Kotlin, bytecode compilation and performance (part 1)
A lot has been said about Kotlin lately (especially in conjunction with the latest news from Google IO 17), but at the same time there is not a lot of such necessary information in which Kotlin is compiled.
Let's take a closer look at the example of compiling to JVM bytecode.
This is the first part of the publication. The second can be found here.
')
The compilation process is quite an extensive topic and in order to better reveal all its nuances, I took most of the compilation examples from Dmitry Zhemerov’s speech: Caught in the Act: Kotlin Bytecode Generation and Runtime Performance . All the benchmarks are taken from the same speech. In addition to reading the publication, I strongly recommend that you also watch his presentation. Some things there are told in more detail. I focus more on the compilation of the language.
Content:
File Level Functions
Primary constructors
data classes
Properties in the class body
Not-null types in public and private methods
Extension functions (extension functions)
Bodies of methods in interfaces
Default arguments
Lambda
But before we consider the basic language constructs and the bytecode they compile, we need to mention how the language itself is directly compiled:
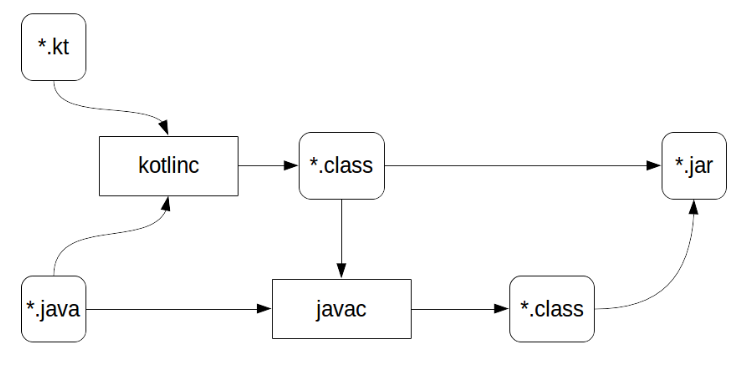
The source files come to the input of the kotlinc compiler, not only the kotlin files, but also the java files. This is necessary so that you can freely reference Java from Kotlin, and vice versa. The compiler itself understands the Java source well, but does not compile them, at this stage only the Kotlin files are compiled. After the received * .class files are transferred to the java compiler along with the source files * .java. At this stage, all java files are compiled, after which it becomes possible to put all the files together in a jar (or in some other way).
In order to see which Kotlin is generated bytecode, you can open a special window in Intellij IDEA from Tools -> Kotlin -> Show Kotlin Bytecode. And after, when opening any * .kt file, its bytecode will be visible in this window. If there is nothing in it that cannot be represented in Java, then the opportunity to decompile it into Java code with the Decompile button will also be available.

If you look at any kotlin * .class file, then there you can see a large @Metadata annotation:
@Metadata( mv = {1, 1, 6}, bv = {1, 0, 1}, k = 1, d1 = {"\u0000\u0014\n\u0002\u0018\u0002\n\u0002\u0010\u0000\n\u0002\b\u0002\n\u0002\u0010\b\n\u0002\b\u0003\u0018\u00002\u00020\u0001B\u0005¢\u0006\u0002\u0010\u0002R\u0014\u0010\u0003\u001a\u00020\u0004X\u0086D¢\u0006\b\n\u0000\u001a\u0004\b\u0005\u0010\u0006¨\u0006\u0007"}, d2 = {"LSimpleKotlinClass;", "", "()V", "test", "", "getTest", "()I", "production sources for module KotlinTest_main"} ) It contains all the information that exists in the Kotlin language and which cannot be represented at the Java bytecode level. For example, information about properties, nullable types, etc. This information does not need to work directly, but the compiler works with it, and it can be accessed using the Reflection API. The metadata format is actually Protobuf with its own declarations.
Dmitry Zhemerov
Let us now turn to examples in which we consider the basic constructions and how they are represented in bytecode. But in order not to understand the cumbersome bytecode entries in most cases, consider the decompiled version in Java:
File Level Functions
Let's start with the simplest example: a function at the file level.
//Kotlin, Example1.kt fun foo() { } Java does not have a similar construction. In bytecode, it is implemented by creating an additional class.
//Java public final class Example1Kt { public static final void foo() { } } The name of the source file with the * Kt suffix (in this case, Example1Kt) is used as the name for this class. It is also possible to change the class name using the annotation file : JvmName:
//Kotlin @file:JvmName("Utils") fun foo() { } //Java public final class Utils { public static final void foo() { } } Primary constructors
In Kotlin, it is possible to declare properties directly in the header of the constructor.
