How many technologies does Yandex need for a search to find fresh documents almost instantly
Over the past year, Yandex has made significant progress in the quality of searches for queries that require the issuance of relevant documents. Now popular documents for the most part fall into the search results for relevant queries almost immediately after publication.

This is not easy to achieve, because the addition of newly created documents to search results, as a rule, contradicts other important user metrics: relevance, authority, etc. Today we have decided for the first time to talk about the basic technologies that allow to use fresh documents in the Search.
1. Why freshness?
The interest in any event within a few days fades to almost zero, unless, of course, this event receives any further development. We conducted a study from which this statement was born: it turns out that, on average, 73% of users are interested in an event directly on the day it happened, and only 3% of readers come to resources three days or more after publication. Many years have passed since the conduct of this study, but in general the situation has not changed. And even articles on habrahabr.ru receive the largest number of search transitions in the first few days of their existence.
Freshly demonstrated freshness is an important feature not only for web search. Freshness is also needed in the search for pictures and videos, search prompts; Of course, in the news aggregators and the media. What is really there: even in the cinema, in most situations we go to a new film, and not to a long time ago!
The importance of refreshing search results for the search engine is difficult to overestimate. In order to achieve good freshness, you need to solve many problems: to build a content system that finds and adds new documents to the index in real time, learn how to predict which users need to show fresh documents for which requests, determine the best of these documents. Of course, all these tasks are solved using machine learning methods.
This article describes some of our approaches to solving these problems. And on the eighth of June, our office will host a meeting of Yandex from the inside , at which, among other things, there will be a report on freshness. We will consider the most difficult of the problems that arise - the task of speeding up the reaction to current events. Sign up for an event at this link .
1.1. How to understand that freshness is needed
In one way or another, freshness is needed in 10-20% of the requests that users specify in Yandex.
First of all, this "event" requests. When something happens in the world, users come to Search to find out the details of the event. Different events are quite different from each other both in terms of user interest, and in terms of the necessary development.
Consider, for example, a graph of the number of clicks on fresh documents during the elections in September 2016:
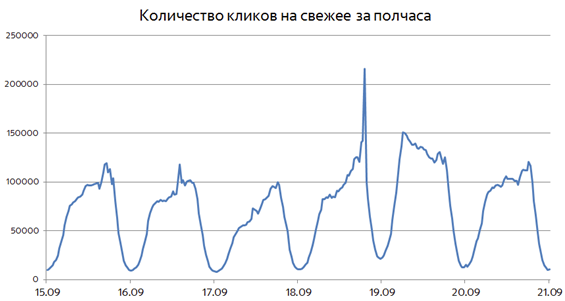
It is clearly seen that on election day, the need for fresh gradually increased until it reached its peak at 22:00. The next day, an increased interest in fresh was maintained, but after a day returned to about normal values. In other words, the interest in an event changes over time. Therefore, the first idea, useful for determining the need for fresh - “if some requests suddenly start asking more often, probably something happened, and users should show fresh documents”. The considered situation is also interesting for one more reason: we forecasted the interest in the fresh, because the election date was known long before they were held.
It so happens that the events are greatly stretched in time. An example of such an event is the 2016 Olympics: during all competitions, users almost twice as often consumed fresh documents than it does on ordinary days:
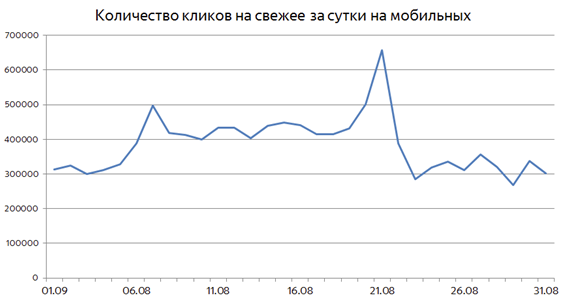
In such situations, it is no longer possible to detect interest in freshness, based on a sharp surge in the frequency of requests of a certain subject. Here another method may come to the rescue: if users really need freshness for some requests, they may need it in the near future.
The situation when something unexpected happens is quite different. Unexpected resonant events are usually not associated with anything good, so just look at the charts without reference to dates and specific incidents:
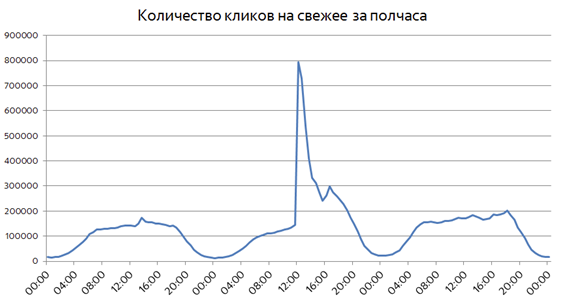
Already in the first half hour after the event, the user interest in fresh grows by almost an order of magnitude. The share of fresh requests among all requests in the Search at such moments may increase to 25%. Unexpected events are well detected by a sharp burst of user interest, but such bursts need to be detected within a few minutes after the occurrence. We have already talked about the Real Time MapReduce technology, which allows Yandex to process search logs and deliver the results of calculations to Real-time Search.
