New architecture of Android applications - we try in practice
Hello. At the last Google I / O, we were finally presented with Google’s official vision of the architecture of Android applications, as well as libraries for its implementation. Less than ten years. Of course, I immediately wanted to try what is offered there.
Beware: libraries are in alpha version, therefore we can expect changes breaking compatibility.
Lifecycle
The main idea of the new architecture is the maximum removal of logic from activations and fragments. The company claims that we must consider these components as belonging to the system and not belonging to the developer’s area of responsibility. The idea itself is not new, MVP / MVVP is already actively used at present. However, interconnection with the life cycles of components has always remained on the conscience of developers.
Now it is not. We are presented with the new android.arch.lifecycle package, which contains the Lifecycle , LifecycleActivity, and LifecycleFragment classes. In the near future, it is assumed that all components of the system that live in a certain life cycle will provide Lifecycle through the implementation of the LifecycleOwner interface:
public interface LifecycleOwner { Lifecycle getLifecycle(); } Since the package cannot be mixed with the stable version in the alpha version and its API, the LifecycleActivity and LifecycleFragment classes have been added. After the package is transferred to a stable state, LifecycleOwner will be implemented in Fragment and AppCompatActivity, and LifecycleActivity and LifecycleFragment will be removed.
The lifecycle contains the current state of the component life cycle and allows LifecycleObserver to subscribe to life cycle transition events. Good example:
class MyLocationListener implements LifecycleObserver { private boolean enabled = false; private final Lifecycle lifecycle; public MyLocationListener(Context context, Lifecycle lifecycle, Callback callback) { this.lifecycle = lifecycle; this.lifecycle.addObserver(this); // - } @OnLifecycleEvent(Lifecycle.Event.ON_START) void start() { if (enabled) { // } } public void enable() { enabled = true; if (lifecycle.getState().isAtLeast(STARTED)) { // , // } } @OnLifecycleEvent(Lifecycle.Event.ON_STOP) void stop() { // } } Now we just need to create a MyLocationListener and forget about it:
class MyActivity extends LifecycleActivity { private MyLocationListener locationListener; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); locationListener = new MyLocationListener(this, this.getLifecycle(), location -> { // , , }); // - Util.checkUserStatus(result -> { if (result) { locationListener.enable(); } }); } } Livedata
LiveData is an analogue of Observable in rxJava, but aware of the existence of the Lifecycle. LiveData contains a value, each change of which comes to the browsers.
Three main LiveData methods:
setValue () - change the value and notify the browsers;
onActive () - at least one active observer has appeared;
onInactive () - no more active browsers.
Therefore, if LiveData does not have active browsers, you can stop updating the data.
An active observer is one whose Lifecycle is in the STARTED or RESUMED state. If a new active observer joins LiveData, it immediately gets the current value.
This allows you to store an instance of LiveData in a static variable and subscribe to it from UI components:
public class LocationLiveData extends LiveData<Location> { private LocationManager locationManager; private SimpleLocationListener listener = new SimpleLocationListener() { @Override public void onLocationChanged(Location location) { setValue(location); } }; public LocationLiveData(Context context) { locationManager = (LocationManager) context.getSystemService( Context.LOCATION_SERVICE); } @Override protected void onActive() { locationManager.requestLocationUpdates(LocationManager.GPS_PROVIDER, 0, 0, listener); } @Override protected void onInactive() { locationManager.removeUpdates(listener); } } Let's make the usual static variable:
public final class App extends Application { private static LiveData<Location> locationLiveData = new LocationLiveData(); public static LiveData<Location> getLocationLiveData() { return locationLiveData; } } And we will subscribe to a location change, for example, in two activations:
public class Activity1 extends LifecycleActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity1); getApplication().getLocationLiveData().observe(this, (location) -> { // do something }) } } public class Activity2 extends LifecycleActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity2); getApplication().getLocationLiveData().observe(this, (location) -> { // do something }) } } Notice that the observe method takes the first parameter of LifecycleOwner, thereby associating each subscription with the lifecycle of a specific activity.
As soon as the life cycle of the activation goes into the DESTROYED subscription is destroyed.
The advantages of this approach are: there is no spaghetti from the code, there are no memory leaks and the handler will not be called for a dead activit.