//Kotlin class A(val x: Int, val y: Long) {} They will be the parameters of the constructor, fields will be generated for them and, accordingly, the values passed to the constructor will be written into these fields. A getter will also be created to allow these fields to be read. The decompiled version of the example above will look like this:
//Java public final class A { private final int x; private final long y; public final int getX() { return this.x; } public final long getY() { return this.y; } public A(int x, long y) { this.x = x; this.y = y; } } If in the declaration of class A of variable x change val to var, then setter will be generated. It is also worth noting that class A will be declared with the modifier final and public. This is due to the fact that all classes in Kotlin are by default final and have a public scope.
data classes
Kotlin has a special modifier for the data class.
//Kotlin data class B(val x: Int, val y: Long) { } This keyword tells the compiler to generate the equals, hashCode, toString, copy, and componentN functions for the class. The latter are needed so that the class can be used in destructing declarations. Let's look at the decompiled code:
//Java public final class B { // --- 2 public final int component1() { return this.x; } public final long component2() { return this.y; } @NotNull public final B copy(int x, long y) { return new B(x, y); } public String toString() { return "B(x=" + this.x + ", y=" + this.y + ")"; } public int hashCode() { return this.x * 31 + (int)(this.y ^ this.y >>> 32); } public boolean equals(Object var1) { if(this != var1) { if(var1 instanceof B) { B var2 = (B)var1; if(this.x == var2.x && this.y == var2.y) { return true; } } return false; } else { return true; } } In practice, the data modifier is very often used, especially for classes that participate in the interaction between components or are stored in collections. Also, data classes allow you to quickly create an immotable data container.
Properties in the class body
Properties can also be declared in the class body.
//Kotlin class C { var x: String? = null } In this example, in class C, we declared a property x of type String, which may also be null. In this case, additional @Nullable annotations appear in the code:
//Java import org.jetbrains.annotations.Nullable; public final class C { @Nullable private String x; @Nullable public final String getX() { return this.x; } public final void setX(@Nullable String var1) { this.x = var1; } } In this case, in the decompiled version, we will see getter, setter (since the variable is declared with the var modifier). The @Nullable annotation is necessary so that those static analyzers who understand this annotation can check the code using them and report any possible mistakes.
If we do not need getter and setter, but just need a public field, then we can add the @JvmField annotation:
//Kotlin class C { @JvmField var x: String? = null } Then the resulting Java code will be as follows:
//Java public final class C { @JvmField @Nullable public String x; } Not-null types in public and private methods
In Kotlin, there is a slight difference between what kind of bytecode is generated for public and private methods. Let's look at an example of two methods in which not-null variables are passed.
//Kotlin class E { fun x(s: String) { println(s) } private fun y(s: String) { println(s) } } In both methods, the parameter s of type String is passed, and in both cases this parameter cannot be null.
//Java import kotlin.jvm.internal.Intrinsics; public final class E { public final void x(@NotNull String s) { Intrinsics.checkParameterIsNotNull(s, "s"); System.out.println(s); } private final void y(String s) { System.out.println(s); } } In this case, an additional type check is generated for the public method (Intrinsics.checkParameterIsNotNull), which checks that the passed parameter is really not null. This is done so that public methods can be called from Java. And if null is suddenly passed to them, then this method should fall in the same place, without passing the variable further along the code. This is necessary for early diagnosis of errors. There is no such verification in private methods. From Java it cannot be called just like that, only if through reflection. But with the help of reflection, you can generally break a lot of things if you wish. From Kotlin, the compiler itself monitors calls and will not allow to pass null to such a method.
