us.
For example, the diagnosis of genetic diseases is already actively and remarkably working. This is industry, reality. In this area you can now come. Probably heard an epic story about Angelina Jolie, how did she do a mastectomy for herself, because she had a very high risk of breast cancer? We can say that this thing has already saved her life, it is quite possible. Or at least greatly improved the quality.
The second is the search for pathogens.
Pro microbiota sequencing today will be a separate report . I really want to listen to him.
Search for pathogens. We look at the DNA that has been cut from small pieces, and we see that there is something wrong. There, some bad DNA was mixed up with some kind of malware, and we see what kind of malware it is, and we can already prescribe a treatment.
In fact, I urge to follow this link . We had a whole seminar, Data & Science, in the framework of the same course. Wonderful speakers, there are four hours, but you will not regret it, especially since you can double the speed on YouTube.
Probably the most common, the very first thing that catches your eye and what comes to mind is images. It is clear that exactly the images are striking. Here, too, a lot of things can be found.
For example, x-ray images. On them it is possible to automatically process and detect many violations, some diseases, etc.
The same MRI, automatic processing, CT. Let's say there is such an OCT - about the same as ultrasound, only on optical waves. I may not be speaking very precisely from a medical point of view, but just to have an understanding.
And images from electron microscopes are also a huge piece of data that can also be analyzed. We are talking about image processing, automatic analysis, pattern recognition, etc.
Here are some examples. There are two of them, both about the same, but nonetheless. To begin with, Google recently released an article, there Jeff Dean, about how they learned to localize tumor cells. Clearly, there is breast cancer, there are metastases in the adjacent lymph nodes, and they need to be found.
There is such a thing - gigapixel images. They have billions of pixels. If you roughly count, the order is. If it is printed out with a normal resolution, then the size of the canvas is approximately 30 by 30 meters. It is clear that when a doctor looks at this image, it’s quite difficult to understand what is happening there, to detect small foci, etc. But if you set up an algorithm on all of this, let's say the same neuron as Google’s did, - you can quite accurately detect the presence of, say, tumor cells. According to the results of research, they showed about 89% accuracy against 73% of a normal live, serious and good doctor. It seems that this is also a promotion.
The following is about the same. Here, it seems to me, is more interesting. The guys identified a different type of lung cancer. There is squamous cell carcinoma, and there is adenocarcinoma. They look a little different and, most importantly, are treated with different chemotherapy. Accordingly, in the image from a microscope, they can most likely distinguish the first from the second. And decision support systems - after all, all the decisions are made by a person - they can already say with a fair degree of confidence that this cancer is most likely here.
How does this example differ from the previous one? It seems they are very similar, the difference is in the details. In the previous gigapixel images, the neural network was simply wrapped up - maybe, it was trained on ImageNet, on dogs and seal dogs (it was a joke). Here they simply process the image, isolate these cells, and already on the images the cells measure, consider about 200 features. In this article, there is a straightforward Excel-table, where it is indicated what particular features they consider. And already on the basis of these features, they classify the tumor. It seems they are just doing SVM up there.
Next, another example about the image. It is clear that we can talk a lot about them. There is a huge number of applications not only for detecting types of oncology, etc. The field is not plowed.
Now I don’t even fantasize a bit, but I’ll do some summing up.
Where can I use big data right now?
In fact, for a doctor, this is basically a diagnosis of decision support systems. That is, we still now seem to be afraid to say that we are 100% diagnosed, that the patient has this thing, treat like this, we don’t need a doctor, we do it automatically. Now we are not ready, as algorithm developers, to make such decisions. But now, with a high degree of probability, algorithms can give the right solution, and diagnose it more accurately.
What is accurate medicine? This is a medicine that, when diagnosing, takes into account not only the current history of a person, but also a huge amount of information about him, in particular the genetic code and all the data that I first described. In this direction, too, everything will move, because the more we know about a person, the more we can understand what a person is sick and how to treat it.
The third point, the simplification of daily work, is an exceptionally mundane. For example, voice recognition seems to be very relevant now for doctors, because in certain cases - when the hands, for example, are occupied with manipulations - it is very inconvenient to write. Good voice recognition can help here, which, let's say, takes and translates everything that the doctor pronounces into the same electronic medical card.
Now about the patient. To begin with - the prediction of disease. What does it mean? This means that the patient comes, as now, donates a piece of saliva or a drop of blood, he is sequenced by DNA and potential problems are found. This is very cool, allows you to know in advance about what you can not find out. Once again I say: all the things related to DNA, sequencing, the processing algorithm of these sequences are also very interesting, there is very strong mathematics. I refer to the link that I gave a dozen slides back. Listen, look - very cool.
Further predictions. Next is the survey recommendation, at about the same level. If we understand that a person has an increased risk of a particular disease, then we can recommend an examination, for example. You can do an ultrasound of the breast or pass on some markers.
Recommendations for a healthy lifestyle. Exactly the same, when you have a box or a smartphone - which most likely - will say: “So, something is all bad, something you have been running for a long time and a lot. Give me some rest. ” Or: “Something in recent times, the pulse has behaved in a strange way. We need to eat carrots, ”- conditionally.
Health monitoring is more for the chronicles. I flipped through a slide with a patch that measures glucose levels. Now, for example, Apple does it with might and main. It seems that non-invasive methods for measuring glucose will be the next huge breakthrough. This is also very important, because a person stabs his finger many times a day, especially if it is a chronicle with diabetes. This is unpleasant, disgusting. If such a plaster is simply pasted somewhere on the arm - in my opinion, this will greatly increase the likelihood that it will not ignore these procedures.
I talked about the good, now a little about the bad.
For a start, sample sizes. Returning to the fact that we still mean big data, I will say: everything is bad with the sample size. If you read a lot of modern research, it is 200-300 measurements. Not to say that this is big data. To educate some normal classifier on 200-300 dimensions is a dubious pleasure, yet more data is needed. And get big data, just take it and say: “I want to do big data in medicine. Give me the data, I will analyze them, ”also fails. Basically, all the studies that are referenced and about which it is said that they are at the forefront of science, are carried out through partnership with some large medical institution. Google partners with the Royal College in London, takes data from them constantly. The same IBM got access to a single medical card in America. It takes a lot of diplomatic efforts, especially in Russia.
What is in Russia? It seems that the most interesting thing we will have in the near future is an electronic medical card. It is currently being developed, implemented. As I have already said, it is being introduced with conditionally variable success. It seems more likely with success than without it. But there are some concerns about implementation. They say: "Let us all cover hundreds of thousands of clinics, medical assistant's points and other things with a single network and structure." That is, with it, as with any large state initiative, there are many problems in terms of the coincidence of data, formats, etc. Even technical problems are not technical — I’m not even talking about organizational ones. Plus, they postulate that there will be access to this data, but, returning to the previous slide, not at all and not immediately. , , . , . , , , .
— , . , , - , c . , , , .
. , Google , . ? , . , , «», — , . , … , 30-40 , . . — , .
. — .
. . . , — , : «, , », . , , . . , - - Kaggle. , , , . — , , — . , - , , : «, — ».
Farther. , . . , . , … , : , - XII , , , . , , , . . , . .
— , , , , , , . . - , , , - .
— . . . — , , , . . , . , , , , , , . . . - . . , — - . , .
— . - , , . , , . . , , , . , — , . , - , , .
— . , — , . . — . , — . -, , - . , .
— . , — , . , . !
Source: https://habr.com/ru/post/330152/
All Articles