1.2. How Freshness is Presented in Yandex Search
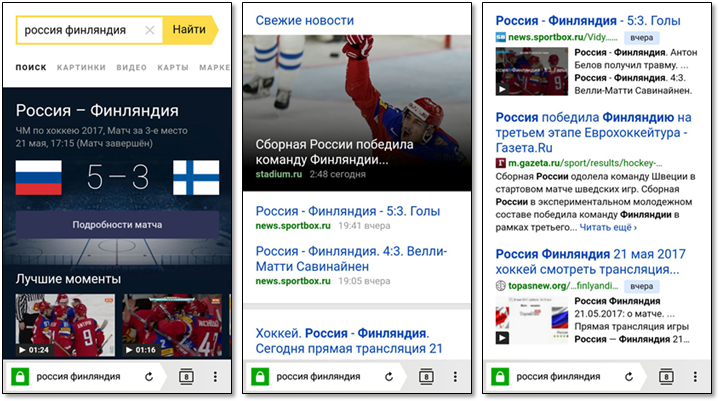
Now we will talk about how fresh results are presented in search results. Consider the query “Russia Finland”, set on May 22, 2017. This query is indicative, because when responding to it, the Search shows almost all the functional elements associated with the processing of fresh requests.
Since sports inquiries account for a significant proportion of fresh requests, we provide information on sports matches in a special way. The user can find out the date and time of the start of the match, the score; Sometimes we know a link to a live broadcast or video of interesting moments.
We specifically group the results from news sources, seeking greater attractiveness.
For other cases, we restrict ourselves to standard search snippets, to which we add color dies with the age of the document. Sometimes we know that the document contains a video, and we add a preview to the snippet.
2. How Freshness gets into search results
2.1. Wide pFound model
Fresh documents are mixed into the output of the wide pFound model. This model was at one time proposed for the task of search results diversity, you can look at the corresponding yafinder report on YaC'2011 dedicated to this: https://events.yandex.ru/lib/talks/12/ . It turned out that the model is suitable for a wider range of tasks, in particular, for mixing up fresh results.
In this model, we assume that the user, by specifying a specific search query, means one of the intents (interests, topics, ...). For example, by asking for a jaguar, the user may mean a car, drink, or animal. The query "seals" may suggest the need for relevant pictures, videos, or just articles. The request "Eurovision" in certain moments certainly requires the most relevant (fresh!) News about the course of the competition or preparation for it, in others the more likely need is the Wikipedia page with a list of the winners of previous years. Among intents, special emphasis should be emphasized, which we denote - this is the “all else” intent, which corresponds to the usual organic issue.
The task of a search engine is to select for each user and his query a set of suitable intents, and then correctly compile the output from the documents relevant to these intents. In the wide pFound model, we believe that each of the intentions corresponds to a certain weight, denoting the probability of user interest to this particular intention, and for each document on issue, the vector of its relevance for all considered intents is known. Then, for each intent, it is possible to calculate the pFound metric - the probability that our output responds to the user's request, if he meant this particular intent. Wide pFound is a metric equal to the sum of weighted pFound intensities for each of the intents:
Where - the probability to find the relevant document in the issue, if the user had in mind th intent.
Let, for example, on some query, the weight of the freshness intensity be 0.9, and the relevance of the documents correspond to the following table.
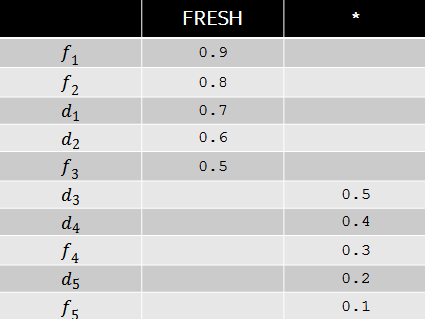
Then, from the point of view of wide pFound, the rearrangement of documents shown in the table below will be optimal. Despite the fact that the relevance of fresh documents in this case is greater, in terms of diversity it is advantageous to put ordinary documents in third and fourth positions, since fresh intent is already highly satisfied with the first two results. As we see, the wide pFound model represents some approach to forming search results from disparate sources, and the task is reduced to determining the weights of the intents and the relevance of documents to these intents.