Such checks, of course, can not affect the performance at all. It is rather interesting to try on how much they worsen it, but it’s hard to do with simple benchmarks. Therefore, we will look at the data that Dmitry Zhemerov managed to get:
Checking parameters for null
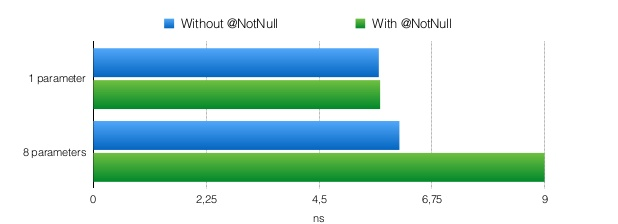
For one parameter, the cost of such a check for NotNull is generally negligible. For a method with eight parameters, which does nothing more than to check for null, it already turns out that there is some appreciable value. But in any case, in ordinary life, this cost (approximately 3 nanoseconds) can be ignored. A more likely situation is that this is the last thing that will have to be optimized in the code. But if you still need to remove unnecessary checks, then at the moment it is possible using the additional options of the kotlinc compiler: -Xno-param-assertions and -Xno-call-assertions (it’s important !: before you turn off the checks, really think the cause of your troubles, and will it not be such that it will do more harm than good)
Extension functions (extension functions)
Kotlin allows you to extend the API of existing classes written not only in Kotlin, but also in Java. For any class, you can write a function declaration, and further in the code, you can use it with this class as if this function was at its declaration.
//Kotlin ( Example6.kt) class T(val i: Int) fun T.foo(): Int { return i } fun useFoo() { T(1).foo() } In Java, a class is generated in which there will simply be a static method with a name, like the extension function. An instance of the extensible class is passed to this method. Thus, when we call the extension function, we actually transfer to the static function the element itself, on which we call the method.
//Java public final class Example6Kt { public static final int foo(@NotNull T $receiver) { Intrinsics.checkParameterIsNotNull($receiver, "$receiver"); return $receiver.getI(); } public static final void useFoo() { foo(new T(1)); } } Almost the entire Kotlin standard library consists of extension functions for the JDK classes. Kotlin has a very small standard library and there is no declaration of its own collection classes. All collections declared via listOf, setOf, mapOf, which in Kotlin look at first glance as their own, are actually ordinary Java collections of ArrayList, HashSet, HashMap. And if you need to transfer such a collection to the library (or from the library), then there is no overhead for converting to its internal classes (as opposed to Scala <-> Java) or copying.
Bodies of methods in interfaces
In Kotlin there is an opportunity to add implementation for methods in interfaces.
//Kotlin interface I { fun foo(): Int { return 42 } } class D : I { } In Java 8, this feature also appeared, but due to the fact that Kotlin should work on Java 6, the resulting code in Java looks like this:
public interface I { int foo(); public static final class DefaultImpls { public static int foo(I $this) { return 42; } } } public final class D implements I { public int foo() { return I.DefaultImpls.foo(this); } } In Java, a standard interface is created, with a method declaration, and the declaration of the DefaultImpls class appears with a default implementation for the desired methods. In the places where methods are used, the call for implementations appears from the class declared in the interface, to the methods of which the object of the call is passed.
The Kotlin team has plans to transition to the implementation of this functionality using the default methods from the Java 8 method, but at the moment there are difficulties with maintaining binary compatibility with already compiled libraries. You can see a discussion of this problem on youtrack . Of course, this does not create a big problem, but if the project is going to create an api for Java, then this feature should be taken into account.
Default arguments
Unlike Java, Kotlin has default arguments. But their implementation is made quite interesting.
//Kotlin ( Example8.kt) fun first(x: Int = 11, y: Long = 22) { println(x) println(y) } fun second() { first() } To implement the default arguments in Java bytecode, a synthetic method is used that passes the mask mask with information about which arguments are missing in the call.
//Java public final class Example8Kt { public static final void first(int x, long y) { System.out.println(x); System.out.println(y); } public static void first$default(int var0, long var1, int mask, Object var4) { if((mask & 1) != 0) { var0 = 11; } if((mask & 2) != 0) { var1 = 22L; } first(var0, var1); } public static final void second() { first$default(0, 0L, 3, (Object)null); } } The only interesting point is why the var4 argument is generated? It itself is not used anywhere, and null is passed in places of use. I did not find the information on the purpose of this argument, maybe yole can clarify the situation.
The following are estimates of the cost of such manipulations:
Default arguments

The cost of the default arguments is already becoming slightly noticeable. But still, losses are measured in nanoseconds and during normal operation such losses can be neglected. There is also a way to force the Kotlin compiler to generate default arguments in bytecode. To do this, add the @JvmOverloads annotation:
//Kotlin @JvmOverloads fun first(x: Int = 11, y: Long = 22) { println(x) println(y) } In this case, in addition to the methods from the previous example, the first method overloads will be generated for various options for passing arguments.
