Cisco CSR 1000v: Reliability - the key to success. Part 2
In our previous article on the virtualization router CSR 1000v from Cisco Systems, we tried to describe the main features of this great product in the simplest and most concise manner. The ideology of such decisions (and this, in particular) is, in fact, very simple and effective, because virtual performance allows you to use and maximize utilize existing computing power. And, if we consider that the target field of application of CSR is a cloud infrastructure, then there should be enough resources for its work. At the same time, the flexibility of using such a “device” increases, since it can be used on the borders of virtual networks. However, in this article I would like to talk about how to maximize network reliability, minimize or even reduce to zero the possible downtime and prevent the emergence of a single point of failure even for a small group of virtual machines.

The resiliency tools in our particular case can be divided into the following three small groups:
1. Mechanisms to ensure fault tolerance of the hypervisor.
2. Default Gateway Failover Protocols (FHRP - First Hop Redundancy Protocol).
3. Clustering mechanisms available in the router's OS.
')
The first group was briefly mentioned in the previous article. In our case, when working with VMware virtualization, there are 2 options: High Availability (HA) and Fault Tolerance (FT). They differ from each other by different consequences if the host on which the active virtual machine (hereinafter VM) was running failed. In the case of HA, the VM will restart on another host; when the functional FT is in operation, the shadow copy of the VM running in parallel on the other host becomes active. Accordingly, for HA, the possible downtime will be from 5 minutes depending on other factors (whether the VM started up on another host, if there were enough computing resources, whether the CSR configuration was saved, whether there are backup copies). If we talk about VMware FT, then the simple will be invisible. However, FT is not applicable in many scenarios, since It requires hardware compatibility of servers where VM copies work, in terms of processor instruction sets, and also has limitations in terms of bandwidth and increases network latency. Below are a number of examples of how FT is affected by various conditions.
The figure below shows how FT affects the throughput of a virtual machine (VM) for a 1 Gbps network.

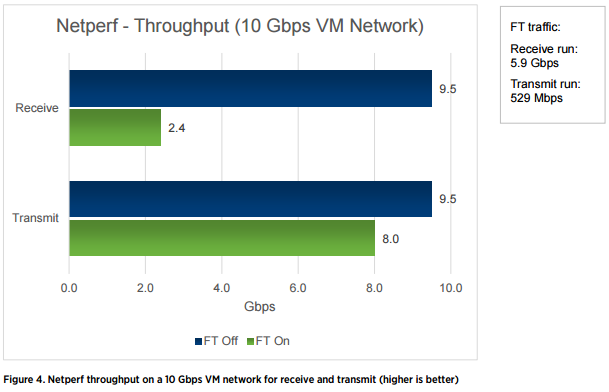
The following figure is the same indicator, only, for 10 Gbit / s.
And this is how the delay increases when the FT is turned on for the virtual machine.
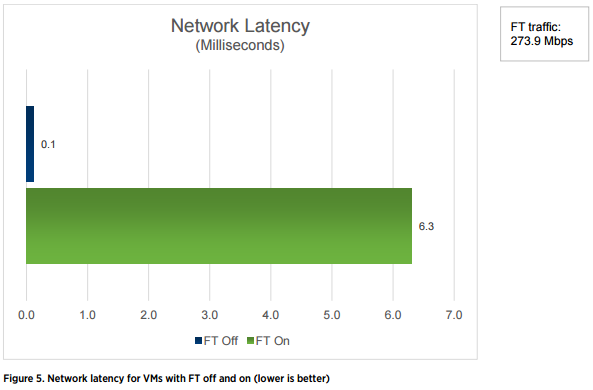
From this we can conclude that FT can be used not for all services, but only for those that are not demanding on the network characteristics (bandwidth, delay, jitter, etc.). For a CSR 1000v, as for a network device, any negative impact on network performance is undesirable.
We turn to the second group of resiliency tools. Next, according to our plan, we have a family of default gateway fault tolerance protocols (FHRP - First Hop Redundancy Protocol). As we know, in the context of Cisco equipment, there are only three main representatives of this group: VRRP, HSRP and GLBP. It is worth noting immediately that this group of protocols provides only fault-tolerant and relatively continuous “user experience”, that is, it provides redundancy and active load switching (or balancing), but does not have a number of other advantages, such as a single control point in the case of methods from group 1.
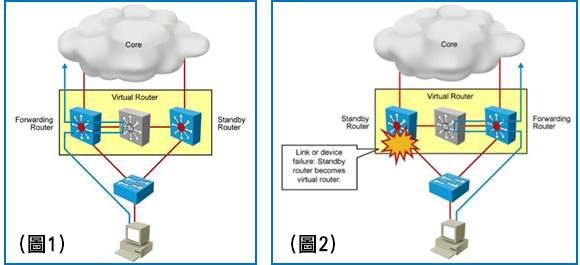
We will not dwell on this group of solutions, since Information on the specified protocols in excess is contained in the official Cisco documentation. Let me just say briefly that VRRP and HSRP imply the presence of one active “device” (not necessarily physical, because you can configure a separate group for each interface) that transfers data and one or more in standby mode. GLBP is different in that it involves balancing between interfaces that are in the same group.
It is worth noting that for FHRP protocols to work correctly in a virtual environment, that is, when using CSR 1000v, you need to set the “MAC address changes”, “Forged transmissions” and “Promiscuous mode” parameters in the security settings for the virtual switch port group to “Accept” ". This is required because the work of these protocols is working with a virtual MAC address, which actually results in the use of several MAC addresses by the virtual machine, and this is not allowed by default.
Also, I will say a few words about performance. The use of the FHRP family of protocols does not significantly affect the network performance and CPU utilization of the router. The capacity is also not affected.