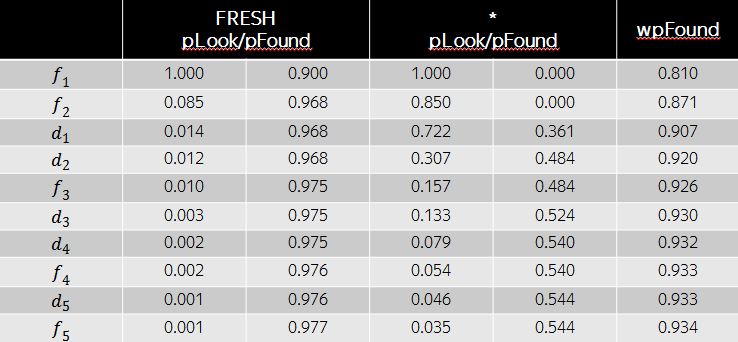
Historically, in Freshness we call the task of determining the weight of fresh intent the task of detecting fresh . The second task is the standard task of ranking documents, in our case fresh ones.
2.2. Click training
The set of documents intended for fresh rankings is changing by the minute: new documents appear, old ones disappear. Because of this, difficulties arise with the use of estimates obtained in the past, since and the factors and scores of documents change over time. For example, at 12:00 pm, the news that somewhere there was a fire may be relevant, and at 14:00 it will not, because the fire has already been localized by that time. Therefore, in order to assess the relevance of a fresh issue at 14:00, one cannot manage to evaluate only new documents: it is necessary to revise the relevance of absolutely all fresh documents on issue.
Because of this, it turns out to be difficult to have a large, up-to-date, valued set of “request-document” marked up pairs in the fresh ranking. A breakthrough as a fresh ranking was achieved when we learned to use additional sources of information for training. The main one is the user signal, clicks on search results.
2.2.1. Training on clicks in ranking
In most cases, fresh documents are not shown in the first position in the issue, so even to train the simplest classifier that predicts the clickability of a fresh document in the first position is not so easy. It’s also impossible to compare neighboring fresh documents: an arbitrarily large number of documents from other sources can be located between the first and second documents of freshness. Therefore, many of the approaches used for click training in traditional rankings do not work at all for freshness. We use other methods.

Imagine an issue containing four ordinary documents and three fresh ones, with the clicks occurring on the first fresh and last ordinary documents.
It can be assumed that the document preferable to documents and but compare and between themselves is already quite difficult. But, for example, we can assume that still better, because the current ranking formula prefers it.
Therefore, you can create a sample in several different ways:
- For the problem of pairwise classification: we will teach the formula to prefer the document documents and .
- For the problem of pointwise classification or regression: assigned to the positive class , and to the negative - and .
- For the ranking task: we require the formula to restore order .
Of course, you can come up with other ways to form training samples. This is a creative and very exciting process.
2.2.2. Training on clicks in detection
Let us consider two learning patterns for detecting fresh ones by clicks that we used at different times. Each of these schemes solves the problem of the so-called contextual multi-armed bandits . The context in this case are the factors calculated by the user query. Among those related to freshness, it would make sense to mention a few: “contrast” of the request (for example, the ratio of the frequency of the request for the last day to its frequency for the last week), the number of news written recently on this topic, the CTR of freshness on request and so on.
Click information can be collected in several ways. For example, you can use user clicks on all the latest documents: if there is a fresh click, then you need to back up the detector's prediction, because the triggering was appropriate. This is a very attractive way, but in practical application it faces a number of difficulties. The sample turns out to be strongly biased towards the positives of the current formula, and in some cases it is very difficult to understand what the magnitude of reinforcement should be. For example, if freshness was shown low and there were no clicks, this can be evidence of both a lack of interest in fresh (and in this case, the weight of the intensity must be reduced), and too low a position (and in this case, the weight of the intensity must be increased).
You can use a special experiment in which freshness is shown on "random" positions. The freshness intent is a number from zero to one, which can be chosen from a small set — say, multiples of 0.05. Then the task is reduced to the choice of one of 21 different values. This is the problem of multi-armed bandits. The response to our choice will be some user behavior on the issue - for example, a click on a result, and the machine learning task will be formulated in terms of choosing the value of the intensity of freshness, for which the probability of this response is maximum. This method gives very good results, but it has one significant drawback: the very procedure for collecting a click signal greatly worsens the output for users, because most fresh hits are irrelevant.
If there is already some formula detection of freshness - selected by assessor estimates or by the method described above - then its value can be changed by a small random variable, and then the optimum value of the change in its prediction can be predicted in the same way as above. More specifically, we assume that on the current query the formula predicts the weight of the intent. . Add to this weight a small random supplement: where - value from a small discrete set of values. For example, . Then you can train the formula , which will predict the optimal value of the additive, and use the sum of two as the new formula: .