Viewmodel
ViewModel is a data store for a UI that can survive the destruction of a UI component, for example, a configuration change (yes, MVVM is now the officially recommended paradigm). The newly created activation reconnects to the previously created model:
public class MyActivityViewModel extends ViewModel { private final MutableLiveData<String> valueLiveData = new MutableLiveData<>(); public LiveData<String> getValueLiveData() { return valueLiveData; } } public class MyActivity extends LifecycleActivity { MyActivityViewModel viewModel; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity); viewModel = ViewModelProviders.of(this).get(MyActivityViewModel.class); viewModel.getValueLiveData().observe(this, (value) -> { // }); } } The parameter of the method determines the scope of the model instance. That is, if the same value is passed in of, then the same instance of the class will return. If there is no instance yet, it will be created.
As a scope, you can pass not just a link to yourself, but something more cunning. Currently, three approaches are recommended:
- activates itself;
- the fragment transfers itself;
- The fragment transmits its activation.
The third method allows you to organize data transfer between fragments and their activation through a common ViewModel. That is, it is no longer necessary to make any arguments for the fragments and special interfaces for the activation. Nobody knows anything about each other.
After the destruction of all components to which the model instance is attached, the onCleared event is triggered and the model is destroyed.
Important point: since the ViewModel generally does not know how many components the same model instance uses, we should not in any case keep a reference to the component inside the model.
Room Persistence Library
Our happiness would be incomplete without the ability to save data locally after the application’s untimely death. And here SQLite available out of the box is in a hurry. However, the database API is rather inconvenient, mainly because it does not provide a way to check the code during compilation. We learn about typos in SQL expressions when the application is executed and it’s good, if not from the client.
But this remained in the past - Google presented us an ORM library with static analysis of SQL expressions during compilation.
We need to implement at least three components: Entity , DAO, and Database .
An entity is one entry in the table:
@Entity(tableName = «users») public class User() { @PrimaryKey public int userId; public String userName; } DAO (Data Access Object) - a class that encapsulates work with records of a specific type:
@Dao public interface UserDAO { @Insert(onConflict = REPLACE) public void insertUser(User user); @Insert(onConflict = REPLACE) public void insertUsers(User… users); @Delete public void deleteUsers(User… users); @Query(«SELECT * FROM users») public LiveData<List<User>> getAllUsers(); @Query(«SELECT * FROM users WHERE userId = :userId LIMIT 1») LiveData<User> load(int userId); @Query(«SELECT userName FROM users WHERE userId = :userId LIMIT 1») LiveData<String> loadUserName(int userId); } Note the DAO interface, not the class. Its implementation is generated at compilation.
The most amazing thing, in my opinion, is that the compilation falls if an expression is sent to Query that refers to non-existing tables and fields.
As an expression in Query, you can pass, including table joins. However, the Entity themselves cannot contain field-references to other tables, this is due to the fact that lazy (lazy) data loading when accessing them will start in the same stream and surely it will turn out to be a UI-stream. Therefore, Google has decided to ban this practice completely.
It is also important that as soon as any code changes an entry in the table, all LiveData, including this table, transmit the updated data to their observers. That is, the database in our application is now "ultimate truth." This approach allows you to finally get rid of the inconsistency of data in different parts of the application.
Not only that, Google promises us that in the future, change tracking will be executed line by line, and not as it is now.
Finally, we need to set the database itself:
@Database(entities = {User.class}, version = 1) public abstract class AppDatabase extends RoomDatabase { public abstract UserDAO userDao(); } It also uses code generation, so we write the interface, not the class.
Create a singleton base in the Application class or in the Dagger module:
AppDatabase database = Room.databaseBuilder(context, AppDatabase.class, "data").build(); We get DAO from it and you can work:
database.userDao().insertUser(new User(…)); At the first access to the DAO methods, the automatic creation / re-creation of the tables is performed or the SQL scripts for updating the schema are executed, if specified. Schema update scripts are specified using Migration objects:
AppDatabase database = Room.databaseBuilder(context, AppDatabase.class, "data") .addMigration(MIGRATION_1_2) .addMigration(MIGRATION_2_3) .build(); static Migration MIGRATION_1_2 = new Migration(1, 2) { @Override public void migrate(SupportSQLDatabase database) { database.execSQL(…); } } static Migration MIGRATION_2_3 = new Migration(2, 3) { … } Plus, don't forget to specify the current version of the schema in the annotation from AppDatabase.
Of course, the SQL schema update scripts should be just strings and should not rely on external constants, since after some time the table classes will change significantly, and old DB versions should still be updated without errors.