So, finally, we turn to the last group - “clustering”. By this word, in this article, we will understand the mechanism for ensuring fault tolerance, implemented in IOS XE under the name High Availability, or, to be precise, Firewall Box to Box High Availability.
Support for this mechanism appeared in Cisco IOS XE Release 3.14S software. The advantages of this technology are fast convergence (failure detection) and synchronization of NAT and Firewall states. Detailed information about the settings is better to peep in the Cisco documentation here . To work with this functionality, a technological license package of Security or AX level is required and we do not forget about the security settings of the port group of the virtual switchboard, similar to FHRP.
The solution architecture is as follows:
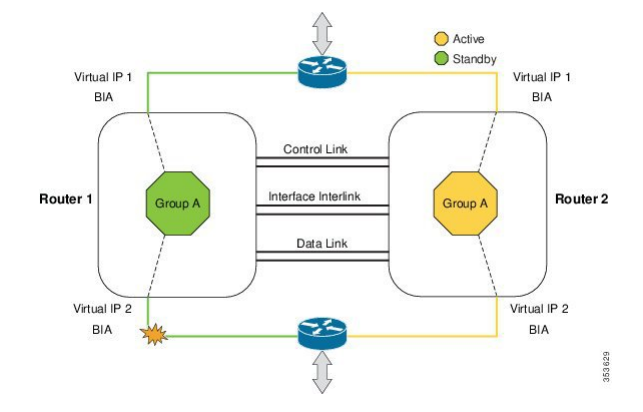
Actually, this concludes a brief overview of the tools to improve fault tolerance regarding the application for the Cisco CSR 1000v in a virtual environment based on VMware. For some, the information will not be new, but someone, I hope, will find in it something new and useful for themselves. Do not judge strictly and use the appropriate tools to protect your services. Thank!
The resiliency tools in our particular case can be divided into the following three small groups:
1. Mechanisms to ensure fault tolerance of the hypervisor.
2. Default Gateway Failover Protocols (FHRP - First Hop Redundancy Protocol).
3. Clustering mechanisms available in the router's OS.
')
The first group was briefly mentioned in the previous article. In our case, when working with VMware virtualization, there are 2 options: High Availability (HA) and Fault Tolerance (FT). They differ from each other by different consequences if the host on which the active virtual machine (hereinafter VM) was running failed. In the case of HA, the VM will restart on another host; when the functional FT is in operation, the shadow copy of the VM running in parallel on the other host becomes active. Accordingly, for HA, the possible downtime will be from 5 minutes depending on other factors (whether the VM started up on another host, if there were enough computing resources, whether the CSR configuration was saved, whether there are backup copies). If we talk about VMware FT, then the simple will be invisible. However, FT is not applicable in many scenarios, since It requires hardware compatibility of servers where VM copies work, in terms of processor instruction sets, and also has limitations in terms of bandwidth and increases network latency. Below are a number of examples of how FT is affected by various conditions.
The figure below shows how FT affects the throughput of a virtual machine (VM) for a 1 Gbps network.
The following figure is the same indicator, only, for 10 Gbit / s.
And this is how the delay increases when the FT is turned on for the virtual machine.
From this we can conclude that FT can be used not for all services, but only for those that are not demanding on the network characteristics (bandwidth, delay, jitter, etc.). For a CSR 1000v, as for a network device, any negative impact on network performance is undesirable.
We turn to the second group of resiliency tools. Next, according to our plan, we have a family of default gateway fault tolerance protocols (FHRP - First Hop Redundancy Protocol). As we know, in the context of Cisco equipment, there are only three main representatives of this group: VRRP, HSRP and GLBP. It is worth noting immediately that this group of protocols provides only fault-tolerant and relatively continuous “user experience”, that is, it provides redundancy and active load switching (or balancing), but does not have a number of other advantages, such as a single control point in the case of methods from group 1.
We will not dwell on this group of solutions, since Information on the specified protocols in excess is contained in the official Cisco documentation. Let me just say briefly that VRRP and HSRP imply the presence of one active “device” (not necessarily physical, because you can configure a separate group for each interface) that transfers data and one or more in standby mode. GLBP is different in that it involves balancing between interfaces that are in the same group.
It is worth noting that for FHRP protocols to work correctly in a virtual environment, that is, when using CSR 1000v, you need to set the “MAC address changes”, “Forged transmissions” and “Promiscuous mode” parameters in the security settings for the virtual switch port group to “Accept” ". This is required because the work of these protocols is working with a virtual MAC address, which actually results in the use of several MAC addresses by the virtual machine, and this is not allowed by default.
Also, I will say a few words about performance. The use of the FHRP family of protocols does not significantly affect the network performance and CPU utilization of the router. The capacity is also not affected.
So, finally, we turn to the last group - “clustering”. By this word, in this article, we will understand the mechanism for ensuring fault tolerance, implemented in IOS XE under the name High Availability, or, to be precise, Firewall Box to Box High Availability.
Support for this mechanism appeared in Cisco IOS XE Release 3.14S software. The advantages of this technology are fast convergence (failure detection) and synchronization of NAT and Firewall states. Detailed information about the settings is better to peep in the Cisco documentation here . To work with this functionality, a technological license package of Security or AX level is required and we do not forget about the security settings of the port group of the virtual switchboard, similar to FHRP.
The solution architecture is as follows:
Actually, this concludes a brief overview of the tools to improve fault tolerance regarding the application for the Cisco CSR 1000v in a virtual environment based on VMware. For some, the information will not be new, but someone, I hope, will find in it something new and useful for themselves. Do not judge strictly and use the appropriate tools to protect your services. Thank!
Source: https://habr.com/ru/post/330038/
All Articles