This method allows you to modify the values of the current formulas for detecting freshness and constantly improve them. It almost does not spoil the issue for users, but allows for a few steps to make significant changes to the predictions of our formulas.
3. When Freshness Works Well
Finally, using the example of several events, I would like to talk about indicators, with the help of which we understand that Freshness works well.
I would like to start with a graph of the general relevance of search results. This schedule is built by the company "Ashmanov and Partners", so there is no doubt about its objectivity:
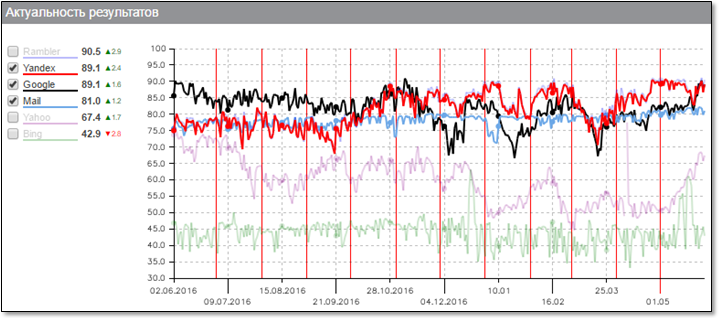
The progress of Yandex (red line) in the speed of indexation of documents, which was achieved during the last year, is clearly visible here. Our robot is really able to find out in a few minutes about the appearance of a new document and deliver it to the Freshness search index so that it will be shown to users on relevant requests.
Consider for example the news about the qualifications of the Brazilian national team at the 2018 World Cup . The document appeared on the publisher's site at 10:56, and as early as 10:58 we showed it to the user for the first time, and up to 11:00 it was shown about twenty times for relevant queries. According to this scheme, it is possible to construct a general metric, and not only to study specific documents. Take, for example, all fairly popular documents (which were shown on handouts at least 1000 times a day) and look at the median time between their publication and the first screening of the issue.
If you draw this graph for the last year, you can see that this value has decreased from four minutes to about two. This means that fresh documents are now available to users almost instantly.
When any sufficiently large event occurs, it is important to immediately begin to respond to users to relevant requests with the most relevant documents. Sometimes this can be seen on the global graphs of the age of fresh documents on the issue. We constantly monitor what proportion of the documents shown are of age less than 10 minutes, half an hour, an hour, two hours, and so on. Due to the fact that interest in events is still stretched in time, the share of such documents rarely exceeds 50%. But there are times when graphics behave like this:
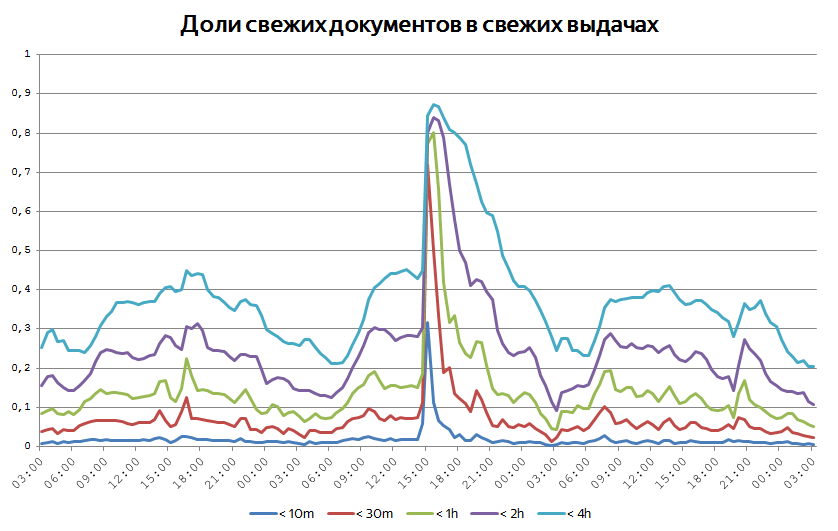
When a significant event occurs in the world, it generates a surge of publications and search activity, and then extremely fresh documents begin to prevail.
4. Conclusion
We considered some aspects of the formation of search results in situations where the user needs the most relevant information on request. Of course, a large number of questions have remained beyond our consideration, such as, for example, the quality of the fast bypass and the robot, antispam, authority, design, and so on. We discussed only freshness in the web search and left out of the scope of consideration other services that also need fresh: pictures, videos, search tips, voice search, and so on. Some of these topics will be touched upon at the already announced Yandex "Inside" meeting, and I hope we will discuss others in future articles.
Stay tuned!
')
Source: https://habr.com/ru/post/329946/
All Articles