At the end of the execution of all scripts, an automatic check is performed for the correspondence between the base and the Entity classes, and Exception is thrown if there is a mismatch.
Caution: If it was not possible to create a chain of transitions from the actual version to the last, the base is deleted and recreated.
In my opinion, the algorithm for updating the scheme has flaws. If you have an outdated database on your device, it will be updated, everything is fine. But if there is no database, and the required version is> 1 and some Migration set is specified, the database will be created based on Entity and Migration will not be executed.
We are kind of hinting that in Migration there can only be changes in the structure of tables, but not filling them with data. This is regrettable. I guess we can expect improvements to this algorithm.
Pure architecture
All of the above entities are building blocks of the proposed new application architecture. It should be noted, Google does not write clean architecture anywhere, this is a certain liberty on my part, but the idea is similar.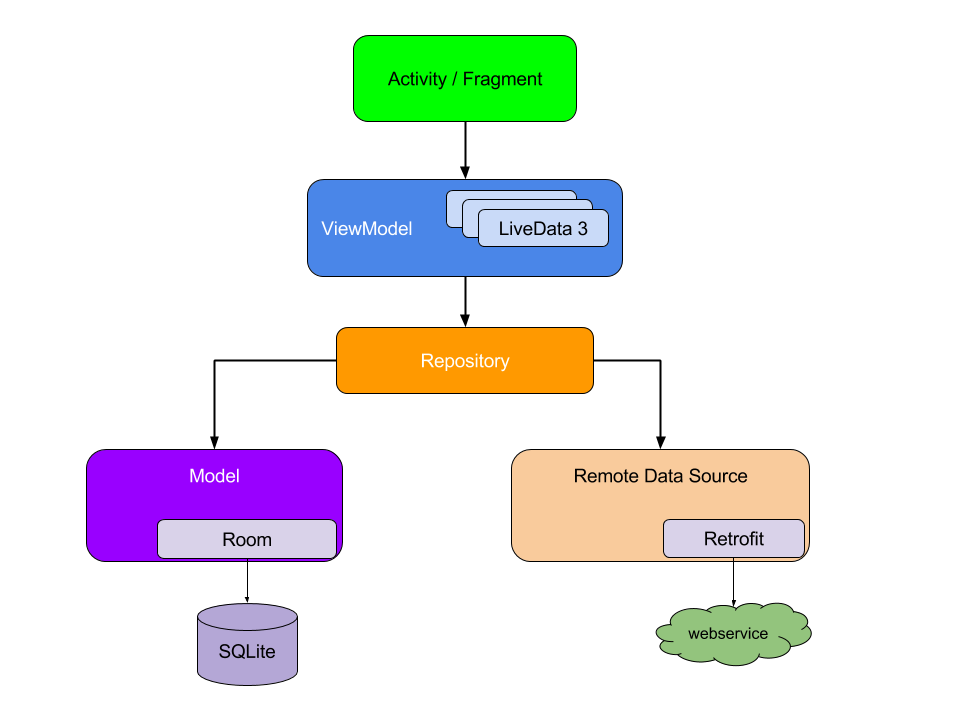
No entity knows anything about the entities above it.
Model and Remote Data Source are responsible for storing data locally and querying them over the network, respectively. Repository manages caching and combines individual entities in accordance with business tasks. The Repository classes are just some kind of abstraction for developers, no special base class Repository exists. Finally, the ViewModel integrates different Repository in a form suitable for a particular UI.
Data between layers is transmitted via LiveData subscriptions.
Example
I wrote a small demo application. It shows the current weather in a number of cities. For simplicity, the list of cities is set in advance. The data provider is the OpenWeatherMap service.
We have two fragments: with a list of cities (CityListFragment) and with the weather in the selected city (CityFragment). Both fragments are in the MainActivity.
Activations and fragments use the same MainActivityViewModel.
MainActivityViewModel requests data from WeatherRepository.
WeatherRepository returns old data from the database and immediately initiates a request for updated data over the network. If the updated data is successfully received, it is saved to the database and updated by the user on the screen.
To work correctly, you must register the API key in WeatherRepository. The key can be taken free of charge after registering with the OpenWeatherMap.
Repository on github .
Innovations look very interesting, but the impulse to redo everything is still worth it. Do not forget that this is only alpha.
Comments and suggestions are welcome. Hooray!
')
Source: https://habr.com/ru/post/329990/
All Articles