//Java public final class Example8Kt { //-- first, second, first$default @JvmOverloads public static final void first(int x) { first$default(x, 0L, 2, (Object)null); } @JvmOverloads public static final void first() { first$default(0, 0L, 3, (Object)null); } } Lambda
Lambda in Kotlin are presented almost as well as in Java (except that they are first class objects)
//Kotlin ( Lambda1.kt) fun <T> runLambda(x: ()-> T): T = x() In this case, the runLambda function takes an instance of the Function0 interface (whose declaration is in the Kotlin standard library), which has the invoke () function. And accordingly, this is all compatible with the way it works in Java 8, and, of course, SAM conversion from Java works. The resulting bytecode will look like this:
//Java public final class Lambda1Kt { public static final Object runLambda(@NotNull Function0 x) { Intrinsics.checkParameterIsNotNull(x, "x"); return x.invoke(); } } Compiling to bytecode strongly depends on whether the value is captured from the surrounding context or not. Consider an example when there is a global variable value and lambda, which simply returns its value.
//Kotlin ( Lambda2.kt) var value = 0 fun noncapLambda(): Int = runLambda { value } In Java, in this case, in essence, a singleton is created. Lambda itself does not use anything from the context and, accordingly, it is not necessary to create different instances for all calls. Therefore, a class that implements the Function0 interface is simply compiled, and, as a result, the call to the lambda occurs without allocation and is very cheap.
//Java final class Lambda2Kt$noncapLambda$1 extends Lambda implements Function0 { public static final Lambda2Kt$noncapLambda$1 INSTANCE = new Lambda2Kt$noncapLambda$1() public final int invoke() { return Lambda2Kt.getValue(); } } public final class Lambda2Kt { private static int value; public static final int getValue() { return value; } public static final void setValue(int var0) { value = var0; } public static final int noncapLambda() { return ((Number)Lambda1Kt.runLambda(Lambda2Kt$noncapLambda$1.INSTANCE)).intValue(); } } Consider another example using local variables with contexts.
//Kotlin ( Lambda3.kt) fun capturingLambda(v: Int): Int = runLambda { v } In this case, singleton is not enough, since each specific lambda instance must have its own parameter value.
//Java public static final int capturingLambda(int v) { return ((Number)Lambda1Kt.runLambda((Function0)(new Function0() { public Object invoke() { return Integer.valueOf(this.invoke()); } public final int invoke() { return v; } }))).intValue(); } Lambda in Kotlin are also able to change the value of non-local variables (unlike Java lambda).
//Kotlin ( Lambda4.kt) fun mutatingLambda(): Int { var x = 0 runLambda { x++ } return x } In this case, a wrapper is created for the variable being changed. The wrapper itself, similarly to the previous example, is transferred to the newly created lambda, inside of which the change of the initial variable takes place through the call to the wrapper.
public final class Lambda4Kt { public static final int mutatingLambda() { final IntRef x = new IntRef(); x.element = 0; Lambda1Kt.runLambda((Function0)(new Function0() { public Object invoke() { return Integer.valueOf(this.invoke()); } public final int invoke() { int var1 = x.element++; return var1; } })); return x.element; } } Let's try to compare the performance of solutions on Kotlin, with counterparts in Java:
Lambda

As you can see, the fussing with wrappers (the last example) takes considerable time, but, on the other hand, in Java this is not supported out of the box, and if you make such an implementation with your hands, then the costs will be similar. The rest of the difference is not so noticeable.
Also in Kotlin there is an opportunity to transfer references to methods (method reference) in lambdas, and they, unlike lambdas, store information about what the methods indicate. References to methods are compiled in a similar way to what lambdas look like without capturing context. It creates a singleton, which in addition to the value still knows what this lambda refers to.
Lambda in Kotlin has another interesting feature: they can be declared with the inline modifier. In this case, the compiler will find all the places where the function is used in the code and replace them with the function body. JIT also knows how to inline some things on its own, but you can never be sure that it will inline and what it will miss. Therefore, to have your own controlled inline mechanism never hurts.
//Kotin ( Lambda5.kt) fun inlineLambda(x: Int): Int = run { x } //run : public inline fun <R> run(block: () -> R): R = block() //Java public final class Lambda5Kt { public static final int inlineLambda(int x) { return x; } } In the example above, no allocation takes place, no calls. In essence, the function code simply “collapses”. This allows you to very effectively implement all sorts of filter, map, etc. The same synchronized statement is also inline.
Continued in part 2
Thanks for attention!
I hope you enjoyed the article. I ask all those who have noticed any errors or inaccuracies to write about it to me in a personal message.
Source: https://habr.com/ru/post/330060/
All Articles